SMILES, a Chemical Language and Information System.【SMILES, 一种化学语言和信息系统。】
文章目录
- 1.介绍
- 2.SMILES:目标和方法
- 3.SMILES:规范规则
-
- (1)原子。
- (2)边
- (3)树枝。
- (4) 循环结构
- (5) 断开的结构。
- (6)芳香性。
- 4. 基本的SMILES
- 5.SMILES符号惯例
-
- (1) 氢特殊化。
- (2) 键/边
- (3) 互变异构体。
- (4) 芳香度检测
- (5) 含有芳香族氮的化合物。
- (6) 芳香族和非芳香族化合物的示例。
- 6.讨论
SMILES(Simplified Molecular Input Line Entry System 简化分子输入行输入系统)是为现代化学信息处理而设计的化学符号系统。基于分子图论的原理,SMILES允许通过使用非常小且自然的语法进行严格的结构说明。SMILES符号系统也非常适合高速机器处理。由此产生的化学家易用性和机器兼容性允许设计许多高效的化学计算机应用程序,包括生成独特的符号、恒定速度(零阶)数据库检索、灵活的子结构搜索和性能预测模型。
1.介绍
化学形式化的第一步是给化合物命名。对于最简单的原子到最复杂的结构,这需要一个明确且可重复的符号。所有其他化学信息程序都遵循化学命名的基本过程。因此,化学符号的改进一直是一项持续的努力,在本期刊的第页中有充分的记录。Wisweser1描述了化学命名法的历史发展,从作为一门基础科学的化学开始到计算机时代的开始。当计算机开放化学信息的处理和存储时,这取决于对化学结构的描述。Morgan开发了一种生成独特机器描述的技术,该技术遵循CAS(化学文摘服务)在线搜索系统。其他重要的进展是图论在化学符号和化学子结构搜索系统中的应用。[8]还从理论角度考虑了化学信息的唯一性。
随着计算机的引入,直线符号在化学术语中得到了广泛应用,因为计算机可以相对轻松地处理线性数据串。线条符号是国际纯化学和应用化学联合会(IUPAC)符号系统的基础。Read以与图论概念相关的一般术语对其进行了描述。Read列出了化学编码系统中被认为需要的12种属性。1983年,这些属性中有许多是互不兼容的。然而,在接下来的几年里,计算机技术的进步已经加快,因此它们正在克服化学信息的增量增长。计算机技术和化学知识现在可以在现有硬件上存储所有现存的化学信息。仅仅让机器存储信息的化学信息问题在很大程度上是历史问题。当前和未来的努力必须着眼于建立高效的系统 根据需要提供化学相关信息。为此,基于新的信息系统SMILES(简化分子输入线系统),正在开发一种新的化学语言和辅助计算机程序。本文介绍了SMILES系统使用的方法和编码规则。
2.SMILES:目标和方法
SMILES是一种化学符号语言,专门为化学家的计算机使用而设计。它很容易被化学家使用,但足够灵活,可以独立于使用中的特定计算机系统来解释和生成化学符号。与传统的化学记数法类似,它通过更快的速度和更好地利用计算机容量,改进了传统的软件方法。分子结构是唯一和准确的规定,可以用于化学数据库。在计算机化化学符号的几种方法中,线符号很受欢迎,因为它用一系列线性符号来表示分子结构,类似于自然语言。Wisweser线符号是该方法最广泛使用的代表。**它满足确定性化学符号的基本要求,但很难使用,因为必须遵循许多规则才能生成复杂结构的正确符号。**为了克服这个和其他困难,SMILES系统被设计成真正的计算机交互系统。它的简单使用是基于严格记录化学用户输入的计算机程序。这是实现以下原始目标的结果:
(1) 一个化学结构的图形将被唯一地描述,包括但不限于由节点(原子)和边(键)组成的分子图形。
(2)将提供一个用户友好的结构规范,以便快速自然地学习所有输入规则。
(3)将设计一个机器友好且独立于机器的系统,用于解释和生成独特的符号。
与其他化学符号系统不同,符号的简洁性和字母表的经济性并不是主要目标。其他线条符号中的许多缺陷可归因于过度使用符号和基于最终符号长度的等级规则。计算机硬件的进步使这些限制过时了。目前的方法将明确但一般的化学结构描述(由化学家用户)与独特结构描述的生成(由计算机)分开。后者需要规则和等级制度,这对化学家来说是固有的困难。因此,这项任务只能由计算机算法来完成。
3.SMILES:规范规则
SMILES将分子结构表示为一个图形,该图形本质上是化学家用来描述分子的二维价取向图。这是化学结构的一个重要简化。没有人试图表示原子的任何特定三维排列。
SMILES符号是以空格结尾的一系列字符。氢原子可以省略(氢抑制图)或包含(氢完整图)。芳香结构优先于Kekulé形式直接指定。
下面几节给出了为几乎任何化学结构生成SMILES的规则。讨论将限于规定化学结构的规则;异构体、子结构和独特的SMILES生成是以下论文的主题。
(1)原子。
原子由原子符号表示;这是SMILES中唯一需要使用的字母。每个非氢原子由方括号中的原子符号独立指定。两个字符符号中的第二个字母必须用小写字母输入。“有机子集”中的元素B、C、N、O、P、S、F、Cl、Br和I,如果所附氢的数量符合与显式键一致的最低正常价,则可以不加括号地写入。芳香环中的原子用小写字母表示;如,普通碳用字母C表示,芳香碳用字母c表示。由于没有括号就意味着附加氢,以下原子符号是有效的符号。
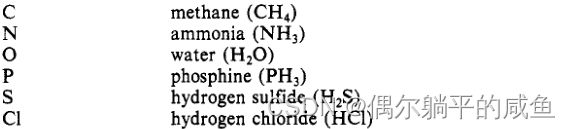
不在有机子集中的元素必须用括号描述,例如。 ![]()
附加氢和正式电荷总是在括号内指定。附加氢的数量由符号H和可选数字表示。类似地,正式电荷由符号+或-,后跟可选数字之一表示。如果未指定,则假定括号内的原子附着的氢和电荷数为零。例如 
SMILES程序还将[Fe++]形式的构造识别为[Fe+3]形式的同义词。
(2)边
单键、双键、三键和芳香键分别用符号-、=、#和:来表示。单键和芳香键可以省略,通常也可以省略。 例如

对于线性结构,SMILES符号对应于传统的图解符号,但氢可以省略。例如,6-羟基-1,4-己二烯可以用三个同样有效的SMILES表示:
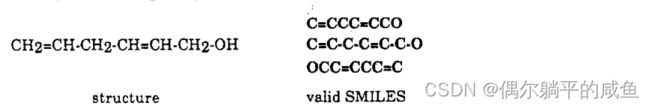
(3)树枝。
分支由括号中的附件指定。例如
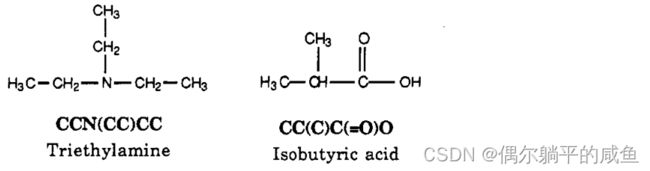
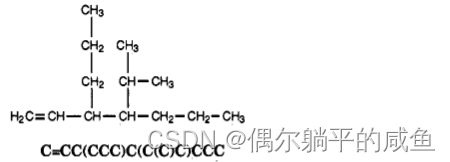
分支可以嵌套或堆叠,如3-丙基-4异丙基-1-庚烯所示:
(4) 循环结构
环状结构由每个环中的一个单键(或芳香键)断裂来表示。这些键按任意顺序编号,在每个环闭合处原子符号后面紧跟一个数字,表示开环(或闭环)键。这就留下了一个连通的非循环图,它通过使用上述三个规则被写成一个非循环结构。环己烷就是一个典型的例子:

同一结构通常有许多不同但同样有效的描述,例如,1-甲基-3-溴代环己烯的以下SMILES符号: 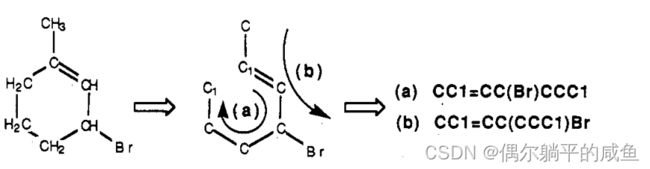
对于相同的结构,可以编写许多其他符号,这些符号来自不同的环闭包。SMILES在输入时没有首选条目;虽然上面的(a)可能是最简单的,但其他的也同样有效。 单个原子可能有多个闭合环。立方烷的结构说明了这一点,其中两个原子有两个以上的闭环: 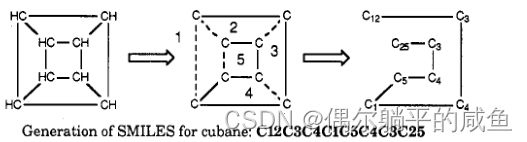
如果需要,可以重复使用表示环闭包的数字。从左到右读取时,环在第一个匹配数字处闭合,可以重复使用而不会产生歧义。例如,数字1在以下规范中使用了两次: 
重复使用环闭包数字的能力使指定具有10个或更多环的结构成为可能。需要同时打开10个以上的环形密封圈的结构极为罕见。如有必要或需要,可通过在两位数前加百分号来指定编号更高的环闭包。例如,带有环封2、13和24的碳纤维将被写入C2%13%24。
(5) 断开的结构。
断开连接的化合物被写成单个结构,由一个句点分隔。离子或配体的排列顺序是任意的。
这并不意味着一个电荷与另一个电荷配对,也不一定要有净零电荷。如果需要,可以将一种离子的SMILES嵌入另一种离子中,如苯酚钠示例所示。
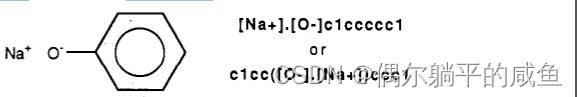
(6)芳香性。
芳香结构可以通过以小写字母书写芳香环中的原子来区分,例如苯甲酸。

正如将要更详细地讨论的,SMILES系统自动检测芳香性,因此等效非芳香结构(如O=C(0)Cl=CC=CC=Cl)的输入将在内部转换为SMILES标准形式。
根据以上简单的规则,几乎所有的有机结构都可以用直线表示法来描述。图1中吗啡的结构更为复杂。它包含五个环,其中一个是芳香的。图中显示了环原子符号上的数字表示的环断裂和环闭合。在环闭合处,1和5个芳香族碳原子用小写字母c表示。
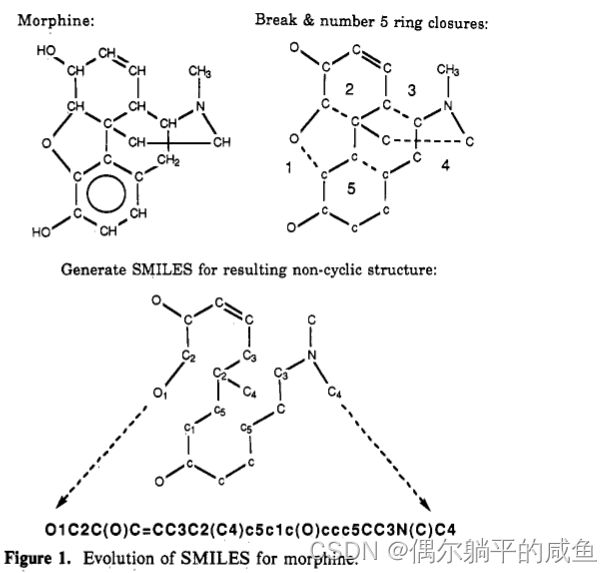
4. 基本的SMILES
尽管SMILES规则很简单,但对于绝大多数有机化合物来说,一个更简单的四个规则子集就足够了。尽管SMILES允许直接指定电荷、附加氢和芳香性,但通常不需要它们。该子集仅使用符号H、C、N、O、P、S、F、Cl、Br、I和(,)以及数字,并遵循以下四条规则:
(1)原子由原子符号表示。
(2) 双键和三键分别用=和#表示。
(3) 分支用括号表示。
(4) 环形闭包由附加到符号的匹配数字表示。
5.SMILES符号惯例
为吗啡建立SMILES符号的过程(图1)显示了SMILES语言用于指定化学结构的简单性、灵活性和一致性。SMILES的灵活性反映了化学中的多样性。为了提供一个统一的符号系统,通过规定某些类别化合物的SMILES书写应遵循的一些约定,对SMILES规则进行了改进。这些包括键规格、某些氮环化合物中的氢规格,以及涉及芳香性的其他因素。
(1) 氢特殊化。
写SMILES时,通常不需要指定氢原子。除特殊用途外,SMILES系统将氢附着视为非氢原子的一种性质。附加氢的数量可以用三种方式来确定:
①对于没有括号的原子,根据正常价假设隐含地确定;
② 明确地按计数,对于括号内指定的原子,按提供的氢计数(如果未指定,则为零);
③作为显式原子,作为SMILES中的[H]原子。关于隐式氢附着的SMILES约定假设氢构成原子最低正常价的剩余部分,这与显式键规范一致。B、C、N、O和卤素的单一正价态分别为3、4、3、2和1。“最低正常价”指磷的3或5,脂肪族硫的2、4或6。例如,这确保0S(=0)(=0)0被解释为H2S04(硫酸),而S被解释为H2S(硫化氢)。给予一对孤对的芳香族硫的形式价为3或5。
即使指定为显式原子,SMILES系统也会移除所有氢原子,只保留附着的氢原子数。从这个计算机程序可以生成一个氢完整的图表,只要需要。从分子图中消除氢使化学家和机器的任务更容易,主要是因为要处理的原子更少。
氢抑制公约几乎没有例外,最明显的是质子[H+]和分子氢[H][H]的规范,也有一些应用需要对一个以上的氢键进行一般规范,例如在晶体学数据库中。SMILES系统中使用的规则是消除所有氢原子,但以下三种情况除外:
①与其他氢相连的氢;
②与零个或多个其他原子相连的氢;
③在同分异构体、同位素氢规范中,例如[2H],在这些情况下,氢被保留,并与任何其他原子一样被处理,只是它们的氢计数始终为零。为完整起见,此处包含案例3;异构化SMILES在本文中没有涉及。
(2) 键/边
SMILES中的四个基本键是单键、双键、三键和芳香键。离子“键”不是直接指定的;带有正式电荷的独立部分被写为一个断开连接的结构。当需要时,原子可以连接起来,并且仍然显示电荷分离。然而,有几种债券并不容易归入上述类别。有时,键具有共价和离子特性的混合特性。这种联系可以用几种方式表示,但对于数据库应用程序,有必要选择一种描述并遵循它。在大多数有机化合物中,键是共价的,因此,对于有机化合物和共价无机化合物,键类型的选择很简单。离域键,如硝基部分,最好以共价键形式与两个不带电的氧原子结合,如硝基甲烷,CN(=0)=0。这是这是惯例,因为硝基甲烷也可以写成有效的电荷分离结构,C[N+](=0)[0-]。不带电形式的优点是它保持了正确的拓扑对称性。当对称性不是一个问题时,如果电荷分离结构避免代表不寻常价态的原子,则首选它们。例如,重氮甲烷写为C=[N+]=[N-],优先于C=N=[N]。
“有机”和“无机”术语之间没有区别。人们可以明确地指定任何形状的原子所附着的氢的数量。然而,必须在括号内指定氢含量;默认值为零。例如,丙烷可以输入为[CH3][CH2][CH3],而不是CCC。
(3) 互变异构体。
互变异构结构在SMILES中被明确描述。没有“互变异构键”或“流动氢”规范。一个或所有互变异构结构的选择留给用户,并取决于应用。出于数据库和索引的目的,许多作者更喜欢烯醇而不是酮形式。例如,对于结构
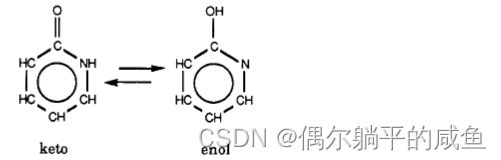 烯醇形式OCLNCCCCl(2-吡啶醇)通常比0=cl[nHjccccl(2-吡啶酮)更受欢迎,但这是一个惯例问题。如果必须选择一种形式表示进行建模,则通常首选更“稳定”的形式。在实际实践中,用于预测建模目的的唯一有效方法是生成所有合理的互变异构形式,并对每种形式进行建模。
烯醇形式OCLNCCCCl(2-吡啶醇)通常比0=cl[nHjccccl(2-吡啶酮)更受欢迎,但这是一个惯例问题。如果必须选择一种形式表示进行建模,则通常首选更“稳定”的形式。在实际实践中,用于预测建模目的的唯一有效方法是生成所有合理的互变异构形式,并对每种形式进行建模。
(4) 芳香度检测
必须在产生明确化学名称的系统中检测芳香性。正如下文将讨论的那样,这对于生成独特的命名法和有效的子结构识别都是必要的。“芳香性”的定义不可能既严格又全面;这个词暗示了对合成化学家的“反应性”,对核磁共振光谱仪的“环电流”,对晶体学家的“对称性”,以及对这个词的最初使用者的“气味”。我们定义芳香性的目的是提供一个自动和严格的定义,以便生成一个明确的化学术语。尽管SMILES算法产生了大多数化学家认为是自然的结果,但这个物理性质的定义并不意味着什么。
给定有效的芳香性检测算法,如果用户更喜欢输入脂肪族(Kekulé样)结构,则无需输入任何芳香结构。以芳香族的形式输入结构,为精确的化学规格提供了捷径,更接近大多数化学家使用的心理分子模型。严格算法重新定义的一个优点是,任何适合用户的有效结构都可以自动转换为标准形式。
SMILES算法能够准确检测绝大多数芳香化合物和离子。系统将接受芳香或非芳香输入规范;它将检测芳香性,并相应地转换输入结构。这是通过扩展版的Hückel规则来识别芳香分子和离子来实现的。13为了符合芳香族的条件,环中的所有原子必须是sp2杂化的,并且可用的“多余”x电子的数量必须满足Hückel的47V+2标准。例如,苯写为ClCCCl,但输入C1=CC=CC=C1(环己烯)——Kekule形式导致检测到aro- maticity并导致内部结构转化为芳香族表征。clcccl和clcccl的条目将分别为环丁二烯和环辛四烯产生正确的抗芳香结构,C1=CC=C1和Cl=CC=CC=CO=C1。在这种情况下,SMILES系统会寻找一种能够保留隐含sp2杂交、隐含氢计数和特定形式电荷(如果有的话)的结构。然而,有些输入可能不仅形式上不正确,而且毫无意义,例如CLCCL。这里的CLCCl与C1=CCC=C1(这是环戊二烯的有效值)不同,因为其中一个碳原子是sp3,带有两个附加氢。在这种结构中,不能交替进行单键和双键分配。SMILES系统会将其标记为“不可能”输入。
SMILES解释器的一个特点是,所有被表示为芳香族的结构(出于唯一符号的目的)都可以自动转换为非芳香族形式(出于建模、与其他系统的兼容性或其他目的)。
(5) 含有芳香族氮的化合物。
为了避免混淆,芳香族氮需要特别注意。在SMILES系统中,有两种芳香族氮化合物可以区分;两者都可以用芳香族氮符号n来表示。典型的例子是吡啶和吡咯:
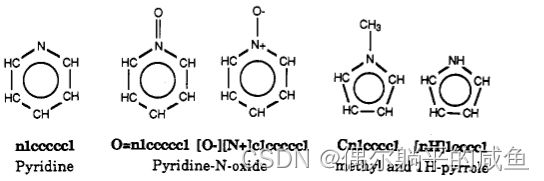
吡啶最好写成NLCCCL;斯迈尔斯正确地推断出吡啶中的氮没有氢,因为两个芳香键满足氮的正常价态。撇开芳香性检测问题不谈,0=NLCCCl(吡啶氮氧化物)中的氮和Cnlccccl(甲基吡咯)中的氮在正常价态下都没有额外氢的价态。然而,在[nH]lccccl(117吡咯)中,氮既是芳香的,也是两个相连的,但有一个附加的氢原子。这在SMILES中通过在括号中写上芳香族n符号来表示,其中可以指定附加的氢。17f吡咯的替代有效输入包括HNLCCCl、[H]NLCCCl,当然还有脂肪族形式N1C=CC=C1;每一个都将转换为正确的内部表示。
(6) 芳香族和非芳香族化合物的示例。
上面给出的SMILES芳香度检测算法的规则非常简单;sp2杂化原子的环具有+2 ir电子,被归类为芳香族。下面将参考示例结构讨论该算法的操作。中性不饱和碳向环中提供一个红外电子,除非它与环外的一个负电原子双键。在这种情况下,碳保留其sp2轨道,但多余的电子无法用于轨道共享。例如,醌是非芳香族的,只有四个多余的电子:

在环中,氧原子和硫原子产生一对孤对,所以furan and thiophene均被视为芳香族(N=1,即6=47V+2)。环内砜被认为是一对孤对,但砜基不能参与正常的红外电子共享。
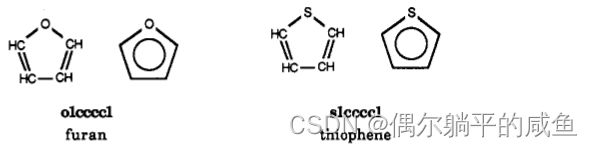
环中不带电的氮可以分别以吡啶基和吡咯基的形式向红外云提供一个或两个电子。至少在这方面,芳香族氮表现良好。例如,吡啶氮氧化物中的氮可以被认为是一种吡啶氮,将其正常的单电子提供给环,或者是一种吡咯氮,将一个电子损失给氧(正常提供的两个电子中,仍有一个电子留给环)。
SMILES还能正确处理带电结构的芳香性。荷电环结构与中性环结构相同,只是环中的正电荷减少或负电荷增加了“多余”红外电子的数量。例如,环戊二烯基阳离子为非芳香族,而环戊二烯酸根阴离子为芳香族。

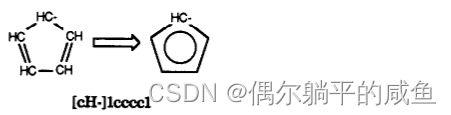
Tropone和tropylium阳离子都是芳香的
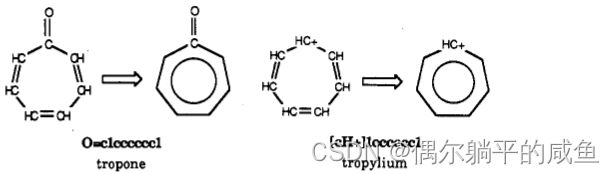
因为羰基碳在一种情况下会“失去”它的电子,而在另一种情况下会“失去”它的电子,从而形成阳离子。
必须特别注意指定每个带电碳上附着的氢的数量。例如,如果苯环的一个电子被移除,形成clccc[cH+]1,这个离子就不是芳香族的,因为只有五个ir电子。但如果除去其中一个氢和一对孤电子,就会形成芳香族苯基阳离子(仍然有六个红外电子):

磷被视为氮,尽管已知的芳香吡咯类磷化合物很少。硒和砷的处理方法与磷和硫类似。除C、N、O、P、S、As和Se以外的元素尚未在芳香族环境中处理。
6.讨论
SMILES被认为是迄今为止人类和机器在化学符号方面的最佳折衷。化学家有许多简单的规则,所以它很容易被理解。在计算上,SMILES以非常快速、紧凑的方式进行解释,从而满足机器节省时间和空间的目标。它基于计算机的语言解析方法,因此机器部分遵循与严格的分层命名规则一致的算法。与传统方法相比,这大大提高了信息处理的效率。
在计算机术语中,SMILES符号表示一棵树,可以在一次传递中进行解释。效率的提高源于语言语法。例如,键的排列由原子的位置暗示,而无需具体定义。因此,如果之前可能需要1000-2000个字符来存储连接表,根据所使用的方法,来描述吗啡等化合物(图1),SMILES将相同的信息存储在40个字符中。还可以表明,与使用连接表格式的常规程序相比,必要的计算机处理时间减少了100倍,例如CAS或MOL连接表中使用的程序。
最初,SMILES是为提供人机界面而开发的。除此之外,它对于实现各种面向机器的化学信息功能也很有价值。成功的应用包括数据存储、结构显示、新结构建模以及子结构搜索和识别。一个例子是在计算模型化合物的分光系数和分子折射率时使用SMILES。这两种性质广泛应用于生化研究。分配系数的对数是哈米特方法中的疏水参数,并已应用于定量结构活性(QSAR)。14基于结构考虑,模拟化合物的碎片,用SMILES术语指定和处理,用于准确估计对数P。
本文旨在介绍SMILES方法,并涵盖将结构输入SMILES系统所需的基本规则。随后的出版物将介绍获取“独特”SMILES的方法,为任何SMILES生成结构描述,生成一个以SMILES为导向的数据库,该数据库以独立于存储多少结构的速度检索信息,以及用于快速而强大的子结构搜索的SMILES方法。
原文地址:https://pubs.acs.org/doi/pdf/10.1021/ci00057a005