“Spark三剑客”之SparkCore和SparkSql学习笔记(零基础入门)(一)
目录
1 Spark的介绍
1.1 Spark的定义
1.2 Spark为什么比MapReduce快?
1.3 RDD 弹性式分布式数据集
1.4 MasterURL
1.5 Spark为什么很占内存?
1.6 SparkCount的典型案例(真我瞎写的,非官方)
1.7 spark代码的核心框架(指的是main方法里的)
2 RDD的那些事
2.1 介绍RDD
2.2 Transformation算子
2.2.1 map算子
2.2.2 flatmap算子
2.2.3 filter算子
2.2.4 sample
2.2.5 union
2.2.6 distinct
2.2.7 join
2.2.8 gourpByKey
2.3.9 reduceByKey
2.2.10 sortByKey
2.2.11 mapPartitions
2.2.12 groupByKey
2.2.13 reduceByKey
2.2.14 sortByKey
2.2.15 mapPartitions
2.2.16 coalesce和repartition
2.2.16 mapPartitionWithIndex
2.3 Action算子
2.3.1 foreach
2.3.2 count
2.3.3 take(n)
2.4.4 first
2.3.5 collect
2.3.6 reduce
2.3.7 countByKey
2.3.8 saveAsTextFile和saveAsHadoopFile和saveAsObjectFile和saveAsSequenceFile
2.4 “持久化”操作
2.4.1 spark持久化的含义
2.4.2 如何持久化
2.4.3 持久化策略
2.5 共享变量
2.5.1 广播变量
2.5.2 累加器
3 SparkSQL
3.1.1定义
3.1.2 rdd dataframe dataset
3.2编程入门
3.2.1 JavaBean存入Dataframe
3.2.2 JavaBean存入Dataset
3.2.3 动态编程 这里就拿dataframe做例子
3.3 RDD Dataframe DataSet之间的转换
3.4 读取数据以及数据的转存
3.5 sparksql与hive的整合
3.6 sparksql的自定义函数
3.6.1 自定义udf函数
3.6.2 自定义UDAF函数
1 Spark的介绍
1.1 Spark的定义
它是一个集成了离线计算、实时计算、SQL查询、机器学习、图计算为一体的一站式框架 。
一站式的体现:既可以做离线计算(批处理),也可以做其他的(SQL查询、机器学习、图计算)
flink对于机器学习、图计算支持真的的不太友好哈。
1.2 Spark为什么比MapReduce快?
因为Spark是基于内存计算,Spark运行起来只有一次Suffle,但是MapReduce存在两次Suffle。
1.3 RDD 弹性式分布式数据集
- 弹性式:Spark运行时导致内存溢出,会把数据落地到磁盘上,并不会导致数据丢失。
- 数据集:其实就是一个存放数据的地方,可以认为是一个不可变的Scala集合。
- RDD的特点: 只读、可分区、分布式的数据集。这个数据集全部或者一部分可以缓存在内存中(这里有个小Tips:就是缓存内存就是对RDD做了持久化操作哦),在多次计算时被重用。
- RDD的存在:RDD的计算和数据保存都在Worker上(Spark的集群模式是主从架构,一个Master调度N个Worker)。RDD是分区的,每个分区分布在集群中的不同Worker节点上面,这样的好处就是RDD可以并行式计算。
- RDD的来源:可以读取HDFS或者hive中的数据,也可以自己创建(makeRDD)。
- 有关MapReduce:
- 好处:自动容错、负载均衡、高扩展
- 坏处:采用非循环的数据列模型,进行计算的时候数据迭代进行大量的磁盘IO流。
- 但是Spark避免了MapReduce的坏处,采用血缘追溯,通过执行时产生的有向无环图,找到数据故障的partition,提高容错性。
- 有关RDD的封装:spark2.X版本RDD已经被封装了,我们做开发的时候不会使用rdd,而是直接使用DataSet或者DataFrame进行计算。
1.4 MasterURL
spark编程是通过SparkConf.setMaster传递线程运行的参数,以及是线程采用什么模式
| master | 含义 | |
|---|---|---|
| local | 程序在本地运行,同时为本地程序提供一个线程来处理spark程序 | |
| local[M] | 程序在本地运行,同时为本地程序提供M个线程来处理spark程序 | |
| local[*] | 程序在本地运行,同时为本地程序提供当前计算机CPU Core数个线程来处理spark程序 | |
| local[M,N] |
|
|
| spark://ip:port |
|
|
| spark://ip1:port1,ip2:port2 | 基于Standalone ha模式运行,spark程序提交到ip和port对应的master上运行 | |
| yarn [deploy-mode=cluster] | yarn的集群模式(一般是生产环境中使用)。 基于yarn模式运行,基于yarn的cluster模式,这个程序会被提交给yarn集群中的resourceManager,然后有RM分配给对应NodeMananger执行 |
|
| yarn [deploy-mode=client] | yarn的客户端模式(一般是生产环境中做测试时使用) 基于yarn模式运行,基于yarn的client模式,只会在提交spark程序的机器上运行 |
|
1.5 Spark为什么很占内存?
因为Spark运行的时候,每个job的运行阶段都会存在副本,即使运行完了也依然存在内存中,所以很占用内存。
1.6 SparkCount的典型案例(真我瞎写的,非官方)
idea中的pom.xml
4.0.0 org.example spark_sz2102 1.0-SNAPSHOT 1.8 1.8 UTF-8 2.11.8 2.4.5 2.7.6 2.11 org.scala-lang scala-library ${scala.version} org.apache.spark spark-core_2.11 ${spark.version} org.apache.hadoop hadoop-client ${hadoop.version} src/main/scala net.alchim31.maven scala-maven-plugin 3.2.2 compile testCompile -dependencyfile ${project.build.directory}/.scala_dependencies org.apache.maven.plugins maven-shade-plugin 2.4.3 package shade *:* META-INF/*.SF META-INF/*.DSA META-INF/*.RSA
在resource中放一个log4j.properties
# Set everything to be logged to the console
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
自己创建了一个文档
a.txt的内容
hello word
hello hadoop
hello jdk
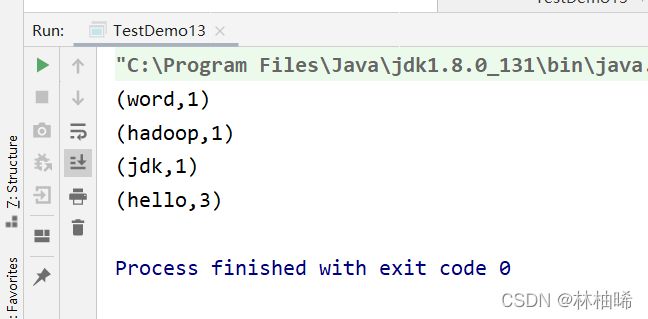
统计的代码
package com.qf.bigdata
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object TestDemo13 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
val lines:RDD[String] = sc.textFile("D:/data/a.txt")
val words:RDD[(String,Int)]=lines.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)
words.foreach(println)
sc.stop()
}
}
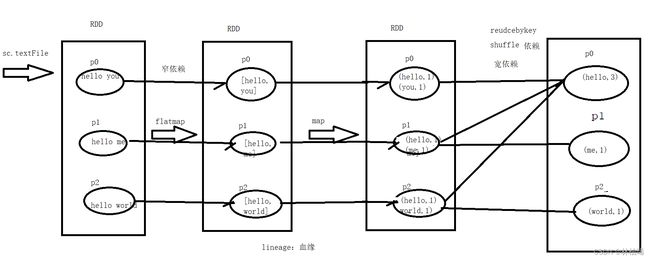
1.7 spark代码的核心框架(指的是main方法里的)
对于countword程序的画图理解
2 RDD的那些事
2.1 介绍RDD
- 每个spark应用程序都包含了一个驱动程序,该程序驱动了功能在集群上执行各种操作。
- RDD只是一个抽象的逻辑定义,不是真实存在的。
- RDD是一个跨集群节点的集合,处理数据可以并行操作。
- RDD可以实现现有的scala集合进行转换创建RDD。
- Spark可以把RDD持久化,并行操作中可以高效复用。
- RDD快速恢复数据是通过血缘追溯,找到分区中的数据故障,快速恢复数据,提高容错性。
- RDD的共享变量:主要是广播变量和累加器。对于不同节点并行运行同一个算子,会把算子中使用的每个变量的副本传送给每个任务,任务之间需要共享变量。
2.2 Transformation算子
2.2.1 map算子
def map[U: ClassTag](f: T => U): RDD[U]
U : 表示f函数的返回值类型
T : 表示RDD中的元素类型的返回值
RDD[U] :通过map算子处理之后的返回类型,返回的RDD[U],这里说明map处理之后返回的是一个新的RDD的副本,RDD的副本中的元素类型是由我们的U类型决定
f : 函数
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val txtRDD:RDD[String] = sc.parallelize(Array(
"hello world",
"hello",
"world"
),2)
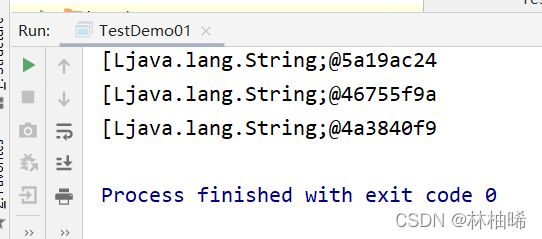
val arrRDD:RDD[Array[String]] = txtRDD.map(_.split("\\s+"))
arrRDD.foreach(println)
}
}
2.2.2 flatmap算子
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
TraversableOnce[U]: 表示f函数的返回值类型,TraversableOnce就把它看作为一个集合即可
U : 表示f函数返回值类型的一个元素的类型
T : 表示RDD中的元素类型的返回值
RDD[U] :通过map算子处理之后的返回类型,返回的RDD[U],这里说明map处理之后返回的是一个新的RDD的副本,RDD的副本中的元素类型是由我们的U类型决定
f:函数
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val txtRDD:RDD[String] = sc.parallelize(Array(
"hello world",
"hello",
"world"
),2)
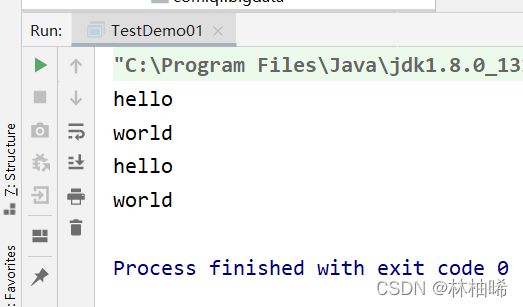
val flatMapRDD:RDD[String] = txtRDD.flatMap(_.split("\\s+"))
flatMapRDD.foreach(println)
}
}
2.2.3 filter算子
def filter(f: T => Boolean): RDD[T]
T : 表示RDD中的元素类型的返回值
f:函数
Boolean:f函数的返回类型
作用:将RDD中的元素过滤,把f函数返回为true的保留。产生一个新的RDD副本
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val txtRDD:RDD[String] = sc.parallelize(Array(
"hello world",
"hello",
"world"
),2)
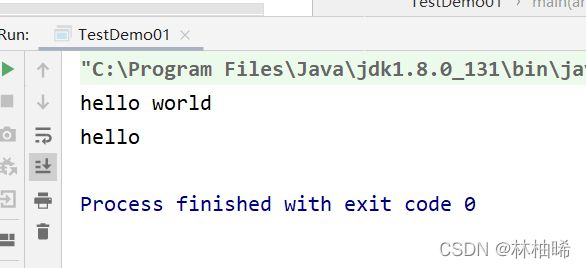
val filterRDD:RDD[String] = txtRDD.filter(_.contains("hello"))
filterRDD.foreach(println)
}
}
2.2.4 sample
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]withReplacement:抽样方式,true有返回抽样,false无返回抽样
fraction:抽样因子/比例,取值范围介于0~1之间
seed:随机数种子
作用:抽样的查询
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())val listRDD:RDD[Int] = sc.parallelize(1 to 1000)
var res: RDD[Int] = listRDD.sample(true,0.01)
println(res.count())
println("_"*10)
res = listRDD.sample(true,0.01)
println(res.count())
println("_"*10)}
}
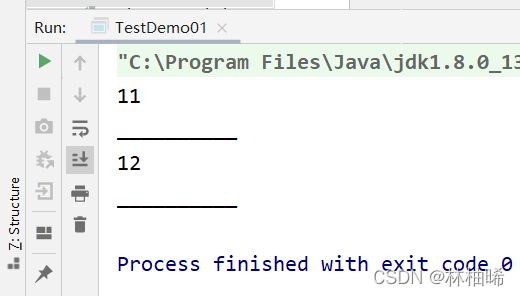
2.2.5 union
def union(other: RDD[T]): RDD[T]
other : 需要进行合并的RDD
返回值:合并之后的RDD
作用:将两个RDD进行合并形成一个新的RDD。类似于SQL中的union all
就是两个rdd元素有一样的也都会出现,不会去重。
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
println("union------------------->")
val listRDD1:RDD[Int] = sc.parallelize(List(1,2,3,4,5))
val listRDD2:RDD[Int] = sc.parallelize(List(5,6,7,8,9,10))
listRDD1.union(listRDD2).foreach(println)
sc.stop()}
}
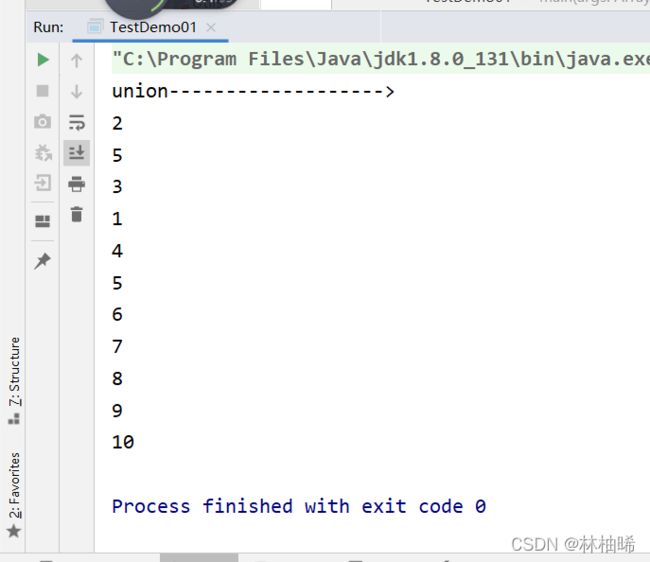
2.2.6 distinct
def distinct(): RDD[T]
作用:将一个RDD中相同的元素剔除,然会一个新的RDD
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
println("union------------------->")
val listRDD1:RDD[Int] = sc.parallelize(List(1,2,3,4,5))
val listRDD2:RDD[Int] = sc.parallelize(List(5,6,7,8,9,10))
listRDD1.union(listRDD2).distinct().foreach(println)
sc.stop()}
}
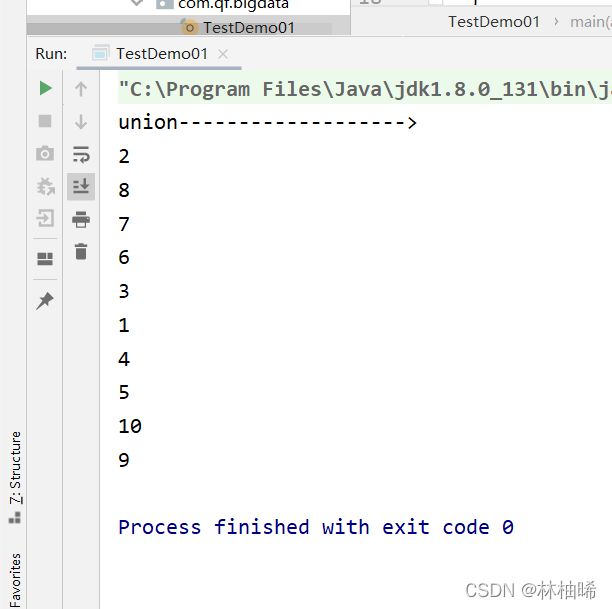
2.2.7 join
一 sql的join
1. 交叉查实训
select * from A a accross join B b; 这种方式会产生笛卡尔积,在工作中一定要避免2. 内连接
select * from A a [inner] join B b [where|on a.id = b.id];3. 外连接
3.1 左外 : 查询到所有的左表数据,右边要符合条件
select * from A a left [outer] join B b on a.id = b.id];3.2 右外 : 查询到所有的右表数据,左边要符合条件
select * from A a right [outer] join B b on a.id = b.id];3.3 全外 : 两边表都能查询
select * from A a full [outer] join B b on a.id = b.id];3.4 左半连接 :一般在工作中不用
二 spark的join
e.g. 假设RDD1[K,V], RDD2[K,W]1. 内连接
val innerRDD[(K,(V, W))]rdd1.join(rdd2)2. 左外
val leftRDD[(K,(V, Option(W)))]rdd1.leftOuterJoin(rdd2)3. 右外
val rightRDD[(K,(Option(V), W))]rdd1.rightOuterJoin(rdd2)4. 全外
val fullRDD[(K,(Option(V), Option(W))]rdd1.fullOuterJoin(rdd2)
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val stuList = List(
"1 刘诗诗 女 18",
"2 欧阳娜娜 女 55",
"3 李冰冰 女 33",
"4 蒋勤勤 女 34",
"6 王冰冰 女 11"
)
val subjectList = List(
"1 语文 79",
"1 数学 0",
"1 体育 99",
"2 语文 69",
"2 数学 10",
"2 英语 89",
"2 体育 19",
"3 语文 79",
"3 数学 69",
"3 英语 99",
"4 语文 19",
"4 数学 40",
"4 英语 69",
"4 艺术 40",
"5 语文 69",
"5 数学 69"
)
val stuRDD:RDD[String] = sc.parallelize(stuList)
val subjectRDD:RDD[String] = sc.parallelize(subjectList)
//join算子只有在二维元组才能使用
//下面这个是对sturdd的id和其余信息切割,然后做成了一个元组
val sid2StuInfoRDD:RDD[(Int,String)] = stuRDD.map(line =>{
val sid = line.substring(0,line.indexOf(" ")).toInt
val info = line.substring(line.indexOf(" ") + 1)
(sid,info)
})
//下面这个代码是测试切割效果
sid2StuInfoRDD.foreach(println)
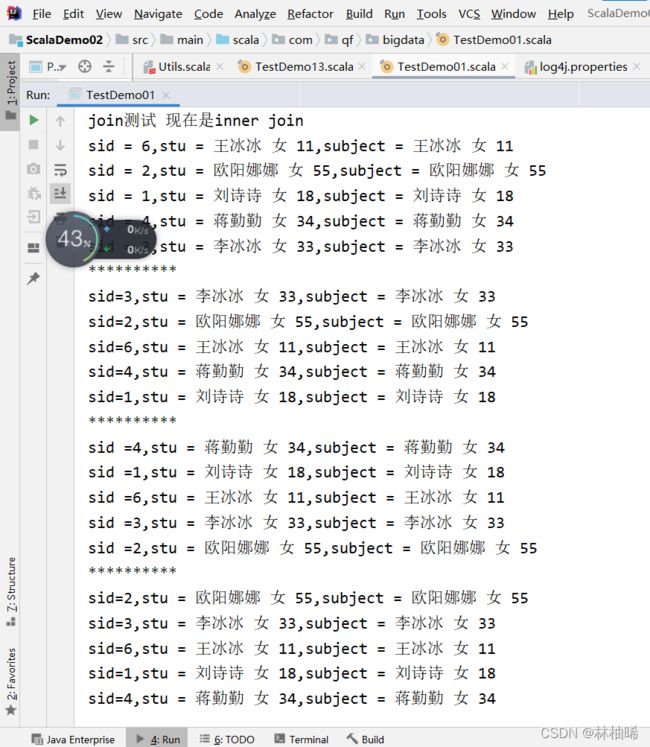
println("join测试 现在是inner join")
val stuSubScoreInfoRDD:RDD[(Int,(String,String))] = sid2StuInfoRDD.join(sid2StuInfoRDD)
stuSubScoreInfoRDD.foreach{
case (sid, (stuInfo,subjectInfo)) => println(s"sid = ${sid},stu = ${stuInfo},subject = ${subjectInfo}")
}
println("*"*10)
val stuInfoRDD:RDD[(Int,(String,Option[String]))] = sid2StuInfoRDD.leftOuterJoin(sid2StuInfoRDD)
stuInfoRDD.leftOuterJoin(sid2StuInfoRDD)
stuInfoRDD.foreach{
case (sid,(stuInfo,subjectInfo)) =>println(s"sid=${sid},stu = ${stuInfo},subject = ${subjectInfo.getOrElse(null)}")
}
println("*" * 10)
val studInfoRDD: RDD[(Int,(Option[String],String))] = sid2StuInfoRDD.rightOuterJoin(sid2StuInfoRDD)
studInfoRDD.foreach{
case (sid,(stuInfo,subjectInfo)) => println(s"sid =${sid},stu = ${stuInfo.getOrElse(null)},subject = ${subjectInfo}")
}println("*"* 10)
val fullRDD:RDD[(Int,(Option[String],Option[String]))] = sid2StuInfoRDD.fullOuterJoin(sid2StuInfoRDD)
fullRDD.foreach{
case (sid,(stuInfo,subjectInfo)) =>println(s"sid=${sid},stu = ${stuInfo.getOrElse(null)},subject = ${subjectInfo.getOrElse(null)}")
}
sc.stop()}
}
2.2.8 gourpByKey
def groupByKey(): RDD[(K, Iterable[V])]
RDD[(K, Iterable[V])] : 返回的RDD中元素类型是一个二维元组:(K, Iterable[V])
作用:分组,都是需要二维元组
缺点:因为不会先进行局部聚合,这将导致它在分布式环境下的shuffle增多。
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val lineRDD:RDD[String] = sc.parallelize(List(
"1,杨过,18,古墓派",
"2,郭靖,32,桃花岛",
"3,令狐冲,1,华山派",
"4,张无忌,2,明教",
"5,韦小宝,3,天地会"
))
//修改数据格式:二维元组
val stuRDD:RDD[(String,String)] = lineRDD.map(line =>{
val index:Int = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0,index)
(className,info)
})
val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
gbkRDD.foreach(println)sc.stop()
}
}
2.3.9 reduceByKey
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
func : 自定义的函数
RDD[(K, V)] :返回的也是RDD副本,也是一个二维元组的RDD
作用:按照key进行分组聚合
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val lineRDD:RDD[String] = sc.parallelize(List(
"1,杨过,18,古墓派",
"2,郭靖,32,桃花岛",
"3,令狐冲,1,华山派",
"4,张无忌,2,明教",
"5,韦小宝,3,天地会"
))
//修改数据格式:二维元组
val stuRDD:RDD[(String,String)] = lineRDD.map(line =>{
val index:Int = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0,index)
(className,info)
})
val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
gbkRDD.foreach(println)
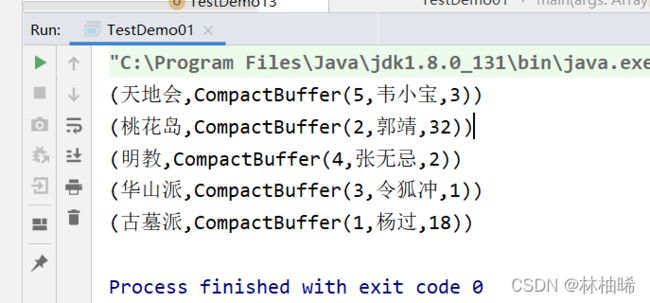
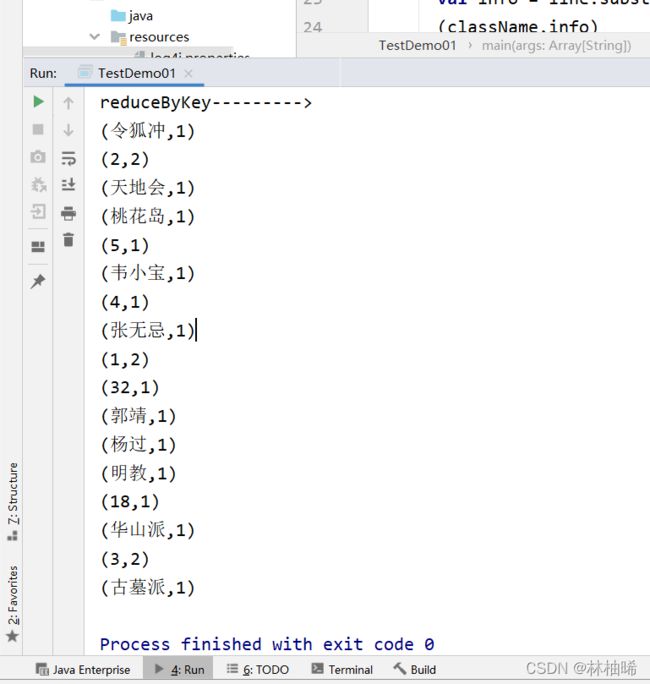
println("reduceByKey--------->")
lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
sc.stop()}
}
2.2.10 sortByKey
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]ascending : 升序、降序(true/false)
numPartitions : 分区数
RDD[(K, V)] : 排序之后的RDD副本
作用:就是按照key进行排序,只保证分区内有序,不保证全局有序。
个人感觉这个排序只是在分区内排序,没很多用途,还是使用字典排序法,对于数字没有用。
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val lineRDD:RDD[String] = sc.parallelize(List(
"1,杨过,18,古墓派",
"2,郭靖,32,桃花岛",
"3,令狐冲,1,华山派",
"4,张无忌,2,明教",
"5,韦小宝,3,天地会"
))
//修改数据格式:二维元组
val stuRDD:RDD[(String,String)] = lineRDD.map(line =>{
val index:Int = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0,index)
(className,info)
})
val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
gbkRDD.foreach(println)
println("reduceByKey--------->")
lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
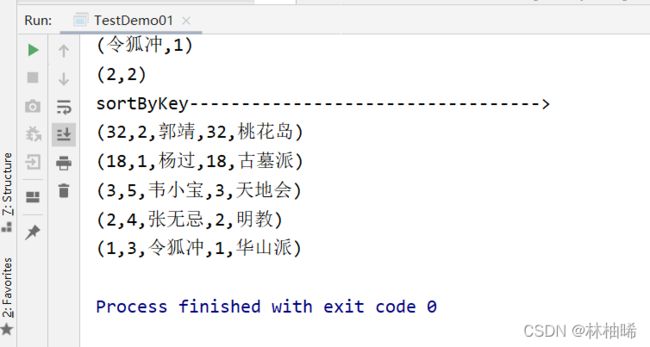
println("sortByKey---------------------------------->")
lineRDD.map(line => {
val stu: Array[String] = line.split(",")
val age:Int = stu(2).toInt
(age, line)
}).sortByKey(false, 2).foreach(println)
sc.stop()}
}
2.2.11 mapPartitions
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]f : 函数
Iterator[T] : 表示一个分区中的所有的数据元素的集合
Iterator[U] : f函数的返回值,也是一个集合
作用:map算子的升级版,map算子是一行读取一次,这个算子是一个分区读取一次
这个算子用处和map算子一样,但是这个用起来效率比map高!
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo01 {
private val logger = LoggerFactory.getLogger(TestDemo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val lineRDD:RDD[String] = sc.parallelize(List(
"1,杨过,18,古墓派",
"2,郭靖,32,桃花岛",
"3,令狐冲,1,华山派",
"4,张无忌,2,明教",
"5,韦小宝,3,天地会"
))
//修改数据格式:二维元组
val stuRDD:RDD[(String,String)] = lineRDD.map(line =>{
val index:Int = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0,index)
(className,info)
})
val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
gbkRDD.foreach(println)
println("reduceByKey--------->")
lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
println("sortByKey---------------------------------->")
lineRDD.map(line => {
val stu: Array[String] = line.split(",")
val age:Int = stu(2).toInt
(age, line)
}).sortByKey(false, 2).foreach(println)
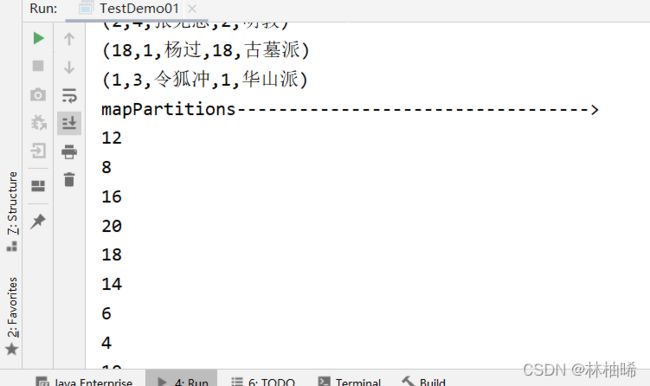
println("mapPartitions---------------------------------->")
val seqRDD: RDD[Int] = sc.parallelize(1 to 10)
seqRDD.mapPartitions(_.map(_ * 2)).foreach(println)
sc.stop()}
}
2.2.12 groupByKey
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo03 {
private val logger = LoggerFactory.getLogger(TestDemo03.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
//1. 加载源数据
val lineRDD: RDD[String] = sc.parallelize(List(
"1,杨过,18,古墓派",
"2,郭靖,32,桃花岛",
"3,令狐冲,1,华山派",
"4,张无忌,2,明教",
"5,韦小宝,3,天地会",
"6,黄蓉,35,桃花岛"
))
//2. 修改数据格式:二维元组
val stuRDD: RDD[(String, String)] = lineRDD.map(line => {
val index: Int = line.lastIndexOf(",")
val className = line.substring(index + 1)
val info = line.substring(0, index)
(className, info)
})
val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
gbkRDD.foreach(println)
sc.stop()}
}
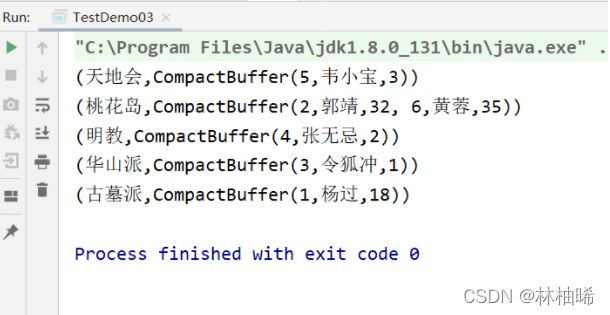
2.2.13 reduceByKey
def reduceByKey(func:(V,V) =>V):RDD[(K,V)]
func:自定义的函数
RDD[(K,V)]:返回RDD副本,是一个二维元组的RDD
作用:按照key进行分组聚合
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo03 {
private val logger = LoggerFactory.getLogger(TestDemo03.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
//1. 加载源数据
val lineRDD: RDD[String] = sc.parallelize(List(
"hello,jdk",
"hello,hadoop"
))
//2. 修改数据格式:二维元组
// val stuRDD: RDD[(String, String)] = lineRDD.map(line => {
// val index: Int = line.lastIndexOf(",")
// val className = line.substring(index + 1)
// val info = line.substring(0, index)
// (className, info)
// })
// val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
// gbkRDD.foreach(println)
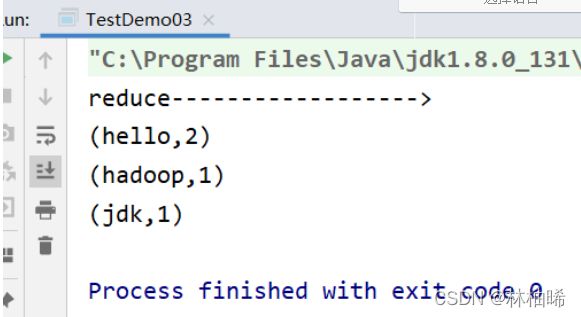
println("reduce------------------>")
lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
sc.stop()}
}
2.2.14 sortByKey
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
ascending : 升序、降序(true/false)numPartitions : 分区数
RDD[(K, V)] : 排序之后的RDD副本
作用:就是按照key进行排序,只保证分区内有序,不保证全局有序。
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo03 {
private val logger = LoggerFactory.getLogger(TestDemo03.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
//1. 加载源数据
val lineRDD: RDD[String] = sc.parallelize(List(
"cidy,14",
"tom,1"
))
//2. 修改数据格式:二维元组
// val stuRDD: RDD[(String, String)] = lineRDD.map(line => {
// val index: Int = line.lastIndexOf(",")
// val className = line.substring(index + 1)
// val info = line.substring(0, index)
// (className, info)
// })
// val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
// gbkRDD.foreach(println)
// println("reduce------------------>")
// lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
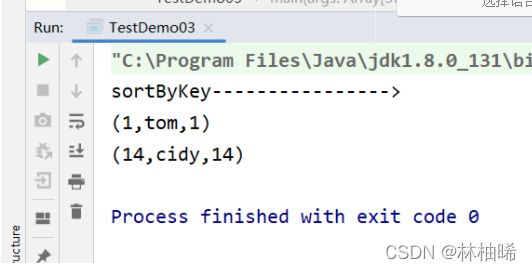
println("sortByKey---------------->")
lineRDD.map(line =>{
val info :Array[String] = line.split(",")
val age:Int = info(1).toInt
(age,line)
}).sortByKey(false,2).foreach(println)sc.stop()
}
}
2.2.15 mapPartitions
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
f:函数
Iterator[T]:表示一个分区中的所有数据元素的集合
Iterator[U]:f函数的返回值,也是一个集合
作用:Map算子的升级版,map算子是一行读取一次,这个算子是一个分区读取一次
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo03 {
private val logger = LoggerFactory.getLogger(TestDemo03.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
// //1. 加载源数据
// val lineRDD: RDD[String] = sc.parallelize(List(
// "cidy,14",
// "tom,1"
// ))
//2. 修改数据格式:二维元组
// val stuRDD: RDD[(String, String)] = lineRDD.map(line => {
// val index: Int = line.lastIndexOf(",")
// val className = line.substring(index + 1)
// val info = line.substring(0, index)
// (className, info)
// })
// val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
// gbkRDD.foreach(println)
// println("reduce------------------>")
// lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
// println("sortByKey---------------->")
// lineRDD.map(line =>{
// val info :Array[String] = line.split(",")
// val age:Int = info(1).toInt
// (age,line)
// }).sortByKey(false,2).foreach(println)
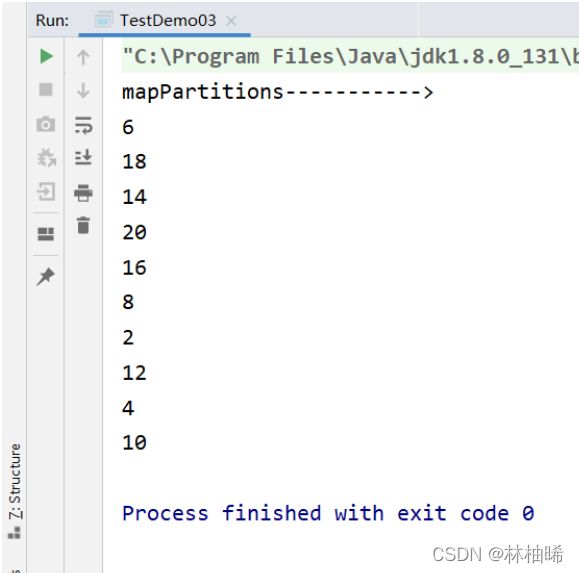
println("mapPartitions----------->")
val seqRDD:RDD[Int] = sc.parallelize(1 to 10)
seqRDD.mapPartitions(_.map(_*2)).foreach(println)
sc.stop()}
}
2.2.16 coalesce和repartition
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T]
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
作用:重分区,从字面上讲这两个算子都是重分区,但是实际上repartition就是由coalesce来实现的,coalesce既可以是宽依赖也可以窄依赖,但是默认是窄依赖,repartition进行分区只能是宽依赖;coalesce一般用于分区减少的操作,repartition一般用于分区增加的操作。
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo03 {
private val logger = LoggerFactory.getLogger(TestDemo03.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
// //1. 加载源数据
// val lineRDD: RDD[String] = sc.parallelize(List(
// "cidy,14",
// "tom,1"
// ))
//2. 修改数据格式:二维元组
// val stuRDD: RDD[(String, String)] = lineRDD.map(line => {
// val index: Int = line.lastIndexOf(",")
// val className = line.substring(index + 1)
// val info = line.substring(0, index)
// (className, info)
// })
// val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
// gbkRDD.foreach(println)
// println("reduce------------------>")
// lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
// println("sortByKey---------------->")
// lineRDD.map(line =>{
// val info :Array[String] = line.split(",")
// val age:Int = info(1).toInt
// (age,line)
// }).sortByKey(false,2).foreach(println)
// println("mapPartitions----------->")
// val seqRDD:RDD[Int] = sc.parallelize(1 to 10)
// seqRDD.mapPartitions(_.map(_*2)).foreach(println)println("coalesce and repartition------------>")
val listRDD:RDD[Int] =sc.parallelize(1 to 1000)
println(s"listRDD partition num is ${listRDD.getNumPartitions}")
val cRDD:RDD[Int] = listRDD.coalesce(1)
val rRDD:RDD[Int] = listRDD.repartition(10)
println(s"cRDD partitions num is ${cRDD.getNumPartitions}")
println(s"rRDD partitions num is ${rRDD.getNumPartitions}")
sc.stop()}
}

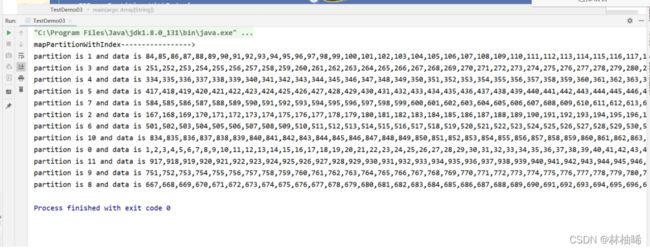
2.2.16 mapPartitionWithIndex
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
f:函数(Int, Iterator[T]) : f函数的参数,Int表示分区编号,Iterator[T]是一个分区的所有的数据
他是 mapPartitions算子的升级版,比 mapPartitions多了一个分区编号
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryobject TestDemo03 {
private val logger = LoggerFactory.getLogger(TestDemo03.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
// //1. 加载源数据
// val lineRDD: RDD[String] = sc.parallelize(List(
// "cidy,14",
// "tom,1"
// ))
//2. 修改数据格式:二维元组
// val stuRDD: RDD[(String, String)] = lineRDD.map(line => {
// val index: Int = line.lastIndexOf(",")
// val className = line.substring(index + 1)
// val info = line.substring(0, index)
// (className, info)
// })
// val gbkRDD:RDD[(String,Iterable[String])] = stuRDD.groupByKey()
// gbkRDD.foreach(println)
// println("reduce------------------>")
// lineRDD.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).foreach(println)
// println("sortByKey---------------->")
// lineRDD.map(line =>{
// val info :Array[String] = line.split(",")
// val age:Int = info(1).toInt
// (age,line)
// }).sortByKey(false,2).foreach(println)
// println("mapPartitions----------->")
// val seqRDD:RDD[Int] = sc.parallelize(1 to 10)
// seqRDD.mapPartitions(_.map(_*2)).foreach(println)// println("coalesce and repartition------------>")
// val listRDD:RDD[Int] =sc.parallelize(1 to 1000)
// println(s"listRDD partition num is ${listRDD.getNumPartitions}")
// val cRDD:RDD[Int] = listRDD.coalesce(1)
// val rRDD:RDD[Int] = listRDD.repartition(10)
// println(s"cRDD partitions num is ${cRDD.getNumPartitions}")
// println(s"rRDD partitions num is ${rRDD.getNumPartitions}")
println("mapPartitionWithIndex----------------->")
val seqRDD:RDD[Int] = sc.parallelize(1 to 1000)
seqRDD.mapPartitionsWithIndex{
case (partitionId,iterator) =>{
println(s"partition is ${partitionId} and data is ${iterator.mkString(",")}")
iterator.map(_ * 2)
}
}.foreach(println)
sc.stop()}
}
combineByKey
通过查看GroupByKey和ReduceByKey的底层源码,发现二者底层都是基于combineByKeyWithClassTag的算子来实现的。包括下面aggregateByKey也是通过combineByKeyWithClassTag来实现的。那么通过名称我们应该可以猜测到我们即将要学习的CombineByKey多少应该和combineByKeyWithClassTag算子有一些关系。
combineByKey其实就是combineByKeyWithClassTag的简化版。作用是它使用现有的分区程序对生成的RDD进行哈希分区。并且此方法是向后兼容。
combineByKey它其实是spark最底层聚合算子之一,可以按照key进行各种各样的聚合操作,spark提供了很多高阶算子,这些算子都是基于combineByKey来实现的。
模拟GroupByKey
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
package com.qf.bigata.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactoryimport scala.collection.mutable.ArrayBuffer
object Demo5_CombineByKey {
private val logger = LoggerFactory.getLogger(Demo5_CombineByKey.getClass.getSimpleName)def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]", "wordcount", new SparkConf())
//1. 加载源数据
val stuRDD: RDD[String] = sc.parallelize(List(
"杨过,古墓派",
"郭靖,桃花岛",
"令狐冲,华山派",
"张无忌,明教",
"韦小宝,天地会",
"黄蓉,桃花岛",
"小龙女,古墓派",
"杨逍,明教",
"陈近南,天地会",
"李莫愁,古墓派"
), 2)//2. 处理数据格式:将数据变为二维的元组
val class2InfoRDD: RDD[(String, String)] = stuRDD.mapPartitionsWithIndex {
case (paritionId, iterator) => {
val array: Array[String] = iterator.toArray
println(s"${paritionId} : ${array.mkString(",")}")
array.map(line => {
val index: Int = line.lastIndexOf(",")
val className: String = line.substring(index + 1)
val info: String = line.substring(0, index)
(className, info)
}).toIterator
}
}//3. groupByKey
println("=========================groupbykey==============================")
class2InfoRDD.groupByKey().foreach(println)println("=========================combinebykey==============================")
class2InfoRDD.combineByKey(createCombiner, mergeValue, mergeCombiners).foreach(println)
sc.stop()
}/**
* 初始化操作
* 在同一个分区中的相同的key会调用一次这个函数,用于初始化,初始化第一个key对应的元素的value
* 说白了就是,RDD中有几个key,就叫用几次这个函数,如果key相同的情况不会再次调用,仅第一次的时候调用
*/
def createCombiner(stu:String):ArrayBuffer[String] = {
println(s"----------------createCombiner<${stu}>----------------------------------")
val ab = ArrayBuffer[String]()
ab.append(stu)
ab
}/**
* 分区内的局部聚合
* 当分区之内,相同的key要先进行局部聚合
*/
def mergeValue(ab:ArrayBuffer[String], stu:String):ArrayBuffer[String] = {
println(s"----------------mergeValue:局部聚合<${ab}>, 被聚合页的只:${stu}----------------------------------")
ab.append(stu)
ab
}/**
* 全局聚合,各个分区内相同的key聚合
* @param ab1 : 全局聚合的临时结果
* @param ab2 : 某一个分区内的所有的数据
* @return
*/
def mergeCombiners(ab1:ArrayBuffer[String], ab2:ArrayBuffer[String]):ArrayBuffer[String] = {
println(s"----------------mergeCombiners:全局的结果<${ab1}>, 分区的结果:${ab2}----------------------------------")
ab1.++:(ab2)
}
}
2.3 Action算子
真相:
RDD中包含了分区,所有数据实际上都是在分区中处理,不在Driver本地执行。action VS transformation
-action算子处理完RDD的数据时候不会产生RDD副本
-action、action算子用于驱动transformation算子
2.3.1 foreach
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val rdd1 = sc.makeRDD(List(1,2,3,4,5),2)
// 行动算子foreach是在excutor端执行的,而普通函数foreach是在Driver端执行的
rdd1.foreach(x =>println(x))
rdd1.collect().foreach(println)
sc.stop()
}
}
2.3.2 count
def count():Long
作用:返回RDD中的元素的个数
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())val listRDD:RDD[Int] = sc.parallelize(1 to 100).map(num =>{
println("-------------------"+num)
num * 10
})val count :Long =listRDD.count()
println(count.isInstanceOf[Long]) //我只是判断count返回的类型,确定是一个Long类型
println(count)
}
}
2.3.3 take(n)
def take(num:Int):Array[T]
作用:取RDD的前3个元素,但是不会对RDD进行排序,所以如果是求topn就一般对RDD中的元素进行排序。
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())val listRDD:RDD[Int] = sc.parallelize(1 to 100).map(num =>{
println("-------------------"+num)
num * 10
})
val top3:Array[Int] = listRDD.take(3)
println(top3.mkString(","))
}
}
2.4.4 first
就是打印第一个元素
同理还有last
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())val listRDD:RDD[Int] = sc.parallelize(1 to 100).map(num =>{
println("-------------------"+num)
num * 10
})
val first = listRDD.first()
println(first)
}
}
2.3.5 collect
说明:
(各个分区中的数据都要统一放到driver中)数据实际上是保持在RDD中,RDD是一个弹性分布式数据集,数据会通过分区分布在不同的节点中,需要将各个分区的数据放在driver中统一处理。
存在风险:
1)dirver内存压力大
2)在网络大规模传输,效率低
建议:
不建议使用,如果要使用还是先filter算子处理无用数据再使用collect。
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val rdd1 = sc.makeRDD(List(1,2,3,4,5),2)
// 行动算子foreach是在excutor端执行的,而普通函数foreach是在Driver端执行的
rdd1.foreach(x =>println(x))
rdd1.collect().foreach(println)
sc.stop()
}
}
2.3.6 reduce
def reduce(f: (T, T) => T): T
它是一个action算子,不是reducebykey一样是transformation算子。reduce的作用对一个RDD进行聚合操作,并返回结果,结果是一个值
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val tRDD:RDD[(String,String)] = sc.parallelize(List(
("name","cidy"),
("age","18"),
("sex","feman"),
("salary","10000000")
))
val tuple:(String,String) = tRDD.reduce{
case ((k1,v1),(k2,v2)) =>(k1+"_"+k2,v1+"_"+v2)
}
println(tuple.toString().mkString(","))
sc.stop()
}
}
一个很尴尬的例子
就是居然把字符串切割成字符了
2.3.7 countByKey
本质是一个action算子
作用是统计RDD中的Key的个数。要求RDD中的元素得是一个二维元组,此算子才可用。
2.3.8 saveAsTextFile和saveAsHadoopFile和saveAsObjectFile和saveAsSequenceFile
以上算子都是用于将RDD中的数据映射到磁盘中。
tRDD.saveAsTextFile("file:/h:/1")
2.4 “持久化”操作
2.4.1 spark持久化的含义
跨节点完成内存中的rdd数据持久化
每个节点都会将其计算的所有的分区存储在内存中,并且在数据集上的其他操作中重用它们。
好处:提升程序的运行效率至10倍以上
2.4.2 如何持久化
使用:persist()和cache()
说明
第一次操作的时候,对RDD中的数据集保存在内存中
需要复用的时候直接获取
2.4.3 持久化策略
每个持久化的RDD可以使用不同的存储策略进行存储,就是可以持久化到磁盘或者是到内存中。
通过设置StorageLevel的类来设置持久化级别,默认存储级别是cache

package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
var start: Long = System.currentTimeMillis()
val listRDD: RDD[String] = sc.parallelize(List(
"hello every one",
"hello everybody",
"ma ma ha ha",
"xi xi xi ha ha"
))
var count: Long = listRDD.count()
println(s"没有持久化:listRDD's count is ${count}, cost time : ${(System.currentTimeMillis() - start)} ms")listRDD.persist(StorageLevel.MEMORY_AND_DISK) // { 开启持久化并配置策略
start = System.currentTimeMillis()
count = listRDD.count()println(s"持久化之后:listRDD's count is ${count}, cost time : ${(System.currentTimeMillis() - start)} ms")
listRDD.unpersist() // } // 关闭持久
sc.stop()
}
}
2.5 共享变量
2.5.1 广播变量
就是把需要多次使用的变量加载到内存中
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val stuRDD:RDD[Student] = sc.parallelize(List(
Student("01","韦小宝","0",18),
Student("02","令狐冲","0",32),
Student("03", "任盈盈", "1", 12),
Student("04", "东方估量", "1", 32)
))
val genderMap = Map(
"0" ->"小哥哥",
"1" ->"小姐姐"
)
stuRDD.map(stu =>{
val gender:String = stu.gender
Student(stu.id,stu.name,genderMap.getOrElse(gender,"春哥"),stu.age)
}).foreach(println)println("使用广播变量==========================")
val genderBC:Broadcast[Map[String,String]] = sc.broadcast(genderMap)
stuRDD.map(stu =>{
val gender:String = stu.gender
Student(stu.id,stu.name,genderBC.value.getOrElse(gender,"春哥BC"),stu.age)
}).foreach(println)
sc.stop()
}
}
case class Student(id:String,name:String,gender:String,age:Int)
2.5.2 累加器
accumulator累加器的概念和mapreduce中的counter是一样的。计数!!!
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val lineRDD: RDD[String] = sc.parallelize(List(
"Our materialistic sciety has led us t hello that happiness cannt be hello withut having mney"
))
val wordsRDD: RDD[String] = lineRDD.flatMap(_.split("\\s+"))
val accumulator = sc.longAccumulator
val rbkRDD: RDD[(String, Int)] = wordsRDD.map(word => {
if (word.equals("hello")) accumulator.add(1L)
(word, 1)
}).reduceByKey(_ + _)
rbkRDD.foreach(println)
println("累加器统计hello的个数:" + accumulator.value)
sc.stop()
}
}
自定义累加器
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.LoggerFactory
import scala.collection.mutable
object Demo04 {
private val logger = LoggerFactory.getLogger(Demo04.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sc = new SparkContext("local[*]","wordcount",new SparkConf())
val lineRDD: RDD[String] = sc.parallelize(List(
"Our materialistic sciety has led us t hello that happiness cannt be hello withut having mney"
))
val wordsRDD: RDD[String] = lineRDD.flatMap(_.split("\\s+"))
val myAcc = new MyAccumulator
sc.register(myAcc,"myAcc")
val rbkRDD:RDD[(String,Int)] = wordsRDD.map(word =>{
if (word.equals("hello")){
myAcc.add(word)
}
(word,1)
}).reduceByKey(_+_)
println("自定义累加"+myAcc.value)
sc.stop()
}
}
class MyAccumulator extends AccumulatorV2[String,Map[String,Long]] {
//累加器的所有的数据都存储在map上
private var map = mutable.Map[String,Long]()
//是否初始化累加器的初始化值
override def isZero: Boolean = true
//拷贝累加器
override def copy(): AccumulatorV2[String, Map[String, Long]] = {
val acc = new MyAccumulator
acc.map = this.map
acc
}
override def reset(): Unit = map.clear()
override def add(word: String): Unit = {
if(map.contains(word)){
val newCount = map(word) + 1
map.put(word,newCount)
}else{
map.put(word,1)
}
//map.put(word,map.getOrElse(word,0) + 1)
}
override def merge(other: AccumulatorV2[String, Map[String, Long]]): Unit = {
other.value.foreach{
case (word,count) =>{
if(map.contains(word)){
val newCount = map(word) +count
map.put(word,newCount)
}else{
map.put(word,count)
}
}
}
}
override def value: Map[String, Long] = map.toMap
}
3 SparkSQL
3.1.1定义
spark生态圈用于sql的计算模块。
曾经叫Shark,15年后面开启了sparksql。
sparksql不依托hive,形成两种不同的业务:sparksql和hive-on-spark
3.1.2 rdd dataframe dataset
(1)编程模型
rdd是第一代编程模型,只有spark core和sparkstreaming使用
df和ds是第二代和第三代编程,是parksql和struturedstreaming使用
(2)编程模型的特点
df和ds可以理解是一个mysql的二维表,有表头、表名、字段、字段类型
rdd是一张表,但是没有表头
df和ds区别就是表头形式不同 (ds的表头是一个整的,df的表头是根据字段区分开的)
df是spark1.3出现的,ds是spark1.6出现的
3.2编程入门
pom.xml
4.0.0 org.example spark_sz2102 1.0-SNAPSHOT 1.8 1.8 UTF-8 2.11.8 2.2.3 2.7.6 2.11 org.scala-lang scala-library ${scala.version} org.apache.spark spark-core_2.11 ${spark.version} org.apache.hadoop hadoop-client ${hadoop.version} org.apache.spark spark-sql_2.11 ${spark.version} org.apache.spark spark-hive_2.11 ${spark.version} mysql mysql-connector-java 8.0.21
package com.qf
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo05 {
def main(args: Array[String]): Unit = {
val spark:SparkSession = SparkSession.builder().appName("demo1").master("local[*]").getOrCreate()
import spark.implicits._
val df:DataFrame = spark.read.json("D:\\data\\sss\\sql\\people.json")
df.printSchema() //打印元数据
df.show()
df.select("name","age").show() //要导入隐式转换
df.select($"name",$"age").show() //要导入隐式转换
//列也可以+1
df.select($"name",($"height"+1).as("height")).show()
//也有其他算子 where和group
df.select($"age").groupBy($"age").count().as("count").show()
//另一种方式,经常使用
df.createTempView("people")
spark.sql(
"""
|select age,count(1) from people group by age
|""".stripMargin).show()
spark.stop()
}
}
3.2.1 JavaBean存入Dataframe
package com.qf
import java.util
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{Column, DataFrame, Dataset, SparkSession}
import org.slf4j.LoggerFactory
import scala.beans.BeanProperty
//JavaBean+反射
object Demo07 {
private val logger = LoggerFactory.getLogger(Demo07.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val spark:SparkSession = SparkSession.builder().appName("demo01").master("local[*]").getOrCreate()
import spark.implicits._
import scala.collection.JavaConversions._ //java的list和scalalist要转换
val list = List(
new Student(1,"郑宇",1,24),
new Student(2,"李狗剩",2,10)
) //先说一下,这个是java的list
val df:DataFrame = spark.createDataFrame(list,classOf[Student]) //这是一个java的list转换为scala的list并且转为df
df.printSchema()
df.show()
println("_"*10)
//把list转换为ds就别了,因为ds要求的集合类型对象必须是样例类
//val ds:Dataset[Student] spark.createDataset(list)
spark.stop()
}
}
class Student {
@BeanProperty var id:Int = _
@BeanProperty var name:String = _
@BeanProperty var gender:Int =_
@BeanProperty var age:Int = _
def this (id:Int,name:String,gender:Int,age:Int){
this()
this.id = id
this.name = name
this.gender = gender
this.age = age
}
}
3.2.2 JavaBean存入Dataset
说明一下:dataset也是一张表,但是它只能存样例类,不能存普通的javabean。所以要存入dataset只能自定义一个样例类。
package com.qf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{Dataset, SparkSession}
import org.slf4j.LoggerFactory
//把javabean放入dataset里面去!一定要使用样例类啊!
object Demo09 {
private val logger = LoggerFactory.getLogger(Demo09.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val spark:SparkSession = SparkSession.builder().appName("demo09").master("local[*]").getOrCreate()
import spark.implicits._
val list = List(
new Stu(1,"李白",1,19),
new Stu(2,"杜甫",1,67)
)
val ds:Dataset[Stu] = spark.createDataset(list)
ds.printSchema()
ds.show()
spark.stop()
}
}
case class Stu(id:Int,name:String,gender:Int,age:Int)
3.2.3 动态编程 这里就拿dataframe做例子
package com.qf
import java.util
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql.{Column, DataFrame, Dataset, Row, SparkSession}
import org.slf4j.LoggerFactory
import scala.beans.BeanProperty
import scala.collection.JavaConversions
//动态编程
object Demo08 {
private val logger = LoggerFactory.getLogger(Demo08.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val spark = SparkSession.builder().appName("demo08").master("local[*]").getOrCreate()
import spark.implicits._
import scala.collection.JavaConversions._
val rowRDD:RDD[Row] = spark.sparkContext.parallelize(List(
Row(1,"曾真",1,10),
Row(2,"李露露",3,90)
))
//创建表头部分
val schema:StructType = StructType(List(
StructField("id",DataTypes.IntegerType,false),
StructField("name",DataTypes.StringType,false),
StructField("gender",DataTypes.IntegerType,false),
StructField("age",DataTypes.IntegerType,false)
))
val df:DataFrame = spark.createDataFrame(rowRDD,schema)
df.printSchema()
df.show()
spark.stop()
}
}
3.3 RDD Dataframe DataSet之间的转换
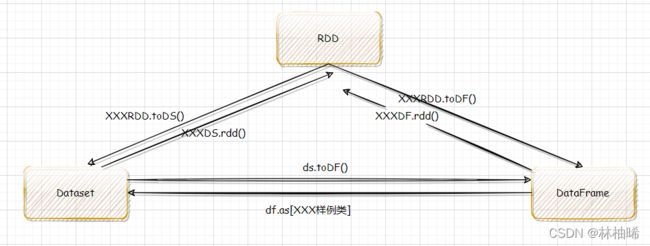
上图是我第一次作图,所以不太美观,但是真的可以直观看见各种转换关系
小tips:
只要转换为df,都是toDF()
只要转换为rdd,都是rdd()
RDD->TODF or DS
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}/**
* RDD 转 DataFrame 或者是Dataset
*/
object Spark_10_RDD_ToDFOrDS {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._
val rdd1: RDD[Int] = sparkSession.sparkContext.makeRDD(List(1, 2, 3, 4, 5))
println("--------------RDD===>DataFrame: RDD的元素只有一列的情况-----------------------")
val df1: DataFrame = rdd1.toDF("num")
df1.show()println("--------------RDD===>Dataset: RDD的元素只有一列的情况-----------------------")
val ds: Dataset[Int] = rdd1.toDS()
ds.show()
val rdd2: RDD[(Int,String,Int)] = sparkSession.sparkContext.makeRDD(List((1,"lily",23),(1,"lucy",24),(1,"tom",25)))
println("--------------RDD===>DataFrame: RDD的元素只有多列的情况,只能使用元组-----------------------")
val df2: DataFrame = rdd2.toDF("id","name","age")
df2.show()
println("--------------RDD===>Dataset: RDD的元素是元组多列的情况下,列名是_1,_2,_3,....... -----------------------")
val ds1: Dataset[(Int, String, Int)] = rdd2.toDS()
ds1.select("_2").show()
val rdd3: RDD[Dog] = sparkSession.sparkContext.makeRDD(List(Dog("旺财", "白色"), Dog("阿虎", "棕色")))
println("--------------其他自定义类型的RDD===>DataFrame -----------------------")
val df3: DataFrame = rdd3.toDF()
df3.select("color").where("color='白色'").show()println("--------------其他自定义类型的RDD===>Dataset -----------------------")
val ds3: Dataset[Dog] = rdd3.toDS()
ds3.where("color='棕色'").select("*").show()sparkSession.stop()
}
case class Dog(name:String,color:String)
}
DF ->RDD OR DS
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}import java.util.Date
/**
* DataFrame 转 RDD 或者是Dataset
*/
object Spark_11_DF_ToRDDOrDS {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._val df: DataFrame = sparkSession.read.json("data/emp.json")
println("--------------DataFrame=>RDD 注意:RDD的泛型为Row-----------------------")
val rdd1: RDD[Row] = df.rdd
//rdd1.foreach(println)
rdd1.foreach(row=>println(row.get(0)+","+row.get(1)+","+row.get(2)))
println("--------------DataFrame=>Dataset 注意: 1 需要自定义一个类型与df中的列数以及类型进行匹配,2,使用as[自定义类型]进行转换即可-----------------------")
val ds: Dataset[E] = df.as[E]
ds.show()
sparkSession.stop()
}
case class E(empno:Long,ename:String,job:String,mgr:Long,hiredate:String,sal:Double,comm:Double,Deptno:Long)
}
DS -> RDD or DF
package com.qf.sparksql.day02
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}/**
* 或者是Dataset 转 RDD 或者是DataFrame
*/
object Spark_12_DS_ToRDDOrDF {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("SQLStyle")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
import sparkSession.implicits._val emps = List(Employee(1001,"lucy","saleman",1000),
Employee(1002,"lily","saleman",1001),
Employee(1003,"john","saleman",1001),
Employee(1004,"michael","boss",1002))
val ds: Dataset[Employee] = sparkSession.createDataset(emps)println("------------Dataset => RDD 两个数据模型的泛型是一样的-------------------------")
val rdd1: RDD[Employee] = ds.rdd
rdd1.foreach(emp=>println(emp.ename+"\t"+emp.job))
println("------------Dataset => DataFrame :本质就是将Dataset的泛型转成Row形式 ------------------------")
val df: DataFrame = ds.toDF()
df.where("mgr=1001").select("*").show()sparkSession.stop()
}
case class Employee(empno:Long,ename:String,job:String,mgr:Long)
}
3.4 读取数据以及数据的转存
3.5 sparksql与hive的整合
这个案例本来是通过main方法的参数传入路径的,但是我idea环境有问题,无法把新编出来的main方法打成jar。就每次打的jar都是今天敲的代码。我也去找了两个小时的资料,尝试了十几均失败。
然后我就自己把这个案例改了,就是把导数据的这个步骤写死了。(狗头保命)
因为没改代码的话,spark老找不到路径,无论我写的是绝对路径还是相对路径。
环境准备
把hive的conf中的hive-site.xml和hadoop的etc的hadoop中的core-site.xml、hdfs-site.xml放到resource文件夹中
core-site.xml
hdfs-site.xml
hive-site.xml
因为有这三个文件,spark才可以找hive的路径嘛
因为我拿的是推荐系统项目的环境,所以上面那个pmml文件本项目不需要,大家忽略一下

package com.qf.bigata.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.slf4j.LoggerFactory
object Demo01 {
private val logger = LoggerFactory.getLogger(Demo01.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
//1. 控制输入参数
// if (args == null || args.length != 2) {
// println(
// """
// |Parameters error! Usage:
// |""".stripMargin)
// System.exit(-1)
// }
//
// val Array(basicPath, infoPath) = args
//2. 获取到sparksql的入口
val spark: SparkSession = SparkSession.builder().appName("Demo01").master("local[*]")
.enableHiveSupport().getOrCreate()
import spark.implicits._ // Java和scala转换的隐式转换
//3. 全程使用sql的方式编程
//3.1 创建hive库
spark.sql(
"""
|create database if not exists hive
|""".stripMargin)
//3.2 创建basic和info表
//3.2.1 teacher_basic
spark.sql(
"""
|create table if not exists hive.teacher_basic(
|name string,
|age int,
|classes int
|) row format delimited
|fields terminated by ','
|""".stripMargin)
//3.2.2 teacher_info
spark.sql(
"""
|create table if not exists hive.teacher_info(
|name string,
|height double
|) row format delimited
|fields terminated by ','
|""".stripMargin)
//3.3 加载数据
spark.sql(
s"""
|load data local inpath './data/teacher_basic.txt' into table hive.teacher_basic
|""".stripMargin)
spark.sql(
s"""
|load data local inpath './data/teacher_info.txt' into table hive.teacher_info
|""".stripMargin)
//3.4 join查询建立新表
spark.sql(
"""
|create table hive.teacher
|as
|select
|b.name,
|b.age,
|b.classes,
|i.height
|from hive.teacher_basic as b left join hive.teacher_info as i
|on b.name = i.name
|""".stripMargin)
//4. 释放资源
spark.stop()
}
}
然后就是打jar包
找那个有依赖,名字最长的jar包
并且把jar包上传到服务器里面
然后我们就创建一下数据表(在服务器中)
cd data
touch teacher_basic.txt
touch teacher_info.txt
有关 teacher_basic.txt
zs,25,2
ls,30,10
ww,34,1
有关 teacher_info.txt
zs,175.0
然后就是在服务器中运行程序
start-all.sh
hive --service metastore &
hive --service hiveserver2 &
${SPARK_HOME}/bin/spark-submit \
--name demo01 \
--conf spark.task.cpus=1 \
--conf spark.executor.cores=4 \
--conf spark.sql.shuffle.partitions=50 \
--master yarn \
--deploy-mode client \
--driver-memory 512M \
--executor-memory 3G \
--num-executors 1 \
--class com.qf.bigata.test.Demo01 \
/data/jar/spark.ja
注意上面的路径要根据自己的实际路径写哦
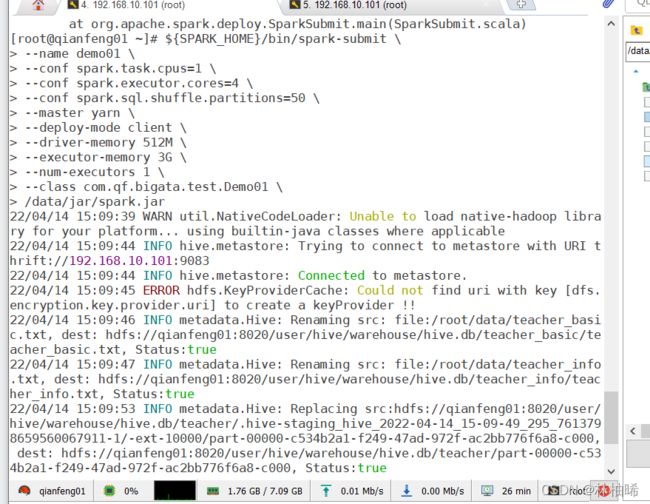
如果是这样有一半概率是成功了
我们来看看hive吧
hive (default)> show databases;
OK
app_news
default
dwb_news
dws_news
hive
ods_news
Time taken: 0.603 seconds, Fetched: 6 row(s)
hive (default)> use hive;
OK
Time taken: 0.03 seconds
hive (hive)> show tables;
OK
teacher
teacher_basic
teacher_info
Time taken: 0.031 seconds, Fetched: 3 row(s)
hive (hive)> select * from teacher;
OK
zs 25 2 NULL
Time taken: 0.324 seconds, Fetched: 1 row(s)
hive (hive)>
3.6 sparksql的自定义函数
3.6.1 自定义udf函数
一路输入,一路输出
下面这个案例就是统计字符串的长度
注意:
这个程序直接在idea本地上跑,不是放在服务器里面,一定要把resource中的hive-site.xml、hdfs-site.xml、core-site.xml删掉,不然程序根本就跑不完(因为它会一直找hive这边的资源)
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.slf4j.LoggerFactory
object Demo02 {
private val logger = LoggerFactory.getLogger(Demo02.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
val spark:SparkSession = SparkSession.builder().appName("Demo02").master("local[*]").getOrCreate()
import spark.implicits._
val lineRDD:RDD[String] = spark.sparkContext.parallelize(List(
"sarkura asd asd sadsf",
"sadsdxs sdsf asfxscf acf"
))
//注册自定义的udf|udaf的函数
spark.udf.register[Int,String]("myLength",myLength)
val df: DataFrame = lineRDD.toDF("line")
df.createOrReplaceTempView("test")
spark.sql(
"""
|select
|line,
|length(line)
|from test
|""".stripMargin
).show()
//释放资源
spark.stop()
}
//反射次方法的类型的Method
//scala的反射中此方法类型就是Funtion1
def myLength(str:String):Int = str.length
}
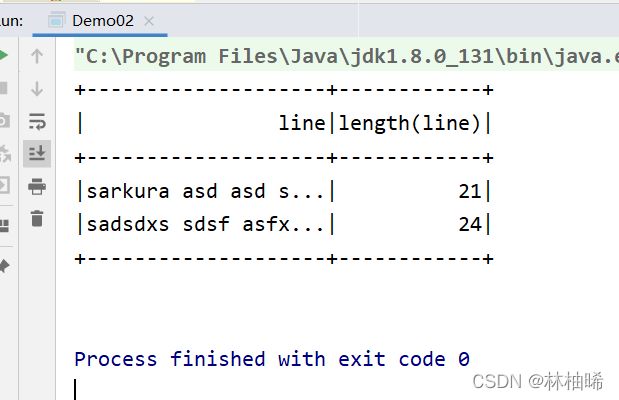
3.6.2 自定义UDAF函数
package com.qf.bigdata
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction, UserDefinedFunction}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.slf4j.LoggerFactory
//UDAF函数
object Demo03 {
private val logger = LoggerFactory.getLogger(Demo03.getClass.getSimpleName)
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
//获取入口
val spark:SparkSession = SparkSession.builder().appName("Demo03").master("local[*]").getOrCreate()
import spark.implicits._
val stuRDD:RDD[Stu] = spark.sparkContext.parallelize(List(
new Stu(1,"小黑锅",1,20),
new Stu(2,"卑微小郭,在线哆嗦",1,21),
new Stu(3,"琪琪",2,24)
))
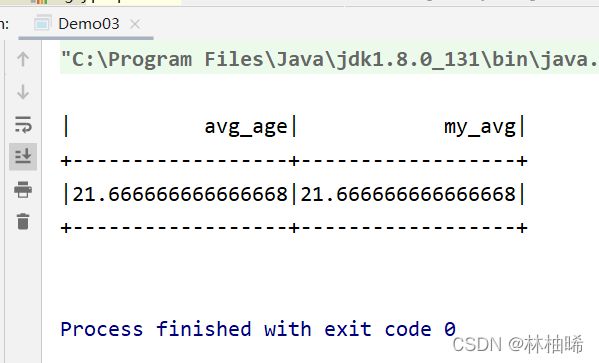
spark.udf.register("myAvg",new MyAvg)
val ds:Dataset[Stu] = stuRDD.toDS()
ds.createOrReplaceTempView("friends")
spark.sql(
"""
|select
|avg(age) as avg_age,
|myAvg(age) as my_avg
|from friends
|""".stripMargin).show()
spark.stop()
}
}
case class Stu(id: Int, name: String, gender: Int, age: Double)
//重写UDAF函数
class MyAvg extends UserDefinedAggregateFunction {
/**
* 指定用户自定义udaf输入参数的元数据
* myavg(value:Double)
*/
override def inputSchema: StructType = StructType(List(StructField("value", DataTypes.DoubleType, false)))
/**
* udaf返回值的类型
*/
override def dataType: DataType = DataTypes.DoubleType
/**
* udaf函数求解过程中的临时变量的类型
* 求平均数:1. 先求总的字段的个数:count 2. 求字段和:sum
*/
override def bufferSchema: StructType = StructType(List(StructField("sum", DataTypes.DoubleType, false), StructField("count", DataTypes.IntegerType, false)))
/**
* 分区初始化操作,说白了就是上面的sum和count的临时变量赋初值
*/
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer.update(0, 0.0) // sum = 0.0
buffer.update(1, 0) // count = 0
}
/**
* 分区内的更新操作
*/
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0, buffer.getDouble(0) + input.getDouble(0)) // sum += age
buffer.update(1, buffer.getInt(1) + 1) // count += 1
}
/**
* 分区之间的合并
*/
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0, buffer1.getDouble(0) + buffer2.getDouble(0)) // sum1 += sum2
buffer1.update(1, buffer1.getInt(1) + buffer2.getInt(1)) // count1 += count2
}
/**
* 返回结果
* avg = sum / count
*/
override def evaluate(buffer: Row): Any = buffer.getDouble(0) / buffer.getInt(1)
override def deterministic: Boolean = true
}