肿瘤预测(AdaBoost)-Python机器学习
文章目录
- 实验内容
- 实验要求
- AdaBoostClassifier参数解释
- 实验代码
- 运行截图
实验内容
基于威斯康星乳腺癌数据集,使用AdaBoost算法实现肿瘤预测。
实验要求
1.加载sklearn自带的数据集,使用DataFrame形式探索数据。
2.划分训练集和测试集,检查训练集和测试集的平均癌症发生率。
3.配置模型,训练模型,模型预测,模型评估。
(1)构建一棵最大深度为2的决策树弱学习器,训练、预测、评估。
(2)再构建一个包含50棵树的AdaBoost集成分类器(步长为3),训练、预测、评估。
参考:将决策树的数量从1增加到50,步长为3。输出集成后的准确度。
(3)将(2)的性能与弱学习者进行比较。
4.绘制准确度的折线图,x轴为决策树的数量,y轴为准确度。
AdaBoostClassifier参数解释
- base_estimator:弱分类器,默认是CART分类树:DecisionTressClassifier
- algorithm:在scikit-learn实现了两种AdaBoost分类算法,即SAMME和SAMME.R, SAMME就是AdaBoost算法,指Discrete。AdaBoost.SAMME.R指Real AdaBoost,返回值不再是离散的类型,而是一个表示概率的实数值。SAMME.R的迭代一般比SAMME快,默认算法是SAMME.R。因此,base_estimator必须使用支持概率预测的分类器。
- n_estimator:最大迭代次数,默认50。在实际调参过程中,常常将n_estimator和学习率learning_rate一起考虑。
- learning_rate:每个弱分类器的权重缩减系数v。fk(x)=fk−1∗ak∗Gk(x)f_k(x)=f_{k-1}a_kG_k(x)f k(x)=f k−1∗a k∗G k(x)。较小的v意味着更多的迭代次数,默认是1,也就是v不发挥作用。
实验代码
#导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier#导入AdaBoost包
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
#1.加载sklearn自带的数据集,使用DataFrame形式探索数据。
breast=load_breast_cancer()
data=pd.DataFrame(breast.data)
target=pd.DataFrame(breast.target)
feature_names=pd.DataFrame(breast.feature_names)
#print(pd.get_option("max_info_columns"))
#print(data.head())#使用pandas工具查看数据
#print(feature_names)
#pd.options.display.max_info_columns=200
#print(data.info())#查看数据集摘要
#print(data.describe())#数据描述性统计分析
#优化后
data=breast['data']
target=breast['target']
feature_names=breast['feature_names']
df=pd.DataFrame(data,columns=feature_names)
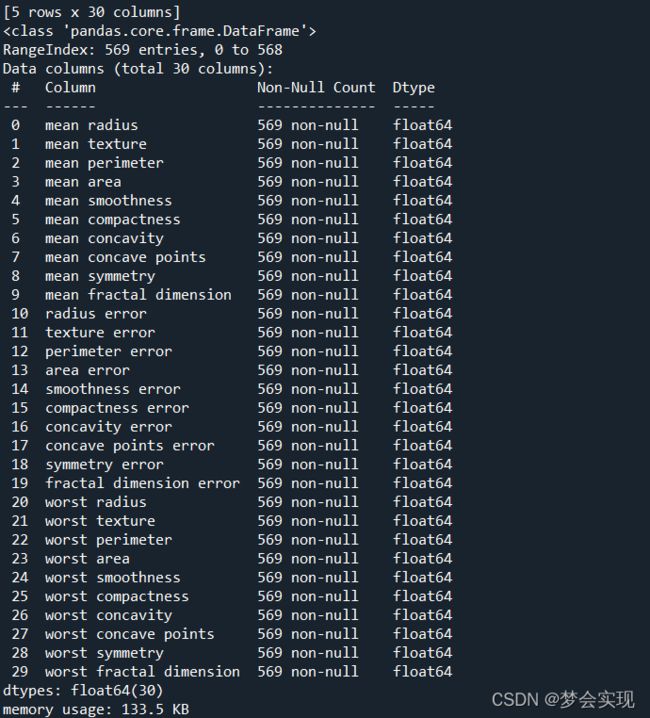
print(df.head())
df.info()
# 2.划分训练集和测试集,检查训练集和测试集的平均癌症发生率。
train_X,test_X,train_y,test_y=train_test_split(data,target,test_size=0.2)
# 3.配置模型,训练模型,模型预测,模型评估。
'''
#利用AdaBoost模型进行预测,输出模型评估报告
AdaBoost1=AdaBoostClassifier()
AdaBoost1.fit(train_X,train_y)
pred1=AdaBoost1.predict(test_X)
print("模型的准确率:",metrics.accuracy_score(test_y,pred1))
print("模型的评估报告:",metrics.classification_report(test_y,pred1))
'''
#(1)构建一棵最大深度为2的决策树弱学习器,训练、预测、评估。
AdaBoost2=AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=3))
AdaBoost2.fit(train_X,train_y)
pred2=AdaBoost2.predict(test_X)
print("模型的准确率:",metrics.accuracy_score(test_y,pred2))
print("模型的评估报告:",metrics.classification_report(test_y,pred2))
#(2)再构建一个包含50棵树的AdaBoost集成分类器(步长为3),训练、预测、评估。
AdaBoost3=AdaBoostClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=50,learning_rate=3)
AdaBoost3.fit(train_X,train_y)
pred3=AdaBoost3.predict(test_X)
print("模型的准确率:",metrics.accuracy_score(test_y,pred3))
print("模型的评估报告:",metrics.classification_report(test_y,pred3))
'''
参考:将决策树的数量从1增加到50,步长为3。输出集成后的准确度。
'''
#(3)将(2)的性能与弱学习者进行比较。
print("弱学习者的均方误差:",round(metrics.mean_squared_error(test_y,pred2),2))
print("决策树的均方误差:",round(metrics.mean_squared_error(test_y,pred3),2))
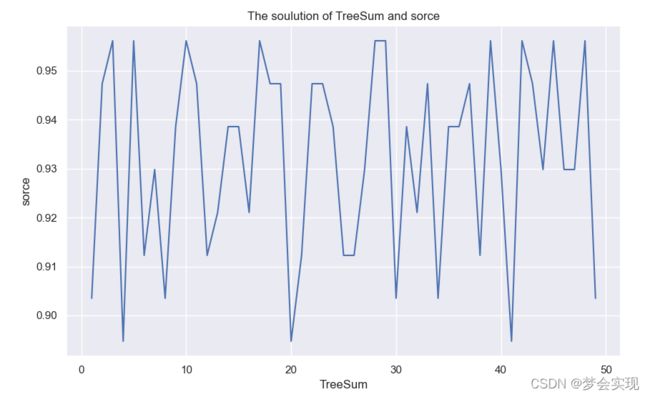
#4.绘制准确度的折线图,x轴为决策树的数量,y轴为准确度。
score_all=[]
for i in range(1,50):
AdaBoost4=AdaBoostClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=i,learning_rate=3)
AdaBoost4.fit(train_X,train_y)
pred4=AdaBoost4.predict(test_X)
score_all.append(metrics.accuracy_score(test_y,pred4))
plt.figure(figsize=(10,6))
plt.plot(range(1,50),score_all)
plt.xlabel(u'TreeSum')
plt.ylabel(u'sorce')
plt.title(u'The soulution of TreeSum and sorce')
plt.show()
运行截图