PyTorch学习笔记(十)——GoogLeNet
目录
- 一、GoogLeNet 简介
- 二、Inception 块
- 三、GoogLeNet 架构
- 四、训练/测试 GoogLeNet
- 附录:完整代码
一、GoogLeNet 简介
GoogLeNet 吸收了 NiN 中串联网络的思想,并在此基础上做了改进。GoogLeNet 的一个观点是,有时使用不同大小的卷积核的组合是有利的。在本节中,我们将介绍一个稍微简化的 GoogLeNet 版本。
二、Inception 块
在 GoogLeNet 中,基本的卷积块被称为 Inception 块,其结构如下:

Inception 块由四条并行路径组成。 前三条路径使用窗口大小为 1 × 1 1\times1 1×1、 3 × 3 3\times3 3×3 和 5 × 5 5\times5 5×5 的卷积层,从不同空间大小中提取信息。中间的两条路径在输入上执行 1 × 1 1\times1 1×1 卷积,以减少通道数,从而降低模型的复杂性。第四条路径使用 3 × 3 3\times3 3×3 最大汇聚层,然后使用 1 × 1 1\times1 1×1 卷积层来改变通道数。这四条路径都使用合适的填充来使得输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上进行连接,并构成 Inception 块的输出。
可以看出,Inception 块只改变输入的通道数而不改变其高和宽。
在 Inception 块中,通常调整的超参数是每条路径的输出通道数。
设四条路径从左往右的输出通道参数分别为 c 1 , c 2 , c 3 , c 4 c_1,c_2,c_3,c_4 c1,c2,c3,c4。因第一条路径只有一个卷积层,所以 c 1 c_1 c1 是一个标量。而第二、三条路径各有两个卷积层,因此 c 2 , c 3 c_2,c_3 c2,c3 各是元组(大小为 2)。由于最大池化不影响通道数,因此 c 4 c_4 c4 也是标量。
Inception 块的代码实现如下:
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4):
super().__init__()
self.path_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
self.path_2 = nn.Sequential(
nn.Conv2d(in_channels, c2[0], kernel_size=1),
nn.ReLU(),
nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1),
)
self.path_3 = nn.Sequential(
nn.Conv2d(in_channels, c3[0], kernel_size=1),
nn.ReLU(),
nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2),
)
self.path_4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, c4, kernel_size=1),
)
def forward(self, x):
output_1 = F.relu(self.path_1(x))
output_2 = F.relu(self.path_2(x))
output_3 = F.relu(self.path_3(x))
output_4 = F.relu(self.path_4(x))
return torch.cat((output_1, output_2, output_3, output_4), dim=1)
三、GoogLeNet 架构
GoogLeNet 架构如下:

其实现如下:
class GoogLeNet(nn.Module):
def __init__(self):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_3 = nn.Sequential(
Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, 10),
)
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
return x
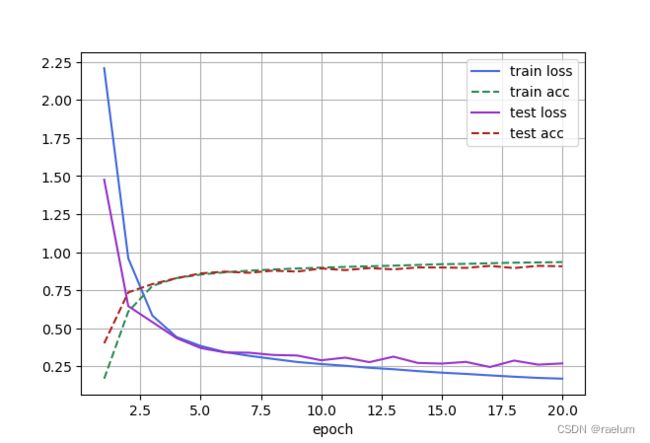
四、训练/测试 GoogLeNet
GoogLeNet 模型的计算复杂,而且不如 VGG 那样便于修改通道数。 为此,我们将输入的高和宽从 224 降到 96,这简化了计算。
使用 FashionMNIST 数据集,设置 batch size 为 128,学习率为 0.07,在 NVIDIA GeForce RTX 3090 上训练 20 个 Epoch 的结果如下:
Epoch 20
--------------------------------------------------
Train Avg Loss: 0.168895, Train Accuracy: 0.935033
Test Avg Loss: 0.269051, Test Accuracy: 0.907700
--------------------------------------------------
3514.5 samples/sec
--------------------------------------------------
Done!
附录:完整代码
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor, Resize
from Experiment import Experiment as E
from torch.nn import functional as F
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4):
super().__init__()
self.path_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
self.path_2 = nn.Sequential(
nn.Conv2d(in_channels, c2[0], kernel_size=1),
nn.ReLU(),
nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1),
)
self.path_3 = nn.Sequential(
nn.Conv2d(in_channels, c3[0], kernel_size=1),
nn.ReLU(),
nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2),
)
self.path_4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, c4, kernel_size=1),
)
def forward(self, x):
output_1 = F.relu(self.path_1(x))
output_2 = F.relu(self.path_2(x))
output_3 = F.relu(self.path_3(x))
output_4 = F.relu(self.path_4(x))
return torch.cat((output_1, output_2, output_3, output_4), dim=1)
class GoogLeNet(nn.Module):
def __init__(self):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_3 = nn.Sequential(
Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, 10),
)
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
return x
def init_net(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
transformer = torchvision.transforms.Compose([Resize(96), ToTensor()])
train_data = torchvision.datasets.FashionMNIST('/mnt/mydataset', train=True, transform=transformer, download=True)
test_data = torchvision.datasets.FashionMNIST('/mnt/mydataset', train=False, transform=transformer, download=True)
train_loader = DataLoader(train_data, batch_size=128, shuffle=True, num_workers=4)
test_loader = DataLoader(test_data, batch_size=128, num_workers=4)
googlenet = GoogLeNet()
googlenet.apply(init_net)
e = E(train_loader, test_loader, googlenet, 30, 0.07)
e.main()
e.show()