最近面试太难了。

在面试数据分析师时,往往会考察一下SQL的掌握程度。
最近有位同学面试了几家,分享了一些觉得有些难度的SQL面试题:比如会让你用SQL实现行转列和列转行操作、用SQL计算留存、用SQL计算中位数、还有如何统计用户最大连续登录天数?
当然这种题变形也很多,连续打卡天数、连续学习天数,连续点击天数等等都是同一个类型,今天我们将会给大家分享SQL和Pandas的多种做法。让大家一次搞懂,下次面试不难!
作者简介
小小明,数据、Python爱好者,CSDN博客专家。个人博客地址:https://blog.csdn.net/as604049322
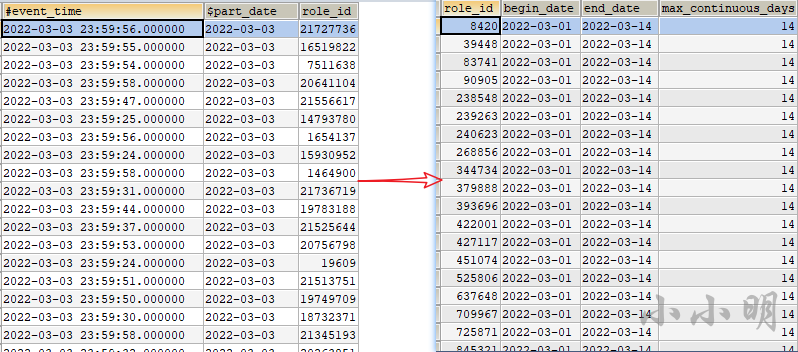
计算每一个用户的最大连续登录天数,由左变换到右边。
SQL 8.0窗口函数
实现思路:
对用户ID和登录日期去重
对每个用户ID按照日期顺序进行编号
将登录日期减去编号对应的天数,使连续的日期转换为同一天
将连续日期转换为同一个日期之后就可以按照这个字段分组,后面就简单了。下面我们一步步看:
对用户ID和登录日期去重:
SELECT DISTINCT role_id,$part_date `date` FROM role_login;对每个用户ID按照日期顺序进行编号,并将登录日期减去该编号对应的天数(可以一步到位):
SELECT
role_id,`date`,
DATE_SUB(`date`,INTERVAL (row_number() OVER(PARTITION BY role_id ORDER BY `date`)) DAY) data_group
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
) a;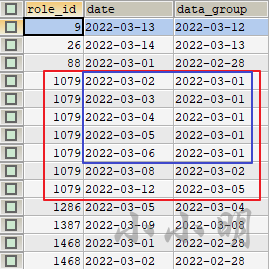
从结果我们可以看到已经成功的使连续的日期都转换到同一天。
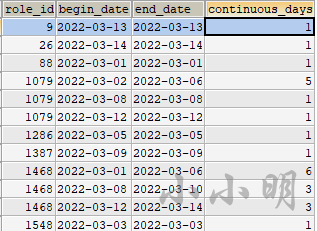
然后我们就可以基于该结果统计每个用户的所有连续日期段:
SELECT
role_id,
MIN(DATE) begin_date,
MAX(DATE) end_date,
COUNT(*) continuous_days
FROM(
SELECT
role_id,`date`,
DATE_SUB(`date`,INTERVAL (row_number() OVER(PARTITION BY role_id ORDER BY `date`)) DAY) data_group
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
) a
) b
GROUP BY role_id,data_group;结果:
然后通过窗口函数标注每个用户的连续日期排名:
SELECT
role_id,begin_date,end_date,
continuous_days ,
row_number() OVER (PARTITION BY role_id ORDER BY continuous_days DESC) rk
FROM(
SELECT
role_id,
MIN(DATE) begin_date,
MAX(DATE) end_date,
COUNT(*) continuous_days
FROM(
SELECT
role_id,`date`,
DATE_SUB(`date`,INTERVAL (row_number() OVER(PARTITION BY role_id ORDER BY `date`)) DAY) data_group
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
) a
) b
GROUP BY role_id,data_group
) c;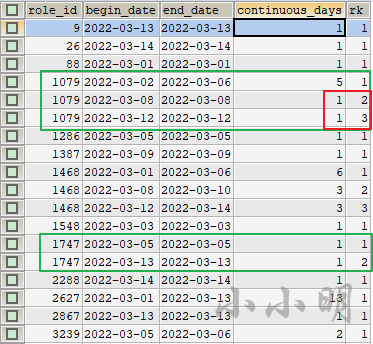
注意:有时同一个用户的最大连续日期可能存在多个,这里以第一个为准;如果需要获取全部的最大日期可以使用
rank或dense_rank窗口函数,可以保证天数一致时排名一致。
完整SQL脚本:
SELECT
role_id,begin_date,end_date,continuous_days max_continuous_days
FROM(
SELECT
role_id,begin_date,end_date,
continuous_days ,
row_number() OVER (PARTITION BY role_id ORDER BY continuous_days DESC) rk
FROM(
SELECT
role_id,
MIN(DATE) begin_date,
MAX(DATE) end_date,
COUNT(*) continuous_days
FROM(
SELECT
role_id,`date`,
DATE_SUB(`date`,INTERVAL (row_number() OVER(PARTITION BY role_id ORDER BY `date`)) DAY) data_group
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
) a
) b
GROUP BY role_id,data_group
) c
) d
WHERE rk=1
ORDER BY max_continuous_days DESC,role_id;成功得到结果:
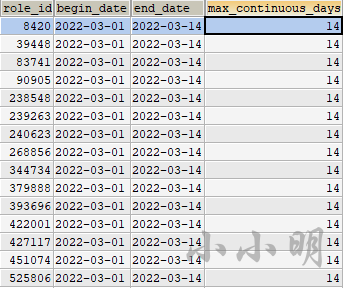
sql变量(5.0也可以使用)
前面方法使用的是SQL 8.0窗口函数,但在低版本sql5.0中并没有窗口函数,如果面试官提出不让用窗口函数,应该怎么办呢?
其实我们可以通过变量来实现,思路仍然与上述相同,首先我们对数据集去重并排序:
SELECT DISTINCT role_id,$part_date `date` FROM role_login
ORDER BY role_id,$part_date;然后利用变量逐行扫描数据集:
SELECT
role_id,`date`,
IF(DATE_ADD(`date`,INTERVAL -1 DAY)=@prev_date,@r,@r:=@r+1) group_id, -- 日期变化大于1天(不连续)改变r值
@prev_date:=`date` -- 记录前一条记录的日期
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
ORDER BY role_id,$part_date
) a,(SELECT @prev_date:=NULL,@r:=0) t;从结果可以看到,对于每个用户下连续的日期都给出了完全相同的分组编号:

然后就可以计算连续天数了:
SELECT
role_id,
MIN(DATE) begin_date,
MAX(DATE) end_date,
COUNT(*) continuous_days
FROM(
SELECT
role_id,`date`,
IF(DATE_ADD(@prev_date,INTERVAL 1 DAY)=`date`,@r,@r:=@r+1) group_id, -- 日期变化大于1天(不连续)改变r值
@prev_date:=`date` -- 记录前一条记录的日期
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
ORDER BY role_id,$part_date
) a,(SELECT @prev_date:=NULL,@r:=0) t
) b
GROUP BY role_id,group_id;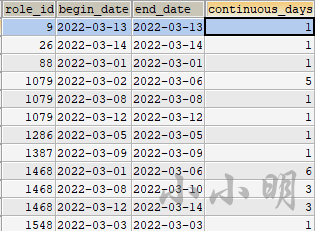
然后借助变量标注排名:
SELECT
role_id,begin_date,end_date,continuous_days ,
IF(@prev_id=role_id,@r2:=@r2+1,@r2:=1) rk,
@prev_id:=role_id -- 记录前一条记录的用户ID
FROM(
SELECT
role_id,
MIN(DATE) begin_date,
MAX(DATE) end_date,
COUNT(*) continuous_days
FROM(
SELECT
role_id,`date`,
IF(DATE_ADD(@prev_date,INTERVAL 1 DAY)=`date`,@r,@r:=@r+1) group_id, -- 日期变化大于1天(不连续)改变r值
@prev_date:=`date` -- 记录前一条记录的日期
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
ORDER BY role_id,$part_date
) a,(SELECT @prev_date:=NULL,@r:=0) t1
) b
GROUP BY role_id,group_id
) c,(SELECT @prev_id:=NULL,@r2:=0) t2
ORDER BY role_id,continuous_days DESC;
可以看到变量已经成功实现了row_number的效果。
最后再进行一次过滤即可:
SELECT
role_id,begin_date,end_date,continuous_days max_continuous_days
FROM(
SELECT
role_id,begin_date,end_date,continuous_days ,
IF(@prev_id=role_id,@r2:=@r2+1,@r2:=1) rk,
@prev_id:=role_id -- 记录前一条记录的用户ID
FROM(
SELECT
role_id,
MIN(DATE) begin_date,
MAX(DATE) end_date,
COUNT(*) continuous_days
FROM(
SELECT
role_id,`date`,
IF(DATE_ADD(@prev_date,INTERVAL 1 DAY)=`date`,@r,@r:=@r+1) group_id, -- 日期变化大于1天(不连续)改变r值
@prev_date:=`date` -- 记录前一条记录的日期
FROM(
SELECT DISTINCT role_id,$part_date `date` FROM role_login
ORDER BY role_id,$part_date
) a,(SELECT @prev_date:=NULL,@r:=0) t1
) b
GROUP BY role_id,group_id
) c,(SELECT @prev_id:=NULL,@r2:=0) t2
ORDER BY role_id,continuous_days DESC
) d
WHERE rk=1
ORDER BY max_continuous_days DESC,role_id;成功得到结果:
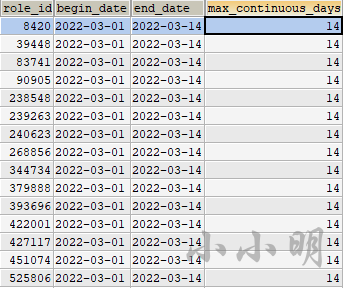
Pandas
下面我们用sql窗口函数的实现思路,用Pandas实现一遍。
首先读取数据集并去重:
import pandas as pd
df = pd.read_excel("role_login.xlsx")
df = df[["role_id", "$part_date"]].drop_duplicates()
df
对每个用户ID按照日期顺序进行编号,并将登录日期减去该编号对应的天数:
data_group = df["$part_date"]-pd.to_timedelta(df.groupby("role_id")["$part_date"].rank(method="dense"), unit='d')统计每个用户的所有连续日期段:
data_group = df["$part_date"]-pd.to_timedelta(df.groupby("role_id")["$part_date"].rank(method="dense"), unit='d')
df = df.groupby(["role_id", data_group], as_index=False).agg(
begin_date=("$part_date", "min"),
end_date=("$part_date", "max"),
max_continuous_days=("$part_date", "count")
)
df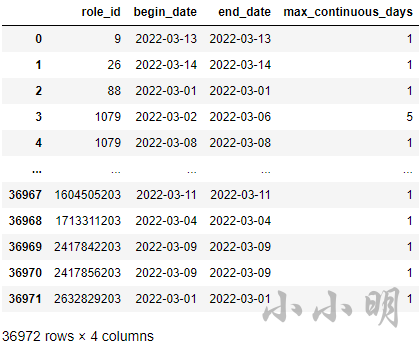
然后我们过滤出每个用户的最大连续日期:
ids = df.groupby("role_id")["max_continuous_days"].idxmax()
r1 = df.loc[ids].sort_values(
["max_continuous_days", "role_id"], ascending=[False, True])
r1按照窗口函数的思路代码如下:
mask=df.groupby("role_id")["max_continuous_days"].rank(method="first", ascending=False) == 1
r2 = df[mask].sort_values(["max_continuous_days", "role_id"], ascending=[False, True])
r2两种思路的结果一致:
(r1 == r2).all()role_id True
begin_date True
end_date True
max_continuous_days True
dtype: bool但是窗口函数的思路相对idxmax快了近百倍,效果如下图所示。
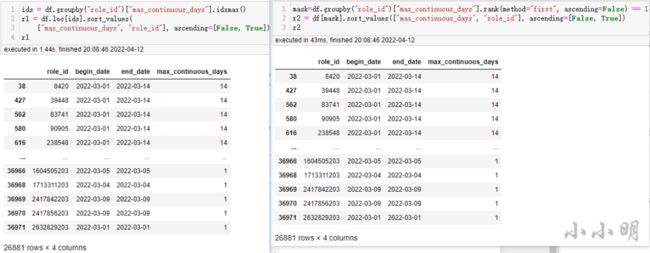
所以针对这取分组最大的问题还是使用rank函数效果更高一些。
RANK、DENSE_RANK差异
本题在一个用户存在多个最大连续日期时只要求取第一个,如果需要取每个用户所有的最大连续日期,则需要使用rank或dense_rank窗口函数。
我们看看Pandas中rank函数的几种method的差异:
import pandas as pd
t1 = pd.DataFrame(data={'num': [2, 4, 4, 8, 8]})
t1['default_rank'] = t1['num'].rank()
t1['min_rank'] = t1['num'].rank(method='min')
t1['max_rank'] = t1['num'].rank(method='max')
t1['dense_rank'] = t1['num'].rank(method='dense')
t1['first_rank'] = t1['num'].rank(method='first')
t1结果:
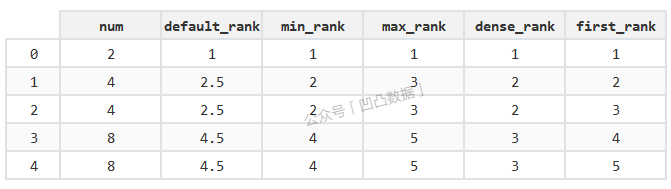
可以看到sql的rank函数相当于Pandas的min_rank,row_number相当于first_rank:
SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM xxm_t2
WHERE cookieid = 'cookie1';结果:

推荐阅读
精进学习SQL的好地方!
⭐超全!120个数据指标与术语。
太强了,10种聚类算法完整Python实现!
⚡Python中“查询”缺失值的4种方法
⚡Python中“处理”缺失值的2种方法
无意中发现的三本【统计学】入门好书
写了100行Python代码,上人民日报了!
2022最新Python神器,出现了!
推荐书籍
最近看了一本书《大数据实践之路:数据中台+数据分析+产品应用》,今天正好介绍一下。
本书共13章,汇集了7位作者(来自多个大型互联网企业)的知识总结和经验分享。本书借助老汤姆、小风等在某电商企业数据部门工作的故事,通过大量案例深入浅出地介绍了数据中台建设与应用之路。如果你是数据产品经理,数据分析师、数据运营人员等数据行业从业者,可以点击链接看看目录是否是自己需要的书籍。


点击这里,阅读更多数据文章!