作者:刘健 同心源(三亚)基金
小 T 导读:同心源(三亚)基金管理有限公司是一家致力于采取科学方法,在二级市场进行投资的私募公司。公司的团队成员均来自于国内外优秀大学,创始人具有计算机博士学位,有多年的算法研究、软件系统开发的经验。
从我司的业务模式出发,业务人员主要通过数据挖掘和自动模式识别这两种方式来发现市场的交易规律。因此,我们的工作场景是基于大量的金融数据之上的,主要包括如下几类:
- 国内期货市场的实时高频数据,逐笔数据等
- 国内期货市场的历史高频数据,逐笔数据
- 国内股票市场的高频数据,逐笔数据等
- 国内股票市场的历史高频数据,逐笔数据
- 依据以上数据产生的更大量级衍生数据
经过多年发展,股票市场数据量十分庞大,随着每日新数据的清洗写入,总量变得更加水涨船高。对于十几TB的数据量,单是进行存储已经不易,如果还要对数据进行查询下载等操作,更是难上加难。这些问题横亘眼前,也让我们对市面上的主流数据库逐渐丧失信心。
后来,经过专业人士的引荐,我们尝试了TDengine,没想到它轻轻松松地就适配了我们的当前业务。
具体实践与落地效果
选好数据库之后我们马上开始了搭建,并选择了当时最新的2.1.3.2的版本部署落地,不同数据种类对应的数据库分别如下:
1)股票高频数据库,包括股票市场的历史数据+每日新增数据:
这类数据每日通过Python连接器的方式,在收盘后批量导入再做分析。其中每个表代表一个股票,共85列,以Float数据为主,共32311张。


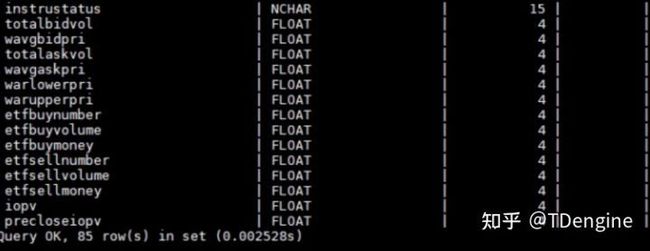
根据上述表结构计算,当前情况每行大概有408字节的长度,然后我们用脚本对所有表进行了行数查询,大概是320亿行。
以上述数据为基础对入库的总数据量进行下估算,粗略计算为408*320亿行,大概12TB左右,后面经过统计最终实际占用磁盘空间却只有2T左右,这令我们十分震惊——压缩率高达16.7%。

众所周知,Float类型的数据压缩一直是数据库领域的一个难题,尤其是对于行式存储的数据库更是困难,高兴之余也非常感谢TDengine的列式存储,帮助我们完美解决了这个棘手的问题。
之后从官方人员处我们得知,在后续版本中,TDengine还对浮点类型数据做了更进一步的算法优化,压缩率还能获得大幅提升。只不过目前需要手动编译,具体操作方式可以联系官方人员。
2)期货库:
期货库是部署在另一个服务器上的,有如下三个:期货高频数据库、期货X频率数据库、期货Y频率数据库。他们分别代表着国内全部期货的高频数据和不同时间频率的聚合数据:
1)期货高频数据库:实时记录交易所发送的tick数据
2)期货X频率数据库:根据时间周期X设定,记录聚合后的数据
3)期货Y频率数据库:根据时间周期Y设定,记录聚合后的数据
以上三个库分别包含3351、5315、5208张子表,与股票库一样,它们同样包括长期的历史数据以及实时数据。
具体的表结构如下所示:
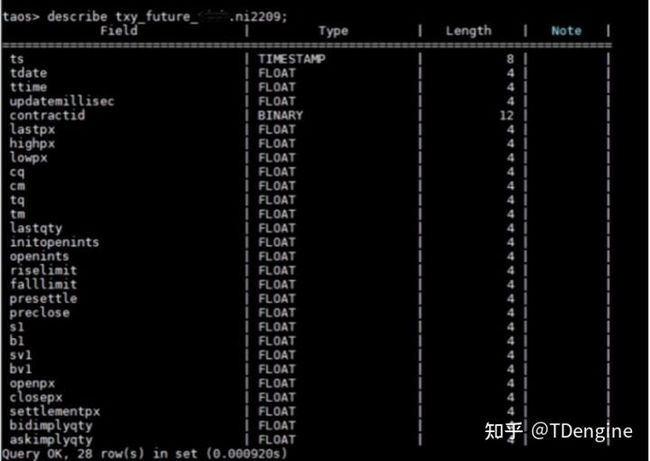
在查询方面,由于当前我们的查询只是针对单表进行,因此逻辑比较简单,代码如下:

此外,由于期货不存在连续多年的行情,所以对于长期的数据展示,我们选择用多段的每X个月数据进行拼接,查询效率非常快。例如:在TDengine客户端服务器使用Python从服务端拉取连续两个月的期货行情数据,耗时仅需0.16秒。
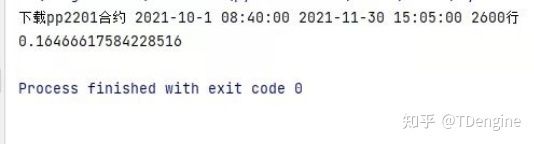
下图为因子1在期货菜粕上的收益曲线,从这张图中我们也可以看出,一些其他常用的函数比如max、last,基于TDengine的缓存等技术也都实现了毫秒级返回数据。

从“两点问题”到深入合作
细心的读者可能也留意到了文章中的两个小问题:
- 为什么我们在估算原数据量时,是通过脚本来统计所有子表行数,再将其乘以单行字节,而不是直接通过TDengine的“超级表”?
- 又为什么在文章开头的数据分类描述中,1-4条都在后文中都看到了实际对应的数据库,但是唯独没有出现第5条——依据以上数据产生的大量衍生数据?
其实是这样,由于项目初期没有多表聚合查询的需求,外加为了降低数据迁移的复杂度,因此在环境搭建初期时我们并没有选择超级表。
但是随着业务的不断完善,我们将会需要更大量的数据来做更复杂的分析,这也就出现了第5条的数据种类——依据以上数据产生的更大量级衍生数据。所以说,这部分数据将来源于我们后面的待上线业务中。
届时,我们将会更深入地用到TDengine的其他核心特性,如超级表、众多计算函数等等。但仅就当下而言,TDengine强大的存储能力和快速查询已经非常令我们惊喜,也让我们对未来更加深入的合作充满期待。
关于作者:
刘健,北京航空航天大学模式识别专业硕士学历,曾经供职于中国航天科技集团从事软件研发工作。2014年与朋友一起创业从事外汇、期货、股票ETF的自动交易至今。着重致力于通过数据挖掘、自动模式识别等方式在国内二级市场中进行自动量化交易。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。