你真的会使用C语言中的 “ 操作符 ” 吗?
前言
本期的主要内容是C语言中的操作符
重点讲解 各种操作符的介绍 和 表达式求值
文章目录
-
- 操作符分类
- 1. 算术操作符
-
- 代码示例一
- 代码示例二
- 总结
- 2. 移位操作符
-
- 原码 反码 补码
- 左移操作符
- 右移操作符
-
- 算术右移
- 逻辑右移
- 3. 位操作符
-
- 按位与
- 按位或
- 按位异或
- 4. 赋值操作符
-
- 复合赋值符
- 5. 单目操作符
-
- sizeof
- ~
- ++和--
- 6. 关系操作符
- 7. 逻辑操作符
-
- &&
- ||
- 总结
- 8. 条件操作符
- 9. 逗号表达式
- 10. 下标引用、函数调用和结构成员
-
- [ ]下标引用操作符
- ( )函数调用操作符
- 访问一个结构的成员
- 11. 表达式求值
-
- 隐式类型转换
- 算术转换
- 操作符属性
- 总结
- 结语
操作符分类
C语言中操作符总共有10种,分别是:
算术操作符
移位操作符
位操作符
赋值操作符
单目操作符
关系操作符
逻辑操作符
条件操作符
逗号表达式
下标引用、函数调用和结构成员
1. 算术操作符
分为:
加:
+
减:-
乘:*
除:/
取模(余):%
这里的话,重点讲一下:/ 和 %
代码示例一
取模:%
int main()
{
int ret = 10 % 3;
printf("%d\n", ret);
return 0;
}
运行结果:
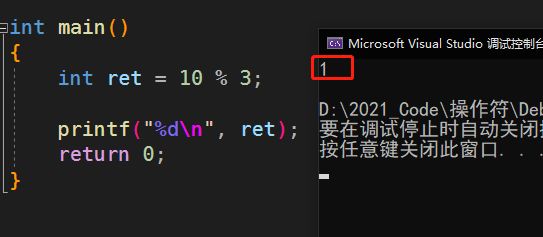
%:取模,得到的是相除之后的余数;
其实还有可能碰到这种情况:n % 3,那么余数是多少呢?
注意: n % 3的余数一定为:0或者1或者2,永远不可能大于等于3;
那如果这样呢?
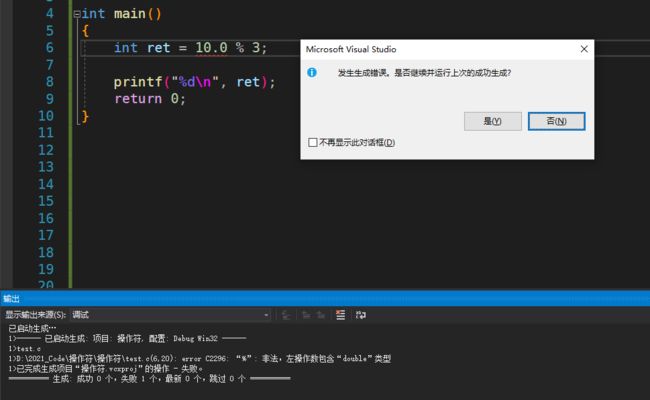
%操作符的两个操作数必须为整数,返回的是整除之后的余数。
代码示例二
除:/
int main()
{
int ret = 10 / 3;
printf("%d\n", ret);
return 0;
}
运行结果:

那如果这样呢?
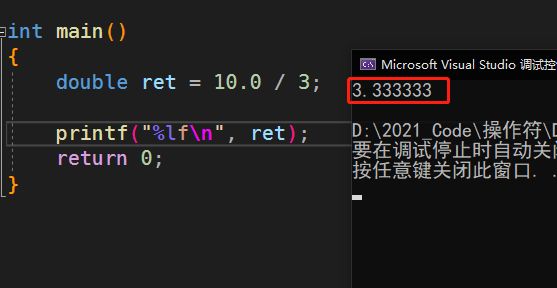
对于除号/,想打印浮点数,分子分母至少一个是浮点数!
总结
- 除了
%操作符之外,其他的几个操作符可以用于整数和浮点数。 - 对于
/操作符如果两个操作数都为整数,执行整数除法。而只要有浮点数执行的就是浮点数除法。 %操作符的两个操作数必须为整数。返回的是整除之后的余数。
2. 移位操作符
分为:
左移操作符::
<<
右移操作符:>>
其实讲移位操作符之前,先来了解一下计算机中的原码、反码和补码
原码 反码 补码
一个数在计算机内部如果是有符号数,则其最高位作为符号位;
如果符号位为0,表示该数为正数;如果符号位为1,表示该数为负数。(0正1负)
如何求原码、反码和补码呢?
原码:最高位作为符号位,其余各位为数值为(0正1负)
反码:正数的反码和原码相同,负数的反码是在原码的基础上:符号位不变,其余各位按位取反
补码:正数的补码与原码相同,负数的补码是在反码的基础上加1
以下求原反补的过程:
例:求+25和-25的原码、反码和补码
①不考虑正负,将25转换成二进制
25D=11001B
② +25 -25
原: 00011001 10011001反: 00011001 11100110
补: 00011001 11100111
再来看一个
例:求+30和-30的原码、反码和补码
①不考虑正负,将30转换成二进制
30D=11110B
② +30 -30原: 00011110 10011110
反: 00011110 11100001
补: 00011110 11100010
计算机中使用的是补码,什么是补码,怎么去理解补码?
补码可以理解成一个循环;
这里不过多阐述了,如果还有不懂的可以去百度一下!
左移操作符
移位规则:左边抛弃、右边补0
正数左移
代码示例:
int main()
{
int a = 5;
int b = a << 2;
printf("%d\n", b);
return 0;
}
运行结果:

那么这个结果是怎么来的呢?
1、首先把十进制的5转换成二进制
十进制:5
二进制:00000101
写出原码反码补码:
原码:00000101
反码:00000101
补码:00000101
所以5的补码为:00000101
2、再把补码向左移动2位
为什么向左移动2位?
因为代码是a<<2!
然后:
于是我们就得到了一个新的补码:00010100



3、转换
再把新的补码转换为十进制的数
也就是把00010100转换成十进制,得到了20
明白了吗?
负数左移
代码示例:
int main()
{
int a = -5;
int b = a << 2;
printf("%d\n", b);
return 0;
}
运行结果:

那么这个-20是怎么得来的呢?
1、首先把十进制的-5转换成二进制
但是我们得先求出5的原码
十进制:5
二进制:0000101
所以:-5的原码、反码、补码为:
原码:10000101
反码:11111010
补码:11111011
所以-5的补码为:11111011
2、再把补码向左移动2位
然后:
最后:



于是我们就得到了一个新的补码:11101100
3、回推
这里就不能直接把
11101100转换成二进制了,因为这是-5
所以我们得由:补码 ---> 反码 ---> 原码,这样逆序的过程,推算出原码

所以我们得到了新的原码:10010111
4、转换
10010100换算成十进制就是:20
但是因为符号位为:1,0正1负
所以结果为:-20

这就是左移操作符,懂了吗?
右移操作符
首先右移操作符分为两种:
- 算术右移
- 逻辑右移
移位规则:
- 算术右移:左边用原该值的符号位填充,右边丢弃
- 逻辑右移:左边用0填充,右边丢弃
那么到底是用算术右移还是逻辑右移呢?
主要是取决于编译器的!
我们常见的编译器都是算术右移
算术右移
这里还是拿数字5来举例
正数算术右移
代码示例:
int main()
{
int a = 5;
int b = a >> 1;
printf("%d\n", b);
return 0;
}
运行结果:

1、移动
上面我们已经求出了5的补码:00000101
看代码给的是向右移动一位
然后:

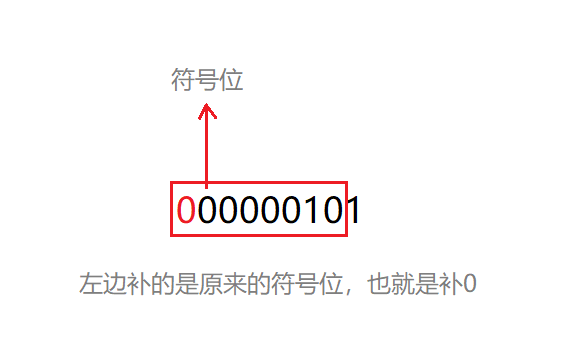
所以得到新的补码:00000010
2、转换
因为是正数,所以我们直接把00000010转换成十进制:2
负数算术右移
代码示例:
int main()
{
int a = -5;
int b = a >> 1;
printf("%d\n", b);
return 0;
}
运行结果:
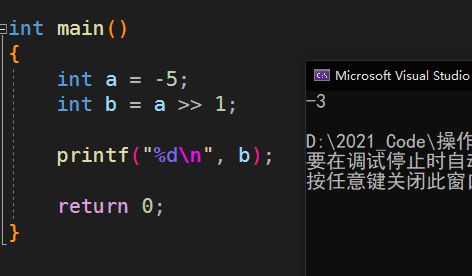
1、移动
上面我们已经求出了-5的补码:11111011
看代码给的是向右移动一位
然后:


所以得到新的补码:11111101
2、回推
我们得以:
补码 ---> 反码 ---> 原码,这样逆序的过程,推算出原码

所以我们得到了新的原码:10000011
3、转换
10000011换算成十进制就是:3
但是因为符号位为:1,0正1负
所以结果为:-3

这就是算术右移的方法,学废了吗?
逻辑右移
逻辑右移的方法和左移操作符有点类似
就是:右边丢弃,左边空的补0
这里就不演示啦!
3. 位操作符
分为:
按位与:
&,按二进制位与
按位或:|,按二进制位或
按位异或:^,按二进制位异或
注:他们的操作数必须是整数
按位与
代码示例:
int main()
{
int a = 3;
int b = -5;
int c = a & b;
printf("%d\n", v);
return 0;
}
运行结果:

为什么会得到这个结果呢?
按位与的规则: 两个都是1才是1,否则0
1、首先求出3和-5的补码
3的补码:0000 0011
-5的补码:1111 1011
a & b的计算方式是:a和b存在内存中的二进制的补码进行计算的
所以相与的结果为:
3的补码:00000011
-5的补码:11111011
相与结果:00000011
但是记住:计算中存储的是补码
所以我们得到的是相与过后的补码:00000011
再转换成原码:
补码:00000011
反码:00000011
原码:00000011
再把原码换算成十进制:00000011=3
这就是按位与的规则
按位或
代码示例:
int main()
{
int a = 3;
int b = -5;
int c = a | b;
printf("%d\n", c);
return 0;
}
运行结果:
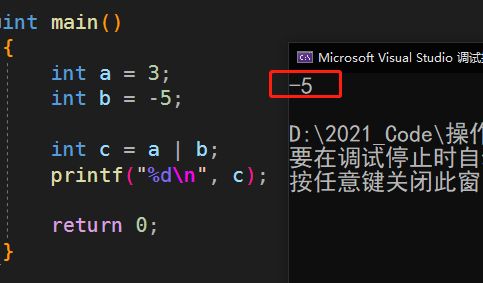
为什么会得到这个结果呢?
按位与的规则: 只要有1就是1,两个同时为0才为0
同样还是先拿出3和-5的补码
3的补码:00000011
-5的补码:11111011
相或结果:11111011
所以我们得到的是相或过后的补码:11111011
再转换成原码:
补码:11111011
反码:11111010
原码:10000101
再把原码换算成十进制:10000101=-5(符号位=1,所以要加负号)
按位异或
代码示例:
int main()
{
int a = 3;
int b = -5;
int c = a ^ b;
printf("%d\n", c);
return 0;
}
运行结果:
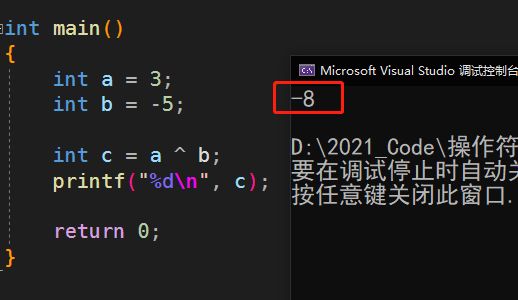
为什么会得到这个结果呢?
按位异或的规则: 相同为0,相异为1
同样还是先拿出3和-5的补码
3的补码:00000011
-5的补码:11111011
相或结果:11111000
所以我们得到的是异或过后的补码:11111000
再转换成原码:
补码:11111000
反码:11110111
原码:10001000
再把原码换算成十进制:10001000=-8(符号位=1,所以要加负号)
4. 赋值操作符
赋值操作符是一个很棒的操作符,它可以让你得到一个你之前不满意的值。也就是你可以给自己重新赋值。
int weight = 120;//体重
weight = 89;//不满意就赋值
double salary = 10000.0;
salary = 20000.0;//使用赋值操作符赋值。
赋值操作符可以连续使用,比如:
int a = 10;
int x = 0;
int y = 20;
a = x = y+1;//连续赋值
这样的代码感觉怎么样?
那同样的语义,你看看:
x = y+1;
a = x;
这样的写法是不是更加清晰爽朗而且易于调试。
复合赋值符
加等:
+=
减等:-=
乘等:*=
除等:/=
模等:%=
右移等:>>=
左移等:<<=
按位与等:&=
按位或等:|=
按位异或等:^=
这些运算符都可以写成复合的效果。
代码示例:
int x = 10;
x += 10;
x = x + 10;
x -= 10;
x = x - 10;
x *= 10;
x = x * 10;
x /= 10;
x = x / 10;
x %= 10;
x = x % 10;
x >>= 10;
x = x >> 10;
x <<= 10;
x = x << 10;
x &= 10;
x = x & 10;
x |= 10;
x = x | 10;
x ^= 10;
x = x ^ 10;
是不是很简单?
5. 单目操作符
逻辑反操作:
!
负值:-
正值:+
取地址:&
操作符的类型长度:sizeof
对一个数的二进制按位取反:~
前置、后置--:--
前置后置++:++
间接访问操作符(解引用操作符):*
强制类型转换:(类型)

以上这些操作符只需要一个操作数
讲几个重点
sizeof
代码示例
int main()
{
short sh = 0;
int i = 10;
printf("%d\n", sizeof(sh = i + 5));
printf("%d\n", sh);
return 0;
}
运行结果:
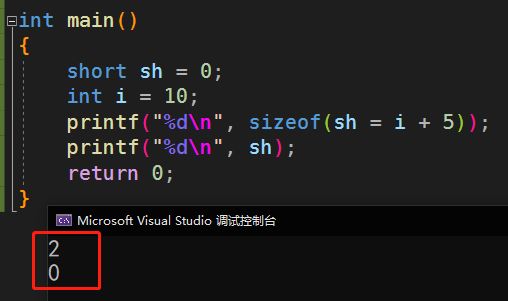
sizeof(sh = i + 5)以sh的类型为准
sh为short型,所以结果为2;
sizeof中的表达式sh = i + 5并没有真实运算,因此sh的值仍然为0
所以得出结论:sizeof内部的表达式不去真实计算
~
按位取反:~
问题:
假设我想把 00001011 的倒数第三个0改为1 怎么用代码弄?
很简单,我们只有把它和00000100 相 | 一下就行;
(相或规则:只要有1就是1,两个同时为0才为0)
那么00000100怎么来的?? ?数字1向左移两位 1<<2
11:00001011
1:00000001
1<<2:00000100
11:00001011
代码示例:
int main()
{
int a = 11;//10的二进制是: 1011
int ret;
ret = a | (1 << 2);
printf("%d", ret);
return 0;
}
运行结果:

那如果我想把1111改回去呢???
15:00000000 00000000 0000000 00001111
和这个数相&:11111111 11111111 11111111 111110111
那11111111 11111111 11111111 111110111怎么得来的呢???
首先就是:00000000 00000000 00000000 00000100取反得来
00000000 00000000 00000000 00000100而这个又是1向左移两位的结果
00000000 00000000 00000000 00000001(数字1)
所以逻辑是 首先 1<<2然后取反最后相与
(相与规则:两个都是1才是1,否则0)
代码示例:
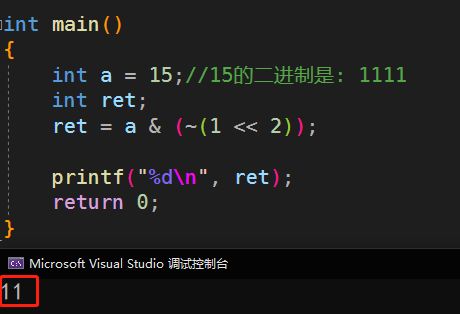
int main()
{
int a = 15;//15的二进制是: 1111
int ret;
ret = a & (~(1 << 2));
printf("%d\n", ret);
return 0;
}
运行结果:
++和–
++分为:
1、前置++:先使用,再++;
2、后置++:先++,再使用;
先看前置++:
int main()
{
int a = 10;
int b = ++a;
printf("a=%d b=%d\n", a, b);
return 0;
}
运行结果:

先让a自己+1,再把a+1的结果赋值给b;
所以:a=11, b=11;
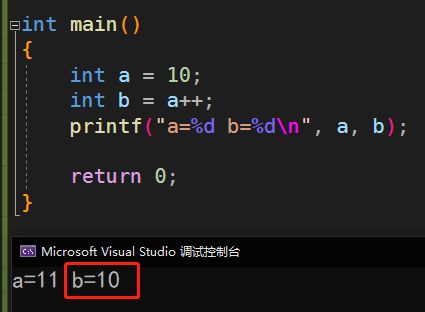
再看后置++:
int main()
{
int a = 10;
int b = a++;
printf("a=%d b=%d\n", a, b);
return 0;
}
运行结果:
先把a的值赋给b,再让a自己+1;
所以:a=11, b=10;
--的使用和++一样,这里就补演示了
6. 关系操作符
分为:
大于:
>
大于等于:>=
小于:<
小于等于:<=
不相等:!=
相等:==

这些关系运算符比较简单,没什么可讲的,但是我们要注意一些运算符使用时候的陷阱
在编程的过程中要注意:== 和=,如果不小心写错,会导致错误。
7. 逻辑操作符
分为:
逻辑与:
&&
逻辑或:||

但是这里我们要区分上面的位操作符:
按位与:
&
按位或:|
位操作符是计算数字的二进制位,而逻辑操作符是计算的整个表达式的真假;
&&
逻辑与&&:从左向右所有表达式都为真(非0),那整体就为真(1),否则为假(0)
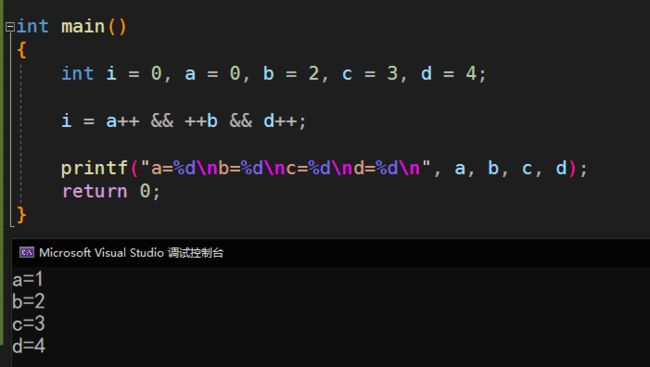
代码示例:
int main()
{
int i = 0, a = 0, b = 2, c = 3, d = 4;
i = a++ && ++b && d++;
printf("a=%d\nb=%d\nc=%d\nd=%d\n", a, b, c, d);
return 0;
}
运行结果:
那么这段代码怎么计算的呢?
1、首先在
i = a++ && ++b && d++;这段表达式中;从=的右边开始,从左向右依次执行
2、a++先使用a的值,然后再进行+1,所以此时a的值就为0;
3、a=0表示为假(非0为真),所以这个逻辑表达式就为假,后面的++b && d++不再执行;
4、所以打印结果:a=1, b=2, c=3, d=4;
||
逻辑或||:从左向右所有表达式有一个为真(非0),那么整体就为真(1),只有所有表达式都为假时整体才为假(0);
代码示例:
int main()
{
int i = 0, a = 0, b = 2, c = 3, d = 4;
i = a++ || ++b || d++;
printf("a=%d\nb=%d\nc=%d\nd=%d\n", a, b, c, d);
return 0;
}
运行结果:

那么这段代码怎么计算的呢?
1、首先还是从左往右依次执行:
a++ || ++b || d++
2、a++先使用a的值,然后再进行+1,所以此时a的值就为0;
3、a=0表示为假(非0为真),因此继续执行;
4、++b先让b自己+1,再使用b;此时b=3表示为真;
5、因此整个表达式的结果就为真,后面的d++的操作将不再执行;
总结
逻辑与&&:左操作数为假,右边不计算;
逻辑或 ||:左操作数为真,右边不计算;
8. 条件操作符
也叫做 三目操作符
exp1 ? exp2 : exp3
表达式exp1如果成立,则返回表达式2的值;否则返回表达式3的值
三目运算符和if-else语句十分类似;
代码示例:
int main()
{
int a = 10;
int b ;
if (a > 5)
{
b = 3;
}
else
{
b = -3;
}
printf("b=%d\n", b);
}
运行结果:

用if-else语句的话,代码就比较啰嗦;
那可以换成条件表达式;
代码示例:
int main()
{
int a = 10;
int b ;
b = (a > 5) ? 3 : -3;
printf("b=%d\n", b);
return 0;
}

9. 逗号表达式
exp1, exp2, exp3, …expN
逗号表达式,就是用逗号隔开的多个表达式
计算方法:从左向右依次执行,整个表达式的结果是最后一个表达式的结果
代码示例:
int main()
{
int a = 1;
int b = 2;
int c = (a > b, a = b + 10, a, b = a + 1);//逗号表达式
printf("c=%d\n", c);
return 0;
}
运行结果:

那么这段代码怎么计算的呢?
1、
c = (a > b, a = b + 10, a, b = a + 1)从左向右依次计算
2、a>b结果为假,这个表达式的结果为0;
3、a=b+10的结果为12,此时a的值为12;
4、这个a单独放在这里,继续执行后面的表达式;
5、b=a+1的值为13, 因此整个表达式的结果就是最后一个表达式b = a + 1的结果12
但其实这段代码还有可以改进的地方!
逗号表达式可以和while循环结合,使语句更简洁
代码示例:
int main()
{
a = get_val();
count(a);
while (a > 0)
{
a = get_val();
count(a);
//语句
}
return 0;
}
写成这样的话,是不是就重复了
改写代码:
int main()
{
while(a = get_val(),a>0,count(a))
{
//语句
}
return 0;
}
10. 下标引用、函数调用和结构成员
分为:
下标引用操作符:
[ ]
函数调用操作符:( )
访问结构体成员:.
结构体指针访问:->
[ ]下标引用操作符
用来访问和使用数组的;
操作数:一个数组名+一个索引值
int arr[10];//创建数组
arr[9] = 10;//实用下标引用操作符。
[ ]的两个操作数是arr和9。
( )函数调用操作符
接受一个或者多个操作数:第一个操作数是函数名,剩余的操作数就是传递给函数的参数
void test1()
{
printf("hehe\n");
}
void test2(const char* str)
{
printf("%s\n", str);
}
int main()
{
test1(); //实用()作为函数调用操作符。
test2("hello world!");//实用()作为函数调用操作符。
return 0;
}
运行结果:

访问一个结构的成员
分为:
结构体.成员名:
.
结构体指针 -> 成员名:->
.代码示例:
struct stu
{
char name[10];//名字
int age;//年龄
char sex[10];//性别
double score;//成绩
};
int main()
{
//创建一个学生s,并对其进行初始化赋值
struct stu s = { "张三", 100, "男", 95.9 };
// . 为结构成员访问操作符,能够访问结构体的成员
printf("name=%s age=%d sex=%s score=%.1lf\n", s.name, s.age, s.sex, s.score);
return 0;
}
运行结果:

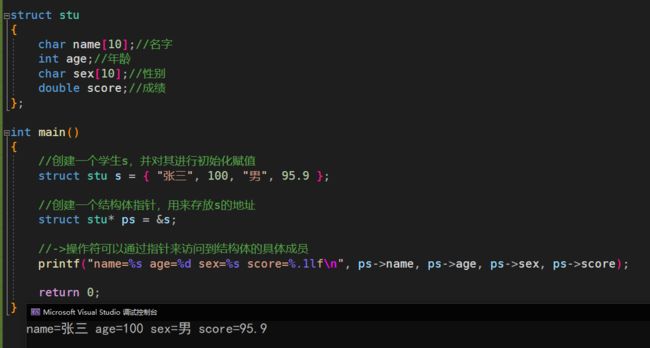
->代码示例:
struct stu
{
char name[10];//名字
int age;//年龄
char sex[10];//性别
double score;//成绩
};
int main()
{
//创建一个学生s,并对其进行初始化赋值
struct stu s = { "张三", 100, "男", 95.9 };
//创建一个结构体指针,用来存放s的地址
struct stu* ps = &s;
//->操作符可以通过指针来访问到结构体的具体成员
printf("name=%s age=%d sex=%s score=%.1lf\n", ps->name, ps->age, ps->sex, ps->score);
return 0;
}
运行结果:
两种访问方法都可以!
11. 表达式求值
表达式求值的顺序一部分是由操作符的优先级和结合性决定。
同样,有些表达式的操作数在求值的过程中可能需要转换为其他类型。
隐式类型转换
C的整型算术运算总是至少以缺省整型类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度 一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。
通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令 中可能有这种字节相加指令)。
所以,表达式中各种长度可能小于int长度的整型值,都必须先转换为int或unsigned int,然后才能送入CPU去执行运算。
//负数的整形提升
char c1 = -1;
变量c1的二进制位(补码)中只有8个比特位:
1111111
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为1
提升之后的结果是:
11111111111111111111111111111111
//正数的整形提升
char c2 = 1;
变量c2的二进制位(补码)中只有8个比特位:
00000001
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为0
提升之后的结果是:
00000000000000000000000000000001
//无符号整形提升,高位补0
代码示例一:
int main()
{
char x = 3;
char y = 127;
char z = x + y;
printf("%d\n", z);
return 0;
}
运行结果:
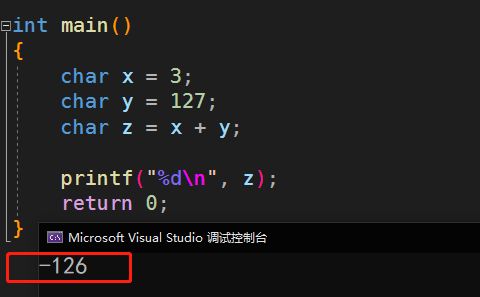
x和y的值被提升为普通整型,然后再执行加法运算。
加法运算完成之后,结果将被截断,然后再存储于z中,因此结果并不是130
如何进行整体提升呢?
整形提升是按照变量的数据类型的符号位来提升的
char x = 3
首先3是一个整数,它的大小是4个字节也就是32位,00000000000000000000000000000011
但是x是char类型,这个类型的变量x只能存放1个字节也就是8位:00000011
同理:
char y = 127;
127写成32位是00000000000000000000000001111111
char 类型的b只能存放8位:01111111
最后
x和y在相加时,由于它们的大小只有1字节,并不满足普通整形类型4字节的大小;
因此为了提升计算精度要把它们进行整形提升
整形提升是按照变量的数据类型的符号位来提升的
也就是最左边是1提升的位就补1,是0就补0
因此x和y在相加时,要先整形提升为32位,即:
3的整型提升:00000000000000000000000000000011
127的整型提升:00000000000000000000000001111111
相加:00000000000000000000000010000010
注意:
但是z是char类型,只能存放8位
因此z里面放的是:10000010
在打印z的时候,z也要进行整形提升:
z最左边的符号位是1,所以提升的位都补1,整形提升以后的32位结果是: 11111111111111111111111110000010
整形提升以后得到的是补码,我们再把补码转换成原码,就是打印的结果:
补码 :11111111111111111111111110000010
反码 :11111111111111111111111110000001
原码:10000000000000000000000001111110
这个原码就是我们打印的结果-126
代码示例二:
int main()
{
char a = 0xb6;
short b = 0xb600;
int c = 0xb6000000;
if (a == 0xb6)
printf("a\n");
if (b == 0xb600)
printf("b\n");
if (c == 0xb6000000)
printf("c\n");
return 0;
}
运行结果:
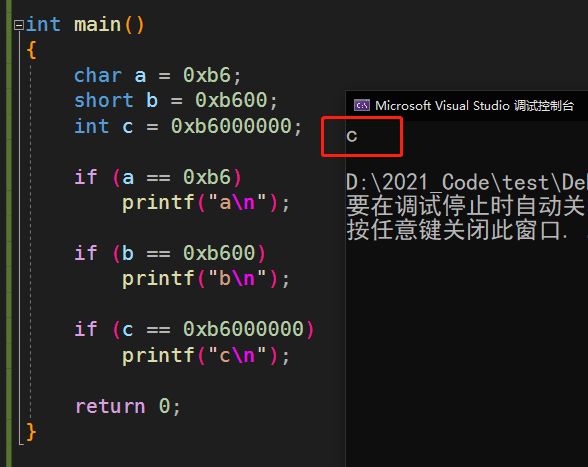
分析:
a,b要进行整形提升,但是c不需要整形提升;
a,b整形提升之后,变成了负数,所以表达式 a==0xb6 ,b==0xb600 的结果是假;
但是c不发生整形提升,则表 达式 c==0xb6000000 的结果是真;
所以结果为:c
我们来看一下它们各自的值:

可以看到,只有c的值是相等的,c本身就是个int型,它并不用整形提升;
a和b整形提升以后,它们的值发生了改变。
至于如何把16进制转换成2进制,然后整形提升,这些以及在前面说过很多遍了,在这里就不具体说明了;
强调一点: 只要参与到表达式运算,就会发生整形提升
代码示例三:
int main()
{
char c = 1;
printf("%u\n", sizeof(c));
printf("%u\n", sizeof(+c));
printf("%u\n", sizeof(-c));
return 0;
}
运行结果:

分析:
c只要参与表达式运算,就会发生整形提升,表达式+c,就会发生提升;
所以sizeof(+c)和sizeof(-c)是4个字节;
而sizeof( c )并不会发生整形提升,所以是一个字节 ;
算术转换
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数的转换为另一个操作数的类型,否则操作就无法进行。
下面的层次体系称为寻常算术转换。
long double
double
float
unsigned long int
long int
unsigned int
int

如果某个操作数的类型在上面这个列表中排名较低,那么首先要转换为另外一个操作数的类型后执行运算。
警告: 但是算术转换要合理,要不然会有一些潜在的问题。
比如一个int类型和float类型相加,那int类型首先就要转化成float类型,然后再相加;
这不难理解,在此不作过多说明;
但是算术转换要合理,要不然会丢失精度。
比如:
float f = 3.14;
int num = f;//隐式转换,会有精度丢失
操作符属性
复杂表达式的求值有三个影响的因素:
- 操作符的优先级
- 操作符的结合性
- 是否控制求值顺序
两个相邻的操作符先执行哪个?
取决于他们的优先级;如果两者的优先级相同,取决于他们的结合性。
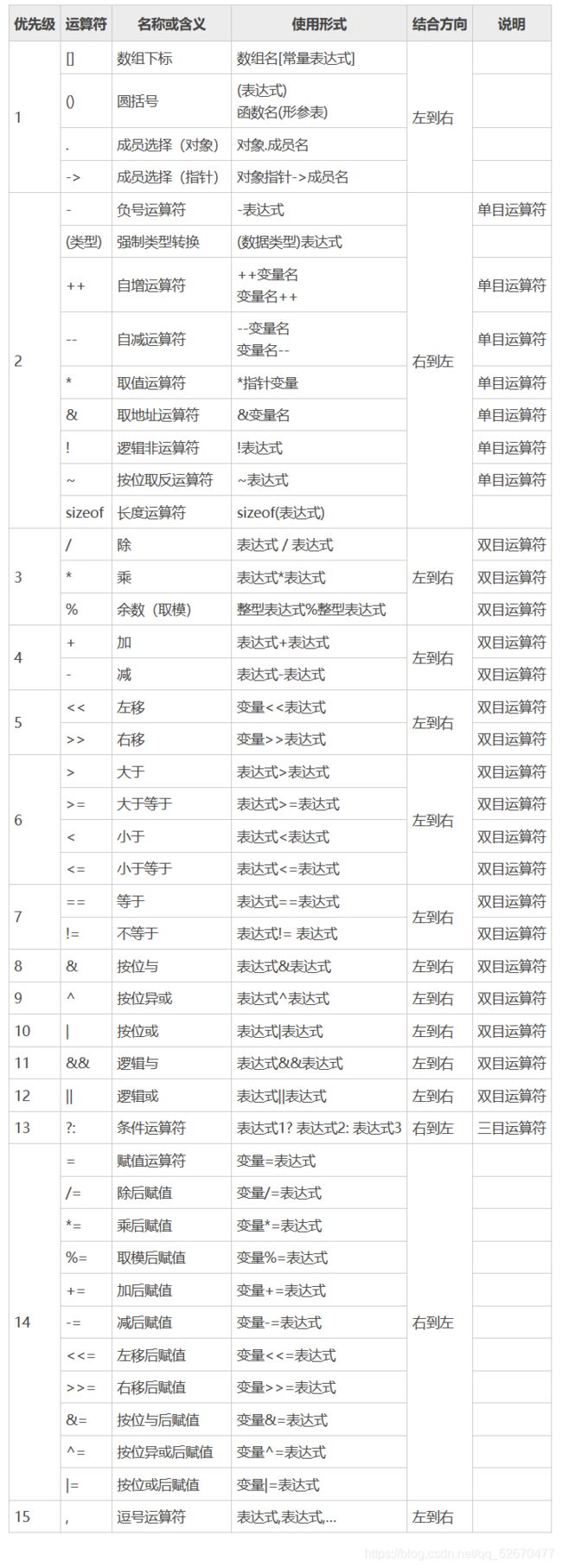
操作符优先级:
| 操作符 | 描述 | 用法示例 | 结果类型 | 结合性 | 是否控制求值顺序 |
|---|---|---|---|---|---|
| ( ) | 聚组 | (表达式) | 与表达式同 | N/A | 否 |
| ( ) | 函数调用 | rexp(rexp,…,rexp) | rexp | L-R | 否 |
| [ ] | 下标引用 | Rexp[rexp] | lexp | L-R | 否 |
| . | 访问结构成员 | Lexp.member_name | lexp | L-R | 否 |
| -> | 访问结构指针成员 | Rexp->member_name | lexp | L-R | 否 |
| ++ | 后缀自增 | Lexp++ | rexp | L-R | 否 |
| – | 后缀自减 | Lexp– | rexp | L-R | 否 |
| ! | 逻辑反 | !rexp | rexp | R-L | 否 |
| ~ | 按位取反 | ~rexp | rexp | R-L | 否 |
| + | 单目,表示正值 | +rexp | rexp | R-L | 否 |
| - | 单目,表示负值 | -rexp | rexp | R-L | 否 |
| ++ | 前缀自增 | ++lexp | rexp | R-L | 否 |
| – | 前缀自减 | –lexp | rexp | R-L | 否 |
| * | 间接访问 | *rexp | lexp | R-L | 否 |
| & | 取地址 | &lexp | rexp | R-L | 否 |
| sizeof | 取其长度,以字节表示 | Sizeof rexp | rexp | R-L | 否 |
| Sizeof(类型) | |||||
| (类型) | 类型转换 | (类型)rexp | rexp | R-L | 否 |
| * | 乘法 | Rexp * rexp | rexp | L-R | 否 |
| / | 除法 | Rexp / rexp | rexp | L-R | 否 |
| % | 整数取余 | Rexp % rexp | rexp | L-R | 否 |
| + | 加法 | Rexp + rexp | Rexp | L-R | 否 |
| - | 减法 | Rexp - rexp | Rexp | L-R | 否 |
| << | 左移位 | Rexp << rexp | Rexp | L-R | 否 |
| >> | 右移位 | Rexp >> rexp | Rexp | L-R | 否 |
| > | 大于 | Rexp > rexp | Rexp | L-R | 否 |
| >= | 大于等于 | Rexp >= rexp | Rexp | L-R | 否 |
| < | 小于 | Rexp < rexp | Rexp | L-R | 否 |
| <= | 小于等于 | Rexp <= rexp | Rexp | L-R | 否 |
| == | 等于 | Rexp == rexp | rexp | L-R | 否 |
| != | 不等于 | Rexp != rexp | Rexp | L-R | 否 |
| & | 位与 | Rexp & rexp | Rexp | L-R | 否 |
| ^ | 位异或 | Rexp ^ rexp | rexp | L-R | 否 |
| | | 位或 | Rexp | rexp | Rexp | L-R | 否 |
| && | 逻辑与 | Rexp && rexp | Rexp | L-R | 是 |
| || | 逻辑或 | Rexp || rexp | rexp | L-R | 是 |
| ?: | 条件操作符 | Rexp ? rexp : rexp | rexp | N/A | 是 |
| = | 赋值 | Lexp = rexp | rexp | R-L | 否 |
| += | 以…加 | Lexp += rexp | rexp | R-L | 否 |
| -= | 以…减 | Lexp -= rexp | Rexp | R-L | 否 |
| *= | 以…乘 | Lexp *= rexp | Rexp | R-L | 否 |
| /= | 以…除 | Lexp /= rexp | Rexp | R-L | 否 |
| %= | 以…取模 | Lexp %= rexp | Rexp | R-L | 否 |
| <<= | 以…左移 | Lexp <<= rexp | Rexp | R-L | 否 |
| >>= | 以…右移 | Lexp >>= rexp | Rexp | R-L | 否 |
| &= | 以…与 | Lexp &= rexp | Rexp | R-L | 否 |
| ^= | 以…异或 | Lexp ^= rexp | Rexp | R-L | 否 |
| |= | 以…或 | Lexp |= rexp | Rexp | R-L | 否 |
| , | 逗号 | Rexp, rexp | Rexp | L-R | 是 |
再来一张比较易懂的图:
由于操作符具有优先级和结合性,因此非常容易写出很多有问题的代码,比如:
a + --a;
操作符的优先级只能决定自减–的运算在+的运算的前面,但是我们无法知道最左边的a是已经自减以后的a还是没自减之前的a;
再来看一个:
a*b + c*d + e*f
上面代码在计算的时候,由于*比+的优先级高,只能保证,*的计算是比+早;
但是优先级并不能决定第三个*比第一个+早执行。
代码示例:
int fun()
{
static int count = 1;
return ++count;
}
int main()
{
int answer;
answer = fun() - fun() * fun();
printf("%d\n", answer);
return 0;
}
在算answer = fun() - fun() * fun();的时候,虽然根据优先级知道先算乘再算减,
但是哪个fun()先调用呢?这个问题其实是未知的,函数的调用顺序不一样,其运算的结果也是不一样的。
还有下面这种:
int main()
{
int i = 10;
i = i-- - --i * (i = -3) * i++ + ++i;
printf("i = %d\n", i);
return 0;
}
在不同编译器中测试结果:非法表达式程序的结果
以下是在不同编译器当中测得的结果:

最后一个代码:
int main()
{
int i = 1;
int ret = (++i) + (++i) + (++i);
printf("%d\n", ret);
printf("%d\n", i);
return 0;
}
这段代码中的第一个++ i在执行的时候,第三个++i是否执行,这个是不确定的;
因为依靠操作符的优先级和结合性是无法决定第一个++和第三个前置++的先后顺序。
以上这些代码在不同的编译器下运行的结果都是不同的,因为不同的编译器其运算和函数调用的顺序都是不同的。
总结
我们写出的表达式如果不能通过操作符的属性确定唯一的计算路径,那这个表达式就是存在问题的。
结语
以上就是C语言中所有的操作符详解和使用方法,如有错误欢迎指正!
学会了吗?
那么来做一些练习题吧!
链接:操作符重点难题
你知道的越多,你不知道越多,我们下期见!