Sentence-BERT 语义相似度双塔模型
论文介绍
发表:2019,EMNLP
论文题目:《Sentence-BERT:sentence embeddings using siaese BERT-networks》
论文地址:https://arxiv.org/abs/1908.10084
Github:https://github.com/UKPLab/sentence-transformers
适用领域:
- 句向量生成
- 语义相似度计算
- 语义搜索
- 无监督任务(聚类)
1 概述
在20年之前的各种预训练模型中,比如bert,XLNet,Albert等等,这些都不适合用作语义相似度以及无监督任务中。通常这类问题的解决方式是计算出句向量,然后计算距离(余弦相似度,曼哈顿距离等)来表示语义距离。
1.1 交互型模型(单塔模型)
在以Bert为代表的预训练模型,其语义相似度的计算的处理方式是构造句子对[CLS]sen1[SEP]sen2 输入到模型中,通过各种句子间的特征交互完成相似度计算。这就是所谓的交互式模型。这样来看,效果一般来说表现都不错,但是更多的在计算速度上面存在很大的问题。
以10000个句子对为例,如果需要匹配每个句子的相似度最大的句子,则需要进行两两交互,10000个句子之间的计算量为10000*(10000-1)/2,约等于5000w次推理计算,在V100gpu上面大概需要65h。
所以交互型学习可以捕获到更深层的结构信息,当然带来的主要问题就是计算速度很慢。
1.2 表示型模型(双塔模型)
概括说来就是分别针对单个句子计算句向量表示,在对两个句向量进行距离计算,在这里形成交互。
表示型匹配模型的共同特点是:对将要匹配的两个句子分别进行编码与特征提取,最后进行相似度交互计算。其优点是:
- 将文本映射为一个简洁的表达,便于储存。
- 匹配的计算速度快。
- 模型在表示层可以用大量无监督的数据进行预训练。因此非常适合于信息检索这种对存储和速度要求都比较高的任务。
但缺点是:
- 匹配不仅仅是一一对应的,而且是有层次、 有结构的 ,分别从两个对象单独提取特征,很难捕获匹配中的结构信息。
本文就是这样的一个表示型双塔模型。
2 Bert进行单句Sentence Embedding
上文提到,可以通过对单个句子进行sentence embedding,然后在进行交互,两两计算距离,如果直接使用bert进行这样的操作不就好了吗。为什么还需要提出本文的Sbert呢?
实际上,bert有过sentence embeddings工作的研究,通过一个单一句子输入到bert得到他的word embeddings,然后通过CLS,或者meaning的方式得到固定长度的embedding。但是这样看来,并没有什么有效的方法去评估这种嵌入的效果如何。
在语义相似度任务中,直接进行bert输出sentence embeddings的实验效果并不好,见后面实验对比。
3 SBERT(sentence-bert)
针对文本相似度等会回归问题,SBERT主要在bert的基础上进行了结构设计:采用了Siamese(孪生)和triplet(三级)网络结构来获取语义embedding。
3.1 Siamese(孪生)
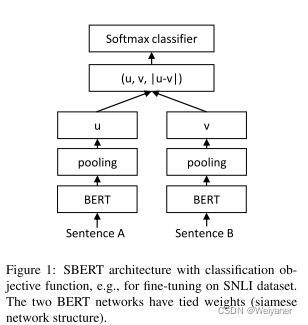
Siamese network是一个简单而又神奇的网络结构,就像一个连体人一样,孪生网络采用权值共享的方式来实现,如下图所示。

何为权值共享?
简单理解就是一个网络结构,甚至在实现上面就是同一个模型。
孪生网络的作用?
简单来说,衡量两个输入的相似程度。孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
3.2 Pooling操作
在bert输出层之后,进行pooling可以将word embeddings 变成一个固定程度的sentence embedding,一般怕pooling有三种操作:
- max: 取出word embeddings中的最大值作为sentence embedding
- CLS-token:也就是bert的做法,将CLS作为sentence embedding
- Mean:对所有word embeddings进行平均池化,本文实验表示,这也是三者中最好的策略。
3.3 分类任务网络结构
通过将输出的sentence embeddings串联起来,得到三个特征(u,v,|u-v|),经过一个softmax层,训练权重W,进行分类。
o = s o f t m a x ( W t ( u , v , ∣ u − v ∣ ) ) o=softmax(W_t(u,v,|u-v|)) o=softmax(Wt(u,v,∣u−v∣))
其中,损失函数为交叉熵函数,embedding维度为n(一般是768,large是1024),W的维度为3n*k(k是label数)。
3.4 回归任务网络结构
回归任务就直接计算二者的余弦相似度,采用MSE作为损失函数。斯皮尔曼系数或者皮尔森系数作为评价指标。

3.5 Triplet 目标函数
给定一个sentence a,一个正样本p和负样本n,优化ap之间的距离小于an之间的距离作为目标函数,也就是最小化以下函数:
![]()
4 SBERT为何更快(训练+推理)?
主要可以从训练和推理效率来说明,在训练中
- 在输入上表示为:一次性输入2个句子,即[CLS]句子0[SEP]\n[CLS]句子1[SEP]。而bert的输入长度是[CLS]句子0[SEP]句子1[SEP],长度是2倍。而运行速度和句子的长度是呈平方递增的,句子变短了所以效率有所提升。虽然SBERT的batch数增大了二倍,但不是平方的关系。
在推理上
- 对于n个句子,SBERT只需要计算n次,BERT需要计算n(n-1)/2次。因为SBERT对每个句子计算sentence embedding之后就保存,然后直接计算两两之间的余弦相似度即可,距离的计算可以忽略不计。所以在10000个句子,推理才有可能从65h变成5s左右。
5 实验结果
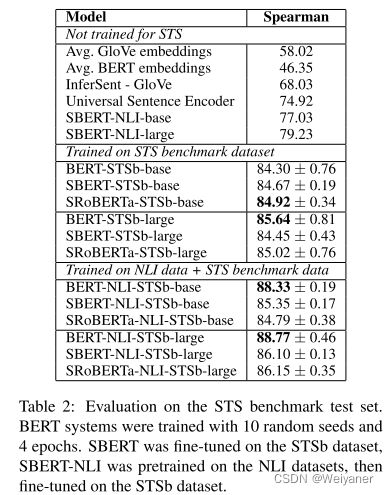
1 无微调+直接STS表现
不经过STS数据集微调的情况下,直接在STS进行预测,通过Spearman系数进行评价,得到结果如下:

从上面可以看出,直接使用bert输出sentence embeddings的效果并不好,平均相关性只有29.19。而SBERT的表现确实出色。
2 微调SBERT+STS表现
经过NLI数据集微调之后,表现进一步提升。
参考:
1
2