c++第10章·泛型程序设计与c++标准模板库
泛型程序设计的基本概念

类型T必须具备3个功能:
1.类型T的变量之间能够比较大小
2.类型T必须具有公有的复制构造函数
3.类型T的变量之间可以用 = 赋值
概念、模型


容器
共性


顺序容器
将一组具有相同类型的元素以严格的线性形式组织起来
vector(将已有元素删除(erase会释放内存),多出闲置空间不会被释放,再插入新的元素时可能会重新占用这些空间。因此,向量容器对象已分配的空间所能容纳的元素个数,前者叫容量【capacity】,后者叫大小【size】)
#include
using namespace std;
int main(){
vector a;
for(int i=0;i<5;++i){
a.push_back(i);
}
cout< a.capacity()返回a的容量大小
deque(类似queue,但是可以在队列头增加元素,队列尾删除元素。deque 容器中存储元素并不能保证所有元素都存储到连续的内存空间中){deque添加完元素后会使所有迭代器失效}
list(splice()接合)


比较

通用功能


关联容器
set、multiset
map、multimap(set和map都是接触过的,基本用法掌握)
迭代器(iterator)
迭代器(iterator)是一种可以遍历容器元素的数据类型。迭代器是一个变量,相当于容器和操纵容器的算法之间的中介。C++更趋向于使用迭代器而不是数组下标操作,因为标准库为每一种标准容器(如vector、map和list等)定义了一种迭代器类型,而只有少数容器(如vector)支持数组下标操作访问容器元素。可以通过迭代器指向你想访问容器的元素地址,通过*x打印出元素值。这和我们所熟知的指针极其类似
List,是链表实现的,我们知道,链表的元素都存储在一段不是连续的地址空间中。我们需要通过next指针来访问下一个元素。那么,我们也可以通过访问list的迭代器来实现遍历list容器元素
容器都有成员begin和end,其中begin成员复制返回指向第一个元素的迭代器(用*迭代器打印出元素值),而end成员返回指向容器尾元素的下一个位置的迭代器,它是一个不存在的元素位置
例子
vector ::iterator it;
for( it = vector.begin(); it != vector.end(); it++ )
cout<<*it<::reverse_iterator it = v.rbegin(); it!=v.rend();it++ )
cout<<*it< 输入流迭代器

输出流迭代器
 说明
说明

例子
int main()
{
istream_iteratoros(cin); //会等待输入数据
istream_iteratorend1;
while(1)
{
cout<<*os< 输入流迭代器os一旦被创建,则就会等待键盘输入数据,按下回车后则输入的数据进入输入流,继续下一条指令
int main()
{
ostream_iteratoros(cout," ");
*os=1;
os++;
*os=2;
return 0;
} *os=1;执行后屏幕上立刻输出1;
函数对象
如果一个类将()运算符重载为成员函数,这个类就称为函数对象类,这个类的对象就是函数对象。函数对象是一个对象,但是使用的形式看起来像函数调用,实际上也执行了函数调用,因而得名

在accmulate算法中的应用
#include
#include
#include //accumulate 在此头文件定义
using namespace std;
template
void PrintInterval(T first, T last)
{ //输出区间[first,last)中的元素
for (; first != last; ++first)
cout << *first << " ";
cout << endl;
}
int SumSquares(int total, int value)
{
return total + value * value;
}
template
class SumPowers
{
private:
int power;
public:
SumPowers(int p) :power(p) { }
const T operator() (const T & total, const T & value)
{ //计算 value的power次方,加到total上
T v = value;
for (int i = 0; i < power - 1; ++i)
v = v * value;
return total + v;
}
};
int main()
{
const int SIZE = 10;
int a1[] = { 1,2,3,4,5,6,7,8,9,10 };
vector v(a1, a1 + SIZE);
cout << "1) "; PrintInterval(v.begin(), v.end());
int result = accumulate(v.begin(), v.end(), 0, SumSquares);
cout << "2) 平方和:" << result << endl;
result = accumulate(v.begin(), v.end(), 0, SumPowers(3));
cout << "3) 立方和:" << result << endl;
result = accumulate(v.begin(), v.end(), 0, SumPowers(4));
cout << "4) 4次方和:" << result;
return 0;
} 程序的输出结果如下:
1)1 2 3 4 5 6 7 8 9 10
2)平方和:385
3)立方和3025
4)4次方和:25333
第 37 行,第四个参数是 SumSquares 函数的名字。函数名字的类型是函数指针
int accumulate(vector ::iterator first, vector ::iterator last, int init, int(*op)(int, int))
{
for (; first != last; ++first)
init = op(init, *first);
return init;
} 形参 op 是一个函数指针,而op(init, *first)就调用了指针 op 指向的函数,在第 37 行的情况下就是函数 SumSquares
第 39 行,第四个参数是 SumPowers
在sort算法中的应用
#include
#include //sort算法在此头文件中定义
using namespace std;
template
void Printlnterva1(T first, T last)
{ //用以输出 [first, last) 区间中的元素
for (; first != last; ++first)
cout << *first << " ";
cout << endl;
}
class A
{
public:
int v;
A(int n) : v(n) {}
};
bool operator < (const A & a1, const A & a2)
{ //重载为 A 的 const 成员函数也可以,重载为非 const 成员函数在某些编译器上会出错
return a1.v < a2.v;
}
bool GreaterA(const A & a1, const A & a2)
{ //v值大的元素作为较小的数
return a1.v > a2.v;
}
struct LessA
{
bool operator() (const A & a1, const A & a2)
{ //v的个位数小的元素就作为较小的数
return (a1.v % 10) < (a2.v % 10);
}
};
ostream & operator << (ostream & o, const A & a)
{
o << a.v;
return o;
}
int main()
{
int a1[4] = { 5, 2, 4, 1 };
A a2[5] = { 13, 12, 9, 8, 16 };
sort(a1, a1 + 4);
cout << "1)"; Printlnterva1(a1, a1 + 4); //输出 1)1 2 4 5
sort(a2, a2 + 5); //按v的值从小到大排序
cout << "2)"; Printlnterva1(a2, a2 + 5); //输出 2)8 9 12 13 16
sort(a2, a2 + 5, GreaterA); //按v的值从大到小排序
cout << "3)"; Printlnterva1(a2, a2 + 5); //输出 3)16 13 12 9 8
sort(a2, a2 + 5, LessA()); //按v的个位数从小到大排序
cout << "4)"; Printlnterva1(a2, a2 + 5); //输出 4)12 13 16 8 9
return 0;
} 编译至第 45 行时,编译器将 sort 实例化得到的函数原型如下:
void sort(A* first, A* last, bool (*op)(const A &, const A &) );该函数在执行过程中,当要比较两个元素 a、b 的大小时,就是看 op(a, b) 和 op(b, a) 的返回值。本程序中 op 指向 GreaterA,因此就用 GreaterA 定义的规则来比较大小(返回值为真的排序)
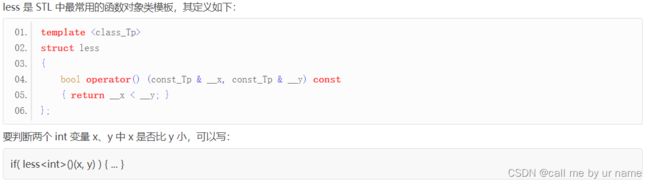
STL 中定义了一些函数对象类模板,都位于头文件 functional 中。例如,greater 模板的源代码如下:
template
struct greater
{
bool operator()(const T& x, const T& y) const{
return x > y;
}
}; 
STL中函数对象类模板


 算法
算法
算法本身就是一种函数模板
头文件
STL中算法大致分为四类:
1、非可变序列算法:指不直接修改其所操作的容器内容的算法。
2、可变序列算法:指可以修改它们所操作的容器内容的算法。
3、排序算法:包括对序列进行排序和合并的算法、搜索算法以及有序序列上的集合操作。
4、数值算法:对容器内容进行数值计算。
非可变序列算法

 lower_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
lower_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
upper_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
两个函数都是左闭右开
count_if(beg,end,func):函数count的_if版本
可变序列算法
 关于copy函数:
关于copy函数:
std::copy(start, end, container);start,end是需要复制的源文件的头地址和尾地址,container是接收器的起始地址
copy,transform,fill_n和generat都需要保证:输出序列有足够的空间
删除函数并不真正删除元素,只是将要删除的元素移动到容器的末尾,删除元素需要容器擦除函数来操作。同理,独特的函数也不会改变容器的大小,只是这些元素的顺序改变了,是将无重复的元素复制到序列的前端,从而覆盖相邻的重复元素.unique返回的迭代器指向超出无重复的元素范围末端的下一位置(呼应前文中vector的capacity大于size)
排序算法

partial_sort对区间[beg,end]内的mid - beg个元素进行排序,将最小的mid - beg个元素有序放在序列的前mid - beg的位置上。
reverse_copy(beg,end,dest):reverse的_copy版本。
rotate_copy(beg,mid,end,dest):rotate的_copy版本。
数值算法

accumulate
int sum = accumulate(vec.begin() , vec.end() , 42);accumulate带有三个形参:头两个形参指定要累加的元素范围,第三个形参则是累加的初值
string sum = accumulate(v.begin() , v.end() , string(" "));这个函数调用的效果是:从空字符串开始,把vec里的每个元素连接成一个字符串
adjacent_difference
#include
#include "adjacent_difference.h"
#include
#include
using namespace std;
int main(void) {
int a[5] = {0, 1, 2, 3, 4};
vector ivec(a, a+5);
ostream_iterator oite(cout, " ");
adjacent_difference(ivec.begin(), ivec.end(), oite); // 0 1 1 1 1
cout << endl;
adjacent_difference(ivec.begin(), ivec.end(), oite, plus()); // 0 1 3 5 7
system("pause");
return 0;
} 第一个值保持原序列的第一个值
partial_sum
类似adjacent_difference用法
#include
#include // inner_product
#include
using namespace std;
int main()
{
int ia[5] = { 1, 2, 3, 4, 5 };
vector iv(ia, ia + 5);
cout << inner_product(iv.begin(), iv.end(), iv.begin(), 10) << endl;
// result: 10 + 1 * 1 + 2 * 2 + 3 * 3 + 4 * 4 + 5 * 5
// 此版本 accumulate 需要用户传入一个二元仿函数对象
// 此处主要为了实现一般内积
cout << inner_product(iv.begin(), iv.end(), iv.begin(), 10, minus(), plus) << endl;
// result: 10 - (1 + 1) - (2 + 2) - (3 + 3) - (4 + 4) - (5 + 5)
}
inner_product()的第3个参数好像没什么意义(就写同第一个参数一样的应该不影响使用)
template
T inner_product(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, T init) {
// 提供 init 的原因和算法 acculumate 一致
for ( ; first1 != last1; ++first1, ++first2)
init = init + (*first1 * *first2);
return init;
}