前言:
- 高级数据结构(Ⅰ)并查集(union-find)
- 动态连通性
- union-find算法API
- quick-find算法
- quick-union算法
- 加权quick-union算法
- 使用路径压缩的加权quick-union算法
- 算法比较
- 并查集 > 左神版
高级数据结构(Ⅰ)并查集(union-find)
1.动态连通性
问题的输入是一列整数对,其中每个整数都表示一个某种类型的对象,一对整数p和q可以被理解为“p和q是相连的”。我们假设“相连”是一种等价关系,这意味着它具有:
- 自反性:p和p是相连的
- 对称性:如果p和q是相连的,那么q和p也是相连的
- 传递性:如果p和q是相连的且q和r是相连的,那么p和r也是相连的
本文中以下内容中使用网络方面的术语,将对象称为触点,将整数对称为连接,将等价类称为连通分量或是简称分量。简单起见,假设我们有用0到n-1整数所表示的N个触点。这样做并不会降低算法的通用性。
2.union-find算法API
为了说明问题,我们设计了一份API来封装所需的基本操作:初始化、连接两个触点、判断包含某个触点的分量、判断两个触点是否存在于同一个分量之中以及返回所有分量的数量。详细的API如下表所示
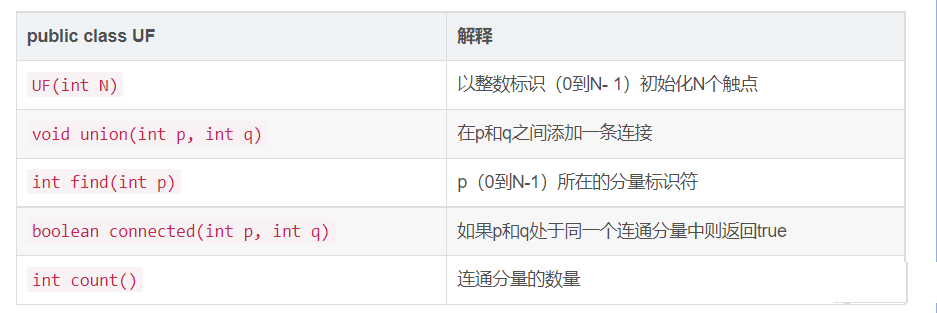
为解决动态连通性问题设计算法的任务变成了实现这份API,所有的实现都应该:
- 定义一种数据结构表示已知的连接
- 基于此数据结构实现高效的union()、find()、connected() 和count() 方法
- 实现:
public class UF {
private int[] id; //分量id(以触点作为索引)
private int count; //分量数量
public UF(int N) {
//初始化分量id数组
count = N;
id = new int[N];
for(int i = 0; i < N; i++) {
id[i] = i;
}
}
public int count() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
return -1; //省略此条代码
}
public void union(int p, int q) {
//见 quick-find、qucik-union、加权uick-union
}
public static void main(String[] args) {
//解决输入的连通性问题
Scanner sc = new Scanner(System.in);
int N = sc.nextInt(); //读取触点数量
UF uf = new UF(N);
while(sc.hasNext()) {
int p = sc.nextInt();
int q = sc.nextInt(); //读取整数对
if(uf.connected(p, q)) continue; //如果已连通则忽略
System.out.println("(" + p + ", " + q + ")"); //打印连接
}
System.out.println(uf.count() + "components");
}
}
union-find的成本模型:在研究实现union-find的API的各种算法时,我们统计的是数组的访问次数(访问任意数组元素的次数,无论读写)
3.quick-find算法
此方法保证当且仅当id[p] 等于 id[q]时p和q是连通的。换句话说,在同一个连通分量中的所有触点在id[]中的值必须全部相同。这意味着connected(p, q)只需要判断id[p] == id[q],当且仅当p和q在同一连通分量之中该语句才会返回true。为了调用union(p, q)确保这一点,我们首先要检查它们是否已经存于同一个连通分量之中。如果存在于同一分量中我们不需要采取任何行动,否则我们面对的情况就是p所在的连通分量中的所有触点的id[]值均为同一个值,而q所在的连通分量中的所有触点的id[]均为另一个值。要将两个分量合二为一,我们必须将两个集合中所有触点对应的id[]元素变为同一个值。为此,我们需要遍历整个数组,将所有和id[p]相等的元素的值变为id[q]的值。我们也可以将所有和id[q]相等的元素的值变为id[p]的值,两者均可。
详细代码如下所示:
public class QuickFindUF {
private int[] id; //分量id(以触点作为索引)
private int count; //分量数量
public QuickFindUF(int N) {
//初始化分量id数组
count = N;
id = new int[N];
for(int i = 0; i < N; i++) {
id[i] = i;
}
}
public int count() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
return id[p];
}
public void union(int p, int q) {
//将p和q归并到相同的分量中
int pID = find(p);
int qID = find(q);
//如果p和q已经在相同的分量之中则不需要采取任何行动
if(pID == qID) return;
//将p的分量重命名为q的名称
for(int i = 0; i < id.length; i++) {
if(id[i] == pID) id[i] = qID;
}
count--;
}
}
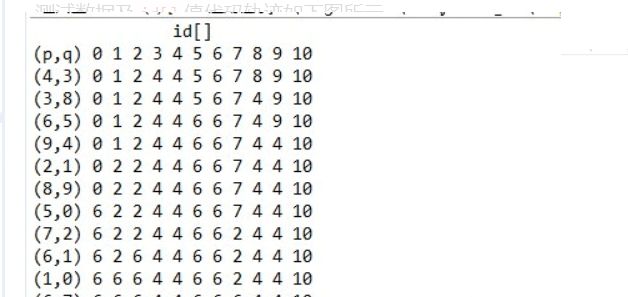
输出
边(p,q) id[]
p q -|- 0 1 2 3 4 5 6 7 8 9
-------------------------------------
4 3 -|- 0 1 2 3 3 5 6 7 8 9
3 8 -|- 0 1 2 8 8 5 6 7 8 9
6 5 -|- 0 1 2 8 8 5 5 7 8 9
9 4 -|- 0 1 2 8 8 5 5 7 8 8
2 1 -|- 0 1 1 8 8 5 5 7 8 8
8 9 -|- 0 1 1 8 8 5 5 7 8 8 此时不用做任何改变,8与9已结处于同一个连通分量中
5 0 -|- 0 1 1 8 8 0 0 7 8 8
7 2 -|- 0 1 1 8 8 0 0 1 8 8
6 1 -|- 1 1 1 8 8 1 1 1 8 8
1 0 -|- 1 1 1 8 8 1 1 1 8 8 此时不用做任何改变,1与0已结处于同一个连通分量中
6 7 -|- 1 1 1 8 8 1 1 1 8 8 此时不用做任何改变,6与7已结处于同一个连通分量中
4.quick-union算法
此算法重点提高union()方法的速度,它和quick-find算法是互补的。它也基于相同的数据结构----以触点作为索引的id[]数组,但我们赋予这些值的意义不同,我们也需要用它们来定义更加复杂的结构。确切地说,每个触点对应的id[]元素都是同一个分量中另一个触点的名称(也可能是它自己)----我们将这种联系称为链接。在实现find()方法时,我们从给定的触点开始,由它的链接得到另一个触点,再由这个触点到达第三个触点,如此继续跟随着链接直到到达一个根触点,即链接指向自己的触点(这样的触点必然存在)。当且仅当分别由两个触点开始的这个过程到达了同一个根触点时它们存在于同一个连通分量中。为了保证这个过程的有效性,我们需要union(p, q)来保证这一点。它的实现很简单:我们由p和q的链接分别找到它们的根触点,然后只需将一个根触点连接到另一个根触点即可将一个分量重命名为另一个分量,因此这个算法叫做quick-union。和刚才一样,无论是重命名含有p的分量还是重命名含有q的分量都可以。
实现:
public class QuickUnionUF {
private int[] id; //分量id(以触点作为索引)
private int count; //分量数量
public QuickUnionUF(int N) {
//初始化分量id数组
count = N;
id = new int[N];
for(int i = 0; i < N; i++) {
id[i] = i;
}
}
public int count() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
//找出分量的名称
while(p != id[p]) p = id[p];
return p;
}
public void union(int p, int q) {
//将p和q的根节点统一
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
id[pRoot] = qRoot;
count--;
}
}
输出:

5.加权quick-union算法
与其在union()中随意将一棵树连接到另一棵树,我们现在会记录每一棵树的大小并总是将较小的数接到较大的树上。这项改动需要添加一个数组和一些代码来记录树中的结点数,它能够大大改进算法的效率,提高了查询根触点的速度。该算法构造的树的高度远远小于未加权的版本所构造的树的高度。
public class WeightedQuickUnionUF {
private int[] id; //父链接数组(由触点索引)
private int[] sz; //(由触点索引的)各个根节点所对应的分量的大小
private int count; //连通分量的数量
public WeightedQuickUnionUF(int N) {
count = N;
id = new int[N];
for(int i = 0; i < N; i++) id[i] = i;
sz = new int[N];
for(int i = 0; i < N; i++) sz[i] = 1;
}
public int count() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
//跟随连接找到根节点
while(p != id[p]) p = id[p];
return p;
}
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
//将小树的根节点连接到大树的根节点
if(sz[pRoot] < sz[qRoot]) {
id[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}else {
id[qRoot] = id[pRoot];
sz[pRoot] += sz[qRoot];
}
count--;
}
}
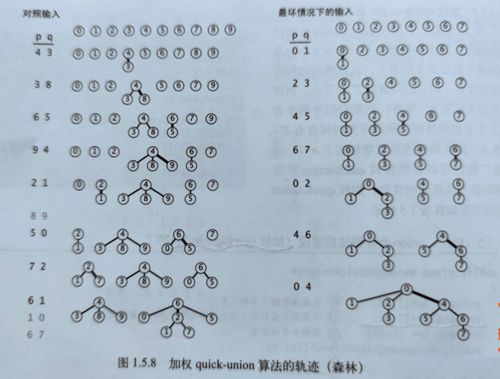
6.使用路径压缩的加权quick-union算法
理想情况下,我们都希望每个节点都直接链接到它的根节点上,但我们又不想像quick-union算法那样通过修改大量链接来做到这一点。我们接近这种理想状态的方式很简单,就是在检查节点的同时将他们直接链接到根节点。这种方法的实现很容易,而且这些树并没有阻止我们进行这种修改的特殊结构:如果这么做能够改进算法的效率,我们就应该实现它。要实现路径压缩,只需要为find()添加一个循环,将在路径上遇到的所有结点都直接链接到根节点。我们所得到的结果是几乎完全扁平化的树,它和quick-find算法理想情况下所得到的树非常接近。这种方法既简单又高效,但在实际情况下已经不太可能对加权quick-union算法继续进行任何改进了。
路径压缩的加权quick-union算法是最优的算法
实现:
public class PathCondenseWeightedQuickUnionUF {
private int[] id; //父链接数组(由触点索引)
private int[] sz; //(由触点索引的)各个根节点所对应的分量的大小
private int count; //连通分量的数量
public PathCondenseWeightedQuickUnionUF(int N) {
count = N;
id = new int[N];
for(int i = 0; i < N; i++) id[i] = i;
sz = new int[N];
for(int i = 0; i < N; i++) sz[i] = 1;
}
public int count() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
/*递归版本
public int find(int p) {
if(id[p] == p) return p;
id[p] = find(id[p]);
return id[p];
}
*/
public int find(int p) {
int root = p;
while (root != id[root]) {
root = id[root];
}
while (id[p] != root) {
int temp = p;
p = id[p];
id[temp] = root;
}
return root;
}
public void union(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
//将小树的根节点连接到大树的根节点
if(sz[pRoot] < sz[qRoot]) {
id[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}else {
id[qRoot] = id[pRoot];
sz[pRoot] += sz[qRoot];
}
count--;
}
}
输出:
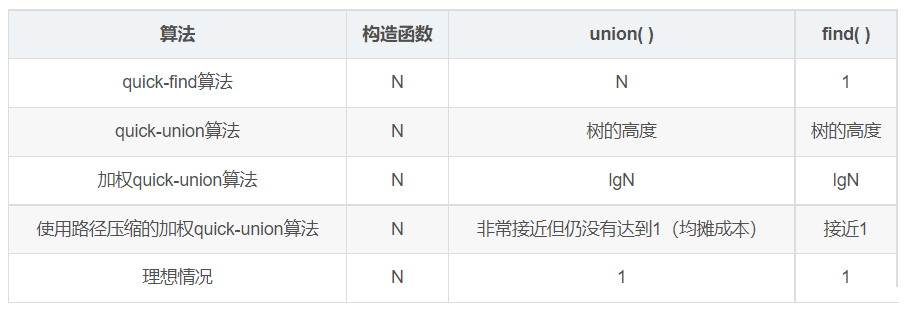
7.算法比较
各种union-find算法的性能特点(存在N个触点时成本的增长数量级(最坏情况下))
到此这篇关于C高级数据结构之并查集的文章就介绍到这了,更多相关C++并查集内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!