基于CNN的动态手势识别:Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks
Real-time Hand Gesture Detection and Classification Using Convolutional Neural Networks论文解读
- 1. 概述
- 2. 简介
- 3. 方法
-
- 3.1 构架
- (1)检测器
- (2)分类器
- (3)后处理
- (4)一次性激活(Single-time Activation)
- (5)激活的评估
- 4. 实验
-
- 4.1 使用EgoGesture数据集的离线结果
- 4.2 离线结果使用nvGesture数据集
- 4.3 实时分类结果
- 结论和展望
论文链接:https://arxiv.org/abs/1901.10323
论文代码(PyTorch版本):https://github.com/ahmetgunduz/Real-time-GesRec
论文出处:CVPR2019
1. 概述
- 从视频流中实时识别动态手势是一项具有挑战性的任务,因为(i)在视频中没有指示手势何时开始和结束,(ii)所表演的手势只应识别一次,以及(iii)考虑内存和功率预算,设计整个架构。
- 在这项工作中,我们提出了一个分层结构,使离线工作的卷积神经网络(CNN)架构通过滑动窗口方法在线有效地运行,以解决这些挑战。
- 提出的体系结构由两个模型组成:(1)一个用于检测手势的轻量级CNN架构检测器和(2)一个用于对检测到的手势进行分类的深度CNN分类器。
- 为了评估检测到的手势的一次性激活情况,我们提出使用Levenshtein距离作为评估指标,因为它可以同时测量误分类、多次检测和漏检。
- 我们在两个公开的数据集上评估我们的架构:EgoGesture 和 NVIDIA Dynamic 手势数据集,这两个数据集需要对手势进行时间检测和分类。
- 使用ResNeXt-101模型作为分类器,在EgoGesture和NVIDIA基准测试中,深度模态的离线分类精度分别达到了94.04%和83.82%。
2. 简介
-
手势识别在人机交互中的各种应用可能性也使其在研究界越来越受欢迎。与鼠标和键盘相比,任何基于视觉的界面都更方便、实用、自然,因为手势的直观性。
-
手势识别主要有三种方法:
(i)基于手套的可穿戴设备,第一种方法需要佩戴额外的设备,其中有很多电缆,尽管它在精确度和速度方面都有很好的效果。
(ii)手关键点的三维位置,第二种方法需要额外的手关键点提取步骤,需要额外的时间和计算成本。
(iii)原始视觉数据,只需要一个与用户无关的图像捕捉传感器,如相机、红外传感器或深度传感器。由于使用者无须佩戴沉重的装置,便可获得可接受的识别精度和足够的计算速度,因此这一选择脱颖而出,成为最实用的选择。 -
在本工作中,为了提供一个实际的解决方案,我们开发了一种基于视觉的手势识别方法,使用深度卷积神经网络(cnn)对原始视频数据。目前,cnn不仅为基于图像的任务(如对象检测、图像分割和分类)提供了最先进的结果,而且还为基于视频的任务(如活动识别、动作定位和手势识别)提供了最先进的结果。
-
在实时手势识别应用中,系统需要满足以下几个特点:
(i)可接受的分类精度,
(ii)快速反应时间,
(iii)资源效率
(iv)每个动作的单次激活。 -
然而,以往的研究大多只考虑了(i),并试图在手势识别中提高离线分类的准确性,而忽略了其余项目。
-
在本文中,我们提出了一种用于实时手势检测和分类的层次结构,该结构允许我们集成离线工作模型,同时仍然满足上述所有属性。
-
我们的系统由一个离线训练的深度3D CNN手势分类(分类器)和一个轻量级、浅层的3D CNN手势检测(检测器)。
-
图1显示了所提出方法的流程。滑动窗口用于传入视频流,通过检测器队列向检测器提供输入帧。

图1. 视频流的处理采用跨距(stride)为1的滑动窗口方法。上面的图表显示了一个手势开始时被激活的检测器概率分数,并一直保持激活状态直到手势结束。第二个图用不同的颜色显示每个类的分类分数。第三个图对原始分类分数应用加权平均过滤,消除了可能的手势候选之间的歧义。下图说明了单次激活,红色箭头表示动作早期检测,黑色箭头表示手势完成后的检测。 -
图1中最上面的图表显示了在执行手势时活跃的检测器概率得分,在其余时间保持不活跃。只有当检测器检测到一个手势时,分类器才会激活。这是非常关键的,因为在大多数情况下,在实时手势识别应用程序中没有手势执行。因此,不需要一直保持高性能分类器处于活动状态,这大大增加了系统的内存和功耗。
-
第二个图用不同的颜色显示了每个类的原始分类分数。从图中可以看出,类似的类别的分数同时变得很高,特别是在手势的开始。
-
为了解决这些歧义,我们对类别分数进行加权,以避免在手势开始时就做出决定(图1中的第三个图表)。
-
最后,下图显示了单次激活,红色箭头表示早期检测,黑色箭头表示手势完成后的检测。
-
使用Levenshtein距离作为评价指标来比较捕获的单次激活与ground-truth标签。该度量方法可以同时度量误分类、多次检测和漏检,具有较高的适用性和可评价性。
-
对于所提出方法的分类器,可以使用任何离线工作的CNN架构。在我们的实验中,我们使用了著名的C3D和ResNeXt-101。
-
利用ResNeXt-101实现了SOAT的深度模式离线分类准确率94.03%和83.82%分别在EgoGesture和nvGesture数据集上。
-
对于实时检测和分类,我们通过放弃少量的识别性能来实现相当大的早期检测。
3. 方法
3.1 构架
- 最近,随着大数据集的可用性,基于CNN的模型已经证明了它们在动作/手势识别任务中的能力。3D CNN架构在视频分析中尤其突出,因为它们利用了帧之间的时间关系以及它们的空间内容。
然而,对于如何在实时动态系统中使用这些模型,还没有明确的描述。通过我们的工作,我们的目标是填补这一研究空白。 - 图2显示了使用滑动窗口方法的有效实时识别系统的工作流程。与离线测试相反,我们不知道手势何时开始或结束。正因为如此,我们的工作流程从一个检测器开始,当一个手势被检测到时,检测器被用作一个开关来激活分类器。

图2. 提出的两模型层次结构的一般工作流程。带有stride的滑动窗口在检测器队列位于分类器队列最开始的位置的传入视频帧中运行。如果检测器识别出一个动作/手势,那么分类器就会被激活。检测器的输出经过后处理以获得更健壮的性能,并且最终的决定是使用一次性激活块做出的,即每个执行的手势只有一个激活。 - 我们的检测器和分类器模型由大小分别为n和m的帧序列提供,n远小于m,且有一个重叠因子。
- 图2所示。滑动窗口使用的stride值在图2中用s表示,检测器和分类器都是一样的。虽然更高的步幅提供更少的资源使用,但我们选择s为1,因为它足够小,不会错过任何手势,并允许我们获得更好的性能。
- 除了检测器和分类器模型,还有一个后处理和一个一次性激活。
(1)检测器
- 检测器的目的是区分手势类和无手势类。它的主要且唯一的作用是充当分类器模型的开关,这意味着如果它检测到一个手势,那么分类器就会被激活并由分类器队列中的帧提供信息。
- 由于该系统的总体精度高度依赖于检测器的性能,我们要求检测器(i)鲁棒性,(ii)准确检测真阳性(手势)和(iii)轻量,因为它连续运行。
- 对于(i),让检测器运行在比分类器更少的帧数上。
- 对于(ii),将检测器队列置于分类器队列的最开头,如图2所示。这使得检测器可以激活分类器,无论何时一个手势开始,而不管手势持续时间。此外,为了减少误报的可能性(即获得更高的召回率),检测器模型采用weightedcross entropy loss进行训练。对于无手势类和手势类,我们选择的分类权值分别为1和3,因为我们的实验表明,这个比例足够在EgoGesture和nvGesture数据集中分别有98+%和97+%的召回率。此外,我们对输出的概率进行了后处理,并在去激活分类器的决策中设置了连续的无手势预测次数的计数器。
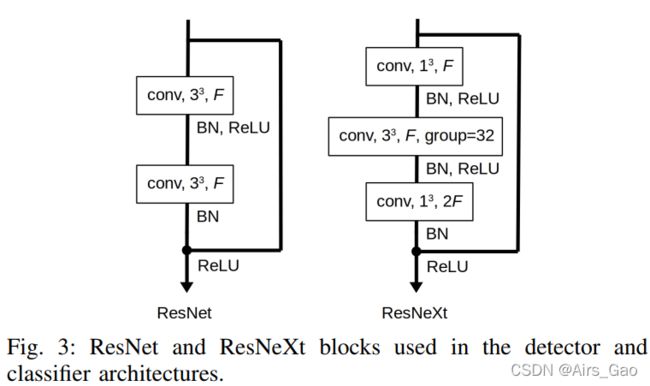
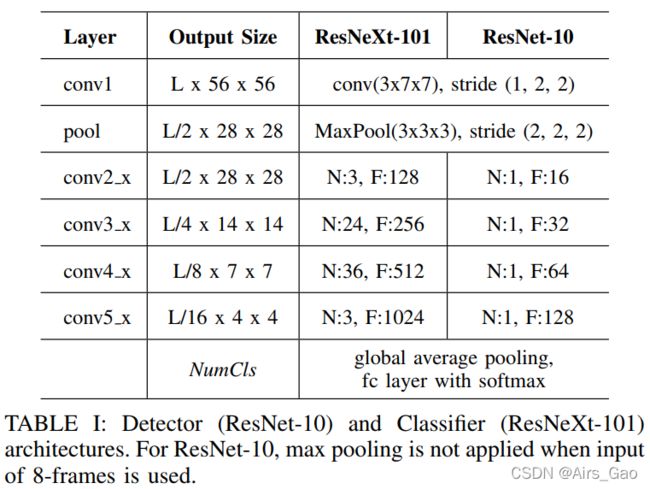
- 对于 (iii) ,使用图3中的ResNet块构造ResNet-10架构,每一层的特征尺寸都非常小,如表I所示,这样可以得到小于1M(≈862K)的参数。F、N分别为对应层的特征通道个数和分块个数。图3中的BN、ReLU和group分别为批量归一化、校正的线性单元非线性和群卷积数。
(2)分类器
- 由于我们对模型的大小和复杂性没有任何限制,任何提供良好分类性能的体系结构都可以被选择为分类器。这导致我们使用两个最近的3D CNN架构(C3D和ResNext-101)作为我们的分类器模型。然而,重要的是要注意我们的体系结构是独立于模型类型的。
- 对于C3D模型,我们已经使用了与[19]一样的模型, 但仅将后两个全连通层的节点数量从4096个改变为2048个。
- 对于ResNeXt-101,我们遵循了[6]的指导方法,选取的模型参数如表1所示,ResNeXt块如图3所示。
- 由于3D cnn的参数数量远远多于2D cnn,为了防止过拟合,3D cnn需要更多的训练数据。因此,我们首先在Jester数据集上对分类器架构进行了预训练,这是最大的公开可用的手势数据集,然后在EgoGesture和nvGesture数据集上对我们的模型进行微调。该方法提高了训练的准确性,大大缩短了训练时间。
(3)后处理
- 在动态手势中,在执行手势时,手可能会离开摄像机视图。即使先前对探测器的预测是正确的,任何错误的分类都会降低所提议的体系结构的整体性能。
- 为了利用以前的预测,我们将以前的检测器预测的原始softmax概率添加到队列中(qk),大小为k,并对这些原始值进行过滤,获得最终的检测器决策。利用这种方法,检测器提高了决策的信心,并消除了连续预测中的大部分错误分类。我们选择队列大小(k)为4,在我们的实验中,stride s为1时取得了最好的结果。
- 我们分别对qk中的值进行了(i)平均、(ii)指数加权平均和(iii)中值滤波。平均滤波取qk的平均值,中值滤波取中值。在这三种过滤策略中,我们使用了中值过滤,因为它的效果稍好一些。
(4)一次性激活(Single-time Activation)
- 在实时手势识别系统中,缩短每个手势的反应时间和单次激活是非常重要的。Pavlovic等人指出,动态手势有准备(preparation),有核(nucleus)(峰值)和缩回(retraction )部分。在所有的部分中,核是最具鉴别性的一个,因为我们可以决定哪些手势在核部分执行,甚至在它结束之前预测出。
- 通过两级控制机制实现一次激活。要么当置信度测量在手势实际结束前达到阈值水平时检测到手势(早期检测),要么在检测器使分类器失效时预测手势(晚期检测)。在晚期检测中,我们假设检测器不应该错过任何手势,因为我们保证检测器有非常高的召回率。
- 早期检测最关键的部分是,手势应在其核部分后检测,以获得更好的识别性能。因为一些手势可能包含类似的准备部分,这在手势的开始就造成了一种模糊性,如图5的顶部图所示。
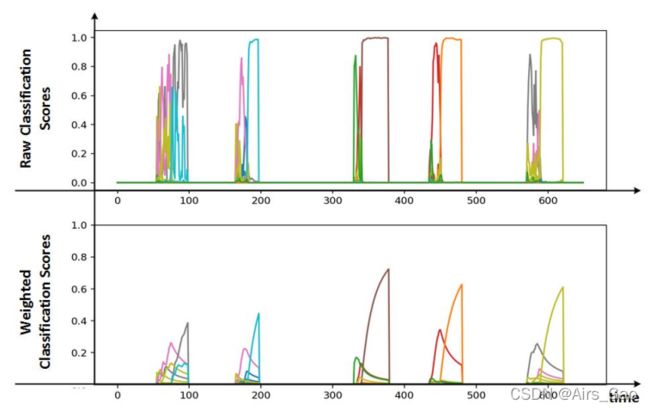
图5 原始(上)和加权(下)分类分数。在上面的图表中,我们观察到在所有手势的开始都有很多噪音;然而,在每个手势接近尾声时,分类器会变得更加自信。下面的图表显示,我们可以通过给手势的开始部分分配更小的权重来消除这一噪声部分。 - 因此,我们对类别分数应用了加权平均法,其权重函数为图4 (b)
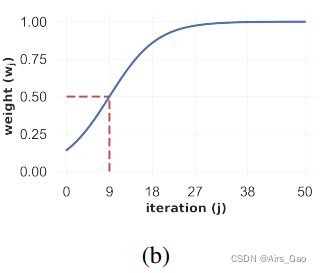
图4(b)根据该方程,用于单次激活的类sigmoid权重函数
它的公式为:
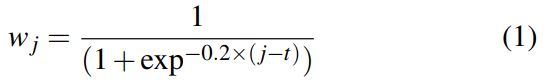
- 5显示了5个手势在每次迭代中的概率得分及其对应的加权平均值。可以很容易观察到在手势的准备阶段的模糊性被成功解决。
- 通过这种加权平均策略,迫使我们的单次激活器在捕捉到手势的核心部分后,在手势的中后期做出决定。另一方面,由于手势持续时间的变化,我们需要一个置信度测量来进行实时的早期检测。因此,我们决定使用每个类别加权平均分数的差值作为我们早期检测的置信度指标。当检测器打开分类器时,在每次迭代中计算每个类的加权平均概率。如果两个最高平均概率之间的差大于一个阈值t_early,然后触发早期检测。否则,我们等待检测器关闭分类器,此时大于 t_late (固定为0.15,因为它在我们的实验中显示了最好的结果)的最高分数的类别被预测作为延迟检测。这个策略的细节可以在算法中找到:

(5)激活的评估
- 与离线测试不同,离线测试通常只考虑类的准确性,我们还必须考虑以下场景来进行实时评估:
(a)分类器对手势的错误分类,
(b)检测器没有检测到手势,
(c)多个检测在一个手势。 - 考虑到这些情况,我们建议使用Levenshtein距离作为在线实验的评估指标。Levenshtein距离是一种度量,它通过计算将一个序列转换为另一个序列的项目级更改(插入、删除或替换)的数量来度量序列之间的距离。在我们的例子中,一个视频和这个视频中的手势分别对应于一个序列和序列中的项。
- 例如,让我们考虑以下ground truth和视频的预测手势:

- 在本例中,Levenshtein距离为2:删除两次检测到的“6”中的一个,将“7”替换为“3”。我们用真正目标类别的数量来平均这个距离。对于这种情况,平均距离是2/9 = 0.2222,然后我们从1中减去这个值,因为我们想测量我们的结果的接近度(在这项工作中,它被称为Levenshtein精度),它等于(1−0.2222)×100 = 77.78%。
4. 实验
- 该方法的性能在两个公开的数据集上进行了测试:EgoGesture和NVIDIA动态手势数据集。
4.1 使用EgoGesture数据集的离线结果
- EgoGesture数据集是近年来发展起来的一种用于自我中心手势识别的多模态大规模数据集[24]。该数据集不仅用于分割的手势分类,也用于连续数据中的手势检测。从6个不同的室内和室外场景中收集了83类静态和动态手势。数据集分割由不同的受试者以3:1:1的比例创建,得到1239个训练视频、411个验证视频和431个测试视频,分别有14416、4768和4977个手势样本。所有模型首先在Jester数据集[1]上进行预训练。对于测试集的评估,我们使用了训练集和验证集进行训练。
- 我们初步研究了C3D和离线分类任务上的ResNeXt架构。表格II显示了使用的架构与最新的方法的比较。采用32帧输入的ResNeXt-101架构可获得最佳性能。
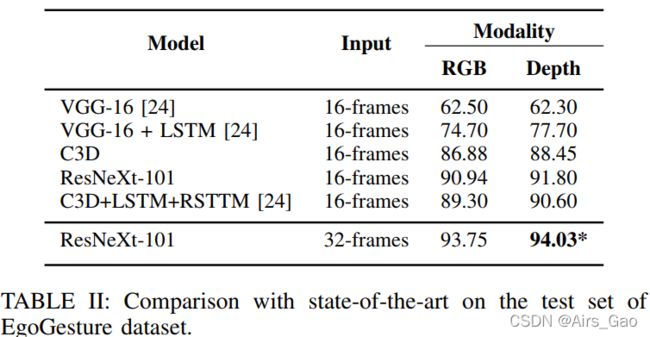
- 其次,我们研究了输入帧数对手势检测和分类性能的影响。表三和表四的结果显示,当我们增加所有模式的输入尺寸时,我们获得了更好的性能。这在很大程度上取决于所使用的数据集的特征,特别是手势的平均持续时间。
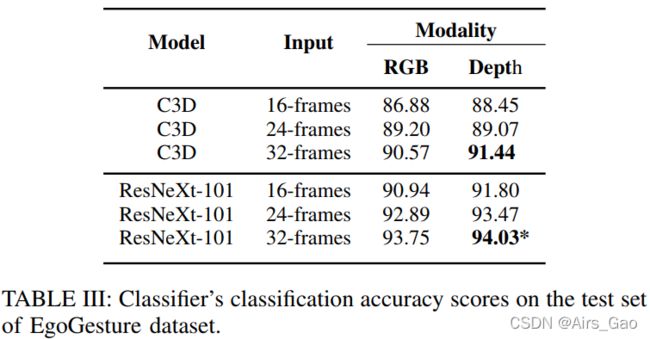
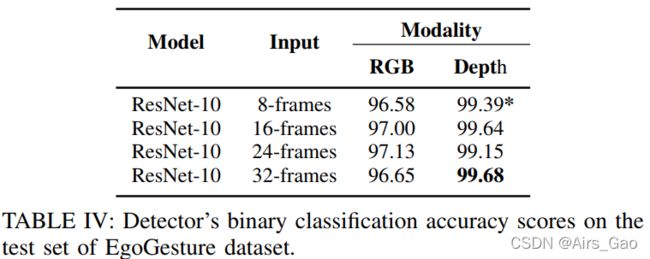
- 第三,研究了不同输入尺寸下的RGB和深度模式。我们一直观察到,具有深度模态的模型比具有RGB模态的模型表现得更好。深度传感器滤除背景运动,并允许模型更多地关注手部运动,因此可以从深度模态获得更多的鉴别特征。对于实时评估,选择深度模态和输入大小为8帧的ResNet-10作为检测器,因为较小的窗口大小允许检测器更鲁棒地发现手势的开始和结束。该模型的详细结果如表V所示

4.2 离线结果使用nvGesture数据集
- nvGesture数据集包含25个手势类,每个类用于人机界面。该数据集通过室内汽车模拟器的多个传感器和视点进行记录。一共有1532个弱分割视频(即视频中没有手势部分),以7:3的比例分割,得到1050个训练视频和482个测试视频,每个视频只包含一个手势。
- 通过将C3D和ResNeXt架构与最先进的模型进行比较,我们再次初步研究了C3D和ResNeXt架构在离线分类任务中的性能。
- 如表VI所示,ResNeXt-101架构达到了最佳性能。
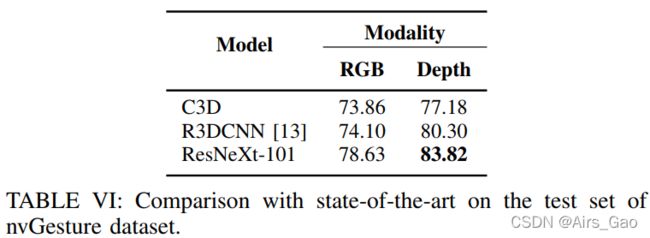
- 与EgoGesture数据集类似,对于所有的模式,随着输入尺寸的增加,我们实现了更好的分类和检测性能,如图所示表七和表八。


- 对于所有的输入尺寸,深度模态再次获得比RGB模态更好的性能。此外,ResNet-10具有深度模态,输入大小为在线测试中选择8帧作为检测器,详细结果见表9。

- 为了实时评估,我们选择了8帧两个数据集中具有深度模态的ResNet-10检测器和性能最好的分类器,对应的表中有*符号。
4.3 实时分类结果
- 在EgoGesture和nvGesture数据集的测试集中,分别有431和482个视频。我们在每个视频上分别评估了我们提出的架构,并在最后计算了平均Levenshtein精度。我们实现在EgoGesture和nvGesture数据集中,Levenshtein的准确率分别为91.04%和77.39%.
- 此外,通过模拟不同的早期检测阈值水平(t_early)在0.2 ~ 1.0之间变化,采用0.1步长来研究早期检测时间。
- 图6为加权平均法和均匀平均法在EgoGesture 和 nvGesture数据集上的早期检测次数比较。
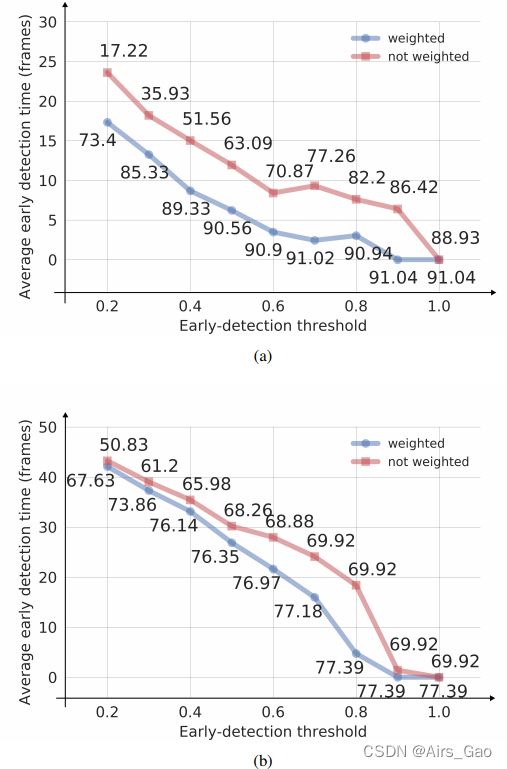
图6 比较(a) EgoGesture和(b) nvGesture数据集的早期检测时间、早期检测阈值和获得的Levenshtein准确率。 - 图6显示了加权平均的重要性,它比均匀平均要好得多。
随着阈值的增加,我们迫使体系结构在手势结束时做出决策,从而实现更好的性能。 - 然而,我们可以通过放弃少量的性能来获得可观的早期检测性能。例如,如果我们将检测阈值设置为0.4,对于EgoGesture数据集,我们可以通过放弃仅1.71%的Levenshtein准确性,使我们的单次激活平均提前9帧。我们还观察到,由于nvGesture数据集包含了弱分割的视频,所以它的平均早期检测时间更长。
- 最后,我们研究了双模型方法的执行性能。我们的系统在没有手势的情况下平均运行速度为460帧/秒(即只有检测器处于活动状态).
在单个NVIDIA Titan Xp GPU上,batch size为大小为8的情况下,以ResNeXt-101 (C3D)作为分类器,在有手势的情况下(即检测器和分类器同时开启)速度可达到62 (41) fps。
结论和展望
- 本文提出了一种新颖的双模型层次结构,用于实时手势识别系统。该体系结构提供了资源效率、早期检测和单次激活,这些都是实时手势识别应用的关键。
- 在未来的工作中,我们希望对单次激活的置信测量的统计假设检验进行更多的研究。
为了进一步提高性能,我们打算使用不同的加权方法。