ceph分布式存储
ceph分布式存储架构
- 1.原理
- 2. ceph
- 3.ceph支持的存储方式
-
- 3.1块存储(硬盘)
-
- 3.1.1 怎么有的叫sda,有的叫sdb,有的叫hda
- 3.1.2 怎么有的叫rbd1和rbd2
- 3.1.3 总结
- 3.2文件存储系统
-
- 3.2.1总结
- 3.3 对象存储
- 4. ceph支持的接口
- 5.ceph存储优点
-
- 5.1 统一存储
- 5.2 CRUSH算法
- 5.3 高拓展性
- 5.4 可靠性强(高可用性)
- 5.5 高性能
- 6.ceph各个组件
-
- 6.1 OSD(Object Storage Device)
- 6.2 Monitors
- 6.3 MDS
- 6.4 MGR
- 7.ceph架构
-
- 7.1 RADOS
- 7.2 LIBRADOS库
- 8. 存储类型
- 9.存储概念
-
- 9.1 存储数据与object的关系
- 9.2 object与pg的关系
- 9.3 pg与osd的关系
- 9.4 pg与pgp的关系
- 9.5 存储池
- 9.6 数据存储过程
- 10. 正常IO流程图
- 11. 生产环境推荐
- 12. ceph官方文档
- 13. ceph中文开源社区
- 14. ceph扩容
- 15. ceph常用命令
-
- 15.1 服务相关
- 15.2 查看
- 15.3 rbd相关
- 15.4 修改
1.原理
分布式文件系统(Distributed File System):文件系统管理的物理存储资源不一定直接连接在本机节点上,而是通过计算机网络与节点相连(把分散在局域网内各个计算机上)共享文件夹,集合到一个文件夹内(虚拟共享文件夹)
2. ceph
开元、统一的分布式存储系统,提供较好的性能、可靠性和可拓展性
优点:良好的可拓展性(PB级别以上)、高性能、高可靠性
起源于加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统
3.ceph支持的存储方式
3.1块存储(硬盘)
i/o 设备中的一类,将信息存储在固定大小的块中,每个块都有自己的地址,可以在块设备的任意位置读取一定长度的数据
3.1.1 怎么有的叫sda,有的叫sdb,有的叫hda
以sd开头的块设备文件对应的是scsi接口的硬盘
以hd开头的块设备文件对应的是IDE接口的硬盘
当系统检测到多个scsi硬盘时,会根据检测到的顺序对硬盘设备将那些字母顺序的命名
注:系统按检测顺序命名硬盘会导致盘符漂移的问题
3.1.2 怎么有的叫rbd1和rbd2
rbd由ceph集群提供出来的块设备
sda和hda都是通过数据线连接到真实的硬盘,而rbd是通过网络连接到ceph集群中的一块存储区域,往rbd设备文件写入数据,最终会被保存到ceph集群的这块区域区域中
3.1.3 总结
块设备可理解成一块硬盘,用户可以直接使用不含文件系统的块设备(裸设备),也可以将其格式化成特定的文件系统,由文件系统来组织管理存储空间,从而为用户提供丰富而友好的数据操作支持
块存储,即rbd,有 kernel 和 librbd 两种使用方式,支持快照、克隆,相当于一块硬盘挂载到本地,用法和用途一样
3.2文件存储系统
ceph文件系统(CEPH FS)是一个POSIX兼容的文件系统,可以将ceph集群看作一个共享文件系统挂载到本地,使用ceph的存储集群来存储数据,同时支持用户空间文件系统FUSE,可以像NFS或者SAMBA那样,提供共享文件夹,客户端通过挂载目录的方式使用ceph提供的存储
在CEPH FS 中,与对象存与块存储最大的不同就是在集群中增加了文件系统元数据服务节点MDS(Ceph Metadata Server),MDS也支持多台机器分布式的部署,以实现系统的高可用性,文件系统客户端需要安装对应的Linux内核模块Ceph FS Kernel Object或者Ceph FS FUSE组件

因为应用场景的不同,ceph的块设备具有优异的读写性能,但不能多出挂载同时读写,目前主要用在OpenStackk上作为虚拟磁盘,而ceph的文件系统接口读写性能较块设备接口差,但具有优异的共享性
文件系统的结构状态时维护在各用户机中
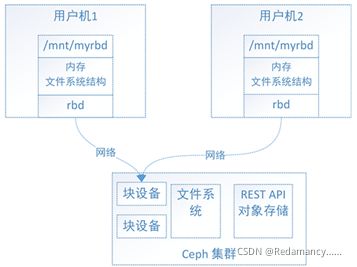
如上图:
假设ceph块设备同时挂载到用户机1和用户机2,当在用户机1上的文件系统写入数据后,更新了用户机1中的文件系统状态,最终数据保存到了ceph集群中,但此时用户机2中的文件系统并不能得知底层ceph集群数据已经变化而位置数据结构不变,用因此用户无法从用户机2上读取用户机1上新写入的数据
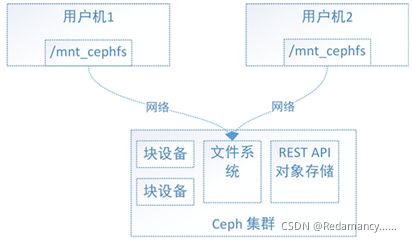
如上图:
文件系统的结构状态是维护在远端ceph集群中的,ceph文件系统同时挂载用户机1和用户机2,当往用户机1的挂载点写入数据后,远端ceph集群中的系统文件状态结构随之更新,当从用户机2的挂载点访问数据时会去远端ceph集群取数据,由于远端ceph集群已更新,用户机2能够获取最新的数据
3.2.1总结
ceph的文件系统弥补了ceph的块设备在共享方面的不足,ceph的文件系统符合POSIX 标准,用户就可以像使用本地存储目录一样使用ceph的文件系统的挂载目录,即无需修改你的程序,就可以将程序的底层存储换成空间无线并可以多出共享读写的ceph集群文件系统
3.3 对象存储
1)对象存储也就是键值存储,通过其接口指令(GET、PUT、DEL、其他拓展指令)像存储服务上传下载数据等
2)对象存储中所有数据读背认为时一个对象,任何数据都可以存入对象存储服务器(如图片、视频、音频等)
通过RGW来实现
1)RGW 即Rados Gateway的全称
2)RGW是ceph对象存储网关,用户向客户端应用程序提供存储界面,提供RESTful API 访问接口
3)RGW可以部署多台作为高可用和负载均衡

4. ceph支持的接口
(1) S3.compatible:S3兼容的接口,提供与Amazon S3大部分RESTfuI API接口兼容的API接口。
(2) Swift.compatible:提供与OpenStack Swift大部分接口兼容的API接口。
Ceph的块设备存储具有优异的存储性能但不具有共享性,而Ceph的文件系统具有共享性,然而性能较块设备存储差,对象存储具有共享性而存储性能好于文件系统存储的存储,对象存储就这样出现了
文件系统存储具有复杂的数据组织结构,能够提供给用户更加丰富的数据操作接口,而对象存储精简了数据组织结构,提供给用户有限的数据操作接口,以换取更好的存储性能。对象接口提供了REST API,非常适用于作为web应用的存储
5.ceph存储优点
5.1 统一存储
支持三种调用接口:对象存储、块存储、文件系统挂载
通常采用ceph作为openstack的唯一后端存储来提升数据转发几率
5.2 CRUSH算法
能实现各类负载的副本放置规则,具有相当强大的拓展性,支持数千个存储节点
5.3 高拓展性
扩容方便、容量大,能够管理数千台服务器、EB级的容量
5.4 可靠性强(高可用性)
能够跨主机、机架、机房、数据中心存放,存储节点可以自管理、自动修复、误单点故障,容错性强
5.5 高性能
在多个副本中读写操作能够做到高度并行化,节点越多,整个集群的 IOPS和吞吐量越高
6.ceph各个组件
6.1 OSD(Object Storage Device)
提供存储资源
功能:用于集群中所有数据与对象的存储,处理集群的复制、恢复、回填、再均衡
一块硬盘对应一个OSD,由OSD来对硬盘存储进行管理,至少需要2个OSD守护进程,集群才能达到active+clean状态
active:表示磁盘处于活动状态
clean:表示主osd和副本osd成功同步
journal盘:一般写数据到ceph集群时,都是先将数据写入到journal盘中,然后每隔一段时间再将journal盘中的数据刷到文件系统中,为了使读写时延更小,都采用SSD,一般分配再10G以上
ceph中引入journal盘的概念是因为运行ceph OSD随机小块的写操作首先写入journal,然后合并成顺序IO刷到文件系统
6.2 Monitors
负责监视ceph集群,维护ceph集群的健康状态、各种Map图(包括建施图、OSD图、归置图(PG)图、CRUSH图),还维护了monitor、OSD和PG的状态改变历史信息
6.3 MDS
为ceh文件系统存储元数据、但对象存储和块存储设备不需要使用该服务
6.4 MGR
分担和脱渣monitor的部分功能,减轻monitor的负担,更好的管理ceph存储系统
7.ceph架构

7.1 RADOS
ceph的底层是RADOS,也是分布式存储系统,ceph所欲的存储功能都是基于RADOS实现,ceph的高可靠、高可拓展、高性能能、高自动化都是由这一层来提供,用户数据的存储在最终也是通过这一层来进行存储的,RADOS是ceph的核心
RADOS系统主要由两部分组成,分别是OSD和Monitor。
OSD: Object StorageDevice,提供存储资源。
Monitor:维护整个Ceph集群的全局状态
7.2 LIBRADOS库
基于RADOS层的上一层,是一个库,允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言
8. 存储类型
1、RADOSGW:对象存储接口,RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。
2、RBD:是Ceph对外提供的块设备服务。
3、CEPH FS:是Ceph对外提供的文件系统服务
9.存储概念

9.1 存储数据与object的关系
当用户将数据存储到ceph集群时,存储数据都会被分隔成多个object,每个object都有一个object id,每个object的大小都是可以设置的,默认4MB ,object时ceph存储的最小存储单元
9.2 object与pg的关系
由于object的数量很多,对象的size很小,在一个大规模的集群中可能由几百到上千万个对象,这么多对象光是遍历寻址,速度都是很缓慢的,为了解决这些问题,ceph引入了归置组(Placcment Group即PG)的概念用于管理object,每个object最后都会通过CRUSH算法计算映射到某个pg中,一个pg可以包含多个object
9.3 pg与osd的关系
pg也需要通过CRUSH计算映射到osd中去存储,如果是二副本的,则每个pg都会映射到二个osd,比如[osd.1,osd.2],那么osd.1是存放该pg的主副本,osd.2是存放该pg的从副本,保证了数据的冗余
9.4 pg与pgp的关系
pg是用来存放object的,pgp相当于是pg存放osd的一种排列组合
比如有3个osd,osd.1、osd.2和osd.3,副本数是2,如果pgp的数目为1,那么pg存放的osd组合就只有一种,可能是[osd.1,osd.2],那么所有的pg主从副本分别存放到osd.1和osd.2,如果pgp设为2,那么其osd组合可以两种,可能是[osd.1,osd.2]和[osd.1,osd.3]
9.5 存储池
对ceph集群进行逻辑划分,设置存储对象的权限、备份数目、PG数以及CRUSH规则等属性

9.6 数据存储过程
Ceph存储集群从客户端接收文件,每个文件都会被客户端切分成一个或多个对象,然后将这些对象进行分组,再根据一定的策略存储到集群的OSD节点中
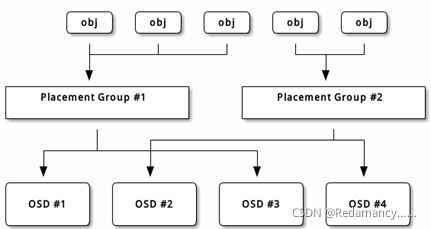
图中,对象的分发需要经过两个阶段的计算,才能得到存储该对象的OSD,然后将对象存储到OSD中对应的位置。
(1)对象到PG的映射。PG是对象的逻辑集合。PG是系统向OSD节点分发数据的基本单位,相同PG里的对象将被分发到相同的OSD节点中(一个主OSD节点多个备份OSD节点)。对象的PG是由对象ID号通过Hash算法,结合其他一些修正参数得到的。
(2)PG到相应的OSD的映射。RADOS系统利用相应的哈希算法根据系统当前的状态以及PG的ID号,将各个PG分发到OSD集群中。OSD集群是根据物理节点的容错区域(比如机架、机房等)来进行划分的
10. 正常IO流程图

步骤:
- client 创建cluster handler(集群处理信息)。
- client 读取配置文件。
- client 连接上monitor,获取集群map信息。
- client 读写io 根据crush map 算法请求对应的主osd数据节点。
- 主osd数据节点同时写入另外两个副本节点数据。
- 等待主节点以及另外两个副本节点写完数据状态。
- 主节点及副本节点写入状态都成功后,返回给client,io写入完成
11. 生产环境推荐
1、存储集群采用全万兆网络
2、集群网络(不对外)与公共网络分离(使用不同网卡)
3、mon、mds与osd分离部署在不同机器上
4、journal推荐使用SSD,一般企业级IOPS可达40万以上
5、OSD使用SATA亦可
6、根据容量规划集群
7、至强E5 2620 V3或以上cpu,64GB或更高内存
8、最后,集群主机分散部署,避免机柜故障(电源、网络)
12. ceph官方文档
http://docs.ceph.org.cn/
13. ceph中文开源社区
http://ceph.org.cn/
14. ceph扩容

15. ceph常用命令
15.1 服务相关
- systemctl status ceph*.service ceph*.target #查看所有服务
- systemctl stop ceph*.service ceph*.target #关闭所有服务
- systemctl start ceph.target #启动服务
- systemctl stop ceph-osd*.service # 关闭所有osd服务
- systemctl stop ceph-mon*.service #关闭所有mon服务
- sudo systemctl start ceph-osd@{id} #启动单个osd服务
- sudo systemctl start ceph-mon@{hostname} #启动单个mon服务
- sudo systemctl start ceph-mds@{hostname} #启动单个mds服务
15.2 查看
- ceph -help #查看命令帮助
- ceph -s #查看状态
- ceph osd pool set rbd pg_num 1024 # 修改pg_num数量
- ceph osd pool set rbd pgp_num 1024 # 修改pgp_num数量
- ceph osd tree #查看osd树列表
- ceph osd pool ls #查看所有的osd池
- ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show # 查看指定的osd运行中的所有参数
- rados df #查看储存池使用情况
- rados -p rbd ls |sort
- ceph osd pool get rbd pg_num
- ceph osd pool get rbd pgp_num
- ceph osd pool set rbd pg_num 1024
- ceph osd pool set rbd pgp_num 1024
15.3 rbd相关
- rbd create --size {megabytes} {pool-name}/{image-name}
- rbd list
- rbd info RBD_NAME
- rbd feature disable RBD_NAME FEATURE1 FEATURE1 …
- rbd map RBD_NAME #映射到系统内核
- rbd showmapped #查看rbd映射条目
- rbd unmap /dev/rbd0 # 取消内核映射
- rbd resize --size 2048 RBD_NAME # to increase
- rbd resize --size 2048 RBD_NAME --allow-shrink #to decrease
- rbd du {RBD_NAME} -p rbd #查看某个或所有Image的容量,-p 指定pool名
- rbd diff RBD_NAME | awk ‘{ SUM += $2 } END { print SUM/1024/1024/1024 " GB" }’ #查看rbd image当前占用大小
15.4 修改
ceph tell # 使用tell命令手动临时修改组件的配置
[例如:集群状态恢复涉及数据回填时,加速回填速度]
- ceph tell ‘osd.*’ injectargs ‘–osd-max-backfills 16’ #默认为1
- ceph tell ‘osd.*’ injectargs ‘–osd-recovery-max-active 8’ #默认为4