pytorch(五)——笔记
目录
- 1.经典卷积网络
-
- 1.1 ImageNet
- 1.2 VGG
- 1.3 GoogLeNet
- 1,4 Stack more layers?
- 2.深度残差网络
-
- 2.1 The residual module
- 2.2 Deeper residual module
- 2.3 代码实现
1.经典卷积网络
1.1 ImageNet
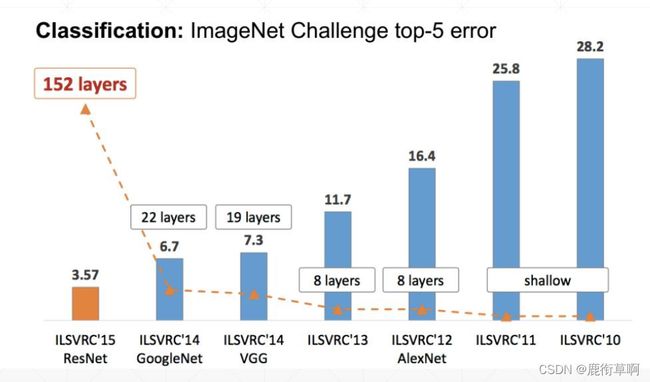
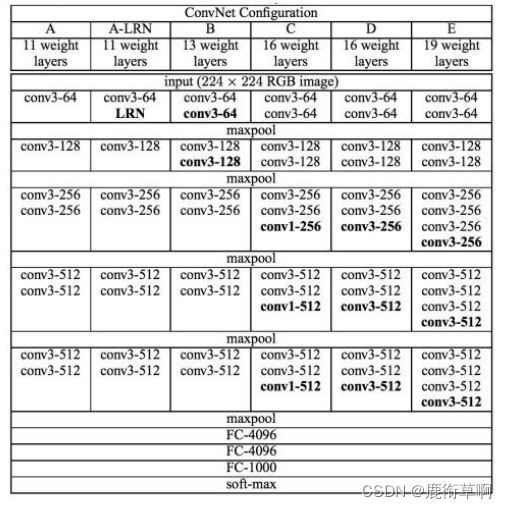
1.2 VGG
VGG网络层
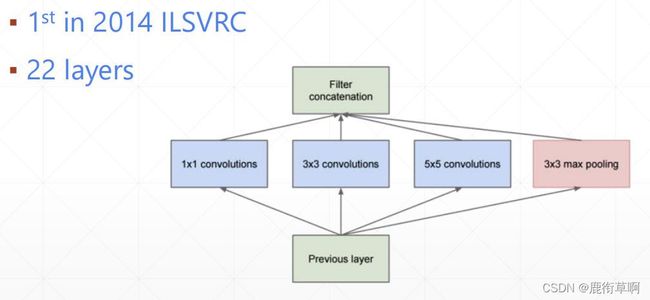
1.3 GoogLeNet
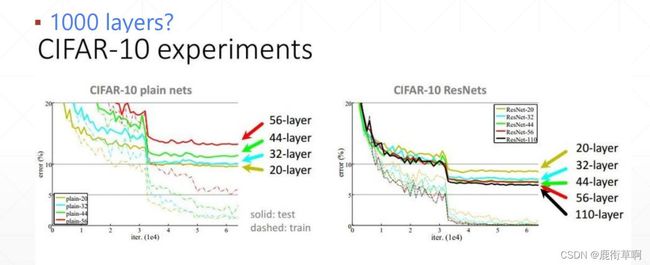
1,4 Stack more layers?
2.深度残差网络
2.1 The residual module
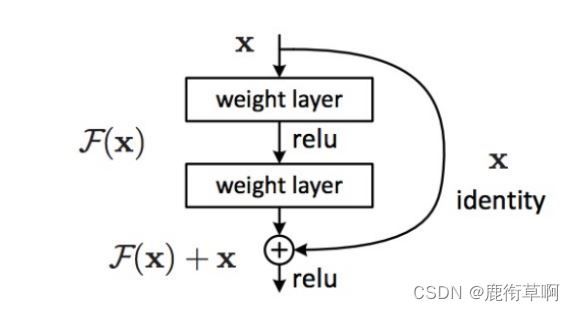
2.2 Deeper residual module
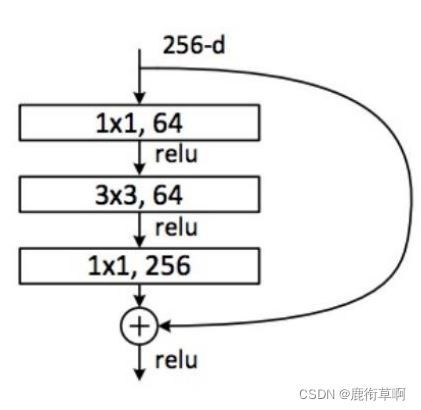
2.3 代码实现
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
# from torchvision.models import resnet18
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=1),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
return out
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16)
)
# followed 4 blocks
# [b, 64, h, w] => [b, 128, h ,w]
self.blk1 = ResBlk(16, 16)
# [b, 128, h, w] => [b, 256, h, w]
self.blk2 = ResBlk(16, 32)
# # [b, 256, h, w] => [b, 512, h, w]
# self.blk3 = ResBlk(128, 256)
# # [b, 512, h, w] => [b, 1024, h, w]
# self.blk4 = ResBlk(256, 512)
self.outlayer = nn.Linear(32*32*32, 10)
def forward(self, x):
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x))
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x)
x = self.blk2(x)
# x = self.blk3(x)
# x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
batchsz = 32
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
x, label = iter(cifar_train).next()
print('x:', x.shape, 'label:', label.shape)
device = torch.device('cuda')
# model = Lenet5().to(device)
model = ResNet18().to(device)
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
for epoch in range(1000):
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tensor scalar
loss = criteon(logits, label)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
#
print(epoch, 'loss:', loss.item())
model.eval()
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
# print(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()