python机器学习基础02——sklearn之KNN
文章目录
- KNN分类模型
- K折交叉验证
KNN分类模型
- 概念:
- 简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN)
这里的距离用的是欧几里得距离,也就是欧式距离
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
df = pd.read_excel('./datasets/my_films.xlsx')
#提取特征数据
feature = df[['Action Lens','Love Lens']]
#提起标签数据
target = df['target']
#数据集切分
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.1,random_state=2020)
#创建算法模型对象
#n_neighbors == knn中的k
knn = KNeighborsClassifier(n_neighbors=3)
#训练模型:特征数据必须是二维的
knn.fit(x_train,y_train)
knn.predict(x_test)
print('模型分类结果:',knn.predict(x_test))
print('真实的结果:',y_test)
结果:
模型分类结果: ['Action' 'Action']
真实的结果: 2 Action
1 Action
Name: target, dtype: object
scikit-learn自带数据集合
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import sklearn.datasets as datasets
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
feature = iris['data']
target = iris['target']
feature.shape,target.shape
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
knn = KNeighborsClassifier(n_neighbors=8)
knn.fit(x_train,y_train)
knn.score(x_test,y_test)
print('模型分类结果:',knn.predict(x_test))
print('真实的分类结果:',y_test)
结果:
模型分类结果: [2 0 1 1 1 2 2 1 0 0 2 1 0 2 2 0 1 1 2 0 0 2 1 0 2 1 1 1 0 0]
真实的分类结果: [2 0 1 1 1 2 2 1 0 0 2 2 0 2 2 0 1 1 2 0 0 2 1 0 2 1 1 1 0 0]
- k-近邻算法之约会网站配对效果判定(datingTestSet.txt)
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler,StandardScaler
df = pd.read_csv('./datasets/datingTestSet.txt',header=None,sep='\t')
feature = df[[0,1,2]]
target = df[3]
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
knn = KNeighborsClassifier(n_neighbors=75)
knn.fit(x_train,y_train)
knn.score(x_test,y_test) # 0.82
#归一化
mm = MinMaxScaler()
m_feature = mm.fit_transform(feature)
x_train,x_test,y_train,y_test = train_test_split(m_feature,target,test_size=0.2,random_state=2020)
knn = KNeighborsClassifier(n_neighbors=75)
knn.fit(x_train,y_train)
knn.score(x_test,y_test) # 0.955
#标准化
s = StandardScaler()
s_feature = s.fit_transform(feature)
x_train,x_test,y_train,y_test = train_test_split(s_feature,target,test_size=0.2,random_state=2020)
knn = KNeighborsClassifier(n_neighbors=75)
knn.fit(x_train,y_train)
knn.score(x_test,y_test) # 0.96
- 学习曲线寻找最优的k值
- 穷举不同的k值
import matplotlib.pyplot as plt
ks = np.arange(3,150,5)
scores = []
for k in ks:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train,y_train)
score = knn.score(x_test,y_test)
scores.append(score)
scores = np.array(scores)
plt.plot(ks,scores)
plt.xlabel('k')
plt.ylabel('score')
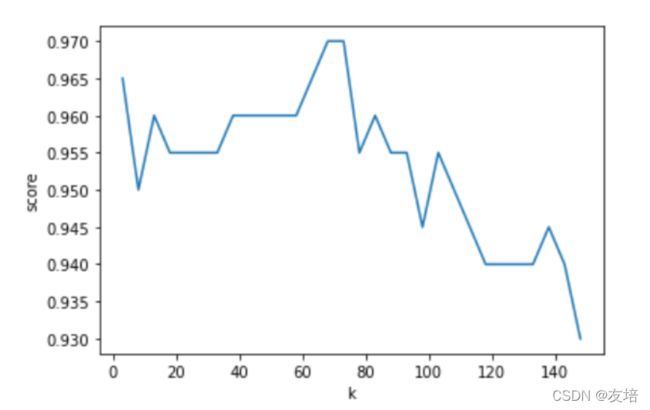
#如何具体找出分值最好的k值
max_value_index = scores.argmax() #argmax可以返回numpy数组中最大值的下标
best_k = ks[max_value_index] # 68
K折交叉验证
-
目的:
- 选出最为适合的模型超参数的取值,然后将超参数的值作用到模型的创建中。
-
思想:
- 将样本的训练数据交叉的拆分出不同的训练集和验证集,使用交叉拆分出不同的训练集和验证集测分别试模型的精准度,然就求出的精准度的均值就是此次交叉验证的结果。将交叉验证作用到不同的超参数中,选取出精准度最高的超参数作为模型创建的超参数即可!
-
实现思路:
- 将训练数据平均分割成K个等份
- 使用1份数据作为验证数据,其余作为训练数据
- 计算验证准确率
- 使用不同的测试集,重复2、3步骤
- 对准确率做平均,作为对未知数据预测准确率的估计
-
API
- from sklearn.model_selection import cross_val_score
- cross_val_score(estimator,X,y,cv):
- estimator:模型对象
- X,y:训练集数据
- cv:折数
# k折交叉验证应用在KNN
from sklearn.model_selection import cross_val_score
feature = feature
target = target
x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020)
#交叉验证(作用在训练集中)
knn = KNeighborsClassifier(n_neighbors=15)
#参数1:模型对象,参数2:训练集的特征,参数3:训练集的标签,参数cv就是折数
mean_score = cross_val_score(knn,x_train,y_train,cv=10).mean() # 0.81875
ks = np.arange(3,150,5)
scores = []
for k in ks:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn,x_train,y_train,cv=5).mean()
scores.append(score)
plt.plot(ks,scores)
plt.xlabel('k')
plt.ylabel('score')
scores = np.array(scores)
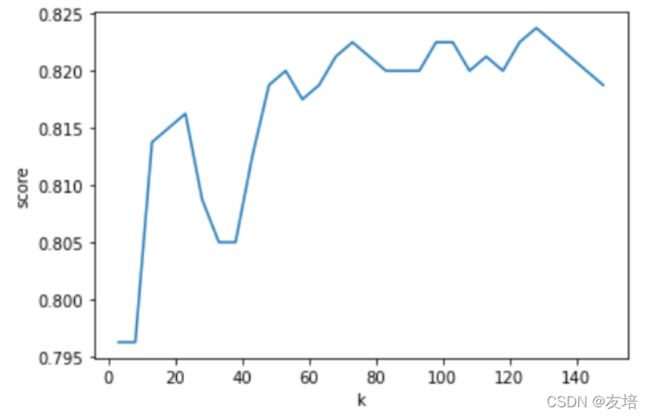
best_k = ks[scores.argmax()]
#使用最优的超参数训练模型
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(x_train,y_train)
knn.score(x_test,y_test) # 0.82
knn.predict(x_test) #训练好的模型进行分类操作