【GCN-RS】经典工作:NGCF、LightGCN、LR-GCCF(代码实现)
开源了一个小项目,将一些经典的RS模型整合到一套代码中,可以作为学习参考,
GitHub地址:https://github.com/ChadsLee/RS_Zoos
NGCF:Neural Graph Collaborative Filtering (SIGIR’19)
前文GCN中的邻接矩阵 A A A可以表征数据之间的关联,在这里换了一个说法,叫做“CF signal”。
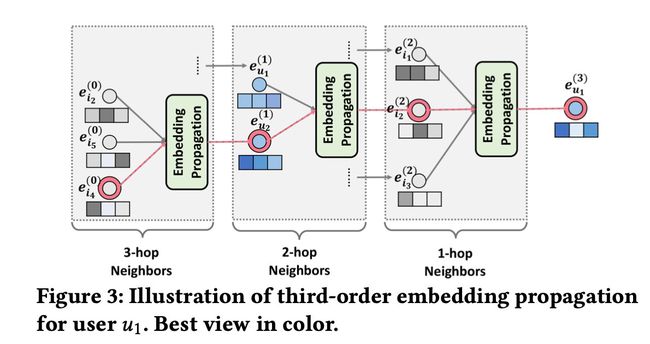
假设用户为 u u u,物品为 i i i,我们可以画出user-item的二部图,同时根据二部图可以将 u 1 u_1 u1的高维连接表示出来,如下图所示:

模型框架主要有三个部分组成:
- Embedding Layer:提供初始的user embedding 和 item embedding
- Multiple Embedding Propagation Layers:通过注入高阶连接关系来细化嵌入
- The Prediction Layer:通过整合多层嵌入来预测 ( u , i ) (u,i) (u,i)
Embedding Layer
E = [ e u 1 , ⋯ , e u N ⏟ users embeddings , e i 1 , ⋯ , e i M ⏟ item embeddings ] \mathbf{E}=[\underbrace{\mathbf{e}_{u_{1}}, \cdots, \mathbf{e}_{u_{N}}}_{\text {users embeddings }}, \underbrace{\mathbf{e}_{i_{1}}, \cdots, \mathbf{e}_{i_{M}}}_{\text {item embeddings }}] E=[users embeddings eu1,⋯,euN,item embeddings ei1,⋯,eiM]
d维embedding,没什么好说的,如果是矩阵分解, e u \mathbf{e}_{u} eu和 e i \mathbf{e}_{i} ei一乘就就是预测结果了。
Embedding Propagation Layers
u − > i u->i u−>i和 i − > u i->u i−>u是一样的,这里以 u u u为例。首先考虑一层,对应一阶的情况。
first-order propagation
物品 i i i传递给消费过他的用户 u u u的信息可以表达为:
m u ← i = f ( e i , e u , p u i ) m u ← i = 1 ∣ N u ∣ ∣ N i ∣ ( W 1 e i + W 2 ( e i ⊙ e u ) ) , \mathbf{m}_{u \leftarrow i}=f\left(\mathbf{e}_{i}, \mathbf{e}_{u}, p_{u i}\right)\\ \mathbf{m}_{u \leftarrow i}=\frac{1}{\sqrt{\left|\mathcal{N}_{u}\right|\left|\mathcal{N}_{i}\right|}}\left(\mathbf{W}_{1} \mathbf{e}_{i}+\mathbf{W}_{2}\left(\mathbf{e}_{i} \odot \mathbf{e}_{u}\right)\right), mu←i=f(ei,eu,pui)mu←i=∣Nu∣∣Ni∣1(W1ei+W2(ei⊙eu)),
W 1 W_1 W1 和 W 2 W_2 W2是训练出来的权重矩阵,维度为 d ∗ d ′ d*d' d∗d′, 1 ∣ N u ∣ ∣ N i ∣ \frac{1}{\sqrt{\left|\mathcal{N}_{u}\right|\left|\mathcal{N}_{i}\right|}} ∣Nu∣∣Ni∣1就是衰减因子 p u i p_{u i} pui。
信息聚合:
e u ( 1 ) = LeakyReLU ( m u ← u + ∑ i ∈ N u m u ← i ) \mathbf{e}_{u}^{(1)}=\text { LeakyReLU }\left(\mathbf{m}_{u \leftarrow u}+\sum_{i \in \mathcal{N}_{u}} \mathbf{m}_{u \leftarrow i}\right) eu(1)= LeakyReLU (mu←u+i∈Nu∑mu←i)
到这里为止,形式上和GCN里的 A X W AXW AXW差的比较多,但是在思想上是相同的,用周围的点先更新一下自己,只不过计算方法有些差别。
high-order propagation
{ m u ← i ( l ) = 1 ∣ N u ∣ ∣ N i ∣ ( W 1 ( l ) e i ( l − 1 ) + W 2 ( l ) ( e i ( l − 1 ) ⊙ e u ( l − 1 ) ) ) m u ← u ( l ) = W 1 ( l ) e u ( l − 1 ) e u ( l ) = LeakyReLU ( m u ← u ( l ) + ∑ i ∈ N u m u ← i ( l ) ) \left\{\begin{array}{l} \mathbf{m}_{u \leftarrow i}^{(l)}=\frac{1}{\sqrt{\left|\mathcal{N}_{u}\right|\left|\mathcal{N}_{i}\right|}}\left(\mathbf{W}_{1}^{(l)} \mathbf{e}_{i}^{(l-1)}+\mathbf{W}_{2}^{(l)}\left(\mathbf{e}_{i}^{(l-1)} \odot \mathbf{e}_{u}^{(l-1)}\right)\right) \\ \mathbf{m}_{u \leftarrow u}^{(l)}=\mathbf{W}_{1}^{(l)} \mathbf{e}_{u}^{(l-1)} \end{array}\right. \\ \mathbf{e}_{u}^{(l)}=\text { LeakyReLU }\left(\mathbf{m}_{u \leftarrow u}^{(l)}+\sum_{i \in \mathcal{N}_{u}} \mathbf{m}_{u \leftarrow i}^{(l)}\right) ⎩⎨⎧mu←i(l)=∣Nu∣∣Ni∣1(W1(l)ei(l−1)+W2(l)(ei(l−1)⊙eu(l−1)))mu←u(l)=W1(l)eu(l−1)eu(l)= LeakyReLU (mu←u(l)+i∈Nu∑mu←i(l))
prediction layer
经过 L L L层的传播后,不是取用户 u u u最后一层的向量,而是把 L L L个向量 e u 1 , … , e u L e_{u}^{1}, \ldots, e_{u}^{L} eu1,…,euL串联拼接起来,最终得到用户 u u u的表示:
e u ∗ = e u ( 0 ) ∥ ⋯ ∥ e u ( L ) , e i ∗ = e i ( 0 ) ∥ ⋯ ∥ e i ( L ) \mathbf{e}_{u}^{*}=\mathbf{e}_{u}^{(0)}\|\cdots\| \mathbf{e}_{u}^{(L)}, \quad \mathbf{e}_{i}^{*}=\mathbf{e}_{i}^{(0)}\|\cdots\| \mathbf{e}_{i}^{(L)} eu∗=eu(0)∥⋯∥eu(L),ei∗=ei(0)∥⋯∥ei(L)
最后用向量内积得到预测结果:
y ^ N G C F ( u , i ) = e u ∗ ⊤ e i ∗ \hat{y}_{\mathrm{NGCF}}(u, i)=\mathbf{e}_{u}^{* \top} \mathbf{e}_{i}^{*} y^NGCF(u,i)=eu∗⊤ei∗
所以NGCF的整体框架:

LightGCN(SIGIR’20)
NGCF是经典之作,但是模型似乎有些太复杂了,本文先做实验证明NGCF模型的缺陷,然后简化了NGCF。
NGCF有缺陷

文章认为非线性激活函数和特征转换对CF模型没有用,在其他结点分类任务如文本分类中,每个结点都包含丰富的特征语义,如文章摘要等,在CF任务里每个结点只有ID输入,没有丰富的特征。也做了消融实验证明:

LightGCN
图卷积的定义为:
e u ( k + 1 ) = ∑ i ∈ N u 1 ∣ N u ∣ ∣ N i ∣ e i ( k ) e i ( k + 1 ) = ∑ u ∈ N i 1 ∣ N i ∣ ∣ N u ∣ e u ( k ) \begin{array}{l} \mathbf{e}_{u}^{(k+1)}=\sum_{i \in \mathcal{N}_{u}} \frac{1}{\sqrt{\left|\mathcal{N}_{u}\right|} \sqrt{\left|\mathcal{N}_{i}\right|}} \mathbf{e}_{i}^{(k)} \\ \mathbf{e}_{i}^{(k+1)}=\sum_{u \in \mathcal{N}_{i}} \frac{1}{\sqrt{\left|\mathcal{N}_{i}\right|} \sqrt{\left|\mathcal{N}_{u}\right|}} \mathbf{e}_{u}^{(k)} \end{array} eu(k+1)=∑i∈Nu∣Nu∣∣Ni∣1ei(k)ei(k+1)=∑u∈Ni∣Ni∣∣Nu∣1eu(k)
非线性激活函数没了,特征变换矩阵没了,也不整合自身节点了。
经过 K K K层后,用户、物品节点信息聚合为:
e u = ∑ k = 0 K α k e u ( k ) , e i = ∑ k = 0 K α k e i ( k ) \mathbf{e}_{u}=\sum_{k=0}^{K} \alpha_{k} \mathbf{e}_{u}^{(k)} , \\ \mathbf{e}_{i}=\sum_{k=0}^{K} \alpha_{k} \mathbf{e}_{i}^{(k)} eu=k=0∑Kαkeu(k),ei=k=0∑Kαkei(k)
所以模型能训练的参数只有重要性权重 α k \alpha_k αk和第0层的embedding,作者又将 α k = 1 / ( k + 1 ) \alpha_k = 1/(k+1) αk=1/(k+1)。
预测时做向量内积:
y ^ u i = e u T e i \hat{y}_{u i}=e_{u}^{T} e_{i} y^ui=euTei
LR-GCCF (AAAI’20)
和LightGCN同年,指出了NGCF非线性激活函数的缺点(但是没有去掉特征转换),所以改进了信息聚合的方法。文章提出了残差的思想,但实际上和NGCF一模一样。
信息聚合

对于每个用户和物品,传播的矩阵形式:
[ E k + 1 ] u = e u k + 1 = [ 1 d u e u k + ∑ j ∈ R u 1 d j × d u e j k ] W k [ E k + 1 ] i = e i k + 1 = [ 1 d i e i k + ∑ u ∈ R i 1 d i × d u e u k ] W k \begin{array}{l} {\left[\mathbf{E}^{k+1}\right]_{u}=\mathbf{e}_{u}^{k+1}=\left[\frac{1}{d_{u}} \mathbf{e}_{u}^{k}+\sum_{j \in R_{u}} \frac{1}{d_{j} \times d_{u}} \mathbf{e}_{j}^{k}\right] \mathbf{W}^{k}} \\ {\left[\mathbf{E}^{k+1}\right]_{i}=\mathbf{e}_{i}^{k+1}=\left[\frac{1}{d_{i}} \mathbf{e}_{i}^{k}+\sum_{u \in R_{i}} \frac{1}{d_{i} \times d_{u}} \mathbf{e}_{u}^{k}\right] \mathbf{W}^{k}} \end{array} [Ek+1]u=euk+1=[du1euk+∑j∈Rudj×du1ejk]Wk[Ek+1]i=eik+1=[di1eik+∑u∈Ridi×du1euk]Wk
其中 d i ( d u ) d_i(d_u) di(du)代表在用户项目二分图中的item i i i(user $ u ) 的 d i a g o n a l d e g r e e , )的diagonal degree, )的diagonaldegree,R_{*}$ 代表节点 ( ∗ ) (*) (∗) 在图 G \mathcal{G} G 中的邻居节点。
作者引入了残差的概念,第 k + 1 k+1 k+1层的输出等于上一层的输出加上第 k + 1 k+1 k+1层的向量内积:
r ^ u i k + 1 = r ^ u i k + < e u k + 1 , e i k + 1 > \hat{r}_{u i}^{k+1}=\hat{r}_{u i}^{k}+<\mathbf{e}_{u}^{k+1}, \mathbf{e}_{i}^{k+1}> r^uik+1=r^uik+<euk+1,eik+1>
所以模型的输出就是:
r ^ u i = r ^ u i K − 1 + < e u K , e i K > = r ^ u i K − 2 + < e u K − 1 , e i K − 1 > + < e u K , e i K > = r ^ u i 0 + < e u 1 , e i 1 > + … + < e u K , e i K > = < e u 0 ∥ e u 1 ∥ … ∥ e u K , e i 0 ∥ e i 1 ∥ … ∥ e i K > \begin{aligned} \hat{r}_{u i} &=\hat{r}_{u i}^{K-1}+<\mathbf{e}_{u}^{K}, \mathbf{e}_{i}^{K}>\\ &=\hat{r}_{u i}^{K-2}+<\mathbf{e}_{u}^{K-1}, \mathbf{e}_{i}^{K-1}>+<\mathbf{e}_{u}^{K}, \mathbf{e}_{i}^{K}>\\ &=\hat{r}_{u i}^{0}+<\mathbf{e}_{u}^{1}, \mathbf{e}_{i}^{1}>+\ldots+<\mathbf{e}_{u}^{K}, \mathbf{e}_{i}^{K}>\\ &=<\mathbf{e}_{u}^{0}\left\|\mathbf{e}_{u}^{1}\right\| \ldots\left\|\mathbf{e}_{u}^{K}, \quad \mathbf{e}_{i}^{0}\right\| \mathbf{e}_{i}^{1}\|\ldots\| \mathbf{e}_{i}^{K}> \end{aligned} r^ui=r^uiK−1+<euK,eiK>=r^uiK−2+<euK−1,eiK−1>+<euK,eiK>=r^ui0+<eu1,ei1>+…+<euK,eiK>=<eu0∥∥eu1∥∥…∥∥euK,ei0∥∥ei1∥…∥eiK>
这就是本文标题中的“Linear Residual”,但是我们看看,它是不是其实和NGCF一模一样:
e u ∗ = e u ( 0 ) ∥ ⋯ ∥ e u ( L ) , e i ∗ = e i ( 0 ) ∥ ⋯ ∥ e i ( L ) y ^ N G C F ( u , i ) = e u ∗ ⊤ e i ∗ \mathbf{e}_{u}^{*}=\mathbf{e}_{u}^{(0)}\|\cdots\| \mathbf{e}_{u}^{(L)}, \quad \mathbf{e}_{i}^{*}=\mathbf{e}_{i}^{(0)}\|\cdots\| \mathbf{e}_{i}^{(L)} \\ \hat{y}_{\mathrm{NGCF}}(u, i)=\mathbf{e}_{u}^{* \top} \mathbf{e}_{i}^{*} eu∗=eu(0)∥⋯∥eu(L),ei∗=ei(0)∥⋯∥ei(L)y^NGCF(u,i)=eu∗⊤ei∗