动手学习深度学习——深度卷积神经网络Alexnet
1、AlexNet定义
- 第⼀,与相对较⼩的LeNet相⽐,AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以及1个 全连接输出层。
- 第⼆,AlexNet将sigmoid激活函数改成了更加简单的ReLU激活函数。
- 第三,AlexNet通过丢弃法来控制全连接层的模型复杂度。⽽LeNet并没有使⽤丢弃 法。
- 第四,AlexNet引⼊了⼤量的图像增⼴,如翻转、裁剪和颜⾊变化,从⽽进⼀步扩⼤数据集来缓解过拟合。
3、AlexNet⽹络结构
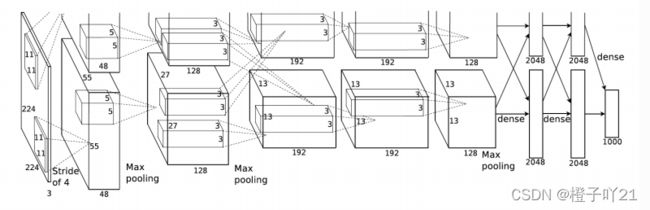
首先总体概述下:
AlexNet为8层结构,其中前5层为卷积层,后面3层为全连接层;学习参数有6千万个,神经元有650,000个;AlexNet在两个GPU上运行;AlexNet在第2,4,5层均是前一层自己GPU内连接,第3层是与前面两层全连接,全连接是2个GPU全连接;RPN层第1,2个卷积层后;Max pooling层在RPN层以及第5个卷积层后。ReLU在每个卷积层以及全连接层后。
卷积核大小数量:
conv1:96 11*11*3(个数/长/宽/深度)
conv2:256 5*5*48
conv3:384 3*3*256
conv4: 384 3*3*192
conv5: 256 3*3*192
ReLU、双GPU运算:提高训练速度。(应用于所有卷积层和全连接层)
重叠pool池化层:提高精度,不容易产生过度拟合。(应用在第一层,第二层,第五层后面)
局部响应归一化层(LRN):提高精度。(应用在第一层和第二层后面)
Dropout:减少过度拟合。(应用在前两个全连接层)
第1层分析:
第一层输入数据为原始图像的227*227*3的图像(最开始是224*224*3,为后续处理方便必须进行调整),这个图像被11*11*3(3代表深度,例如RGB的3通道)的卷积核进行卷积运算,卷积核对原始图像的每次卷积都会生成一个新的像素。卷积核的步长为4个像素,朝着横向和纵向这两个方向进行卷积。由此,会生成新的像素;(227-11)/4+1=55个像素(227个像素减去11,正好是54,即生成54个像素,再加上被减去的11也对应生成一个像素),由于第一层有96个卷积核,所以就会形成55*55*96个像素层,系统是采用双GPU处理,因此分为2组数据:55*55*48的像素层数据。
重叠pool池化层:这些像素层还需要经过pool运算(池化运算)的处理,池化运算的尺度由预先设定为3*3,运算的步长为2,则池化后的图像的尺寸为:(55-3)/2+1=27。即经过池化处理过的规模为27*27*96.
局部响应归一化层(LRN):最后经过局部响应归一化处理,归一化运算的尺度为5*5;第一层卷积层结束后形成的图像层的规模为27*27*96.分别由96个卷积核对应生成,这96层数据氛围2组,每组48个像素层,每组在独立的GPU下运算。
第2层分析:
第二层输入数据为第一层输出的27*27*96的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被5*5*48的卷积核进行卷积运算,同理按照第一层的方式进行:(27-5+2*2)/1+1=27个像素,一共有256个卷积核,这样也就有了27*27*128两组像素层。
重叠pool池化层:同样经过池化运算,池化后的图像尺寸为(27-3)/2+1=13,即池化后像素的规模为2组13*13*128的像素层。
局部响应归一化层(LRN):最后经过归一化处理,分别对应2组128个卷积核所运算形成。每组在一个GPU上进行运算。即共256个卷积核,共2个GPU进行运算。
第3层分析
第三层输入数据为第二层输出的两组13*13*128的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*128的卷积核(两组,一共也就有3*3*256)进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有384个卷积核,这样也就有了13*13*192两组像素层。
第4层分析:
第四层输入数据为第三层输出的两组13*13*192的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*192的卷积核进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有384个卷积核,这样也就有了13*13*192两组像素层。
第5层分析:
第五层输入数据为第四层输出的两组13*13*192的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*192的卷积核进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有256个卷积核,这样也就有了13*13*128两组像素层。
重叠pool池化层:进过池化运算,池化后像素的尺寸为(13-3)/2+1=6,即池化后像素的规模变成了两组6*6*128的像素层,共6*6*256规模的像素层。
第6层分析:
第6层输入数据的尺寸是6*6*256,采用6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算;每个6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6*6*256尺寸的滤波器对输入数据进行卷积,通过4096个神经元的输出运算结果;然后通过ReLU激活函数以及dropout运算输出4096个本层的输出结果值。
很明显在第6层中,采用的滤波器的尺寸(6*6*256)和待处理的feature map的尺寸(6*6*256)相同,即滤波器中的每个系数只与feature map中的一个像素值相乘;而采用的滤波器的尺寸和待处理的feature map的尺寸不相同,每个滤波器的系数都会与多个feature map中像素相乘。因此第6层被称为全连接层。
第7层分析:
第6层输出的4096个数据与第7层的4096个神经元进行全连接,然后经由ReLU和Dropout进行处理后生成4096个数据。
第8层分析:
第7层输入的4096个数据与第8层的1000个神经元进行全连接,经过训练后输出被训练的数值。
4、总结
AlexNet是更大更深的LeNet,10x参数个数,260x计算复杂度;
新进入丢弃法,ReLU,最大池化层,和数据增强;
AlexNet赢下了2012ImageNet竞赛后,标志着新的一轮神经网络热潮的开始。
5、代码实现
import time
import matplotlib.pyplot as plt
import torch
from torch import nn, optim
import torchvision
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
"""实现稍微简化过的AlexNet """
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels,kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减⼩卷积窗⼝,使⽤填充为2来使得输⼊与输出的⾼和宽⼀致,且增⼤输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使⽤更⼩的卷积窗⼝。除了最后的卷积层外,进⼀步增⼤了输出通道数。
# 前两个卷积层后不使⽤池化层来减⼩输⼊的⾼和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)# 这⾥全连接层的输出个数⽐LeNet中的⼤数倍。使⽤丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256 * 5 * 5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这⾥使⽤Fashion-MNIST,所以⽤类别数为10,⽽⾮论⽂中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
#打印看网络结构
net = AlexNet()
print(net)
"""读取数据"""
def load_data_fashion_mnist(batch_size, resize=None,root='~/Datasets/FashionMNIST'):
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root,
train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root,
train=False, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train,
batch_size=batch_size, shuffle=True, num_workers=4)
test_iter = torch.utils.data.DataLoader(mnist_test,
batch_size=batch_size, shuffle=False, num_workers=4)
return train_iter, test_iter
batch_size = 128
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = load_data_fashion_mnist(batch_size,resize=224)
"""训练"""
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
plt.show()