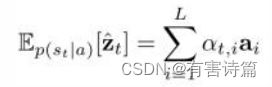图像检测:图像描述
深度语言模型
递归神经网络RNN
有2类 :时间递归神经网络(Recurrent Neural Network),针对时间序列;结构递归神经网络(Recursive Neural Network),针对树状结构
优化方法 :时序后向传播(Back propagation through time)
长时记忆/递归深度问题 :梯度爆炸->梯度剪切;梯度消失->特殊设计
RNN的应用
基于RNN原因模型。我们首先把词依次输入到循环神经网络中,每输入一个词,循环神经网络就输出截止到目前为止,下一个最可能的词。

语言模型是对下一个词出现的概率进行建模。怎样让神经网络输出概率呢?用softmax层作为神经网络的输出层。
朴素Vanilla-RNN
单层神经网络在时间上的扩展,t-1时刻的隐层转态会参与t时刻输出的计算,严重的梯度消失问题。
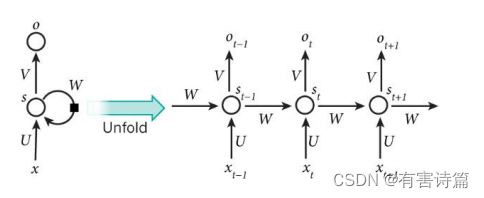
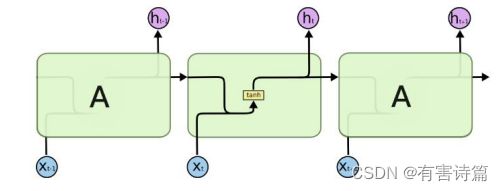
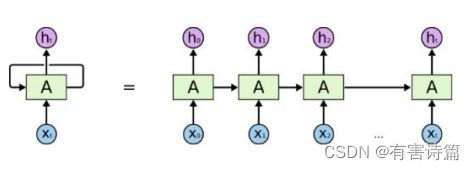
关键:Hidden Layer会有连向下一时间Hidden Layer的边,是全连接。
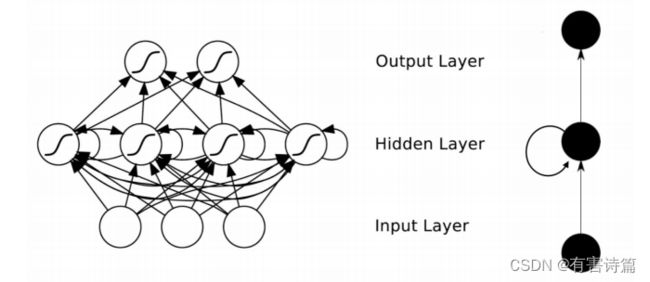
还有一种结构是Bidirectional Networks,也就是说会有来自下一时间的Hidden layer传回来的边。
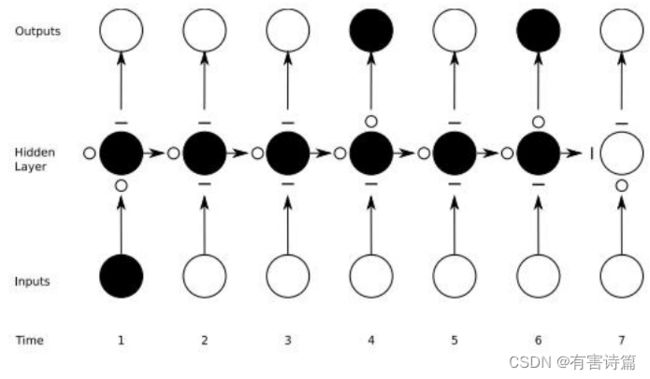
RNN的示例
希望output层中绿色的数字足够大,而红色的数字足够小;这样经过softmax后,才能输出正确的内容。
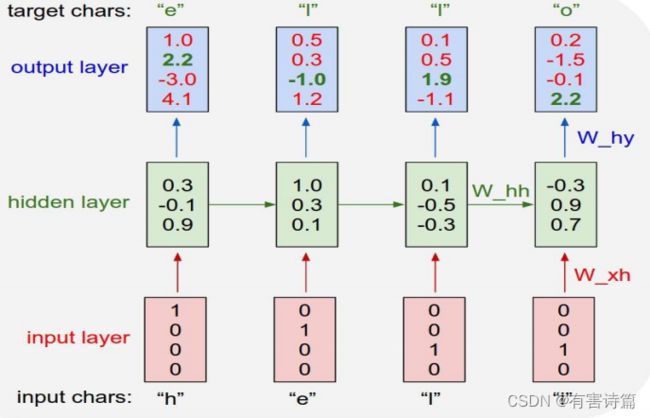
BPTT
时序后向传播(BPTT):是传统后向传播(BP)在时间序列上的扩展,t时刻的梯度是前t-1时刻所有梯度的累积,时间越长,梯度消失越严重。
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:前向计算每个神经元的输出值;
反向计算每个神经元的误差项值,它是误差函数E对神经元j的加权输入的偏导数;计算每个权重的梯度。最后再用随机梯度下降算法更新权重。
LSTM
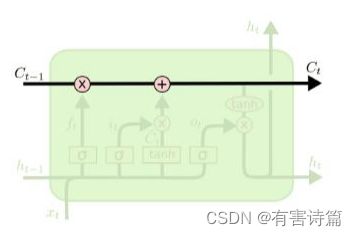
LSTM长短时记忆模型,可以有效捕捉长时记忆,共包含4个神经元,3个控制门神经元:输入门,忘记门,输出门。

LSTM数学模型
3个模型:前一时刻的隐含状态,前一时刻的记忆状态,当前时刻的输入
2个输出:当前时刻的隐含状态,当前时刻的记忆状态。
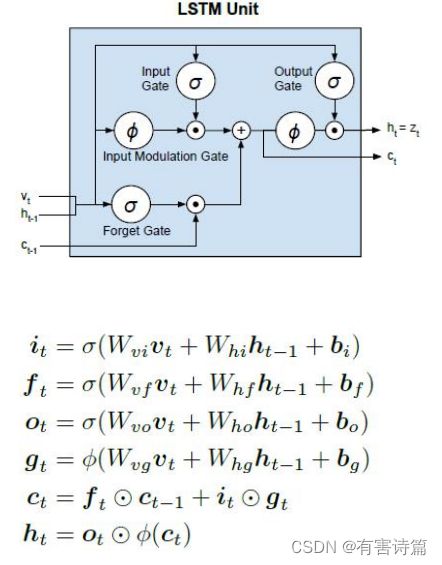
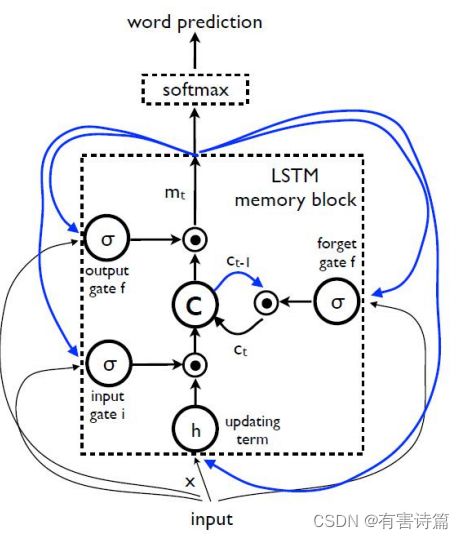
LSTM控制门作用
LSTM结构图

记忆转态(cell state)->信息 :存储之前时刻的信息,避免长时记忆问题的核心。
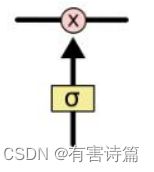
控制门(gate)-> 选择性控制信息流入 :由元素乘操作实现,配有sigmoid激活函数的神经层。值域[0,1],0不通过任何信息,1通过所有信息。
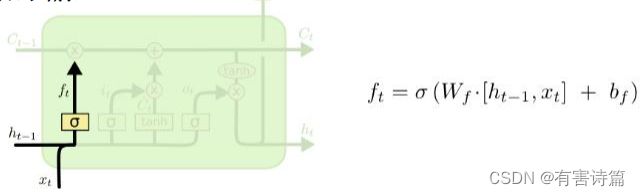
忘记门 :决定前一时刻中多少记忆状态被移除,使用sigmoid激活函数,一共有两个输入,前一时刻的隐藏状态和当前时刻的输入。
输入门 :决定当前时刻有多少新输入信息需要存入记忆状态,sigmoid激活函数,2个输入,前一时刻的隐藏状态和当前时刻的输入。

输入调制 :决定当前时刻有多少新输入信息需要存入记忆状态,Tanh激活函数,2个输入,前一时刻的隐藏状态和当前时刻的输入。

记忆状态更新 :选择性移除前一时刻的旧信息(记忆状态),选择性添加当前时刻的新信息(调制输入)。
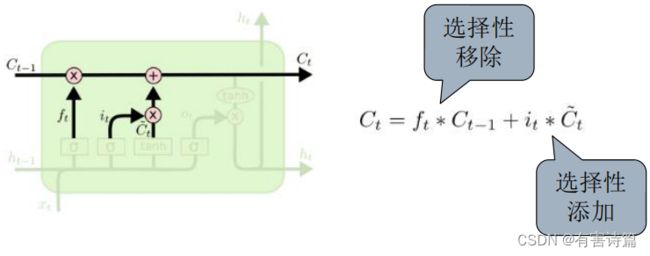
输出门 :决定当前时刻多少记忆状态用于输出,共2个输入,前一时刻的隐含状态和当前时刻的输入。有2个激活函数,Tanh激活函数和sigmoid激活函数。
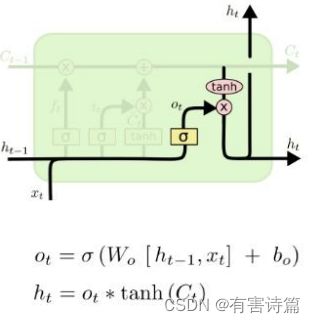
LSTM变种 :Peephole
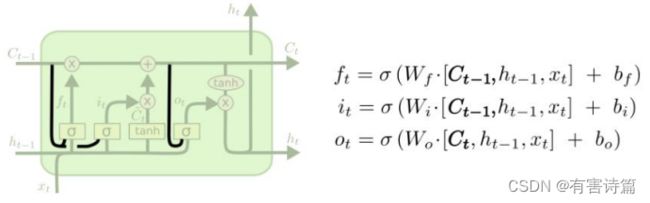
Coupled忘记-输入门
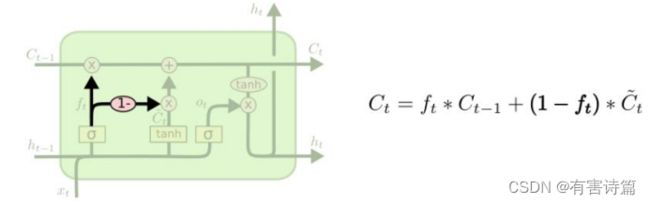
GRU门限递归单元(Gated Recurrent Unit)
较与LSTM有两个改动,合并输入门和忘记门,合并隐藏状态和记忆状态。共有2个控制门,重置门和更新门。

LSTM vs GRU
LSTM : 模型复杂,参数多,拟合能力强;数据要求:大规模,复杂度高。
GRU :模型简单,参数少,拟合能力相对弱,适用于偏小规模,不是很复杂的数据。
图说模型 Image Captioning
为图片生成描述语言,输入图片,输出是客观描述图片内容的句子。

一个视觉-语言问题,可以理解为一种特殊的机器翻译:视觉->语言。模型需要又复杂的场景理解能力:图片理解->计算机视觉,语言理解->自然语言处理,复合、多模态->多媒体
研究难点与挑战:
- 多模态理解与推理,图片捕捉真实世界的原始刻画,自然语言代表更高以及的抽象。
- 复合理解与推理:多个元素,物体,动作,场景,事件等。多步骤,迭代过程。
理解模式:
- 完整理解图片中所有内容
- 用语言描述出自己的理解

模型策略:
- 传统的分段处理策略
- 新的端对端对点策略
传统的分段处理策略
流程:图片内容->文本标签->描述语句
优势:滤除干扰信息,模块化结构,直接使用CV和NLP的研究成果
不足:第一步中错误判断会单向影响第二步的语言推理。
新的端对端对点策略
流程:将图片和文本映射到同一共享空间下,翻译:图片特征->语言描述
优势:同时训练,最优协作,模块化协作
劣势:黑箱严重。
State-of-the-art模型组成:
DNN框架
- CNN :图片理解VGG,ResNet,GoogLeNet
- RNN :语言理解及生成Multimodal-RNN,LSTM,GRU
- 特殊功能模块 :Attention
NIC模型
NIC模型的结果非常简单:就是利用encoder-decoder框架,首先利用CNN(这里是GoogLeNet)作为encoder,将Softmax之前的那一层固定维数的向量作为图像特征;在使用LSTM作为decoder,其中图形特征输入decoder(图像特征仅在开始时刻输入,后面就没用了)。模型的训练就是和任务描述那里介绍的一样,使用最大化对数似然来训练,然后在测试阶段采用beam search来减小搜索空间。
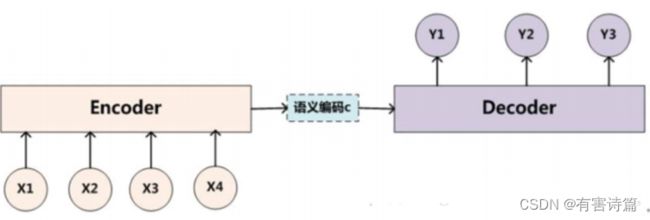
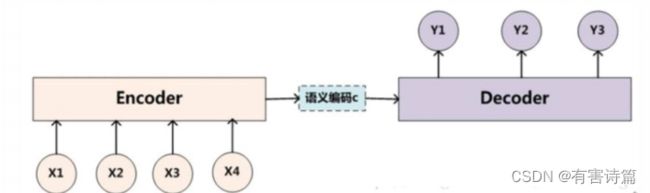
encoder-decoder简介
2014年,Sutskever提出的简单Encoder-Decoder模型,解决sequence to sequence转换的问题。
应用场景:
机器翻译:待翻译的文本序列–>翻译文本序列;
语音识别:声学特征序列–>识别文本序列;
问答系统:问题描述单词序列–>生成答案单词序列;
文本摘要:文本序列–>摘要序列
编码是将source sequence (x1,x2,x3,x4,…)转化为一个固定长度的context vector©,解码是将该context vector转化为targetsequence(y 1,y2,y3,…)。Encoder最后一个时间步的状态作为整个句子的中间语义context vector。context vector直接作为Decoder的初始状态。
NIC模型
CNN+LSTM
Inception V3生成图片特征(最后全连接层),特征映射矩阵W:将文本映射到图片特征空间。文本编码:one-hot
LSTM
CNN特征作为第一个词,句子中的词作为后续序列。

LSTM语言生成器
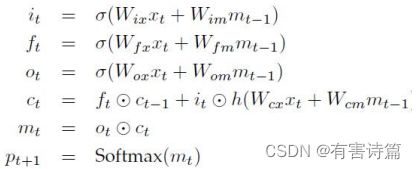
CNN+LSTM图说

训练细节
第一步:固定CNN学习率参数,无动量,训练LSTM语言模型500K,词条化后去掉了词频小于5的词;CNN参数:在ImageNet数据集预训练好的参数;训练参数:1句话n个词->n-1组训练序列。
第二步:微调CNN参数,CNN&LSTM一起训练100K
推理策略
Beam Search(尺寸=3),每一步获取Top3概率的词作为备选。
Beam Search
假设beam size为2;词典大小为3,内容为(a,b,c) 。生成第1个词的时候,选择概率最大的2个词,假设为a,c,则当前序列就是a,c。生成第2个词的时候,将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa abac ca cb cc,然后从其中选择2个得分最高的,作为当前序列。生成第2个词的时候,将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa abac ca cb cc,然后从其中选择2个得分最高的,作为当前序列。

注意力机制
语义编码C是由句子Source的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的
固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架如图所示。
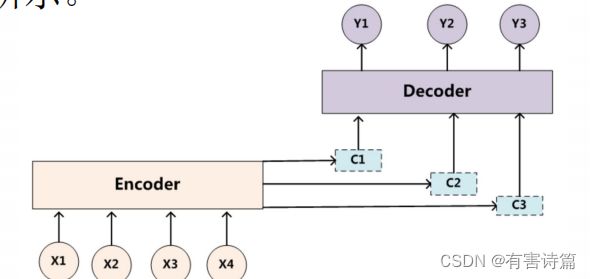
Attention-based Encoder-Decoder,Encoder部分和传统的一致,Decoder部分引入Attention机制,使得c更灵活。这时c就是由h…h,加权求和获得,且每个h;前面的权重系数W不一样,增加模型的灵活性。
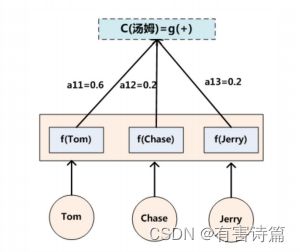
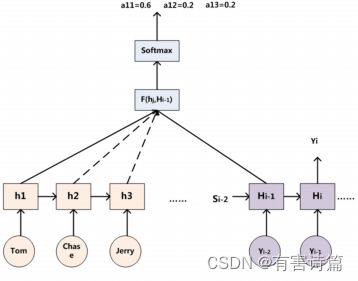
可以用Target输出句子i-1时刻的隐层节点状态H.1去一一和输入句子Source中每个单词对应的RNN隐层节点状态h,进行对比,
即通过函数F(h;,H)来获得目标单词y;和每个输入单词对应的对齐可能性,然后函数F的输出经过Softmax.
Show,attend and tell(SAT)模型
Encoder,模型使用CNN来提取L个D维的特征vector作为注释向量,每一个都对应图像的一个区域,如式:a={a1,…,aL}, ai ∈RD
Decoder,解码阶段用LSTM网络生成caption,其中C是句子长度,K是词表大小,y是各个词的one-hot编码所构成的集合。如式:
y= {y1,… .,yc},yi ∈RK

CNN + LSTM + Attention module
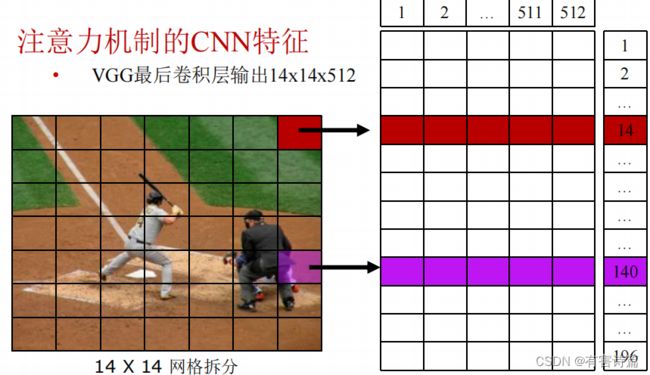
CNN :VGG最后卷积层生成图片特征
特征映射矩阵:将文本映射到图片特征空间
文本编码:one-hot
LSTM:添加第三个输入:基于attention的图片特征。
LSTM改进

输入,遗忘和输出门均有sigmoid激活,所以得到的值在0~1之间,可以直接作为概率值。
候选向量Ct和Ht有tanh激活,值在-1~1之间。
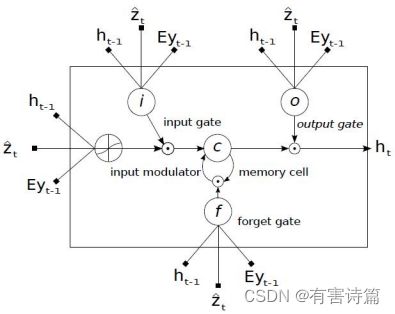
Eyt-1是look-up得到词yt-1,的m维词向量;
ht-1是LSTM上一时刻的隐状态;zt是LSTM真正的“输入”,代表的是捕捉了特定区域视觉信息的上下文向量。
隐状态和细胞状态的初始值的计算方式:两个独立的多层感知机,感知机的输入是各个图像区域特征的平均。
根据以上,就可以求得当前时刻最大概率的输出词,并作为下一时刻的输入,从而获得整个描述( caption)结果。


Hard attention,这里权重a t所起的作用的是否被选中,只有0、1两个选项,所以引入了变量sti,当区域i被选中时为1,否则为0。
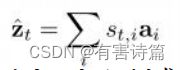
Soft attention,对每个区域都关注,只是关注的重要程度不一样,所以此处的权重α ti就对应着此区域所占比重,那么z就可以直接通过比重加权求和得到。