A ConvNet for the 2020s 简单翻译/理解
A ConvNet for the 2020s 简单翻译/理解
目录
- A ConvNet for the 2020s 简单翻译/理解
- 前言
- 1.Intro
- 2.卷积网络的改造之路
-
- 2.1 训练技巧
- 2.2 宏观设计
-
- 2.2.1 改变阶段计算比率(块的占比)
- 2.2.2 改变干细胞为“Patchify”
- 2.3 ResNeXt-ify
- 2.4 翻转瓶颈
- 2.5 大核
- 2.6 微观设计
- 3.ImageNet上的评估
-
- 3.1 设置
- 3.2 结果
- 3.3 ConvNeXt vs. ViT各向同性的比较
- 4.其他任务上的结果
-
- 4.1 COCO分类
- 4.2 ADE20K分割任务
- 4.3 模型效率说明
前言
最近看到FAIR发的这一篇,尝试证明传统的卷积网络在性能和计算效率能上打过Transformer,结果卓有成效。对于我这种新手来说,这不就是一个优质的综述么,打算做一个简单的翻译+理解,有错误还希望评论区指出,欢迎讨论!
原文地址:https://arxiv.org/abs/2201.03545
1.Intro
2012年是卷积神经网络在图像领域大放异彩的一年,该年主流工作从手动设计特征提取器逐渐转到设计卷积神经网络的结构。
滑动窗口是卷积网络一个共识性的策略。卷积网络也有很多自身特性使其很适合做不同的图像任务,其中最重要的特性就是卷积的滑动不变性。与此同时自然语言处理发展出了另外一条到路,使用Transformer作为backbone。尽管如此不同,在2020年ViT将Transformer应用到视觉领域,彻底改变了(视觉领域)网络结构设计的主流。ViT知是机械的把Transformer搬到视觉领域做分类任务,但其二次复杂度使得它在面对更复杂任务、更高清图像的时候显得无力。
Hierarchical(暂时不会翻) Transformers使用权衡之计,将窗口滑动重新融进Transformer。Swin T是这一方向的里程碑,它可以作为一个backbone,超出分类任务在众多图像任务中达到SOTA。这也可以证明(作者自己说的,并不是严格证明的公理):卷积操作并没有边缘化,反而它的重要性从没有削弱。
有了Swin T的先例,众多任务开始模仿它做滑动窗口的自注意力,但是这非常昂贵。为了解决Transformer带来的各种问题,引入了各种设计,但这些工作有点像在手搓一个卷积结构(原文写的是传统的卷积网络可以做到这一切所有事),唯一一个Transformer好的地方就是其多头注意力机制可以让它灵活的在各个任务中切换。
Transformer和ConvNet的相同与不同:相同,使用了相似的归纳偏置;不同:训练过程和微观/宏观的结构设计。本文想要:1.对比Transformer和ConvNet,找出两者的区别;2.为ConvNet桥接上前ViT和后ViT时代;3.看看纯卷积网络的上限在哪。
为此,我们从标准的ResNet开始,逐渐将其改造成层次Transformer(如Swin T)。我们的工作受这一核心思想指导:一个卷积网络的性能受到哪些来自Transformer的设计的影响(How do design decisions in Transformers impact ConvNets’ performance?)?针对这个问题,我们找到了一些组件(component)切实影响了性能。最后,我们用以上结果设计了一族卷积网络并命名为“ConvNeXt”。经过测试,我们发现传统卷积在各个数据集上的表现(ImageNet分类、COCO检测、ADE10K分割)不输Transformer。我们这么做是为了让人们重新审视卷积在图像领域的重要性。
2.卷积网络的改造之路
这一节我们详细展示了ConvNet到Transformer的路线图,在模型大小上用FLOPs分为两部分,一部分是ResNet50/SwinT(4.5e9),另一部分是ResNet200/SwinB(15e9)
我们改造的方向:1)宏观设计 2)ResNeXt 3)翻转瓶颈 4)大核 5)网络层级别上的小设计

大多数组件的加入是有效的,有的有反向作用,有的需要控制好度,这些组件加在一起有了2个点的提升。
2.1 训练技巧
训练过程也会独立地影响模型结果。
第一步,使用ViT的训练手法训练一个baseline,ResNet50/200.本例中我们使用了类似DeiT和Swin Transformer的训练技巧,训练了300轮。使用AdamW优化器、数据增强(Mixup、Cutmix、RandAugment、RandomErasing)和其他一些技巧包括Stochastic Depth、Label Smoothing。这些技巧使得ResNet50从76.1%涨点到78.8%(+2.7%),一定程度上说明Transformer比ConvNet好的部分很可能在于训练技巧上。在整个改造过程中我们将使用完全一样的超参数并将每个版本使用不同的三个随机数种子训练三次,并将评估结果取均值。
2.2 宏观设计
分析Swin Transformer的结构,它如同ConvNet有很多阶段,每个阶段特征图的分辨率不一样。我们分析的重点:1.改变阶段计算率 2.改变干细胞
2.2.1 改变阶段计算比率(块的占比)
第四阶段的计算往往被认为和下游任务紧密相连,例如检测,检测头会在这个14x14大小的特征平面上运作。SwinT大致延续Res50结构(3,4,6,3),但有小改动,改成了1:1:3:1。我们也类似地把Res50的结构改为(3,3,9,3),涨点从78.8%到79.4%。我们只是粗略探讨计算比率问题,其实还存在一个最优解(挖坑等大伙跳)。后面的改动都基于此。

这张图是ResNet原文给出的ResNet系列网络的结构。
2.2.2 改变干细胞为“Patchify”
(作者首先介绍什么是干细胞)由于图像信息的冗余性,一般处理图像时,不管是Trans方法还是Conv方法,第一步都要降采样,这个降采样的结构称为“干细胞”。ResNet的干细胞结构为:卷积(kernel=7x7,stride=2)+maxpool,实现了四倍降采样(步长2相当于长宽方向上都÷2,一共÷4)。ViT使用了更激进的卷积,核大小达到了14或16,且卷积是无重叠的(步长不小于核大小),这也映证其名:patchify。其中SwinT没那么激进,用的是Conv(kernel=4x4,stride=4)的patchify。我们把SwinT的这个方案应用于Res50,涨点从79.4%到79.5%。后面的改动都基于此。
2.3 ResNeXt-ify
本小节尝试将ResNeXt引入,此物在参数数量、精确度上的表现都比原版ResNet好。其核心思想就是“组卷积”,卷积核们被分到不同的组里。ResNeXt的主旨就是“更多组,更宽层”。具体来说,它在bottleneck block用了成组的3x3卷积核,显著降低FLOPs,宽度的增加补偿了计算容量损失。
使用了组卷积,组数=宽度,FLOP和acc都下降,又加宽了卷积层(64-96),准确率涨回到80.5,FLOPs也涨到5.3G。后面的改动都基于此。

2.4 翻转瓶颈
同深层卷积的FLOPs增长了,但总参数量下降到到4.6G(因为残差块的跳接部分1x1卷积参数变少了),结果涨点从80.5-80.6。Res200涨点从81.9到82.6,同样减少了FLOPs。后面的改动都基于此。
这里结构的改变体现在上图Figure3
2.5 大核
Transformer的一大显著特征就是,其非局部的自注意力可以让它有全局的感受野(一次注意到很远位置的信息,而不用经过层层卷积)。VGG系列网络认为,小核的堆叠可以让计算在硬件上更有效率(事实上Nvidia确实对3x3卷积的操作支持性更好)。SwinT虽然用回了滑动窗口,但核大小最小也是7x7,远大于3x3。
将同深层卷积往上提
This intermediate step reduces the FLOPs to 4.1G, resulting in a temporary performance degradation to 79.9%.
改变卷积核大小
当卷积核大小增长到7之后,后面效果不增反降,故后面的改动基于7x7卷积核的版本。

这张图主要表现的是GELU的使用、大核的使用、LN的使用、卷积层宽度从64-96的改变
2.6 微观设计
ReLU改GELU
性能没任何改变
更少的激活
传统卷积网络习惯在每次卷积后面加上一个激活层。设计如图4的结构,采用更少的激活层,This process improves the result by 0.7% to 81.3%, practically matching the performance of Swin-T.
更少的标准化层
移除两层BN,留下1层,This further boosts the performance to 81.4%,此时的ResNet已经优于SwinT了。意识到此时的BN层甚至比SwinT还要少,我们又加回去一层,但结果并没有变好。
替换BN为LN
BN是常用的标准化方法,可有效提升融合能力、缓解过拟合。用LN训练时没有任何困难(复杂度没有涨)且轻微涨点到81.5%。
分开的下采样层
ResNet中下采样办法是,在块的开始用一层Conv2d(kernel=3x3,stride=2),在跳接处用一层Conv2d(kernel=1x1,stride=2)进行卷积。在SwinT,一个独立下采样层添加在两个阶段之间,我们借鉴此使用Conv(2x2,stride=2)来做空间降采样。但是直接这样干训练时不稳定,需要在特征图分辨率改变处添加标准化层。具体添加位置是:1.每个降采样层之前 2.stem之后 3.最后一个全局平均池化之后。结果是We can improve the accuracy to 82.0%, significantly exceeding Swin-T’s 81.3%.
结束语
我们的工作只能说“谨慎乐观”,一方面这些工作的有效性还有待进一步更严格的证明,另一方面纯卷积在迁移到下游任务时没有Transformer那么轻松。下一节将扩展ConvNeXt并在不同数据集(也就是不同任务)上评估其性能。
3.ImageNet上的评估
仿照SwinT/B的方式,我们搞了ConvNeXt-T/S/B/L它们在通道数C和每阶段块数B上有区别,其设置分别为:
ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
3.1 设置
在ImageNet-1K上进行训练、评估,又在ImageNet-22K预训练+ImageNet-1K上进行微调训练并在ImageNet-1K上进行评估。
其余具体训练参数设置参考原文。
3.2 结果
分类任务

3.3 ConvNeXt vs. ViT各向同性的比较

4.其他任务上的结果
4.1 COCO分类
选用的是Mask R-CNN和Cascade Mask R-CNN的结构,以ConvNeXt作为ackbone。
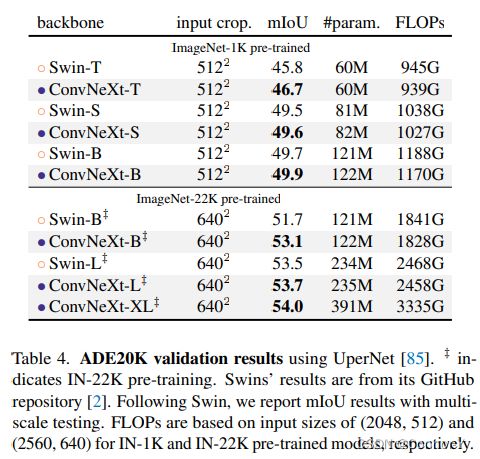
4.2 ADE20K分割任务
选用UperNet作为框架,
4.3 模型效率说明
在同等FLOPs下,同深卷积(depthwise conv)的网络要比传统卷积的网络推理更耗时,在实验中我们的ConvNeXt在推理时间上至少不差于Swin。同时训练时它比Swin使用更少的显存。