李宏毅老师《机器学习》课程笔记-4.2 Batch Normalizaiton
注:本文是我学习李宏毅老师《机器学习》课程 2021/2022 的笔记(课程网站 ),文中图片均来自课程 PPT。欢迎交流和多多指教,谢谢!
Lecture 4.2 training tip: Batch Normalizaiton
本节课介绍一个 Deep Neural Network 的 training tip,在训练 CNN 时就会用到。
我们先回顾一下,遇到下图左所示情况,两个参数的 loss 曲线大不相同,一个陡峭,一个平缓。这样训练时不好设置learning rate,很难到达 loss 最低点。前面的课程中介绍了 adaptive learning rate 的解决方法,根据不同参数 gradient 的不同,相应地调整 learning rate。
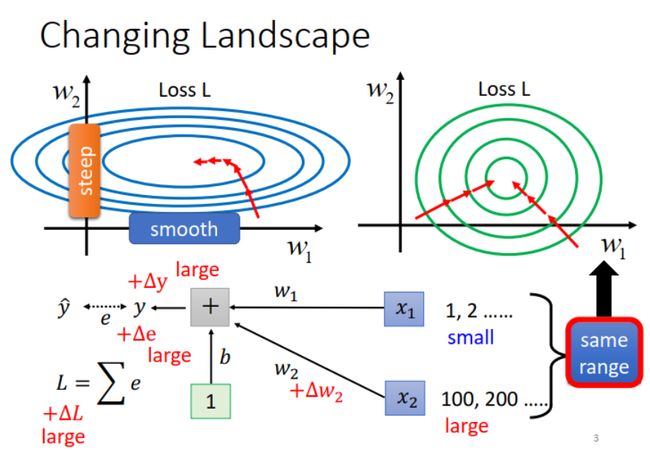
这个问题其实也可以通过改变 landscape of error surface 来解决。首先分析一下,为什么会产生这样的 error surface,这样就知道要怎么调整了。
如上图中所示, w 1 w_1 w1 和 w 2 w_2 w2 的 loss 曲线之所以相差很大,是因为其输入 x 1 x_1 x1 和 x 2 x_2 x2 的取值量级相差很大。如果 w 1 , w 2 w_1, w_2 w1,w2 做相同的变化 △ w \triangle w △w, x 1 x_1 x1 的取值小,引起 y y y 的变化小,进而对 L L L 的影响也小,因此 w 1 w_1 w1 方向的 gradient 就小。而 x 2 x_2 x2 的取值比 x 1 x_1 x1 大了两个数量级,引起 y y y 的变化大。相应地, w 2 w_2 w2 方向的 gradient 就大。
通过这个分析,我们发现,要让 w 1 w_1 w1 和 w 2 w_2 w2 方向的 gradient 相近(如上图右所示),就应该使其对应的输入 x 1 x_1 x1 和 x 2 x_2 x2 的取值在同一范围内。相应的方法就是 feature normalization。
本文介绍 feature normalization 的一种方法。具体操作为:假设 x 1 , x 2 , . . . , x R x^1, x^2, ...,x^R x1,x2,...,xR 表示一组输入 samples,把它们在每个维度 (feature) 上减去相应的均值 (mean),除以对应的方差 (variance)。做完 normalization 之后,输入 samples 每个维度上的均值都是 0,方差是 1。
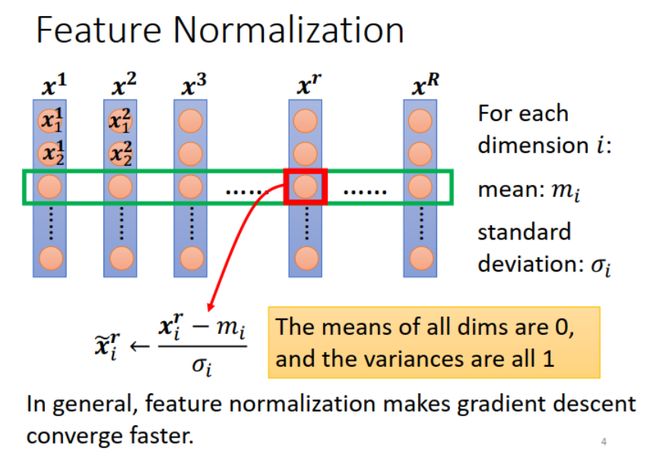
思考:传统机器学习方法,比如线性回归中也会对数据进行类似的操作。不过传统机器学习中是先人工选择特征,然后对特征向量做 Normalization 或最大最小值归一化。而深度学习是机器自动学习特征,因此是在各维度上做 Normalization。
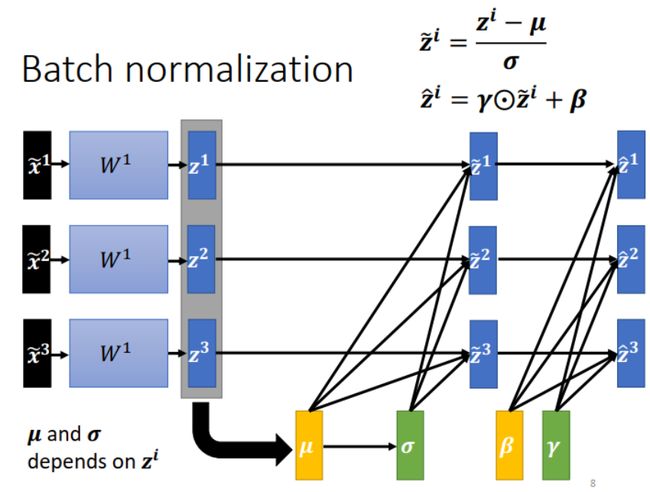
此外,在 Deep Learning 中,还要考虑 hidden layer (中间层)的输出。如下图所示的 z i z^i zi ,它同时是下一层的输入,因此也需要做 Normalization。

在什么位置做 Normalization 呢?
一般来说,在 activation function 之前(对 z i z^i zi 做)或之后(对 a i a^i ai 做)都可以。不过,如果 activation function 是 Sigmoid,因为 Sigmoid function 在取值范围 [0,1] 的 gradient 较大,因此对 z i z^i zi 做 normalization 更好。
对 z i z^i zi 做了 normalizaiton 之后,有一个有趣的现象:本来各条数据(各个 sample )之间是互不影响的。例如 z 1 z^1 z1 的变化只影响 a 1 a^1 a1 。但是做 normalization 要在全部数据 (samples) 上求均值和方差,如下图所示, z 1 z^1 z1 的变化会通过影响 z ~ 2 , z ~ 3 \widetilde z^2, \widetilde z^3 z 2,z 3,进而影响到 a 2 , a 3 a^2, a^3 a2,a3。

也就是说,以前是一次只需要考虑一个 sample ,输入到 deep neural network 得到一个 output。做 Normalizaiton 会使得 sample 之间互相有影响,因此现在一次需要考虑一批 samples,输入一个大的 deep neural network,得到一批 outputs。
实际中全部训练集的数据量很大,做 Normalization 时就考虑一个 batch 的 samples,因此称为 Batch Normalization。注意:batch size 很小,比如说等于 1 时,求不了均值和方差,没有意义。Batch Normalization 适用于 batch size 大的时候。
把输入 samples 的各个维度都调整成均值为 0,方差为 1的分布,有时可能不好解决问题,此时可以做一点改变。如下图右上角的公式所示。注意: γ \gamma γ 和 β \beta β 的值通过学习得到,也就是根据模型和数据的情况调整。 γ \gamma γ 初始设为全 1 向量, β \beta β 初始设为全 0 向量。
Batch Normalization 虽好,但是在 testing 时就遇到了问题。testing 或者实际部署时,数据都是实时处理,不可能每次等到满一个 batch 才处理。
怎么办呢?
求解 training data 的 moving average,具体方法如下图所示,然后把求得的 μ ‾ \overline\mu μ 和 σ ‾ \overline\sigma σ 当作 testing data 的均值和方差。

为什么说 Batch Normalization 对优化参数有帮助?
“Experimental results (and theoretically analysis) support batch normalization change the landscape of error surface.”
实验结果和理论分析验证了 Batch Normalization 可以通过改变 error surface,让 optimization 更顺利。
觉得本文不错的话,请点赞支持一下吧,谢谢!
关注我 宁萌Julie,互相学习,多多交流呀!
阅读更多笔记,请点击 李宏毅老师《机器学习》笔记–合辑目录。
参考
李宏毅老师《机器学习 2022》:
课程网站:https://speech.ee.ntu.edu.tw/~hylee/ml/2022-spring.php
视频:https://www.bilibili.com/video/BV1Wv411h7kN