李宏毅机器学习系列-梯度下降法
李宏毅机器学习系列-梯度下降法
- 梯度下降法回顾
- 调节学习率
- AdaGrad
- 随机梯度下降SGD(Stochastic Gradient Descent)
- 特征缩放(Feature Scaling)
- 梯度下降法的理论(Gradient Descent Theory)
- 梯度下降法的限制
- 帝国时代游戏演示
- 我的世界游戏演示
- 总结
梯度下降法回顾
我们再定义损失函数之后,我们希望损失函数越小越好,于是想要寻找到一组参数 θ ∗ \theta^* θ∗,使得他让损失函数取得的最小值,即:
θ ∗ = a r g min θ L ( θ ) \displaystyle \theta^*= arg \min_{\theta} L(\theta) θ∗=argθminL(θ)
我们假设 θ \theta θ只有两个变量 { θ 1 0 , θ 2 0 } \{\theta_1 ^0,\theta_2^0\} {θ10,θ20},上标代表更新了几次,下标代表第几个变量,我们随机初始化他们得到:

我们定义梯度为:

于是我们进行梯度下降法来更新这两个参数,得到 θ 1 \theta^1 θ1, η \eta η是学习率:
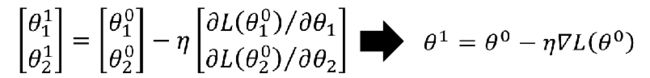
然后继续更新,得到 θ 2 \theta^2 θ2:

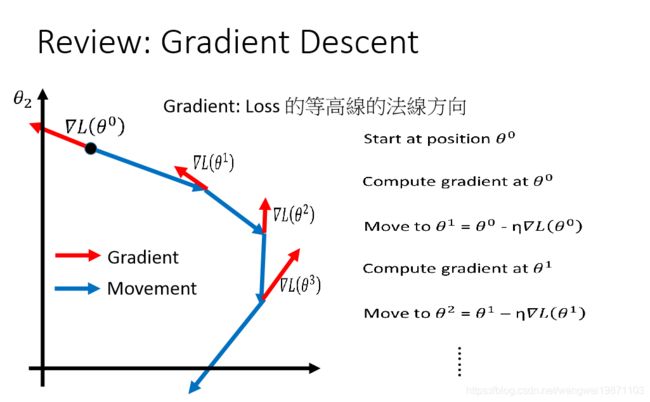
如果我们把他画在图上,看看他是怎么下降的,红色代表梯度向量,蓝色代表下降向量,可以看到下降的方向始终是梯度的反方向,这个可以从公式里面看出来,而梯度的方向是登高线的法线方向,这个是可以证明的,有兴趣的可以看看这篇:
调节学习率
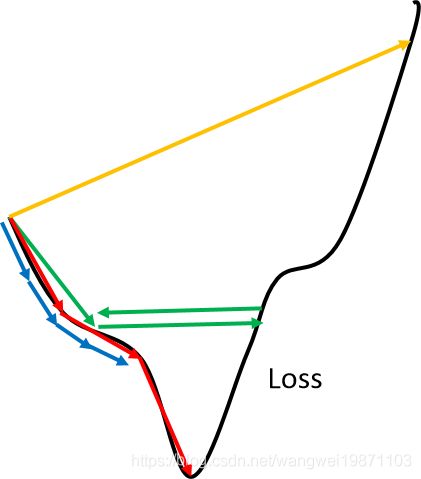
我们可以在二维的环境下可视化学习率和误差的关系,比如下图可以看到,蓝色的为学习率小的,就会下降的比较慢,红色为学习率比较合适的,下降速度快,绿色的为学习率比较大的,就可能出现来回震荡的问题,而黄色属于学习率很大的,直接就发散了,当然这个跟你初始化的位置也关系,运气好可能不会震荡,运气不好开始就发散,具体关于学习率的可视化我也有文章写过,有兴趣的可以看看。
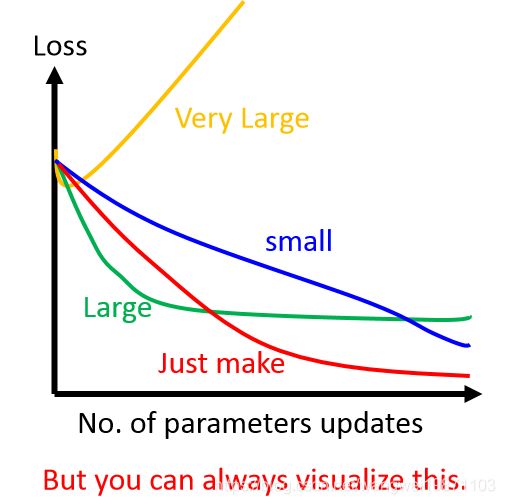
虽然我们再高维中无法绘制学习率和损失的关系,但是我们可以画出迭代次数跟loss的关系,这个跟上图是对应的,我们希望的就是红色的刚刚好的学习率:
那我们选择比较好的学习率呢,手动么,那有点低效啊,所以需要有自适应的学习率,通常我们希望开始的时候学习率大一点,因为可能离最小点比较远,后面越接近希望能小点,以免错过最小点,所以我们用学习率衰减的方式来更新学习率, η \eta η是给定参数,新的学习率 η t \eta^t ηt跟迭代次数t有关系,同时我们还希望每个参数的学习率都不一样,否则就会出现已经走到最小点的参数又被强制给走的:

AdaGrad
我们可以用AdaGrad来进行不同参数的不同学习率更新, η t \eta^t ηt表示第t次迭代后的学习率, g t g^t gt表示第t次迭代后的梯度,他们的定义如下:
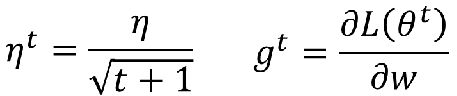
普通的的更新 w t + 1 w^{t+1} wt+1是这样:
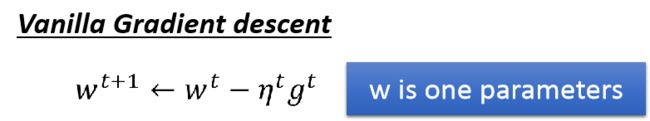
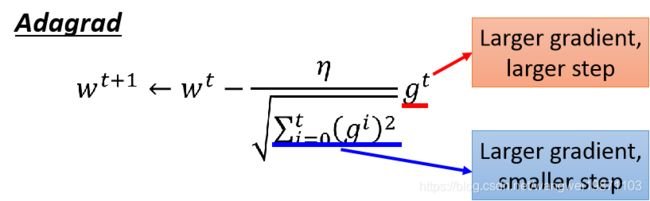
而AdaGrad是这样,多除了一个 σ t \sigma^t σt:

σ t \sigma^t σt定义为之前的所有梯度的平方和的均值的开方:

如果把 η t \eta^t ηt和 σ t \sigma^t σt代入,发现可以消掉一项,然后就只剩下我们指定的 η \eta η和之前所有的梯度平方的和的开方:

但是现在整改式子好像有个比较矛盾的问题,先来看看普通的公式,可以看到,参数更新的大小取决于学习率和梯度,只要梯度越大,应该更新较大:
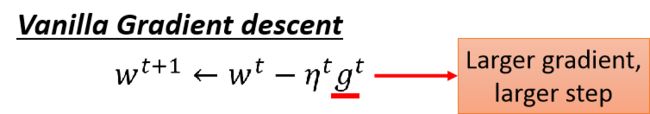
但是AdaGrad的式子却不是这样,分子上是越大更新越大,分母上却是越大更新越小,这个是为什么呢:
一种直觉的解释是为了与之前的梯度大小造成反差,如果这次的比较小,那会变得特别小,如果比较大,就会特别大,产生反差,我也不太明白为什么要这样:

更加真实的解释是这样,我们先考虑一个二次函数 y = a x 2 + b x + c y=ax^2+bx+c y=ax2+bx+c,我们要做梯度下降,那要怎么样的步伐跨出去就最好的呢,看到是一步到位啦,先看他的最低点如图,这个用导数=0即可求出:

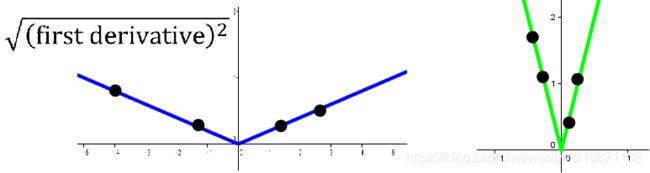
而他的导数的绝对值图像为:

如果我们再二次函数图像上随便取一个点 x 0 x_0 x0,那他到最低点的距离就是 ∣ x 0 + b 2 a ∣ = ∣ 2 a x 0 + b ∣ 2 a |x_0+\frac{b}{2a}|=\frac{|2ax_0+b|}{2a} ∣x0+2ab∣=2a∣2ax0+b∣,而这个分子刚好是导数的绝对值函数在 x 0 x_0 x0的值,因此我们可以认为最好的步伐就是一步跨 ∣ x 0 + b 2 a ∣ |x_0+\frac{b}{2a}| ∣x0+2ab∣到最低点,而这个跨度就是 x 0 x_0 x0的导数的大小,也就是说我们最好的步伐是跟该点的导数大小成正比的,导数越大,我们也应该跨的越大,但是这个只是考虑一个参数的情况下成立:

如果我们有两个参数呢,可以看下下图为loss的等高线图,中间是loss最小的:

如果我们水平方向上来看 w 1 w_1 w1和loss的关系,变化还是比较平滑的,可以看到a的微分大离最小点的距离越远:

如果我们再看 w 2 w_2 w2和loss的关系,变化时比较猛烈的,也是c点微分大,离最小点距离远:

如果我们同时考虑 w 1 , w 2 w_1,w_2 w1,w2,我们观察c的微分比a要大,但是c离最小点的距离没有a的大,所以我们刚才的结论距离和微分正比在多个参数中是不对的,只能用于一个参数。
我们再看前面的结论,最好的跨度为 ∣ 2 a x 0 + b ∣ 2 a \frac{|2ax_0+b|}{2a} 2a∣2ax0+b∣,除了考虑分子的微分之外还有个分母,这个分母的意义是什么呢,其实是2阶微分,因此,我们真正影响最好的跨度的因此有两个,一阶微分和二阶微分,正比于一阶微分的绝对值,反比于二阶微分:
所以对于两个参数的问题,我们可以看到 w 1 w_1 w1方向上的二阶微分比较小, w 2 w_2 w2的比较大,所以考虑到这个,一阶微分大的未必就是最好的步伐:

那这个结论跟AdaGrad有上面关系么,看一看到分子的就是一阶微分,但是分母是以前所有一阶微分的RMS:
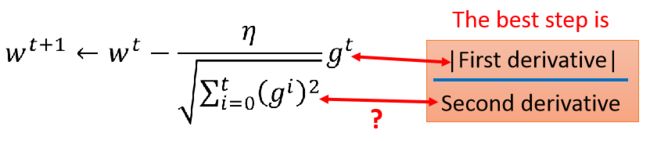
我们会想这个东西跟二阶微分有关系么,当然有,这个可以反映二阶微分的大小,比如如果我们比较两个二阶微分不同的图像,左边的小,右边的大:
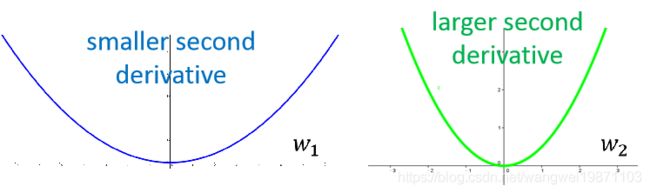
如果我们画出$ \sqrt {g^2} $的图像,然后进行很多的采样,把他们加起来,会发现,如果二阶微分越大和越大,所以这个可以反映二阶微分的大小:
因此AdaGrad在做的事情就是每次都去找到最好的步伐进行参数的更新:
g t ∑ i = 0 t ( g i ) 2 \frac{g^t}{\sqrt {\sum_{i=0} ^t{(g^i)}^2}} ∑i=0t(gi)2gt
前面讲了那么多就是为了解释上面这个式子的意义。
随机梯度下降SGD(Stochastic Gradient Descent)
我们普通的梯度下降法是这样,也可以叫做批量梯度下降:


每次更新要迭代所有的样本才进行一次参数更新,虽然效果很稳定,但是时间很慢,而且样本太多可能内存也不够。所以我们提出了随机梯度下降法:

每次只迭代一个样样本进行一次参数更新,速度就快了,但是这样loss可能会有波动,但是总体来说loss下降的方向是对的。
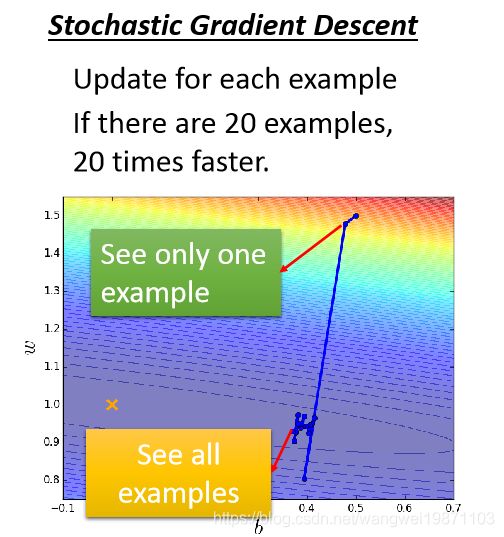
我们可视化分析下,原始的就是非常稳定的朝着最低点前进,但是每次要迭代所有样本才更新一次,走的比较慢:

随机梯度下降,每次就迭代一个样本就更新参数,有多少样本就更新多少此参数,所以走的会比较快,但是也可能会有波动,会散乱,毕竟考虑一个参数可能有噪声引入:
这个有兴趣也可以看我写过相关的可交互可视化文章。
最合适的就是小批量梯度下降啦,刚好在批量和随机之间,具体就不多说了。
特征缩放(Feature Scaling)
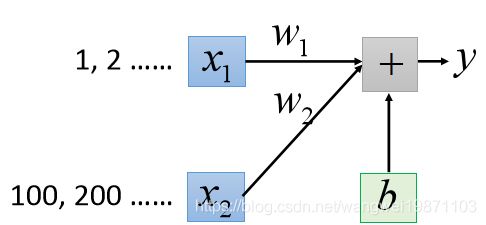
简单来说,就是统一特征的量纲,也就是大小的规格,把他们都归一化,标准化,不然可能会影响梯度下降的速度。假设我们的模型魏 y = b + w 1 x 1 + w 2 x 2 y=b+w_1x_1+w_2x_2 y=b+w1x1+w2x2,原始的数据会有 x 1 , x 2 x_1,x_2 x1,x2大小相差比较大的情况,归一化的就可以统一到0-1了:
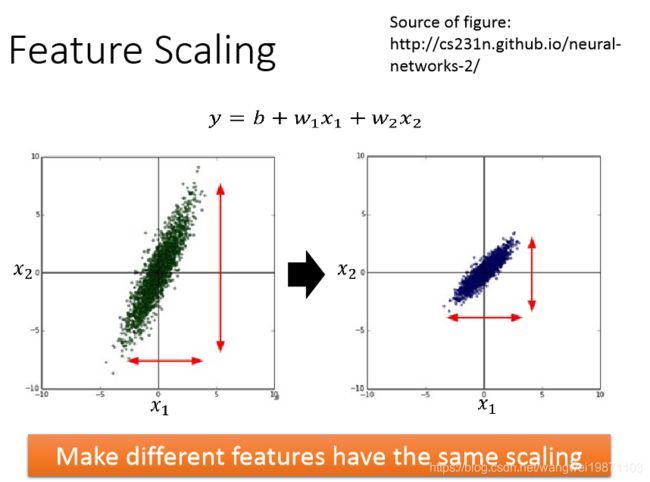
如果我们不归一化,会出现什么问题呢,来简单看个例子 x 1 x_1 x1这边的特征都很小, x 2 x_2 x2特别大,是100倍:
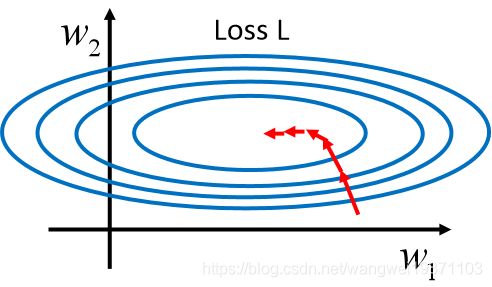
如果我们进行微分,会发现 w 2 w_2 w2的微分都比 w 1 w_1 w1大100倍,从loss的图像上看,就是 w 2 w_2 w2的梯度特别大,破比较陡峭, w 1 w_1 w1的比较小,破比较平滑,所以loss图像在 w 1 w_1 w1方向被拉宽了,但是我们的梯度方向是等高线的法线方向,所有看到他是慢慢绕到最小点去的:
如果进行标准化后,loss图像就类似于一个正圆,可以很快走到最小点,不用绕了,所以训练速度会快很多:

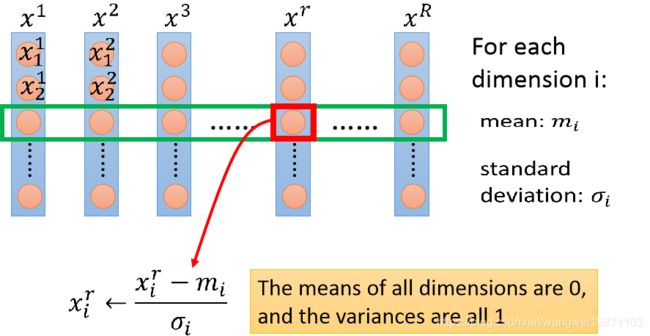
那用什么方法进行特征缩放呢,有很多种,一般就是标准化,归一化,就是把特征都压缩为均值为0,方差为1的分布:
梯度下降法的理论(Gradient Descent Theory)
首先提了个问题,梯度下降法进行中loss一定会下降么,答案当然是否定的啦,前面都讲过啦,学习率调不好,就可能发散了:

我们来看看梯度下降法究竟是怎么一步步走到最小点的,假设我们有一个关于 θ \theta θ的损失函数,有两个参数 θ 1 , θ 2 \theta_1,\theta_2 θ1,θ2,我们画出的loss图就是这样:

然后我们会随机一个初始点比如 θ 0 \theta^0 θ0,然后我们在他的周围一圈内,找到最小的点,然后走过去,比如是 θ 1 \theta^1 θ1,然后继续上面的步骤,找到 θ 2 \theta^2 θ2,一直这样下去,直到找不到最小的,即我们可以到达最小点:
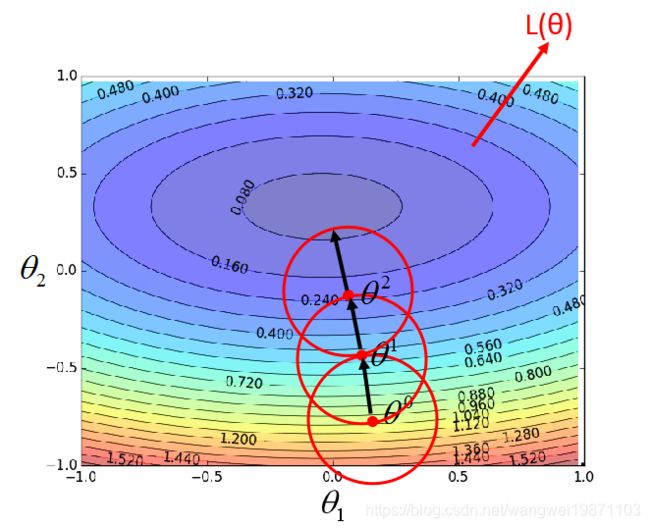
那么问题来了,有上面什么办法可以让我们快速的找到圈范围内的最小点呢,就要用到泰勒级数,泰勒级数可以理解为,如果某个函数在某个点的领域内任意阶可导,则他可以写成导数多项式这样的形式:
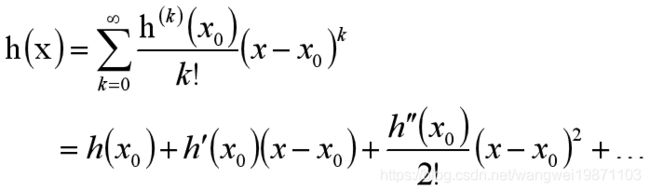
当 x 和 x 0 x和x_0 x和x0无限接近的时候,二次项及其之后的多项式几乎为0了,不需要了:
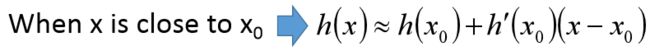
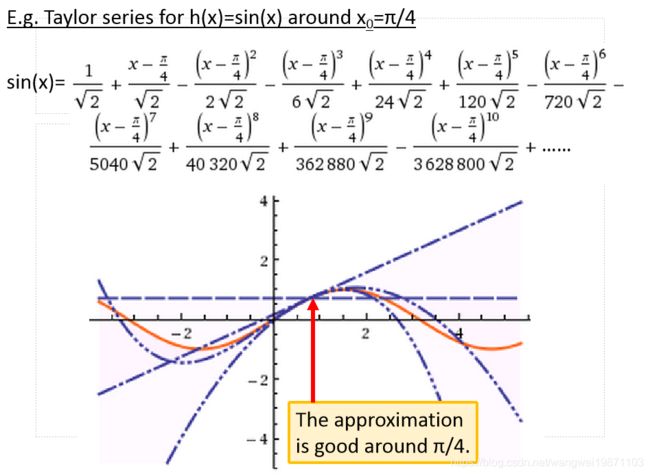
举个y=sin(x)在$x_0=\frac{\pi}{4} $的泰勒级数展开,次数考虑的越多,越能拟合出sin(x):
如果是多个变量,泰勒级数展开也一样:

回到刚才的在范围内找最小点的问题:
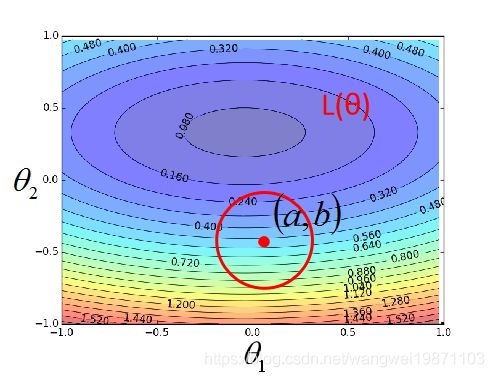
初始点为(a,b),如果红色圈范围足够小的话,loss函数就可以近似为多变量泰勒级数展开:
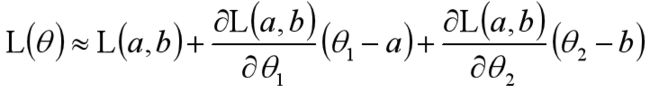
我们设:
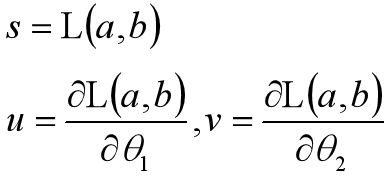
代入后得到:
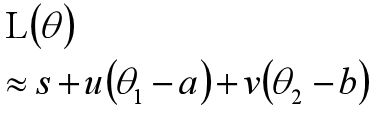
因为s,u,v实常数,于是问题就变成在红色圈内取得L(a,b)的最小值了,即约束条件为:
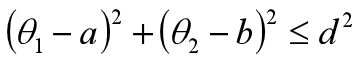
现在我们可以忽略s来求最小值,即:

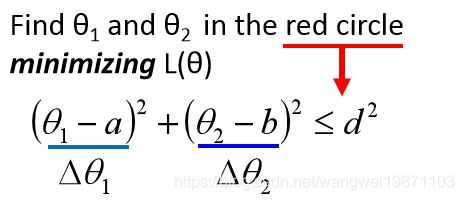
与是我们把问题又转为向量(u,v)点乘( Δ θ 1 , Δ θ 2 \Delta \theta_1,\Delta \theta_2 Δθ1,Δθ2)最小化,两个向量的点乘公式为:
a ⋅ b = ∣ a ∣ ∣ b ∣ c o s θ a \cdot b=|a||b|cos \theta a⋅b=∣a∣∣b∣cosθ, θ \theta θ为夹角,即最小值应该是夹角180度,为-1,所以方向应该是向量(u,v)反方向,大小就是圈的半径,这样是最小的:

于是就可以得到向量( Δ θ 1 , Δ θ 2 \Delta \theta_1,\Delta \theta_2 Δθ1,Δθ2)的表达式, η \eta η为一个系数,就是两个向量的模长比,其中一个是红圈的半径作为分子,因为这个值很小,随意 η \eta η也很小,趋近于0,实际上不是0,但是理论上几乎就是0,所以也就是学习率为什么要那么小的原因:

展开得:

代入u,v得:

这个就是梯度公式啦,但是要记得这个是有条件的,就是红色圈足够小,也就是学习率 η \eta η足够小,使得这个式子成立:
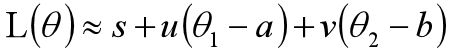
上面这个式子只考虑了泰勒级数的一次微分,能不能考虑二次呢,当然可以,只是这样计算量很大,特别是深度学习里,参数那么多,你去算个海塞矩阵的,几乎要崩溃了,所以相比之下,还是不会去考虑二次微分的。
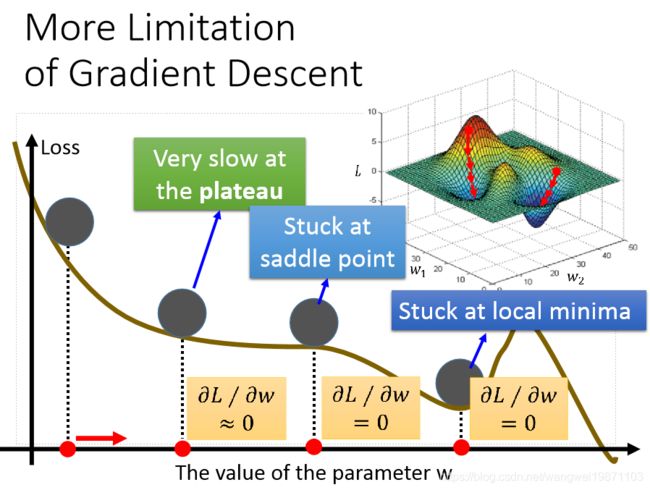
梯度下降法的限制
很多时候我们会发现梯度几乎为0了,不更新了,也许是在局部最小点,也许是在鞍点,也许是学习率非常小的时候,这些都是我们需要解决的问题,比如用带动量的优化方法等等。
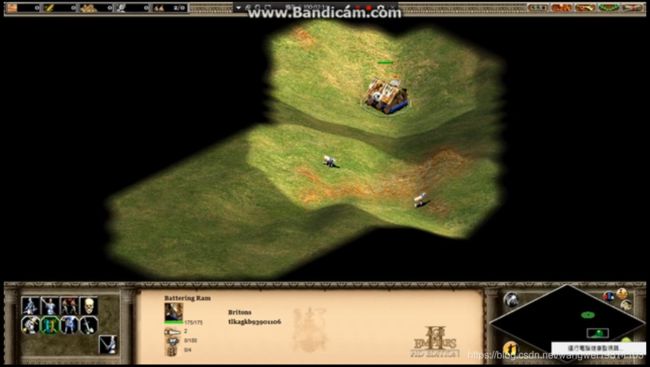
帝国时代游戏演示
用帝国时代演示了梯度下降法是怎么做的,开始我们根本不知道哪个是最低点,我们就好像在迷雾里探险,一步步往比较低的地方走,或许只能走到局部最低点,你没办法知道局部最低点是不是全局最低点,除非你在游戏里开天眼,现实中当然是没办法的:
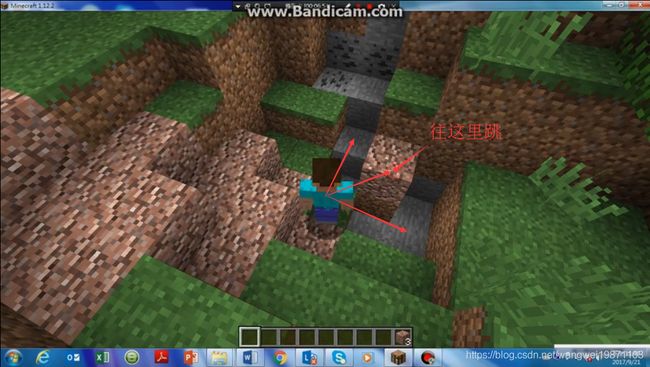
我的世界游戏演示
说明了为什么有时候损失不降低反增加,正常的情况我们要往右前方跳过去,
但是有时候却很尴尬,往高的地方跳了:
总结
介绍了梯度下降法原理和应用,以及相关的优化,AdaGrad的式子的原理,特征压缩,归一化。附上思维导图:

好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件或者网络,侵删。