Centos上Hadoop集群安装及配置详细教程
ps:写此博客记录Hadoop集群的安装配置的步骤,方便日后学习回顾,也希望给各位带来帮助。
Hadoop集群的安装与配置
- 安装环境
-
- 系统基本配置
-
- 伪分布式安装
-
- 分布式安装配置
安装环境
Centos版本:6.7
VMware版本:15.5.1
JDK版本:jdk-7u67
系统基本配置
1.主机名修改
切换至root,进入/etc/sysconfig/network文件中修改HOSTNAME=hadoop1,方便之后的操作。
vi /etc/sysconfig/network
修改之后退出重启,再次进入终端输入hostname命令,若为hadoop1则修改主机名成功。
2.IP地址配置
设置静态IP,点击左上角的编辑,进入虚拟网络编辑器

进入之后的界面,再点击NAT设置
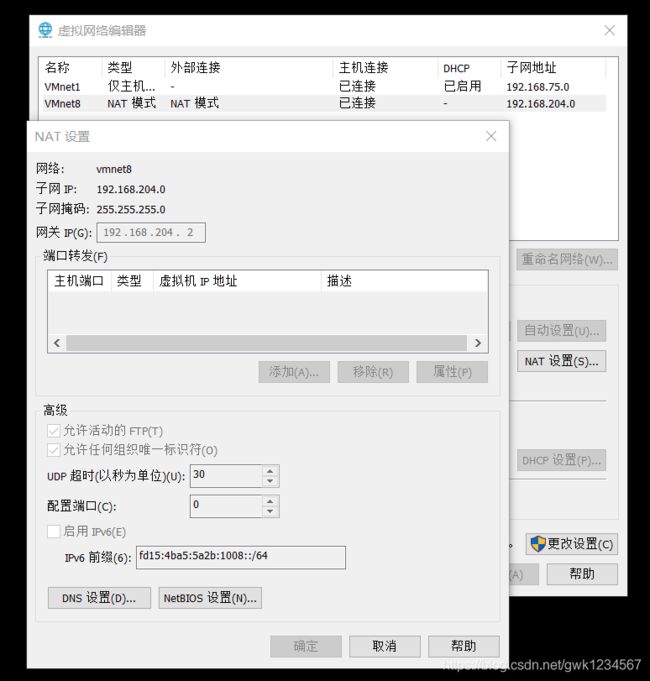
查看自己IP的数据之后,进入/etc/sysconfig/network-scripts/ifcfg-eth0文件修改
vi /etc/sysconfig/network-scripts/ifcfg-eth0
将BOOTPROTO="dhcp"修改为BOOTPROTO=“static”,然后添加如下几行
IPADDR=192.168.204.100
NETMASK=255.255.255.0
GATEWAY=192.168.204.2
DNS1=192.168.204.2
注意,这里的数据是我电脑的数据,进行配置的时候可查看上图示例里的数据GATEWAY和DNS1是网关的IP,NETMASK是子网掩码的数据,IPADDR的前三位与网关的IP的前三位一样,最后一位可与我一样设置为100,如果文件中的ONBOOT不是设置为yes的话就将其改为yes。配置完之后保存退出文件修改内容。
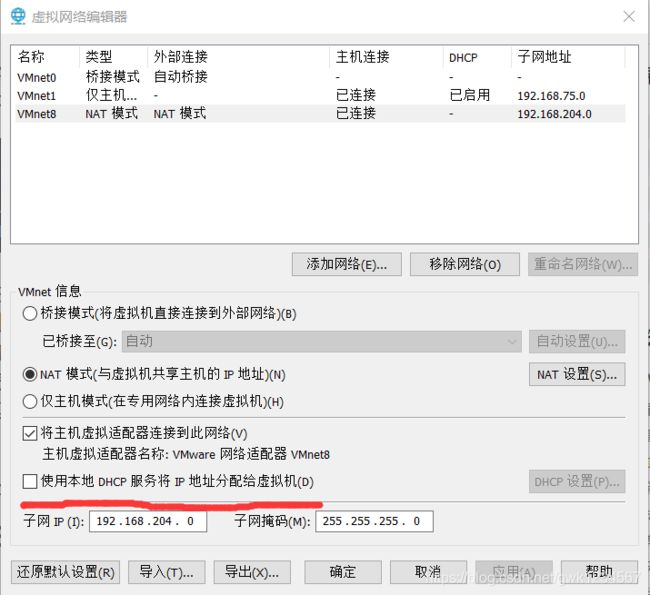
再次点编辑,选中NAT模式之后,点击下方的更改设置,将红线处的勾取消
3.主机名与ip地址做映射
进入/etc/hosts文件
vi /etc/hosts
并在末尾追加
192.168.204.100 hadoop1
其中192.168.204.100是之前配置的IPADDR的地址,按照自己之前配置的修改即可。
通过映射之后,局域网中,可以通过这个名字定位具体的计算机,集群各台服务器之间相互访问更方便。
4.防火墙关闭
输入命令chkconfig --level 0123456 iptables off执行即可
chkconfig --level 0123456 iptables off
关闭防火墙可以方便局域网中不同计算机之间的通信。(没有关闭防火墙的话,部分服务不能跨计算机进行访问,即部分端口是关闭的)
5.selinux关闭
输入getenforce命令
getenforce
如果结果显示permissive或disabled,则可以跳过此步骤。如果不是,那么进入/etc/selinux文件
vi /etc/selinux
修改SELINUX=enforcing为SELINUX=permissive,保存修改退出,重启系统。这样可以方便局域网中不同的计算机之间的通信。
6.JDK安装
从网上下载jdk1.7以上64位linux版本,这里安装jdk-7u67-linux-x64.rpm版本,(这里给出我的安装包,下载安装包,提取码是1022)下载后进入root执行
rpm -ivh jdk-7u67-linux-x64.rpm
当然这里的jdk安装包路径也是取决于你下载的位置,我的安装包放在桌面,所以我的安装命令是
rpm -ivh /home/centos/Desktop/jdk-7u67-linux-x64.rpm
安装成功后,输入java -version查看,如果出现如下图示则安装成功

安装好jdk之后,还需要配置jdk的环境变量。进入/etc/profile文件
vi /etc/profile
然后在文件的末尾加上下面两行代码
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
保存修改退出,重启系统。
7.yum安装配置
切换成root用户,在终端输入命令下载repo
wget https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/cloudera-cdh5.repo -P /etc/yum.repos.d/
因为我们安装的是cdh5.10.1版本的Hadoop,所以我们还需要修改cloudera-cdh5.repo文件,输入命令
vi /etc/yum.repos.d/cloudera-cdh5.repo
将文件中的baseurl=https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5/改成baseurl=https://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5.10.1/。
输入命令
yum clean all
清理缓存残留的yum信息,再输入命令
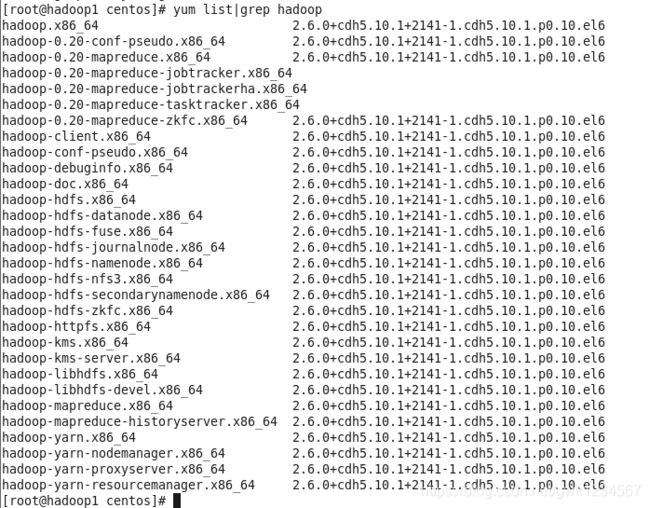
yum list | grep hadoop
查看Hadoop信息,如果出现如下图示则表示成功
伪分布式安装
伪分布式其实就是把所有的进程安装在同一台服务器上,在同一台服务器上拉起所有的进程。
1.安装
我们需要安装Namenode、SeconderayNamenode、Datanode、Resourcemanager、Nodemanager、Jobhistoryserver,
输入以下命令
yum install -y hadoop-hdfs-namenode.x86_64
yum install -y hadoop-hdfs-secondarynamenode.x86_64
yum install -y hadoop-hdfs-datanode.x86_64
yum install -y hadoop-yarn-resourcemanager.x86_64
yum install -y hadoop-yarn-nodemanager.x86_64
yum install -y hadoop-mapreduce-historyserver.x86_64
全部安装完即可,安装之后,可输入命令
cat /etc/passwd
若结果是

则表示安装成功。
2.重要配置
通过rpm包安装,配置文件一般都在/etc/hadoop/conf目录下,所以先输入命令
cd /etc/hadoop/conf
进入core-site.xml文件
vi core-site.xml
文件中只有
</configuration>
在两者之间加入这几行代码
fs.defaultFS</name>
hdfs://hadoop1:8020</value>
</property>
保存修改退出,再进入hdfs-site.xml文件,如同上述一样,文件中有
dfs.namenode.name.dir</name>
file:///var/lib/hadoop-hdfs/cache/hdfs/dfs/name</value>
</property>
</configuration>
我们在其中加入几行代码
dfs.permissions.superusergroup</name>
hadoop</value>
</property>
保存修改退出。
3.本地存储路径配置
进入hdfs-site.xml文件,将文件中的namenode中的value改成如下代码所示
dfs.namenode.name.dir</name>
/data/nn</value>
</property>
同时,在其中再加入这几行代码,步骤儒上述一样
dfs.datanode.data.dir</name>
/data/dn</value>
</property>
保存修改退出。
因为系统中还并未存在/data/dn和/data/nn这两个文件,所以输入命令创建
mkdir -p /data/nn /data/dn
并将其归属于hdfs用户
chown -R hdfs:hdfs /data/nn /data/dn
再修改两个目录权限为700,只允许hdfs用户进行读写执行
chmod 700 /data/nn /data/dn
4.Secondary NameNode配置
同样是hdfs-site.xml文件
cd /etc/hadoop/conf
进入文件,在其中加入如下代码
dfs.namenode.http-address</name>
hadoop1:50070</value>
The address and the base port on which the dfsNameNode Web UI will listen.
</description>
</property>
dfs.namenode.secondary.http-address</name>
hadoop1:50090</value>
The address and the base port on which the dfsNameNode Web UI will listen.
</description>
</property>
5.Yarn和MapReduce配置
进入yarn-site.xml文件,将
yarn.resourcemanager.hostname</name>
hadoop1</value>
</property>
Classpath for typical applications.</description>
yarn.application.classpath</name>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,
$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,
$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,
$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*
</value>
</property>
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.local-dirs</name>
/data/yarn/local</value>
</property>
yarn.nodemanager.log-dirs</name>
/data/yarn/logs</value>
</property>
yarn.log.aggregation-enable</name>
true</value>
</property>
Where to aggregate logs</description>
yarn.nodemanager.remote-app-log-dir</name>
/var/log/hadoop-yarn/apps</value>
</property>
同时也要进入mapred-site.xml文件,在其中加入如下代码
mapreduce.framework.name</name>
yarn</value>
</property>
保存修改退出。
与之前一样,要创建文件,输入命令
mkdir -p /data/yarn/local /data/yarn/logs
然后修改文件的归属用户
chown yarn:yarn /data/yarn/local /data/yarn/logs
最后修改权限
chmod 755 /data/yarn/local /data/yarn/logs
6.配置hadoop-env.sh
同样在/etc/hadoop/conf路径下,进入hadoop-env.sh文件中,并在其中加入如下代码
export JAVA_HOME=/usr/java/default
保存退出。
7.配置JobHistory Server
进入mapred-site.xml文件中,加入如下代码
mapreduce.jobhistory.address</name>
hadoop1:10020</value>
</property>
mapreduce.jobhistory.webapp.address</name>
hadoop1:19888</value>
</property>
保存退出。
8.格式化Namenode
输入如下代码进行格式化
sudo -u hdfs hdfs namenode -format
如果结果出现Exiting with status 0则表示成功,即最后末尾几行如图所示
这里提醒一下,在格式化之前要保证之前的配置都没有问题,否则之后修改会很麻烦。
9.启动服务
这里启动相应的服务,启动NameNode服务,输入如下命令
service hadoop-hdfs-namenode start
启动DataNode服务
service hadoop-hdfs-datanode start
启动resourcemanager服务
service hadoop-yarn-resourcemanager start
启动nodemanager服务
service hadoop-yarn-nodemanager start
启动secondarynamenode服务
service hadoop-hdfs-secondarynamenode start
启动historyserver服务
service hadoop-mapreduce-historyserver start
全部启动之后,输入jps命令,如果结果是图示则服务启动成功

分布式安装配置
1.集群规划
说明:本次实验我们定义的三台主机名分别为hadoop1、hadoop2、hadoop3对应的ip地址是根据我自己的环境来设置的,大家可以根据自己的实际情况来设置ip地址。
| hadoop1(192.168.204.100) | hadoop2(192.168.204.101) | hadoop3(192.168.204.102) |
|---|---|---|
| NameNode | SecondaryNameNode | ResourceManager |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| JobHistoryServer |
2.创建新的虚拟机
在前边的伪分布式中我们已经有一台虚拟机hadoop1,接下来我们可以在hadoop1的基础之上克隆两台虚拟机。废话不多说我们可以克隆新的虚拟机,克隆前先关闭hadoop1。
右击虚拟机名称点击管理,选中克隆,基本设置都是默认,直接点击下一步,但是这里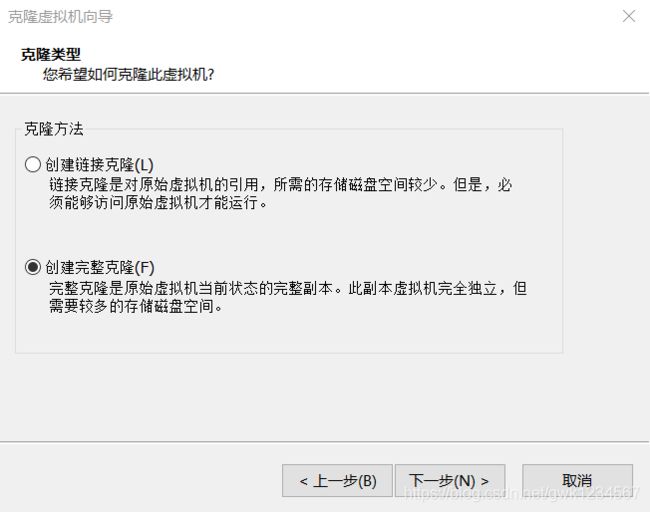
我们要选择创建完整克隆。
3.hadoop2虚拟机配置和整理
克隆完之后,进入hadoop2虚拟机(这是我自己定义的名字,即进入刚刚克隆的虚拟机),需要清除DataNode数据写入目录信息(因为目录里有DataNode的编号信息,如不清除,DataNode只能启动一个)。登陆hadoop2后切换到root账号,root密码为我们在创建hadoop1时设定的密码。然后执行删除命令:
rm -rf /data/dn/*
然后我们修改它的主机名,输入命令
vi /etc/sysconfig/network
将文件中的hadoop1改为hadoop2。
因为是克隆hadoop1,克隆后的eth0的MAC地址跟hadoop1一样,所以我们需要重新设定mac地址。执行如下命令删除/etc/udev/rules.d/70-persistent-net.rules
rm -rf /etc/udev/rules.d/70-persistent-net.rules
然后重启hadoop2。
重启之后,修改新生成/etc/udev/rules.d/70-persistent-net.rules,输入命令
vi /etc/udev/rules.d/70-persistent-net.rules
进入文件,将其中的NAME的值改成NAME=“eth0”,复制ATTR{address}的值,保存修改退出后,输入命令
vi /etc/sysconfig/network-scripts/ifcfg-eth0
进入文件后,将其中的HWADDR的值改成刚才复制ATTR{address}的值,再将IPADDR的值的最后一位改为101(这是我自己的设定),然后保存修改退出。全部完成后重启系统,再次启动后进入终端切换为root帐号,输入命令
service network restart
出现如下结果则表示成功
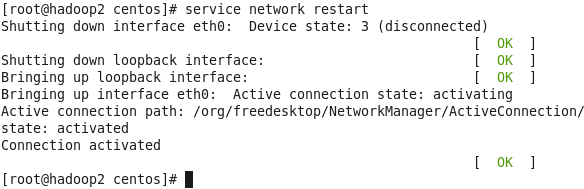
同样的方法再次克隆hadoop3,但是最后的IPADDR的值的最后一位改为102。
4.SSH免密码登陆配置
在hadoop1、hadoop2和hadoop3的root账户下分别执行
ssh-keygen -t rsa
然后按三个回车即可,在hadoop1上执行
cat /root/.ssh/id_rsa.pub>>/root/.ssh/authorized_keys
然后执行
scp /root/.ssh/authorized_keys root@192.168.204.101:/root/.ssh
scp /root/.ssh/authorized_keys root@192.168.204.102:/root/.ssh
这里192.168.204.101和192.168.204.102是hadoop2和hadoop3的IP地址,这里根据自己的设置来输入,之后再输入
vi /etc/hosts
在尾行加入
192.168.204.101 hadoop2
192.168.204.102 hadoop3
保存修改退出,这里根据自己情况输入。
在hadoop2上,输入命令
cat /root/.ssh/id_rsa.pub>>/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@192.168.204.100:/root/.ssh
scp /root/.ssh/authorized_keys root@192.168.204.102:/root/.ssh
再输入命令
vi /etc/hosts
在文件尾行加入如下命令
192.168.204.100 hadoop1
192.168.204.102 hadoop3
保存退出。
在hadoop3上,输入命令
cat /root/.ssh/id_rsa.pub>>/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@192.168.204.100:/root/.ssh
scp /root/.ssh/authorized_keys root@192.168.204.101:/root/.ssh
同样再进入/etc/hosts文件,在尾行加入如下
192.168.204.100 hadoop1
192.168.204.101 hadoop2
保存退出。完成这些步骤后即可免密登录。
5.进程禁用
前边我们在hadoop1上搭建了伪分布式,上边安装了hadoop集群所有的进程。根据我们分布式规划,我们需要关闭SecondaryNameNode和ResourceManager进程。
在hadoop1执行下边命令
chkconfig hadoop-hdfs-secondarynamenode off
chkconfig hadoop-yarn-resourcemanager off
在hadoop2上输入命令
chkconfig hadoop-hdfs-namenode off
chkconfig hadoop-yarn-resourcemanager off
chkconfig hadoop-mapreduce-historyserver off
在hadoop3上输入命令
chkconfig hadoop-hdfs-namenode off
chkconfig hadoop-hdfs-secondarynamenode off
chkconfig hadoop-mapreduce-historyserver off
6.修改resourcemanager的主机名
在hadoop1上输入命令
vi /etc/hadoop/conf/yarn-site.xml
将文件中的value值改为hadoop3,如下
yarn.resourcemanager.hostname</name>
hadoop3</value>
</property>
hadoop2和hadoop3也是一样的操作。
7.格式化Namode
这里先关闭服务(我们之前在hadoop1中开启过)
service hadoop-hdfs-namenode stop
service hadoop-hdfs-datanode stop
service hadoop-yarn-resourcemanager stop
service hadoop-yarn-nodemanager stop
service hadoop-hdfs-secondarynamenode stop
service hadoop-mapreduce-historyserver stop
我们之前格式化过一次,所以先在hadoop1,hadoop2,hadoop3中输入命令
rm -rf /data/dn/current
然后在hadoop1中输入命令
sudo -u hdfs hdfs namenode -format
再将所有datanode中的文件/data/dn/current/VERSION中cluster的值改成与/data/nn/current/VERSION中的cluster一致。
8.启动服务
这里先在hadoop1,hadoop2,hadoop3中输入命令
vi /etc/hadoop/conf/hdfs-site.xml
将文件中的

50090前的hadoop1改成hadoop2,保存修改退出,然后开始输入命令启动服务。
启动服务是有顺序的,先在hadoop1输入命令
service hadoop-hdfs-namenode restart
启动服务后在hadoop2上输入命令
service hadoop-hdfs-secondarynamenode restart
之后在hadoop1,hadoop2,hadoop3中输入命令
service hadoop-hdfs-datanode restart
全部启动后在hadoop3上输入
service hadoop-yarn-resourcemanager restart
再到hadoop1,hadoop2,hadoop3中输入命令
service hadoop-yarn-nodemanager restart
最后到hadoop1中输入命令
service hadoop-mapreduce-historyserver restart
启动即可。启动之后可在hadoop1,hadoop2,hadoop3中输入jps查看是否启动,如果hadoop1中结果如图所示

则成功启动,hadoop2和hadoop3分别是
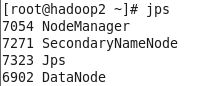
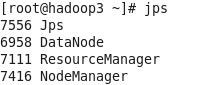
至此hadoop集群安装和配置完成。