Edge AI边缘智能:Communication-Efficient Edge AI: Algorithms and Systems(未完待续)
边缘设备的大规模部署产生了空前规模的数据,这为在网络边缘开发各种智能应用提供了机会。然而,由于不同的信道质量、网络拥挤和隐私问题,这些庞大的数据不可能全部从终端设备发送到云端进行处理。通过将人工智能模型的推理和训练过程推到边缘节点,边缘人工智能成为一个很有前途的替代方案。edge AI需要智能手机和智能汽车等边缘设备与无线接入点(AP)和基站(BS)的边缘服务器之间的密切合作,但这会导致大量的通信开销。在本文中,首先总结了基于边缘节点的分布式训练人工智能模型的通信效率算法,包括零阶、一阶、二阶和联邦优化(federated optimization)算法。然后,对edge AI系统的不同系统架构进行了分类,包括基于数据分区(Data partition based edge training systems)、基于模型分区( Model partition based edge training systems)、基于计算卸载(Computation offloading based edge inference systems)和一般的边缘计算AI系统(General edge computing systems)。
文章目录
一、
一、Introduction
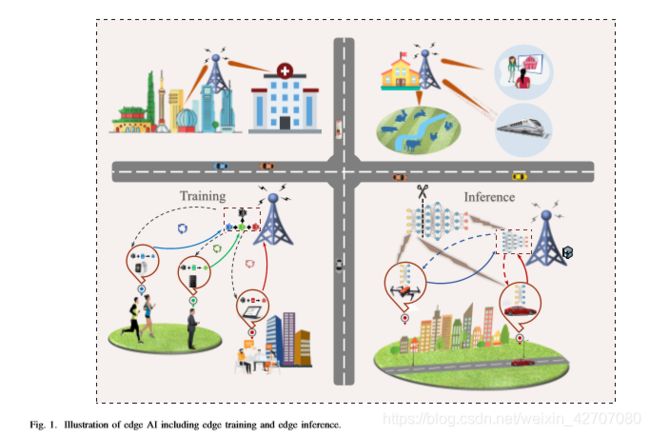
无线系统中的边缘节点可以包括边缘服务器、无线接入点和边缘设备,如下图所示。

将AI模型部署到边缘节点的合理方案是边缘节点协同合作来完成整个AI模型的训练和推理过程,如下图所示,采用联邦学习,利用多个边缘设备训练AI模型,每个设备只需要根据自己的数据样本计算一个局部模型,然后将计算结果发送到融合中心(fusion center),在那里对全局AI模型进行聚合和更新,然后新的AI模型将被传送回每个设备进行下一阶段的训练(传回去设备的是AI模型的相关参数)。
(Note: 训练过程的缺点:以协作的方式利用设备上的计算能力,但是,在模型更新过程中需要大量的通信开销。推理过程的缺点:一些计算密集型的AI推理任务只能通过边缘设备和边缘服务器之间的任务分割来完成,由于该任务需要要求大量计算,需要较多的边缘设备参与其中,分割的任务数也就多了,从而带来了沉重的通信成本。)
二、Motivations and Challenges
2.1 Motivations
5G的推出集中在联网事物的几个关键服务上:增强的移动宽带(eMBB)、超可靠的低延迟通信(URLLC)和大规模的机器类型通信(mMTC)。
6G网络的目标:从connected things到connected intelligence。6G的网络基础设施被设想为充分利用大规模分布式设备的潜力和在网络边缘生成的数据来支持智能应用程序[9]。
Training at network edges 要求协调大量边缘节点,协同构建机器学习模型。(Note:每个边缘节点通常只能访问一小部分训练数据,这是与基于云的模型训练的根本区别)。在边缘训练中,跨边缘节点的信息交换导致了很高的通信成本,尤其是在有限带宽的无线环境中。
Edge inference, i.e., performing inference of AI models at network edges,由于DNN(deep neural network)有大量的模型参数。因此在网络边缘部署DNN模型通常考虑的有model compression approaches, energy-efficient processing of deep neural networks(减少设备功耗),coding techniques来进行数据转换(减少内存)
2.2 Performance Measurements and Unique Challenges of Edge AI
2.2.1 Performance Measurements
edge AI的关键指标主要有:1)model accuracy:模型精度可以通过收集更多的训练数据来提高
2)total latency:从大量数据中训练一个机器学习模型是非常耗时的。分布式训练的过程主要包括计算延迟和通信延迟。计算延迟与边缘节点的能力密切相关。通信延迟可能因传输的原始或中间数据的大小和网络连接的带宽而异。
3)computaion and communication cost:为了有效地训练模型,通常采用分布式架构,这将引入额外的跨节点信息交换通信成本。对于像DNN这样的高维模型,计算和通信成本会增长得非常高。计算成本受主要受目标训练模型的大小和所用设备的资源的影响;通信开销受原始输入数据的大小、传输方式和可用带宽的影响。
2.2.2 Requirements on the algorithms and system architectures
1、 Limited resources on edge nodes:包括limited computation, storage, and power resources and limited link bandwidth
2、Heterogeneous resources across edge nodes:每个边缘节点在硬件、网络和功率预算都是不一样的,即拥有不同的 communication, computation,storage and power capabilities。
3、Privacy and security constraints: Federated learning 可以在协同构建机器学习模型的同时保护数据隐私。
2.3 Communication Challenges of Edge AI
设L为每轮交换信息的总大小(bits),r为通信速率(bits/s),N为通信轮数,T为每轮的总计算时间(s),则edge AI系统的总延时为:
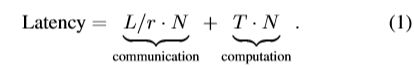
1、从the learning algorithm的角度来看,“要传输什么”决定了每轮所需的通信开销和通信轮数,如根据不同场景设计不同的梯度算法,有损压缩技术如量化、修剪( quantization and pruning )等可以用来减少通信开销。
2、edge AI系统设计对跨边缘节点的通信范式设计的影响: 从in-network computation的角度来研究全梯度的计算:通过聚集所有局部节点上局部计算的局部梯度,可以在一个集中节点上计算全梯度。(PS:What is in-network computation [20]?)
2.4 Related Works and Contributions
1、Algorithm level:加快算法收敛性、信息压缩技术(稀疏化,量化)可减少通信开销

2、System level: 数据分布 (e.g., distributed across edge devices), 模型参数 (e.g., partitioned and deployed across edge devices and edge servers), 计算框架 (e.g., MapReduce), and 通信机制(e.g.,aggregation at a central node)在不同的应用中是不同。对于训练AI模型的edge AI系统有:the data partition system and model partition system。对于部署AI模型的edge AI系统有:Computation offloading based edge inference systems and General edge computing systems.
三、Communication-efficient algorithms for edge AI
3.1 Communication-Efficient Zeroth-Order Methods
零阶优化方法用于只有函数值可用,但导数信息难以计算获得,甚至没有很好定义的应用中,举例:(1)在强化学习中,在没有建立模型的基础上用于决策函数学习(what?)(2)用于DNN的黑盒对抗攻击(what?),因为应用于现实生活中的DNN网络并不知道其内部参数。
对于具有中心协调中心的分布式设置,上行传输时只需要向中心节点传输一个函数值标量即可。
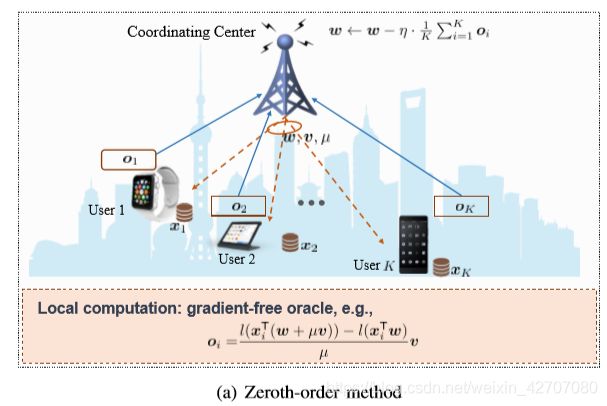
目前零阶优化方法应用的技术有:量化技术,将预测的梯度值量化成较小的bits来进行通信;each device communicates with its neighbors with some probability that is independent from others and the past, and this probability parameter decays to zero at a carefully tuned rate [153](没看明白,有时间再来看下该文)
3.2 Communication-Efficient First-Order Methods
梯度下降法的思想是用适当的步长迭代地更新与损失函数在该点的梯度方向相反的变量.
在设备间通信的梯度交换是其主要瓶颈之一,解决这一问题的一种方法是通过加快学习算法的收敛速度来减少通信次数。另一种方法是减少每轮的通信开销,包括梯度重用方法、量化、稀疏化和基于草图的压缩方法( sketching based compression )
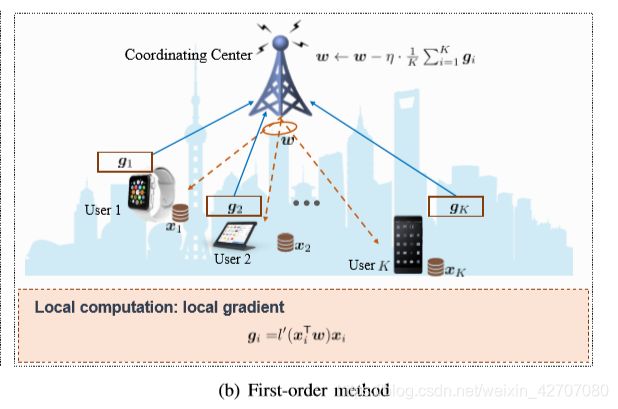
1) Minimizing Communication Round:在一般情况下,设备在每次迭代时将其局部梯度上传到融合中心,通过加快算法的收敛速度来减少通信周期,如采用mini-batch SGD(通信成本随的mini-batch大小线性下降);采用环形拓扑结构,每个设备只与直接相连的设备通信;调整学习速率来加快收敛。
影响算法的收敛速度:数据的统计异质性
2) Minimizing Communication Bandwidth:减少每个设备本地更新的大小
Gradient reuse:从理论上讲,在损失函数为强凸、凸或非凸光滑的情况下,LAG( lazily aggregated gradient )可以达到与BGD(batch gradient descent)相同阶数的收敛速度
Gradient quantization:标量量化方法被提出用少量比特压缩梯度来代替浮点表示法。但是在没有中心汇聚节点的去中心化网络下,一些标量量化方法会失败。梯度向量量化技术被提出来利用CNN梯度之间的相关性。向量量化[174]通过对一个向量的所有项进行联合量化,可以达到最优的率失真权衡; Grassmannian quantization ;Jiang等[175]提出了一种用于梯度压缩的非均匀量子化方法的 quantile sketch。Sketch是一种用概率数据结构近似输入数据的技术
Gradient sparsification:梯度稀疏化背后的基本思想是根据一些标准只传播重要的梯度。这是基于在训练中许多梯度通常是非常小的观察:忽略低于预定义常数阈值的梯度;Adacomp的局部选择梯度残基;对超过阈值的梯度进行通信,而对剩余的梯度进行累积,直到达到阈值; momentum correction, local gradient clipping, momentum factor masking,warm-up training;局部误差校正使梯度按幅度稀疏化[178],为大规模RNN的应用提供了理论基础
3.3 Communication-Efficient Second-Order Methods
一种方法是在中心节点上保持全局近似的逆海森矩阵,另一种方法是在每个设备上局部地解决二阶近似问题

发展近似二阶方法的一种常用方法是利用L-BGFS: Schraudolph等人[48]提出了一种不需要进行线性搜索的在线凸优化的随机L-BFGS;Moritz等人[50]提出了一种线性收敛的随机L-BFGS算法,该算法通过获得更稳定、更高精度的逆Hessian矩阵估计,但每轮需要更高的计算和通信开销
有效通信二阶方法的另一个主要思想是在每个设备上解决二阶近似问题:Shamir等人[51]提出了一种分布式近似牛顿型方法,命名为DANE,该方法使用全局聚集步长求解每个设备上的近似局部牛顿系统,该方法只需要与一阶分布式学习算法相同的通信带宽。随后,在[52]中提出的算法DiSCO通过分布式预条件共轭梯度法近似求解全局牛顿系统,在每一轮通信中求解更精确的二阶近似;Wang等人[53]提出了一种改进的近似牛顿法GIANT,通过在每个设备上的共轭梯度步进一步减少通信轮数,结果表明其性能优于DANE和DiSCO;在[54]中提出了一种新的自适应分布牛顿法,该方法通过在每轮中增加一个标量参数来补偿分布二阶近似的信息损失
3.4 Communication-Efficient Federated Optimization
使用额外的本地计算来降低通信成本:联邦优化[15]是一个基于每个设备上的数据集迭代执行局部训练算法并聚合局部更新模型的框架,即,计算局部更新模型参数的平均值(或加权平均值)。该框架为数据提供了额外的隐私保护,并有可能减少从大量移动设备聚合更新的通信轮数(许多模型压缩方法来减小模型大小,无论是在局部训练过程中还是在局部训练后压缩模型参数,都可以进一步降低联邦优化的聚合通信成本)
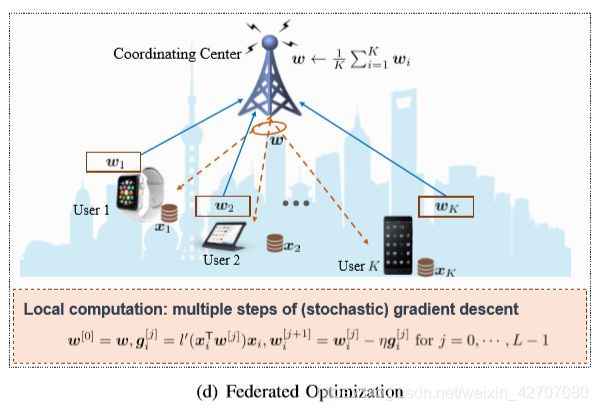
1) Minimizing Communication Round:[55]提出了一种新的框架CoCoA:在每个通信轮中,每个移动设备执行基于本地数据集的双重优化方法的多个步骤,以换取更少的通信轮,然后计算更新的本地模型的平均值(强对偶性失效或对偶问题难以求解时会失效);联邦平均(FedAvg)[18]算法是另一种通信效率高的联邦优化算法,它通过在每个设备上使用给定数量的SGD迭代和模型平均来更新本地模型,该算法只适用于每个设备上的数据样本来自相同的分布。在每轮通信中,每个设备以全局模型为初始点,执行给定数量的SGD步骤,并通过所有局部模型的加权平均得到聚合的全局模型。选择权值作为局部训练数据集的大小,该数据集对于非独立同分布(非iid)的数据分布和不平衡的移动设备数据分布具有很强的鲁棒性。
为了解决设备间的统计异质性,FedProx算法[56]通过在局部目标函数中添加一个最近项来限制局部更新模型接近全局模型,而不是在每一轮通信时用全局更新来初始化每个局部模型。
2) Minimizing Communication Bandwidth:
模型压缩的方法:
Quantization: 量化压缩DNNs的方法是用更少的比特表示权值,而不是采用32位浮点格式。[58],[184]采用kmeans聚类方法对一个预先训练好的DNN的权值进行聚类。在训练阶段,已有研究表明,仅使用随机舍入的16位宽定点数表示法就可以训练DNNs[185],这对分类精度几乎没有影响;在训练中学习二进制权值或激活,这在[59],[60],[61]中进行了深入的研究。这种方法允许大量的计算速度对设备由于按位操作。它还可以显著降低联邦学习中的通信成本,因为权值用1位表示。
Sketching: 在[62]中,HashedNet使用一个哈希函数勾画出神经网络的权值,并强制映射到同一个哈希桶的所有权值共享一个参数值。但它只适用于完全连接的神经网络;[63]将其扩展到CNNs,首先将滤波器权值转换到频域,然后使用低成本的哈希函数将相应的频率参数分组到哈希桶中。
Pruning: 网络剪枝通常通过根据某些标准删除连接、过滤器或通道来压缩DNNs。在[67]的工作中,提出了对一个预先训练好的网络的不重要的权值进行修剪,并对网络进行再训练,以调整剩余连接的权值,从而在不影响精度的情况下将AlexNet的参数数量减少9倍。在[27]中提出了深度压缩,将DNNs分为三个阶段进行压缩。,剪枝,训练量化和霍夫曼编码,这产生了相当紧凑的DNNs。Aghasi等[70]提出通过凸规划逐层修剪网络,这也表明整体性能下降可以由每一层重构误差的总和来约束。
Sparse regularization:通过在训练过程中在损失函数中加入正则化因子来诱导DNNs的稀疏性来实现学习紧凑型DNNs(无须预训练)[72-74]
Structural matrix designing:在压缩神经网络中,低秩矩阵分解的主要思想是将低秩矩阵分解技术应用于神经网络的权矩阵

在[76]中,为了加速卷积,每个卷积层都被一个低秩矩阵近似,并研究了不同的近似矩阵来提高性能。在[77]的工作中,提出了通过为一个预先训练好的CNN构造rank-one滤波器的低秩基来加速卷积层。
低秩的方法在训练阶段也得到了应用。在[78]中,利用低秩方法来减少在训练中学习的网络参数的数量。在[79]、[80]中也采用了低秩方法来学习可分离滤波器来加速卷积,通过增加额外的正则化来找到低秩滤波器。
另一种减少权矩阵参数数量的方法是利用结构化矩阵,Sindhwani等[81]提出学习DNNs的结构化参数矩阵,通过快速的矩阵向量积和梯度计算,也大大加快了推理和训练的速度。文献[82]提出在全连通层的权值矩阵上加入循环结构,在训练阶段和推理阶段加速计算。在[83]中,作者提出了一种自适应Fastfood变换来重新参数化全连通层的矩阵向量乘法,从而降低了存储和计算成本。
四、COMMUNICATION-EFFICIENT EDGE AI SYSTEMS
4.1 Architectures of Edge AI Systems
Data partition based edge training systems: 数据被大量地分布在许多边缘设备上,每个边缘设备只有整个数据集的一个子集。在训练期间,每个边缘设备持有一个完整AI模型的副本来计算一个本地更新。
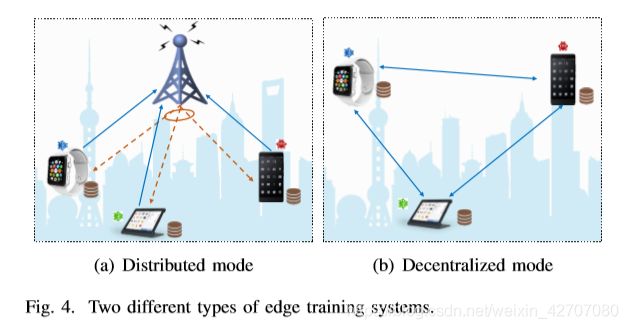
Model partition based edge training systems: 每个节点并只有有AI模型一部分参数的副本。此外在每个边缘节点只能访问一组公共用户身份的部分数据属性时,如何在训练过程中保护数据隐私受到了广泛的关注。它通常被称为vertical federated learning [19]。为了保护数据的私密性,我们提出通过边缘设备和边缘服务器的协同作用,对设备进行简单的处理,并将中间值上传到功能强大的边缘服务器来训练模型。这是通过在设备上部署一小部分模型参数来实现的,并且在边缘设备上保留部分以避免用户数据的暴露。
Computation offloading based edge inference systems:启用低延迟的边缘AI服务,关键是要将经过训练的模型部署到接近最终用户的地方。有两类:将整个模型部署到边缘服务器上、对模型进行分区,然后跨边缘设备和边缘服务器进行部署。
General edge computing systems:mapreduce的框架通常会联合考虑分布式数据输入和分布式模型部署,以加速分布式训练或推理。编码技术在可伸缩的数据变换(scalable data shuffling )[138]、[30]以及降低掉线率( straggler mitigation )[142]中起着关键作用。
4.2 Data Partition Based Edge Training Systems
每个设备通常有一个训练数据子集和一个机器学习模型的副本。训练可以通过执行本地计算和定期交换来自移动设备的本地更新来完成。该系统的主要优点是适用于大部分的模型体系结构,具有良好的可扩展性。主要缺点是模型大小和完成本地计算所需的操作受到每个设备的存储大小和计算能力的限制。
1) Distributed System Mode: 通信瓶颈来自于聚合来自移动设备和掉队设备的本地更新。挑战如下:
Fast aggregation via over-the-air computation:空中计算是利用无线多址信道的信号叠加特性来计算分布式数据函数的一种有效方法[189]。可以通过空中计算计算的函数称为nomographic function[190],通过无线信道可聚合这些值。对于属于nomographic函数类的集合函数,我们可以通过利用空中计算来提高通信效率。
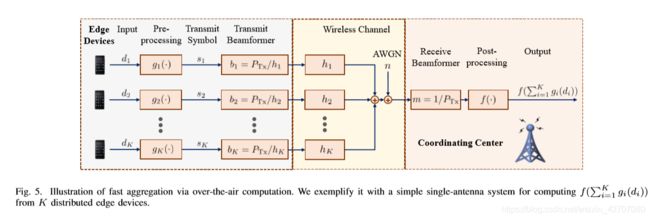
Yang等人[21]提出采用空中计算方法进行快速的模型聚合,聚合函数是来自分布式移动设备的更新的一个线性组合,它属于一组nomographic函数,通过研究无线多址信道的信号叠加特性,采用收发器设计,提高了无线多址信道的通信效率,降低了所需带宽;在[21]中考虑了节点设备选择和波束形成的设计问题,提出了稀疏和低秩优化方法,使所提出的空中计算具有良好的快速模型聚合性能。
空中计算对于快速聚合的效率也在[84]中得到了证明,它描述了通信和学习性能之间的两个权衡。第一个问题是接收信噪比测量的更新质量与提出的深衰落信道干信道反演策略所导致的模型参数截断比之间的权衡。第二个问题是接收信噪比与被利用数据的比例之间的权衡,即当数据均匀分布在设备上时,调度单元内部设备的比例。
Amiri和Gunduz[85]在空中计算的基础上,提出了一种梯度压缩和随机线性投影的方法,以减小由于信道带宽有限而导致的梯度维数,与基于计算和通信的独立方法相比,该方法具有更快的收敛速度。这项工作在[86]中进一步扩展到无线衰落信道。
Aggregation frequency control with limited bandwidth and computation resources:学习过程包括不同设备的局部更新和融合中心的全局聚合。我们可以在一个或多个本地更新的间隔内聚合本地更新,例如采用联合平均算法[18]。通过权衡本地设备上有限的计算资源和用于全局数据聚合的有限的通信带宽来仔细设计聚合频率。
Wang等[87]从理论角度给出了基于梯度下降的联邦学习的收敛边界。基于此收敛结果,作者提出了一种学习数据分布、系统动态和模型特征的控制算法,该算法可以实时动态确定全局聚集的频率,从而在固定资源预算下最小化学习损失。Zhou和Cong[88]建立了非凸损失函数K步平均的分布式随机梯度下降算法的收敛结果。文献[89]研究了从总运行时间而不是迭代次数上的收敛率,提出了一种自适应通信策略,该策略从低聚合频率开始,以节省通信成本,然后增加聚合频率,以达到低错误下限。
Data reshuffling via index coding and pliable index coding: 数据重组[196]、[197]是一种公认的提高机器学习算法统计性能的方法。
为了降低数据重组的通信成本,Lee等[90]提出了一种基于索引编码的编码重组方法。这种方法假设数据放置规则是预先指定的。在每项工作中更新少量的新数据点可以提高统计学习性能,这促使了基于可塑指数编码的半随机数据重组方法的提出[91],以提高编码方案的设计效率。它声称每个设备的新数据不一定以特定的方式,每个数据在不超过c个设备上都是必需的(这称为c约束)。无线网络中也考虑了可塑数据重组问题[92],在每一轮中,作者建议使用新数据点来最大限度地更新设备数量,而不是更新所有移动设备的新数据。结果表明,该方法以牺牲学习性能为代价,大大降低了通信成本。
Straggler mitigation via coded computing:在梯度计算过程中,一些设备可能会掉队,即,这些设备需要更多的时间来完成计算任务。
Tandon等人[93]通过在设备上仔细复制数据集,提出对计算出的梯度进行编码以迁移掉队者,而冗余数据的数量取决于系统中掉队者的数量。在[94]中,掉队者的容忍和沟通成本被联合考虑。因此,与[93]相比,分布式梯度计算的总运行时间进一步减少,除了将计算分配到数据集的子集之外,还将计算分配到梯度向量分量的子集上。Raviv等[95]采用了经典编码理论中的工具,即梯度编码在参数的适用范围和编码算法的复杂度方面都取得了良好的性能。Halbawi等人[96]使用Reed-Solomon编码使学习系统比[93]更健壮。缓解掉队者影响所需的通信负载和计算负载方面的性能在[97]中得到了进一步的改进。
大多数的掉队缓解方法都假定掉队的设备对学习任务没有贡献。相比之下,[98]提出利用非持久性掉队者,因为他们能够在实践中完成指定任务的某个部分。这是通过在每轮通信中从设备向融合中心传输多个本地更新来实现的,而不是每轮只传输一个本地更新。
此外,在[95]中提出了近似梯度编码,其中融合中心只需要近似计算整个梯度,而不需要精确计算,这大大减少了来自设备的计算,同时保持了系统对掉线者的容忍度。然而,这种近似的gradient方法与精确的gradient方法相比,通常会导致学习算法的收敛速度较慢[99]。当损失函数是平方损失时,在[100]中提出用低密度校验码(LDPC)编码数据矩阵的第二矩,以减轻掉队者的影响。他们还指出,基于矩编码的梯度下降算法可以看作是一种随机梯度下降法,这为该方法提供了获得收敛性保证的机会。考虑到一般的损耗函数,在[101]中提出使用低密度生成器矩阵(LDGM)代码将数据分配到设备。Bitar等人[99]提出了一种近似的梯度编码方案,基于成对均衡设计,将数据点冗余地分布到设备上,而忽略掉掉线的部分。建立了收敛保证,并通过数据冗余来提高收敛速度[99]。
2) Decentralized System Mode: 在去中心化模式下,通过直接交换信息而不需要中心节点,利用多个边缘设备对机器学习模型进行训练。众所周知的分散信息交换范式是 gossip communication protocol [199],它通过随机唤醒一个节点作为中心节点来收集邻居节点的更新或将其本地更新广播给邻居节点。将 gossip communication protocol 集成到学习算法中,提出了 Elastic Gossip [102] and Gossiping SGD [103] [104] [105]。
分散机器学习的典型网络拓扑结构是全连接网络,其中每个设备直接与所有其他设备通信。在这个场景中,每个设备维护模型参数的一个本地副本,并计算将发送到所有其他设备的本地梯度。每个设备可以平均从其他设备接收到的梯度,然后执行本地更新。在每次迭代中,如果每个设备从相同的初始点开始,则所有设备上的模型参数都是相同的。这一过程与集中式服务器上的经典梯度下降过程基本相同,因此可以保证集中式设置下的收敛性。然而,这样一个完全连接的网络承受着沉重的通信开销,在设备数量上呈平方增长,而在集中设置的设备数量上,通信开销是线性增长的。因此,网络拓扑设计在缓解分散场景中的通信瓶颈方面起着关键作用。此外,分散算法的收敛速度也取决于网络的拓扑结构[106]。需要注意的是,分散的edge AI系统与分布式模式下的系统有着相同的问题,因为每个设备都扮演着融合中心的角色。
在[107]中观察到,拥有1000台设备的ErdosRenyi图拓扑可以与拥有3000台设备的标准全连通拓扑竞争,这表明,如果对拓扑进行精心设计,机器学习性能会更有效。考虑到不同的设备可能需要不同的时间来进行局部计算,Neglia等[108]分析了不同网络拓扑对分布式次梯度方法总运行时间的影响,从而确定了拓扑图的度,从而加快了收敛速度。他们还表明,稀疏网络有时会导致收敛时间的显著缩短。
用环形拓扑[109],其中每个设备只与布置在逻辑环中的相邻设备通信。更具体地说,每个设备聚集并沿着环传递它的局部梯度,这样所有设备在末端都有一个完整梯度的副本。该方法已在分布式深度学习模型更新中得到应用[110],[111]。然而,部署在环形拓扑结构上的算法对掉队者具有固有的敏感性[112]。为了缓解环拓扑中掉队者的影响,Reisizadeh等人[112]提出使用逻辑树拓扑进行通信,并在此基础上通过梯度编码技术减轻掉队者的影响。在树状拓扑结构中,有几个设备层,其中每个设备仅与其父节点通信。通过并发地将大量子节点的消息传输到多个父节点,与树拓扑的通信可能比与环拓扑的通信更有效。
4.3. Model Partition Based Edge Training Systems
在这样的系统中,每个节点持有部分模型参数,协同完成模型训练任务或推理任务。在训练过程中,模型划分的一个主要优点是每个节点都需要一个较小的存储空间。在该系统中,机器学习模型被分布在多个计算节点中,每个节点只评估模型参数的一部分更新。这种方法在机器学习模型太大而不能存储在单个节点的情况下特别有用[200],[201]。在训练过程中,模型划分的另一个主要关注点是当每个节点上的数据属于不同对方时的数据隐私。然而,使用基于模型分区的架构进行模型训练也会在边缘设备之间造成沉重的通信开销。
• Model partition across a large number of nodes to balance computation and communication:已有文献[113]、[114]、[115]考虑了具有异构硬件和计算机能力的跨边缘节点的模型划分。在[113]中,提出了一种将计算图部署到边缘计算设备上的强化学习方法,然而,这种方法需要大量的时间和资源。为了避免基于强化学习方法的巨大计算成本,Harlap等[114]提出了PipeDream系统来自动确定DNNs的模型划分策略。此外,与使用单一机器或使用数据分区方法相比,注入多个小批量会使系统收敛得更快。虽然PipeDream强调边缘设备的硬件利用,但是每个设备应该维护多个版本的模型参数,以避免由于异步向后更新的参数过时而导致的优化问题。这阻碍了PipeDream扩展到更大的模型。为了解决这个问题,在[115]中提出了GPipe系统,该系统采用了新颖的batch-splitting and re-materialization技术,能够扩展到大型模型,而几乎不需要额外的通信开销。
• Model partition across the edge device and edge server to avoid the exposure of users’ data: 在实践中,强大的边缘服务器通常由服务提供商拥有,但是用户可能不愿意将他们的数据暴露给服务提供商进行模型培训。观察到一个DNN模型可以分成两个连续的层,这促使研究人员将设备的前几层部署在本地,其余的层部署在边缘服务器上,以避免暴露用户数据。Mao等[116]提出了一种隐私保护的深度学习体系结构,其中DNN的浅层部署在移动设备上,大部分部署在边缘服务器上。Gupta和Raskar[202]设计了一个跨多个代理的模型划分方法,即并将其扩展到具有少量标记样本的半监督学习情形。在华为Nexux 6P手机上对特定的DNN人脸识别模型进行了训练和评估,获得了满意的效果。在[117]中,提出了一种兼顾隐私和性能的分区方法ARDEN。移动设备上的模型参数是固定的,并引入差分隐私机制来保证移动设备上输出的隐私。在上传本地输出之前,故意添加噪声以提高DNN的鲁棒性,这对推理性能是有益的。
• Vertical architecture for privacy with vertically partitioned data and model: 在大多数行业中,数据通常是垂直划分的,即,每个所有者只持有部分数据属性。由于竞争、隐私和管理过程,数据隔离成为协作构建模型的严重瓶颈。因此,利用垂直分块数据[19]来保护隐私的机器学习受到了广泛的关注。在训练过程中,模型也被垂直分割,每个所有者持有一部分模型参数。因此,提出并研究了面向隐私保护的机器学习的垂直人工智能体系结构,其中每个节点都可以访问公共数据实例的不同特征并维护相应的模型参数子集。更糟糕的是,每个数据实例的标签只对属于一方的节点可用.
Vaidya和Clifton[118]提出了一种具有安全多方计算的垂直架构下的隐私保护kmeans算法。Kantarcioglu和Clifton[119]研究了垂直分区数据的安全关联规则挖掘问题。文献[120]考虑了线性回归模型,提出了基于半托管式第三方实现安全、可扩展训练的多方计算协议。对于隐私保护分类与支持向量机(SVM),Yuetal。[121]考虑支持向量机的对偶问题,采用随机扰动策略,该策略只适用于三个以上的节点。文献[122]提出了一种基于决策树的隐私保护分类方法,该方法采用交换加密等安全多方计算过程来确定是否存在剩余属性,并对集合交集进行安全基数计算。对于逻辑回归的分类,由于目标函数的耦合和梯度的存在,使得问题变得更加困难。为了解决这个问题,Hardy等人[123]提出使用泰勒近似来受益于同态加密协议,而不暴露每个节点的数据。
4.4 Computation Offloading Based Edge Inference Systems
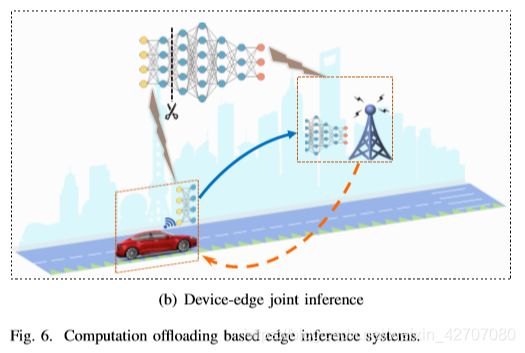
将整个推理任务卸载到一个边缘服务器上,称为基于服务器的边缘推理,如图6(a)所示。它特别适用于资源有限的物联网设备。在这种情况下,整个AI模型都部署在边缘服务器上,边缘设备应该将它们的输入数据上传到边缘服务器进行推理。对于延迟和隐私问题,另一种方法是只将部分任务转移到边缘服务器,边缘服务器根据边缘设备计算的中间值计算推理结果。我们将其称为如图6(b)所示的设备边缘联合推理。这种边缘设备和边缘服务器的协作可以通过在设备上执行简单的处理和在边缘服务器上执行其余部分来实现。

1) Server-Based Edge Inference: 数据传输的主要瓶颈是有限的通信带宽。在带宽受限的边缘AI系统中,为了减少上行链路传输的实时数据传输开销,一种有效的方法是在不影响推理精度的前提下减少设备传输的数据量。此外,为了提高边缘推理的通信效率,提出了多边缘服务器协作下行传输的方案。
• Partial data transmission: 为了实时实现基于云的移动机器人视觉定位,通过网络控制数据量是非常重要的。因此,Ding等人[124]采用了[125]提出的多机器人通信的数据压缩方法,即采用稀疏化方法对数据进行压缩。在基于云计算的协作3 d映射系统中,Mohanarajah等人[126]提出减少带宽需求通过发送只有关键帧,而不是所有的帧产生的传感器,和陈等。[127]提出了确定和卸载等对象检测利用启发式的关键帧选择关键帧的帧差异。当我们能够利用特定任务的结构和相关数据时,这些方法在降低通信成本方面很有用。
• Raw data encoding: 数据编码在压缩数据量中得到了广泛的应用。例如,传统的图像压缩方法(如JPEG)可以积极地压缩数据,但它们通常是从人-视觉的角度进行优化的,如果我们使用高压缩比,这将导致DNN应用程序中无法接受的性能下降。在此基础上观察,达到更高的压缩比,刘等人[128]提出优化数据编码方案从款基于频率分量的角度分析和纠正量化表,这是能够实现更高的压缩率比传统的JPEG方法没有退化图像识别的准确性。与使用标准的视频编码技术不同,在[129]中有人认为,数据收集和传输方案应该在视觉任务中联合设计,以利用预先训练的模型最大化端到端目标。具体来说,作者建议使用DNN将高维原始数据编码为一个稀疏的、潜在的表示,以实现有效的传输,这些数据稍后可以通过解码DNN在云中恢复。此外,该编码过程由一种增强学习算法控制,该算法将动作信息发送到设备进行编码,以最大限度地提高具有解码输入的预训练模型的预测精度,同时实现通信效率高的数据传输。这种新的数据编码思想是实现边缘人工智能系统实时推理的一种很有前途的解决方案。
• Cooperative downlink transmission: 协同传输[203]是一种通过多基站的主动干扰感知协调来提高通信效率的有效方法。文献[130]提出了将每个推理任务卸载到多个边缘服务器上,通过下行传输将输出结果协同传输给移动用户。智能反射面(intelligent reflection surface, IRS)[204]是一种提高无线通信网络频谱效率和能源效率的有效方法,在促进通信效率高的边缘推理方面具有广阔的应用前景[205]。它是通过一个平面阵列来重新配置无线传播环境,从而引起信号幅度和/或相位的变化。为了进一步提高[130]中合作边缘推理方案的性能,Hua等[131]提出了irs辅助边缘推理系统,并设计了任务选择策略,使上行链路和下行链路的传输功耗以及边缘服务器的计算功耗最小化。
2) Device-Edge Joint Inference: 对于许多设备上的数据,如医疗信息和用户行为,隐私是一个主要的问题。因此,通过在移动设备和强大的边缘服务器上部署分区的DNN模型,产生了边缘设备和边缘服务器协同的思想,可以称之为设备-边缘联合推理。通过在本地部署前几层,移动设备可以通过简单的处理来计算本地输出,并将本地输出传输到更强大的边缘服务器,而不会暴露任何敏感信息。
• Early exit: 在对DNNs进行分区时,可以使用Early exit来减少通信工作量,这是在[132]中提出的,其依据是观察到在网络的早期层获得的特征通常足以产生准确的推理结果。因此,如果能够对数据样本进行高可信度的推断,推理过程就可以提前退出。该技术已在[133]中用于云、边缘和设备上的分布式DNN推理。通过提前退出,每个设备首先执行DNN的前几层,如果设备的输出不满足精度要求,则将剩余的计算任务转移到边缘或云上。与将所有原始数据卸载到云中进行推理的传统方法相比,这种方法能够将通信成本降低20倍以上。最近,Li等[211]根据移动设备和边缘服务器之间的异构计算能力,联合设计模型分区策略,根据复杂的网络环境,联合设计早期退出策略,提出了按需低延迟推理框架。
• Encoded transmission and pruning for compressing the transmitted data: 在分层分布式体系结构中,主要的通信瓶颈是在分区点之间传输中间值,因为中间数据可能比原始数据大得多。为了减少中间值传输的通信开销,[134]中提出将网络划分在中间层,中间层的特征在无线传输之前进行编码以减少数据量。结果表明,在最后一个卷积层的末端对CNN进行分区,数据通信需求较少,再加上特征空间编码,可以显著减少通信工作量。最近,在[212]中提出了一种基于深度学习的端到端架构,命名为BottleNet++。通过共同考虑模型分区,功能压缩和传输,相比于只是传输中间数据没有压缩的模型,在减少不到2%的准确性下,BottleNet + +实现64 x带宽减少了加性高斯白噪声信道和256 x二进制消除信道压缩比特率。
网络修剪,已经被用于减少中间特征传输的通信开销。文献[135]提出了两步修剪方法,通过限制修剪区域来减少网络分区点的传输工作量。具体来说,第一步是减少网络的总计算量,第二步是压缩传输的中间数据。
• Coded computing for cooperative edge inference: 编码理论可以用来解决边缘人工智能系统中分布式推理的通信挑战。例如,Zhang和Simeone[136]考虑了移动边缘AI系统中的分布式线性推理,该模型被分割到几个边缘设备之间,这些边缘设备协同计算每个设备的推理结果。在[136]中显示,编码在降低总体计算加通信延迟方面是有效的。
4.5 General Edge Computing System
MapReduce[188]是一个通用的分布式计算框架,能够在训练和推理过程中对各种机器学习问题实现并行加速[213]。类mapreduce的分布式计算框架将分布式数据输入和分布式模型部署结合起来考虑。在[214]中,为了加速训练过程,基于MapReduce框架实现了卷积神经网络。Ghoting等人[215]提出了基于MapReduce框架的SystemML,以支持针对一类广泛的监督和非监督机器学习算法的分布式训练。[30]为支持基于mapreduce的分布式推理任务,提出了一种通信效率高的无线数据变换策略。
在图7所示的类mapreduce分布式计算框架中,一般分为三个阶段(即,一个map阶段,一个shuffle阶段,和一个reduce阶段)来完成一个计算任务。在map阶段,每个计算节点计算所分配数据的映射函数,同时生成许多中间值。在shuffle阶段,节点之间进行通信,以获得一些中间值来计算输出函数。随后,在reduce阶段,每个节点根据可用的中间值计算分配的输出函数。然而,在这样一个分布式计算框架中有两个主要的瓶颈。一个是在shuffle阶段的沉重的通信负载,另一个是由于不同节点上计算时间的可变性而导致的延迟。为了解决这些问题,编码被认为是一种很有前途的方法,它利用了网络边缘丰富的计算资源[137]。近年来,编码技术正在成为降低数据变换的通信成本以及通过减少掉队节点来降低计算延迟的研究热点,如下所述。

• Coding techniques for efficient data shuffling: 类似于mapreduce的分布式计算框架中的数据变换编码技术最早在[138]中被提出,它考虑了一个有线场景,其中每个计算节点可以通过一个共享链接从其他节点获取中间值。在[29]中,作者将[138]的工作扩展到无线设置,在无线设置中,计算节点可以通过接入点彼此通信。提出了一种可扩展的数据变换方案,利用在设备之间放置中间值的特定重复模式,通过设备数量线性增长的因素来减少通信带宽。为了提高在数据转移阶段的无线通讯效率,通过建立干涉对准条件,在[30]中提出了一个低秩优化模型。低秩模型被对流函数差分(DC)算法进一步求解。[29]和[30]都考虑了具有中心节点的无线通信设置下的通信负载最小化问题。
也有一些工作是考虑在没有协调中心的无线通信场景下,如何减少数据变换中的通信负载。也就是说,计算节点之间可以通过共享的无线干扰信道进行通信。例如,在假设信道状态信息完美的情况下,[139]提出了一种基于侧信息抵消和零强迫来权衡大量计算节点以减少通信负载的波束形成策略,其性能优于基于[138]的编码TDMA广播方案。这项工作在[140]中进一步扩展,以考虑不完全信道状态信息。本文[141]针对计算结果提出了数据集缓存策略和编码传输策略。其目标是最小化以延迟(以秒为单位)而不是信道使用(以比特为单位)为特征的通信负载,后者在无线网络中更实用。在[142]中,作者指出,为了用大量的计算来交换通信负载,计算任务必须被划分为大量的子任务,这是不切实际的。因此,他们提出了通过节点协作来改善这种局限性,并设计了一种高效的任务分配方案。Prakash等人[143]研究了分布式图数据处理系统的编码计算,该系统利用图数据的结构,显著提高了与一般MapReduce框架相比的性能。
• Coding techniques for straggler mitigation: 另一个工作重点是通过编码技术解决分布式计算中的掉队问题。利用编码理论缓解掉队者的影响在[142]中首次针对有线网络提出。其主要思想是利用冗余计算节点执行计算子任务,只要收集到计算节点任意子集的局部计算结果,就可以正确地恢复计算结果。该工作扩展到无线网络[144],在无线网络中,一次只能有一个本地计算节点将计算结果发送到融合中心。文献[145]提出了一种最小化总延迟的子任务分配方法,该方法由不同计算节点与融合中心之间的无线通信引起的延迟和不同设备计算时间变化引起的延迟组成。上述工作大部分集中在线性计算(如矩阵乘法)。然而,为了实现最先进的机器学习算法(如DNN)的分布式推理,需要考虑非线性计算。因此,文献[146]提出了一种基于学习的设计代码的方法,可以处理分布式非线性计算问题中的掉线问题。
五、总结
本文对通信挑战和解决方案进行了全面的调查,这些挑战和解决方案将在网络边缘支持大量支持人工智能的应用程序。具体来说,我们首先总结了用于边缘节点上分布式训练AI模型的通信效率算法,包括零阶、一阶、二阶和联邦优化算法。然后,我们将边缘人工智能系统的不同系统架构进行了分类,包括基于数据分区和基于模型分区的边缘训练系统。接下来,我们回顾了弥合计算卸载和边缘推断之间差距的工作。除了这些系统架构之外,我们还介绍了一般的边缘计算定义的AI系统。广泛讨论了这种体系结构中的通信问题和解决方案。