阅读笔记 | Code to Comment “Translation”:Data, Metrics, Baselining & Evaluation

摘要

最早的代码摘要自动生成方法是建立在【strong syntac-tic theories of comment-structures】之上的,并且依赖于文本模板。近年来,研究人员已经将深度学习方法应用到这项任务中,特别是【trainable generative translation models】,这些模型在自然语言翻译任务中表现很好。
作者在这篇论文里仔细研究了以下基本假设:代码摘要自动生成任务与自然语言翻译任务是足够相似的,因此可以使用相似的模型和评价指标。

作者分析了代码摘要自动生成任务的以下几个数据集:CodeNN,DeepCom,FunCom, and DocString.
然后将这些数据集与WMT19数据集进行了比较,发现了代码摘要自动生成数据集与WMT19数据集之间的一些有趣的差异。其中,WMT19是一个常用于训练自然语言翻译模型的标准数据集。

接下来,作者介绍了BLEU这个经常用来评价生成注释的质量的指标,并做了一些【calibrate】BLEU的研究(using “affinity pairs" of methods, from different projects,in the same project, in the same class,etc;)。研究结果表明,目前在某些数据集上的性能可能需要大幅的提高【?】。

此外,作者还认为,简单的信息检索(IR)方法在这项任务中已经表现得足够好了,因此可以作为一个合理的baseline。

最后,作者对如何将该论文的研究成果应用于未来的研究提出了一些建议。
1 INTRODUCTION


注释可以被看作是代码语义的重述,使用一种不同的、更易于理解的自然语言; 因此,可以将注释生成看作是一种翻译任务,即从一种(编程)语言翻译到另一种(自然)语言。这种观点,加上开源项目中大量的代码(附带注释),为利用统计自然语言翻译(NLT)方面数十年的研究提供了非常有吸引力的可能性。最近的几篇论文[22,26,33,61]探讨了利用统计机器翻译(SMT)方法来学习将代码翻译成英语评论的想法。但是这些任务真的相似吗? 我们有兴趣更详细地了解从代码生成注释的任务与在自然语言之间转换的任务是多么相似。

注释形成领域特定的方言,它是高度结构化的,具有大量重复的模板。注释通常以诸如“ returns the”、“ outputs”和“ calculate the”这样的模式开头。
3.【 Zipf plots】【?】
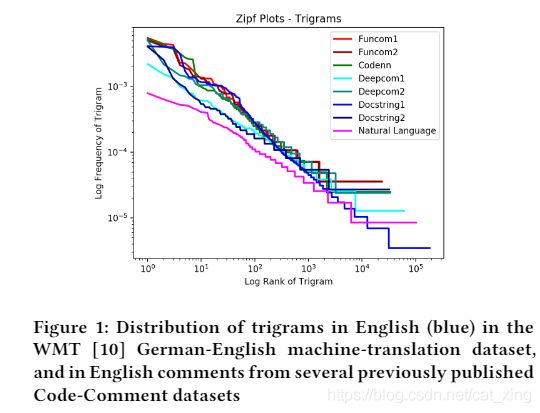

图1比较了WMT德英翻译数据集中英语文本注释(来自用于训练深度学习模型进行代码-注释摘要的数据集[22,26,33])和英语文本注释中的三字母频率:x轴使用对数秩尺度将三元图从最频繁到最不频繁排序,y轴是三元图在语料库中的对数频率。

代码中的注释显示Zipf图的(注意,对数比例)y轴上的斜率始终较高,这表明注释中包含的重复三元关系远比翻译数据集中的英语多得多。这一观察结果促使我们进一步研究代码注释和 WMT 数据集之间的差异,以及使用机器翻译方法生成代码注释的意义

在本文中,我们比较了用于注释生成任务的代码注释翻译(CCT)数据集与用于自然语言翻译的常用自然翻译(WMT)数据集。
1.我们发现 CCT 任务的期望输出更具有重复性。
2.我们发现重复性对测量的性能有很强的影响,在 CCT 数据集中的影响比 WMT 数据集中的影响更大。
3.我们发现WMT翻译数据集具有更平滑、更健壮的输入输出依赖关系。相似的德语输入在WMT中有产生相似的英语输出的强烈倾向。然而,这似乎在cct数据集中是存在的。
4.我们报告说,一个简单的信息检索方法可以满足或超过报告的数字从神经模型
5.我们使用不同“亲和力”的方法来评估BLEU本身作为生成评论质量的度量;这为BLEU测度提供了新的视角

我们的研究结果对该领域的未来工作有一些启示,包括技术方法、测量方法、基准化以及校准 BLEU 评分。

但是首先,有一个免责声明: 这项工作没有提供任何新的模型或改进的先前结果的 CCT 任务。
2 BACKGROUND & THEORY




早期的工作[11,40,48,49]是基于规则的,结合对源代码的一些形式分析来提取特定的信息,然后可以将这些信息放入不同类型的模板中产生注释。另一种方法是使用代码克隆标识为给定的代码生成注释,使用与克隆相关的注释[59]。其他的方法使用了程序员在眼球追踪研究中关注的关键词。还有一些方法使用主题分析来组织代码的描述[37]。

上面提到的这些开拓者式的方法大多依赖于特定的特征和手工设计的规则来完成产生评论的任务。拥有大量源代码的大型开放源代码库的出现提供了一种新颖的、通用的、统计上严格的、可持有性: 这些大型数据集可以被挖掘为代码注释对,然后可以用于训练模型从代码中产生注释。

【不懂】

在经典 SMT 的案例中,DL 不是依赖于特定的归纳偏见,比如短语结构,而是承诺与翻译相关的特征本身可以从大量的数据中学习
最近的几篇文章[24,26,33]已经探索了如何使用这些强大的DL方法来完成代码注释任务
RQ
RQ1. What are the differences between the translation (WMT)data, and code-comment (CCT) data?
翻译(WMT)数据和代码注释(CCT)数据之间有什么区别?

我们分析了已发表的文献,首先讨论了代码解释翻译(CCT)和统计机器翻译(WMT)数据之间是否存在显著的分布差异。我们的研究考察了输入和输出数据的分布,以及输出对输入的依赖性。
RQ2. How the distributional differences in the SMT & CCT datasets affect the measured performance?
SMT 和 cct 数据集中的分布差异如何影响测量的性能?




我们检验这些差异是否真的影响了翻译模型的性能。在早期的工作中,Allamanis[3]指出了数据复制对机器学习在软件工程中的应用的影响。我们研究了数据重复的影响,以及分布差异对深度学习模型的影响。
SMT数据集的一个重要方面是输入-输出依赖性。在德语(DE)到英语(EN)的翻译过程中,相似的 DE 输入句会产生相似的 EN 输出句,而不相似的 DE 输入句会产生不相似的 EN 输出句。这种相关性可能不适用于 CCT 数据集。
RQ3. Do similar inputs produce similar outputs in both WMTand CCT datasets?
在 wmt 和 CCT 数据集中,类似的输入是否产生相似的输出?

细微的差别,比如用 * 代替 + ,用1代替0,可以使和和函数与阶乘函数之间产生差异; 这些小的更改应该会导致相关注释的大更改。同样,有许多不同的方法来编写排序函数,所有这些方法都可能需要相同的注释。
从直觉上看,这在自然语言中似乎不是什么大问题; 因为它们已经进化到在嘈杂环境中进行必然的交流,所以意义应该对小的变化具有强健性。

为什么这很重要?一般来说,现代机器翻译方法利用了深度学习模型的广义函数逼近能力。如果自然语言翻译(WMT)具有更多的功能依赖性,而 CCT 没有,那么深度学习模型将会发现 CCT 是一个更大的挑战
RQ4. How do the performance of naive Information Retrieval(IR) methods compare across WMT & CCT datasets?
在 WMT 和 CCT 数据集中,朴素的信息检索方法的性能如何比较??
我们这里的目标是询问 IR 方法是否可以成为 CCT 任务的一个相关的、有用的基线
RQ5. How has BLEU been used in prior work for the code-comment task, and how should we view the measured per-formance?

最后,我们批判性地评估BLEU分数在这项任务中的使用。鉴于我们发现用于训练smt翻译人员的数据集与代码注释数据集之间的差异,我们认为理解BLEU如何在这项任务中使用,并开发一些经验基线来校准之前工作中观察到的BLEU值是很重要的。

3 DATASETS USED

codenniyeretal[26]是一个早期的CCT数据集,从stackoverflow收集,带有C#和SQL的代码注释对。在我们的分析中,我们只使用了 c # 数据。StackOverflow 有一个众所周知的社区规范,用来避免冗余的问答; 重复的问题通常是在前面的文章中提到的。因此,这个数据集具有明显的无重复性。其他 CCT 数据集是不同的。

They also exclude getters, setters, constructors andtest methods.
后来,Hu 等人更新了他们的数据集和模型,大约有588,108个例子。我们称前者为 DeepCom1,并从后续工作中获得一个在线副本。我们参考现有的 DeepCom2,在网上获得一个副本。此外,DeepCom2在跨项目设置中有10倍的分布(测试集中的示例来自不同的项目)。
他们创建了两个数据集,一个是保留原始标识符的标准数据集,另一个是挑战数据集,其中标识符(不包括 javaapi 类名)被标准化标记替换。他们还确保来自同一项目的数据在培训和/或验证和/或测试中没有重复

Barone 和 senrich [8]通过抓取 GitHub 来收集 Python 方法和前缀注释“ docstrings”。然而,与其他数据集不同的是,Baroneet 不仅仅限于评论的第一句话。这会导致相对较长期的期望产出。
为了使用自然语言对评论数据进行基准测试,我们使用了来自第四届机器翻译大会(WMT19)的数据。经过人工检查,我们确定这个数据集提供了正式语言的良好平衡,这是某种领域特定的松散语言在日常用语中常见的。
在使用自然语言对注释数据进行基准测试时,我们希望确保词汇和表达式的多样性,以避免偏倚结果。我们使用了英德翻译数据集,并将该数据集中的英语与其他数据集中的注释进行了比较(这些数据集都是英语的) ,以确保度量的差异不是由语言差异造成的。
3.1 Evaluation Scores Used

在比较自然语言的翻译时,BLEU评分与人类对翻译质量的判断有很好的相关性。然而,bleu 的计算方法有细微的差别,这使得结果很难比较。
2.【?】

这些计算通常是所有 BLEU 实现中的标准,但也可能有一些变体。

Smoothing:在决定如何处理 pn = 0的情况时,出现了一种变化,即候选字符串中的 n-gram 不在参考字符串[12]中。有些实现选择了不同的方式来平滑这些问题。
Corpus vs. Sentence BLEU:
当评估一个翻译系统时,一个典型的方法是测量测试集中所有样本的BLEU(candidatevsreference)。因此,实施差异的另一个来源是决定如何在所有测试集分数之间组合结果。其中一个选项,最初是在Papineniet al.[43]中提出的,是“语料库BLEU”,有时被称为C-BLEU。在这种情况下,分子和分母会在测试语料库中的每个例子中累积。这意味着只要至少有一个例子有4克的重叠,p4就不会为零,因此几何平均值也不会为零。用于在测试语料库中组合的替代选项被称为“句子BLEU”或S-BLEU。在这个设置中,测试集的BLEU分数是通过简单地取集合中每个句子的BLEU分数的算术平均值来计算的


Tokenization Choices:
变化的最终来源不是指标是如何计算的,而是指标给定的输入。因为精确计数是在一个象征级别,已经注意到 bleu 对标记化非常敏感。标记化对于最终得分非常重要。作为一个玩具示例,假设一个参考句包含字符串“ calls function foo ()”和一个预测句包含字符串“ uses function foo()”。如果选择按空格进行标记化,则有tokens[calls,function,foo()]和[uses,function,foo()]。这种标记化只产生一个二元重叠,没有三元重叠或四元重叠。然而,如果一个人选择把它标记为[calls,function,foo,(,)]和[uses,function,foo,(,)],我们就会有三个重叠的bigram,两个重叠的trigram和一个重叠的4gram。这会导致超过15个BLEU-M2点或近40个BLEU-DC点的摆动(BLEU-M2和BLEU-DC如下所述)。
4.各种BLEU

这个名称并不是预先规定的,也不是标准的,只是作为本文档稍后的参考。


我之前使用的应该是这里的BLEU-DC,也就是NLTK的BLEU,选择的平滑函数是method4,后来改成了method3。

最后,我们注意到在以前的代码注释翻译工作中使用的各种 BLEU 量具有一定的风险。我们在下面进一步讨论。表3提供了一些证据,表明这种差异足以引起人们对所声称的进步的真实解释的关注; 正如我们在下文中所论证的,该领域可以从进一步的标准化中受益。
3.2 Models & Techniques
在本节中,我们概述了应用于此代码注释任务的各种深度学习方法。作者再次强调,本文的目的不是批评或改进特定的技术方法,而是通过对数据报的分析,了解其中的分布情况,以及最常用的评论度量(BLEU) ,以及使用这一度量的意义。


相关工作

Iyeret al [26]是这项工作的一个早期尝试,使用了一个相当标准的 seq2seq RNN 模型,并随着注意力的增强而得到加强。Huet al [22]也使用了类似的基于 rnn 的 seq2seq 模型,但是引入了输入源代码的“树状”预处理。相关方法[5]通过输入代码的 AST (使用 LSTMs)和产品代码摘要来摘录固定大小的随机路径样本。LeClairet al [33]提出了一种将代码的结构表示和序列表示结合起来的方法,他们还建议使用图形神经网络[32]。Wannetal [54]使用类似的方法,但提倡使用强化/学习来增强代元素。最近,有报道使用函数上下文[20]来改进评注合成。源代码词汇表扩散是一个众所周知的问题[28] ; 输入代码或输出注释中以前没有看到的标识符或方法名称会降低性能。Mooreet al [39]的新工作解决了这个问题,在输入中使用关于个人信息的对话,并在输出中使用子标记(bycamel-case 劈开)。最近 Zhang 等人(62)报道了将复杂的 IR 方法与深度学习相结合可以在 CCT 任务中获得更多的收获。出于我们的目的(表明 IR 方法构成了一个合理的基线) ,我们使用了一个非常简单的、普通的、开箱即用的 Lucene IR 实现,它在许多情况下几乎实现了 SOTA 性能。
4 METHODS & FINDINGS
在接下来的部分中,我们将介绍我们的方法和结果。


4.1 Differences between CCT and WMT data


Zipf图是一种可视化文本数据偏度的有用方法,其中(在自然文本中)一些标记(或ngrams)占了文本的很大一部分。每个绘图点都是一对(秩,相对频率),都是对数比例的。我们使用这个图来比较CCT数据中的(英文)评论数据和WMT NLT数据中期望的英文输出数据的相对偏度。检查上面的unigram Zipf图,可以在代码注释和自然英语中看到,一些词汇确实占主导地位。
图2是单词的频率分布:
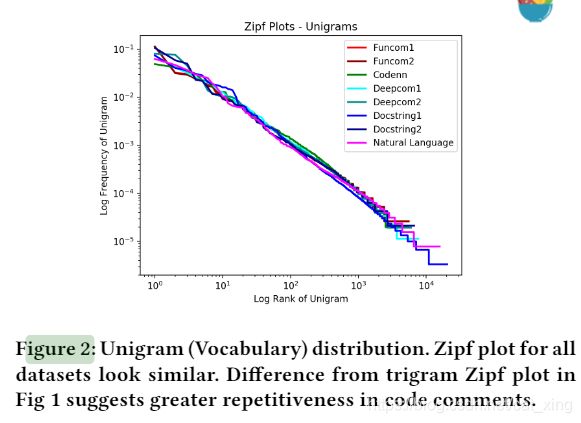
与图1对比:
然而,当我们回过头来看图1中的三元 Zipf 图时,我们可以看到其中的差异。一个明确的建议是: 虽然不同数据集之间的词汇分布没有那么大的差异,但是这些词汇组合成语法的方式在代码注释中更具风格和模板化

图2是三元组的频率分布:
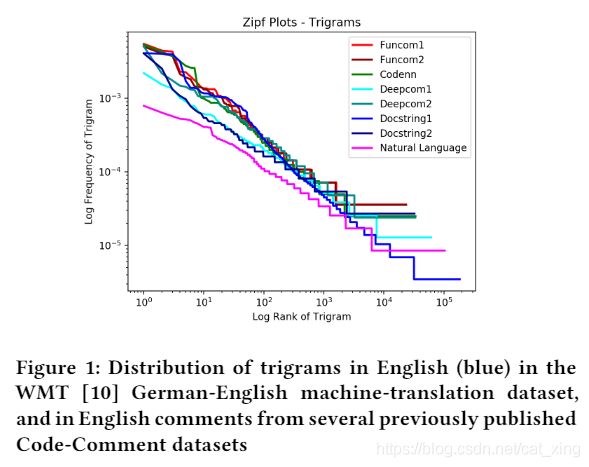

结论1:代码注释的重复性远远大于自然语言翻译数据集中的句子。
如果一个语料库中的大部分期望输出都是由几个频繁词组组成的,那么这些词组似乎在衡量表现时扮演了一个实质性的、或许是误导性的角色。图3支持这种分析。右边的图显示了在不同数据集中的“黄金”(期望的)输出中用随机标记替换单个单词(unigrams)对BLEU-4的影响。左边的图显示了替换三元组合的效果。x轴上的索引(1到100)显示了被随机标记替换的最频繁的n-gram的数量。y轴显示随着代码越来越随机化,测量的BLEU-4的减少。Unigrams图表明,与大多数评论数据集相比,BLEU对期望的自然语言(“nl”)输出的影响相对更大。这种效应在三元图中是相反的;“nl”数据集不像注释数据集那样受到频繁的Trigrams的移除的影响。
图3:用随机单词/三元组替换原数据集中的单词/三元组,各个数据集的BLEU值变化【?bleu怎么算】

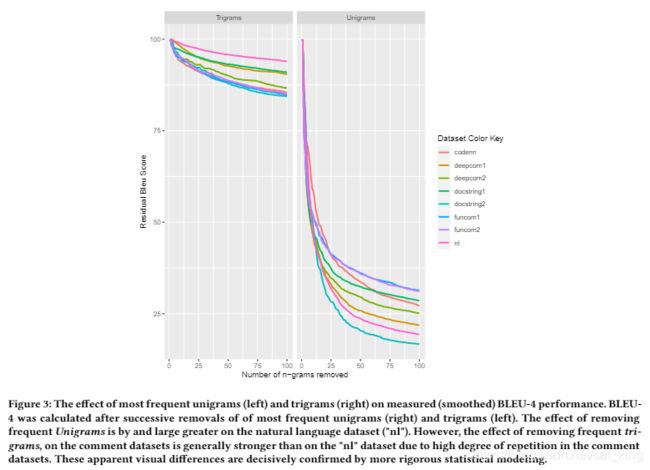

(查阅补充材料)


对代码注释 BLEU 有很大影响的频繁的三元组包括: “ factory method for”、“ delegate to the”和“ method for instanating”。换句话说,为了提高代码注释翻译工具的性能,我们可能会鼓励模型去准确预测类似的三元组,但这可能是误导性的。
结论2:与自然语言翻译相比,频繁的 n-gram 对 BLEU 在代码注释翻译任务中的表现有更强的影响。
4.2 Input-Output Similarity (RQ3)
两个语法结构和词汇相似的德语句子一般会导致两个语法结构和词汇相似的英语句子;同样,一般来说,两个德语句子在词汇和语法上的差异越大,我们期望它们的英译差异越大。

当使用高维非线性函数逼近器(如使用深度学习的编码器-解码器模型)来训练翻译引擎时,这种单调依赖性质可以说是有用的。我们希望将相似的输入句子编码到向量空间的相似点中,从而产生更多相似的输出句子。
自然语言翻译(德语-英语)和代码注释数据集在这方面表现如何?为了衡量这一点,我们从每个数据集中随机抽取了10000对输入片段,并用BLEU-M2测量了它们的相似性,以及相应的黄金(期望的)输出片段的相似性。然后,我们在x轴上绘制每个采样对的输入BLEU-M2相似性,在y轴上绘制相应输出对的BLEU-M2相似性。我们使用核平滑的2-d直方图,而不是散点图,以使频率更明显,以及(我们期望)表明类似的输入产生类似的输出。


![]()

【?】

从表(最后一列)中我们可以看到,根据数据集的不同,大约25-96% 的配对在输入和输出上都有一些相似性。


在自然语言环境中,我们可以清楚地看到输入和输出 bleu 之间更强的关系。特别是对于自然语言数据,这进一步证明了相当高的相关性为非零 BLEU 对(0.70!)在自然语言翻译中,输入输入相似性和输出输出相似性之间存在着明显的视觉依赖关系,这说明自然语言翻译中存在着强烈的、公平的单调关系: 源语越相似,译文越相似
这也表明语言之间的翻译更容易被像深度学习者这样的可学习函数逼近者所接受;对于代码注释数据,这似乎不太正确。

与 CCT 数据集相比,自然语言翻译(WMT)具有更强的输入输出依赖性,因为相似的输入更有可能产生相似的输出。
4.3 Information Retrieval Baselines
如图4和表2所示,自然语言翻译任务的数据集表现出更平滑和更单调的输入输出依赖性; 相比之下,代码注释数据集似乎很少或没有输入输出依赖性。这个发现使人们对是否存在一个通用的序列到序列的代码→注释函数产生了怀疑,这个函数可以通过一个通用的函数来学习,就像一个深层的神经网络。
然而,它也留下了一种可能性,即一种更受数据驱动的方法,即简单地以某种方式记忆训练数据,而不是试图从这些数据中归纳出来,也可能行得通。因此,给定一个代码输入,也许我们可以尝试在训练数据集中找到类似的代码,并检索与类似代码相关联的注释。这是一种简单朴素的信息检索(IR)方法。然后我们将其与NL翻译的IR性能进行比较。




4.3.1 Method.

我们使用 Apache Solr Version 8.3.113来实现一种简单的 IR 方法。Apache Solr 是一个基于 Apache Lucene 的开源文档搜索引擎。我们简单地构造相关数据集的代码部分的索引; 给定一个代码输入,我们使用它作为对索引的“查询”,找到最接近的匹配,并返回与最接近匹配代码相关的注释作为“生成的注释
4.3.2 IR Results.
我们发现在大多数数据集上,简单的IR基线接近神经模型,并且超过了DeepCom1、DocString1和DocString2。然而,IR在WMT翻译数据集和CodeNN上都做得很差。我们推测这可能反映了这些数据集的相对冗余水平。CodeNN来自StackOverflow,它往往有更少的重复问题;在手工管理的WMT中,我们预计会有更少的重复。



一个非常简单的IR方法做得很好,在某些情况下比最近发布的数据集/数据集变体的方法更好,这些数据集/数据集变体目前缺乏IR基线。因此,我们将红外基线视为模型性能的重要校准;通过尝试这样一个简单的基线,首先可以帮助在模型或数据集中找到需要进一步探索的病理学。
2.

我们也注意到有变异的结果。在包含10个交叉投影褶皱的 DeepCom2f 中,我们观察到了20.6ー48.4的 BLEU-DC 范围广泛的结果!这种跨折叠的变化水平值得关注… … 这表明,根据这个模型,一个有较高记忆训练数据能力的模型可能做得更好或更差,如果只做一个分裂,可能会混淆结果。

推荐: 由于在许多 CCT 数据集中,即使是初级的 IR 方法也能提供较好的性能,因此它们可以成为检查新集合和新处理 CCT 数据集中的问题的重要组成部分
4.4 Calibrating BLEU Scores
为了校准这些已报道的 BLEU 评分,我们进行了一项观察性研究,使用亲和群(AGs)的方法建模不同水平的预期相似性之间的方法。例如,考虑一个随机的方法对,使得这对方法的两个元素都是来自不同项目的方法。这是我们最亲密的群体; 我们期望注释有很少的共同点,除了都是描述代码的话语。下一个更高的亲和性组是来自同一项目的随机方法对。我们希望它们有一点相似,因为它们都涉及相同的应用程序域或函数。更高一级的方法是同一个类中的方法,虽然它们描述的是不同的函数,但它们可能更接近。通过从这些亲和群中随机抽取大量的配对,并测量每组配对的BLEU,可以得到每组配对的BLEU估计数。





2.
我们从 Github 上挑选了1000个最大的项目,然后从每个亲和类群中随机选择5000对。对于每一对,我们随机选择一个作为“参考”输出,另一个作为“候选”输出,以及 BLEU-M2分数。我们用两种不同的方式报告结果,如图5和表3所示。在类内,我们从一个单一的类中不会随机抽取超过六对。在所有的 AGs 中,除了一个之外,我们删除了所有的过载方法,以及在分析之前所有的 getter 和 setter。如果没有这个过滤,我们可以看到大约1-3点的差异

![]()

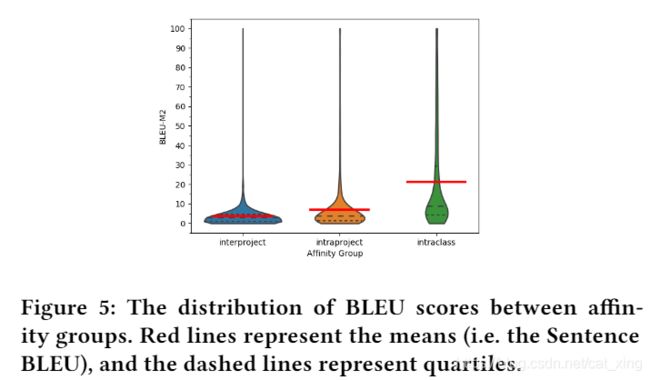
正如预期的那样,项目间平均值显示出相当低的平均值,约为3。项目内平均值高出了2个百分点。最值得注意的是,类内AG有一个大约22左右的BLEUscore,这接近于先前工作中报告的一些(但不是所有)数据集的同类最佳值


另一个更强大的亲和力分组是语义等价的方法。我们没有亲自尝试识别这样一个依赖性组(这可能会受到确认偏差的影响),而是从最近的一个项目SimilarAPI15by Chen[13]中选择了匹配的API调用,该项目使用机器学习方法来匹配不同但等效的API(例如Junitvs.testNG)中的方法。我们从不同的api中提取了40对匹配的高分匹配的描述,并计算了它们的BLEU。我们发现这些BLEU分数平均高出8分左右,平均值在32分左右。然而,这个数字应该慎重考虑,因为这个AG样本中的评论比其他组中的评论要短得多


推荐: 测试亲和群组可以为校准 CCT 数据集上的 BLEU 结果提供一个简单的方法,就像简单地通过检索同一类中随机其他方法的注释来生成注释一样,可以接近 SOTA 技术
Postscript
校准另一个 BLEU 的变化,通过不同的方式计算 BLEU。我们从组内样本中取出5000对样本,利用文献中使用的 BLEU 语法变异对这些句子进行 BLEU 测量。结果见表3。数值范围从21.2到24.8不等; 这个范围实际上相当高,与最近发表的论文报告的增益相比。这一发现澄清了对绩效进行标准化衡量的必要性



5 DISCUSSION
1.数据集中的注释比 WMT 数据集中的英语注释重复性要高得多;这些发现表明,仅仅正确地获得一些常见的评论模式可能会欺骗性地影响测量的绩效。因此,评论生成的实际性能可能与测量值有很大的偏差,相对于自然语言翻译来说更是如此。评论中的重复也可能意味着填空式方法[49]可能会被重新使用,以更多的数据驱动方法;首先对代码进行分类,找到正确的模板,然后再进行填空,或许可以使用一种注意或复制机制


2.当从一种语言翻译到另一种语言时,人们会期望更多相似的输入产生更多相似的输出,而这种依赖性是相对平滑和单调的。我们在图4和表1中的发现表明,对于一般的自然语言输出来说,这个属性确实非常正确,但是对于注释来说就不那么正确了。
深度学习模型是通用的高维连续函数逼近器。显示出平滑输出依赖关系的函数,可以合理地期望更容易建模。BLEU是词汇(标记序列)相似性的一种度量);图4和表1所建议的依赖性的非功能性本质表明,在自然语言翻译中工作良好的标记序列模型可能在代码中性能较差;可能其他的、非顺序的代码模型,如基于asttree的或基于图的,值得进一步探索

简单的 IR ap-proach 提供的 BLEU 性能可以与当前最先进的技术水平相媲美。研究结果表明,一个简单的、标准的、基本的 ireppach 将是处理 CCT 任务的一个有用的基准。特别是考虑到不同 BLEU 和标记化方法的范围,这将是一个有用的稻草人基线
4.以往论文所报告的 BLEU 分数并没有看起来那么高
目前报道的德语-英语翻译任务中 BLEU 得分最高的是40分左右。我们的亲和小组校准表明,在一些数据集上,模型的性能平均相当于从同一个类中检索一个随机方法的评论。虽然这个结论不能在没有使用特定数据集的精确例子和处理的情况下直接得出,但是在亲和类群水平上的比较结果可以为新的 CCT 数据集提供最小/预期数字的洞察力

5.我们发现,目前 CCT 数据集的景观是相当混乱的。同一个数据集通常有几个不同版本的预处理、分割和计算函数,这些在名称上似乎都是等价的,但是没有额外的注意,可能不具有可比性。然而,NLP 中的一些任务似乎并没有观察到任务中的这种变化。
有更广泛的工具来加强各种NLP任务的一致性。例如在WMT翻译会议上,一场竞赛是用公开的数据和人工评估进行的。其他任务,如用于阅读理解的SQuAD[45]和用于多任务评估的GLUE[55],允许将代码上传到服务器,该服务器在保留的数据上运行所建议的模型。这确保了评估指标和数据的一致性

6 THREATS TO VALIDITY




7 CONCLUSION



Our work suggeststhat future work in the area would benefit from
a) other kinds oftranslation models besides sequence-to-sequence encoder-decordermodels
b) more standardized measurement of performance and
c)baselining against Information Retrieval, and against some verycoarse foils (like retrieving a comment from a random other methodin the same class)
启示:
1.dataset需要去掉getter,setter。
2.是不是以后要按这个标准做实验?
3.使用图神经网络训练CFG?
4.IR做为一个baseline?
5.BLEU用哪个?