迁移学习笔记2:类别总结
什么是迁移学习
迁移学习定义
利用任务、数据、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
相似性的这几个方面详细说
任务的相似性是在选定迁移源和目标时候确定的. 而其他的几个都有技术手段可以处理
任务的相似性
如果任务不相似, 很可能产生负迁移
之前会骑自行车,要学习骑摩托车,这种相似性指的就是自行车和摩托车之间的 相似性以及骑车体验的相似性。这种相似性在我们人类看来是可以接受的。
要拿骑自行车的经 验来学习开汽车,这显然是不太可能的。因为自行车和汽车之间基本不存在什么相似性。所 以,这个任务基本上完不成。
数据的相似性
基于样本的迁移学习方法 (Instance based Transfer Learning)
权重重用, 相似的样本,给高权重
基于特征的迁移学习方法 (Feature based Transfer Learning)
特征进行变换. 假设源域和目标域的特征原来不在一个空间,或者在原来那个空间上不相似,把它们变换到一个空间里面.(研究热门)
模型的相似性
基于模型的迁移学习方法 (Model based Transfer Learning)
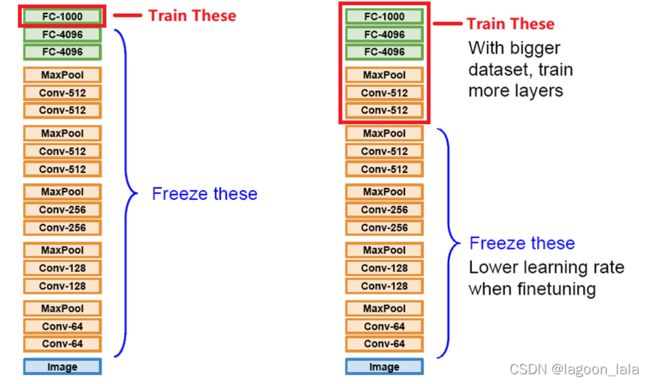
构建参数共享的模型. 神经网络最经典的finetune就是模型参数迁移(用的多)
固定前面若干层的参数,只针对我们的任务,微调后面若干层
基于关系的迁移学习方法 (Relation based Transfer Learning)
利用关系(授课/开会)进行类比. 较少使用
迁移学习的核心问题: 找到新问题和原问题之间的相似性
找到才可以顺利地实现知识的迁移。比如天气问题中,那些北半球的天气之所以相似,是因为它们的地理位置相似;而南北半球的天气之所以有差异,也是因为地理位置有根本不同
基本概念
常用符号
| 符号 |
含义 |
| $$ \mathcal{D}_{s}= \left\{\mathbf{x}_{i}, y_{i}\right\}_{i=1}^{n}/ \mathcal{D}_t= \left\{\mathbf{x}_{j}\right\}_{j=n+1}^{n+m} $$ |
源域数据 / 目标域数据 |
| $$ \mathbf{x} / \mathbf{X} / \mathcal{X} $$ |
样本向量 / 数据集矩阵 / 特征空间 |
| $$ \mathbf{y} / \mathcal{Y} $$ |
类别向量 / 类别空间 |
| $$ (n,m) (n_1,n_2) (n_s,n_t) $$ |
(源域样本数,目标域样本数) |
| $$ P(\mathbf{x}_s) / P(\mathbf{x}_t) $$ |
源域数据 / 目标域数据的边缘分布 一般难以给出P 的具体形式 |
| $$ Q\left(\mathbf{y}_{s} \mid \mathbf{x}_{s}\right) / Q\left(\mathbf{y}_{t} \mid \mathbf{x}_{t}\right) $$ |
源域数据 / 目标域数据的条件分布 |
| $$ f(\cdot) $$ |
要学习的目标函数 |
领域 (Domain)
学习的主体
领域(花体D)=数据+数据的概率分布(大写斜体P)
$$ \mathcal{D}=\mathbf X_\mathcal{D}+ P(\mathbf X_\mathcal{D}) $$

数据的边缘分布不同,就是数据整体不相似。
数据的条件分布不同,就是数据整体相似,但是具体到每个类里,都不太相似。
迁移: 知识从源领域传递到目标领域
两个基本领域: 源领域Source Domain(有知识/标注)和目标领域Target Domain(赋予知识/标注)
$$ \mathcal{D}_{s}= \left\{\mathbf{x}_{i}, y_{i}\right\}_{i=1}^{n}\\ \Downarrow \\ \mathcal{D}_t= \left\{\mathbf{x}_{j}\right\}_{j=n+1}^{n+m} $$
迁移学习方法
传统的非深度迁移、深度网络的 finetune、深度网络自适应、以及深度对抗网络的迁移。
由于网络上已有成型的深度网络的 finetune、深度网络自适应、以及深度对抗网络的迁移教程,因此我们不再叙述这些方法,只在这里介绍非深度方法的教程。
其他三种方法的地址分别是:
• 深度网络的 finetune:用 Pytorch 对 Alexnet 和 Resnet 进行微调
• 深度网络的自适应:DDC/DCORAL 方法的 Pytorch 代码
• 深度对抗网络迁移:DANN 方法
更多深度迁移方法的代码,请见https://github.com/jindongwang/transferlearning/
tree/master/code/deep。
深度网络的 finetune
训练一个Model,就是去更新它的权值,将权值认为是知识,把这些知识应用到新任务中去。
特别是CV方面, 提取图像特征的前几层常常是识别小纹路的方向, 抽象的形状

获取filter识别图像的过程:
(原来训练CNN时,输入固定,模型参数用梯度下降找出)此时方向相反,用训练好的filter,模型固定参数,训练合适的input x,x为要找的参数,梯度上升进行更新, 使degree最大, 再把x可视化.)
为什么要 Model Finetune?
一般来说需要模型微调的任务都有如下特点:在新任务中数据量较小,不足以训练一个较大的Model。可以用Model Finetune的方式辅助我们在新任务中训练一个较好的模型,让训练过程更快。
模型微调的步骤
一般来说,一个神经网络模型可以分为Features Extractor(提取特征)和Classifer(分类)两部分.
通常我们习惯对Features Extractor的结构和参数进行保留,而仅修改Classifer来适应新任务。这是因为新任务的数据量太小,预训练参数已经具有共性,不再需要改变,如果再用这些小数据训练,可能反而过拟合。
所以步骤如下:
1.获取预训练模型参数
1.加载参数至模型(load_state_dict)
2.修改输出层以适应新任务
3.训练输出层参数
代码参考:
https://blog.csdn.net/u012436149/article/details/78038098
| from torchvision import models from torch import nn from torch import optim #step 1 resnet_model = models.resnet18(pretrained=True) # pretrained 设置为 True,会自动下载模型 所对应权重,并加载到模型中 # 也可以自己下载 权重,然后 load 到 模型中,源码中有 权重的地址。 # 假设 我们的 分类任务只需要 分 100 类,那么我们应该做的是 # 1. 查看 resnet 的源码 # 2. 看最后一层的 名字是啥 (在 resnet 里是 self.fc = nn.Linear(512 * block.expansion, num_classes)) # 3. 在外面替换掉这个层 #step 2 resnet_model.fc= nn.Linear(in_features=..., out_features=100) # 这样就 哦了,修改后的模型除了输出层的参数是 随机初始化的,其他层都是用预训练的参数初始化的。 #step3训练全连接分类层参数 # 如果只想训练 最后一层的话,应该做的是: # 1. 将其它层的参数 requires_grad 设置为 False # 2. 构建一个 optimizer, optimizer 管理的参数只有最后一层的参数 # 3. 然后 backward, step 就可以了 # 这一步可以节省大量的时间,因为多数的参数不需要计算梯度 for para in list(resnet_model.parameters())[:-1]: para.requires_grad=False optimizer = optim.SGD(params=[resnet_model.fc.weight, resnet_model.fc.bias], lr=1e-3) ... |
深度网络的自适应
DDC/DCORAL 方法的 Pytorch 代码
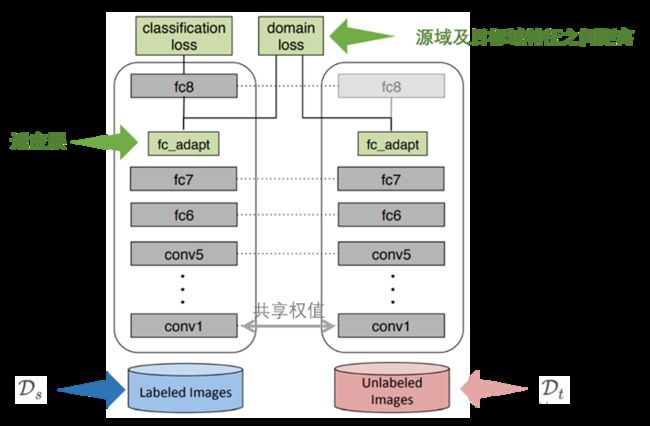
DDC(Deep Domain Confusion)为例
博客参考https://blog.csdn.net/weixin_40585997/article/details/110939689
论文参考https://arxiv.org/pdf/1412.3474.pdf
网络包括两个流向,第一条流向的输入为源数据,是带标签的;另一条流向的输入是目标数据,包含少量的带标签数据或不包含带标签数据,两个流向的卷积神经网络共享权值。和以往不同的是,作者在两个流向的网络的特征层之间增加了一个适应层,并通过适应层的输出计算出一个domain loss,文中通过利用源域及目标域特征之间的MMD(Maximum Mean Discrepancy)距离来作为domain loss,通过最小化MMD距离来减小源于与目标域之间的差异
(这部分代码模块太多, 不太可能讲得完不放了)
深度对抗网络迁移
DAAN 动态对抗适应网络Dynamic Adversarial Adaptation Network
参考:
https://zhuanlan.zhihu.com/p/141887441
Domain adversarial adaptation methods借鉴了生成式对抗网络(GAN, Generative Adversarial Networks)的思想来学习可转移的特征。对抗训练类似于两人博弈,一个玩家是领域判别器 domain discriminator G_d ,另一个玩家是特征提取器feature extractor G_f 。
domain discriminator G_d:分辨源域和目标域,通过极小化 G_d损失来学习参数 θ_d
feature extractor :通过提取域不变特征来混淆domain discriminator,通过极大化 G_d的损失来学习参数 θ_f
(通过这个特征, 无法分清是源域还是目标域, 即源域目标域共同特征)
label classifier G_y :通过极小化自身的损失来学习参数 θ_y
总的损失函数
$$ \begin{aligned} L\left(\theta_{f}, \theta_{y}, \theta_{d}\right)=& \frac{1}{n_{s}} \sum_{\mathbf{x}_{i} \in \mathcal{D}_{s}} L_{y}\left(G_{y}\left(G_{f}\left(\mathbf{x}_{i}\right)\right), y_{i}\right) \\ &-\frac{\lambda}{n_{s}+n_{t}} \sum_{\mathbf{x}_{i} \in\left(\mathcal{D}_{s} \cup \mathcal{D}_{t}\right)} L_{d}\left(G_{d}\left(G_{f}\left(\mathbf{x}_{i}\right)\right), d_{i}\right) \end{aligned} $$
取共同特征进行分类, 分类准确度↑. (因为目标域无标签, 做不了分类)
源域目标域区分度↓
非深度迁移
画树形图
边缘分布自适应(TCA)
条件分布自适应(STL)
联合分布自适应(JDA)
动态分布自适应(DDA)
数据分布自适应(第一类方法)
Distribution Adaptation
源域和目标域的数据概率分布不同,通过变换,将不同的数据分布的距离拉近.
| 数据概率分布不同 |
边缘分布不同 |
数据整体不相似 |
| 条件分布不同 |
数据整体相似 但是每个类不相似 |
常用的迁移学习方法
精度比较:DDA(动态DA )> JDA (联合分布自适应)> TCA(迁移成分分析) > 条件分布自适应
特征选择法(第二类方法)
假设
公共特征上,源领域和目标领域的数据分布一致.
机器学习选择出共享的特征,构建统一模型.
通常与分布自适应方法进行结合
核心方法
SCL(Structural Correspondence Learning)找公共特征(Pivot feature)
参考:
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/121005222
" The oncogenic mutated forms of the ras proteins are constitutively active
and interfere with normal signal transduction"
这句话里面的 “signal” 在此处是名词,但如果词性标注模型是用 WSJ 语料训练的,会将其错误的识别为形容词。对比 MEDLINE 语料中 signal 这个词的上下文与 WSJ 语料中名词的上下文,可以发现一些共同的 Pattern,比如都出现在 required、from 与 for 这些词前面,因此可以用这些共同的 Pattern 作为 Feature,训练的模型就可以获得很好的跨领域泛化能力。这些 Pattern 就是 Pivot Feature。

子空间学习(第三类方法)
假设:
源域和目标域数据在变换后的子空间有相似的分布
按特征变换形式分类:
1.统计特征对齐方法(基于统计特征变换)
2.流形学习方法(基于流形变换)
(详细参考笔记)
代码实践
TCA为例顺便讲一讲公式