<数据结构>刷题笔记——链表篇进阶(图文详解)
文章目录
- 1. 环形链表
-
- 【思路】
- 【扩展问题】
- 【参考代码】
- 【链接】
- 2. 环形链表 II
-
- 【思路】
- 【思路二】
- 【参考代码】
- 【链接】
- 3. 复制带随机指针的链表
-
- 【思路】
- 【参考代码】
- 【链接】
目前在不断更新<数据结构>的知识总结
该系列相关文章:
<数据结构>刷题笔记——链表篇(一)
<数据结构>刷题笔记——链表篇(二)
已完结系列:
c语言自学教程——博文总结
我的gitee:gitee网址
期待系统学习编程的小伙伴可以关注我,不迷路!
1. 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
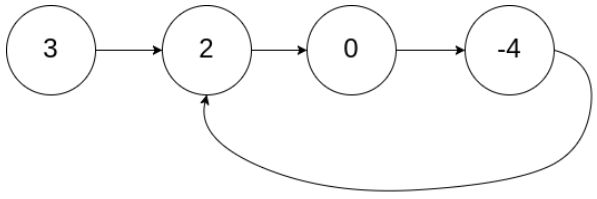
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
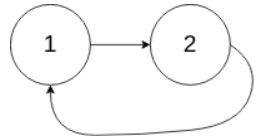
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。

提示:
链表中节点的数目范围是 [0, 104]
-105 <= Node.val <= 105
pos 为 -1 或者链表中的一个 有效索引 。
【思路】
快慢指针,即慢指针一次走一步,快指针一次走两步,两个指针从链表其实位置开始运行,如果链表带环则一定会在环中相遇,否则快指针率先走到链表的末尾。
为什么快指针每次走两步,慢指针走一步可以?
假设链表带环,两个指针最后都会进入环,快指针先进环,慢指针后进环。当慢指针刚进环时,可能就和快指针相遇了,最差情况下两个指针之间的距离刚好就是环的长度。
此时,两个指针每移动一次,之间的距离就缩小一步,不会出现每次刚好是套圈的情况,因此:在满指针走到一圈之前,快指针肯定是可以追上慢指针的,即相遇。(这里的套圈指的是越过,错过)

【扩展问题】
快指针一次走3步,走4步,…n步行吗?
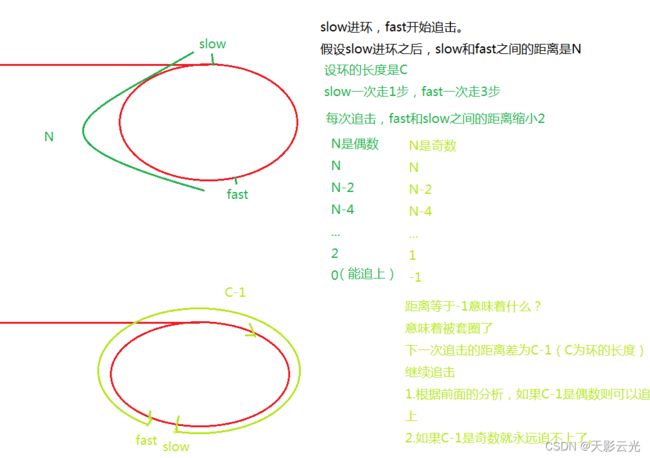
慢指针一次走1步,快指针一次走4步,也就是它们的速度差为3的情况更加复杂了,可能第一圈的时候被套圈,第n圈的时候刚好追上呢。其它情况感兴趣的自己研究研究,我在这里就不细说了。
【参考代码】
bool hasCycle(struct ListNode *head) {
struct ListNode* fast,*slow;
fast = slow = head;
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
if(fast == slow)
return true;
}
return false;
}
【链接】
力扣141. 环形链表
2. 环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
提示:
链表中节点的数目范围在范围 [0, 104] 内
-105 <= Node.val <= 105
pos 的值为 -1 或者链表中的一个有效索引
【思路】
这道题跟上一道题的不同点在于它要求找到入环的第一个节点。想达成这个目的,我们得好好分析分析。
让一个指针从链表起始位置开始遍历链表,同时让一个指针从判环时相遇点的位置开始绕环运行,两个指针都是每次均走一步,最终肯定会在入口点的位置相遇。
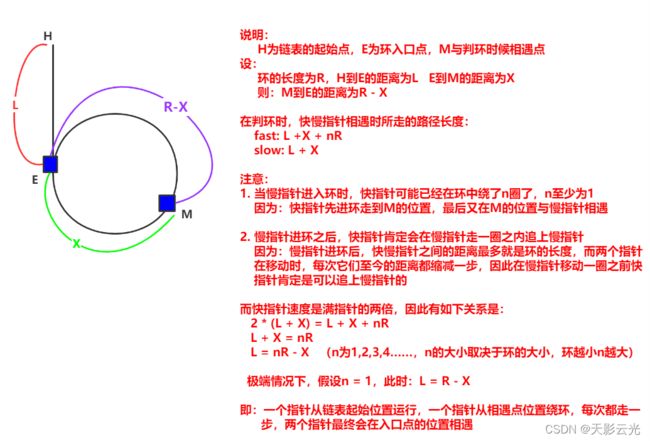
这是一道数学证明题,很巧妙也很难想到
【思路二】
其实还有另一种思路:把环剪开,它就会变成力扣160. 相交链表这道题,这题我上一篇讲解过,感兴趣可以去看看。
代码的思路是第一个巧妙的方法。
【参考代码】
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode* fast,*slow, *meet, *start;
start = fast = slow = head;
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
if(fast == slow)
{
meet = fast;
while(start != meet)
{
start = start->next;
meet = meet->next;
}
return start;
}
}
return NULL;
}
【链接】
力扣142. 环形链表 II
3. 复制带随机指针的链表
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]

示例 3:
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
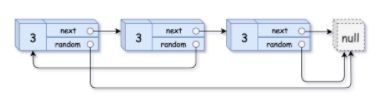
提示:
0 <= n <= 1000
-104 <= Node.val <= 104
Node.random 为 null 或指向链表中的节点。
【思路】
一开始我就想,直接创造新链表,把val和next复制好,在解决random的问题。但之后发现random实在太难找了,我得一个个遍历来找random。
然后让我们不乏换一个思路,这个思路的根本思想就是 “顺藤摸瓜”。
首先把复制的节点跟到原节点的后面
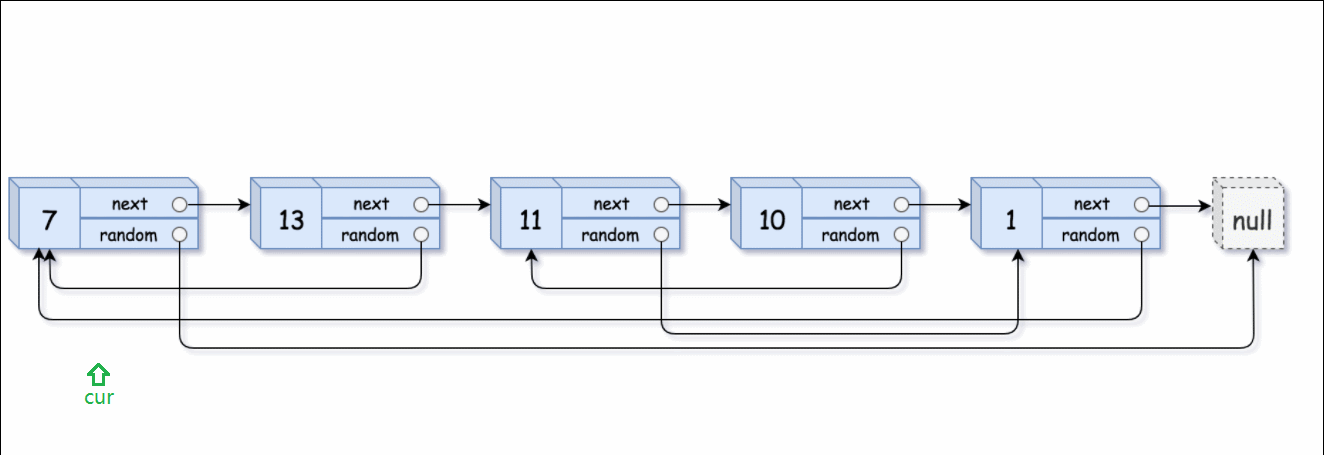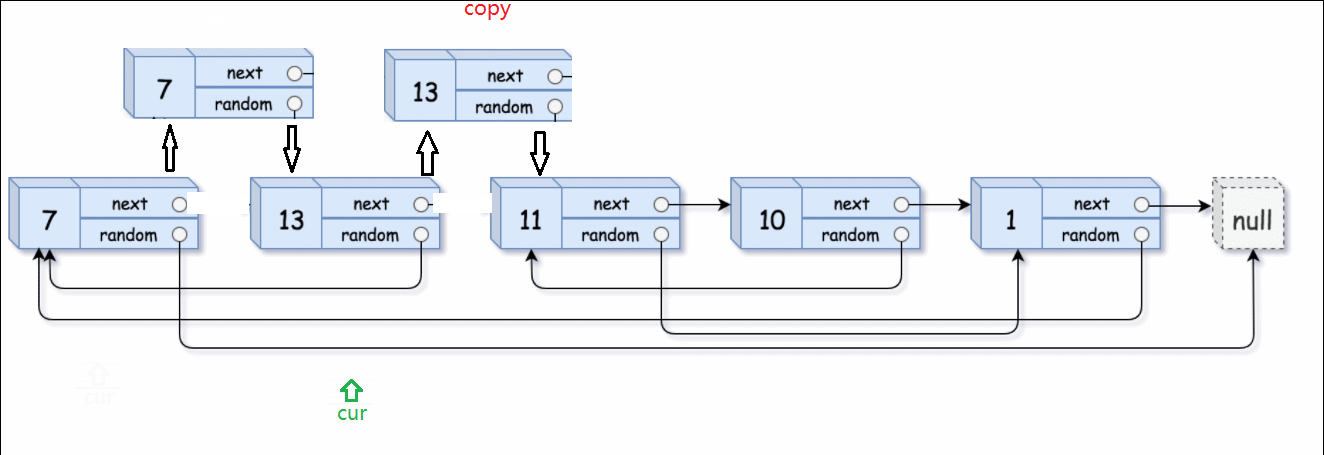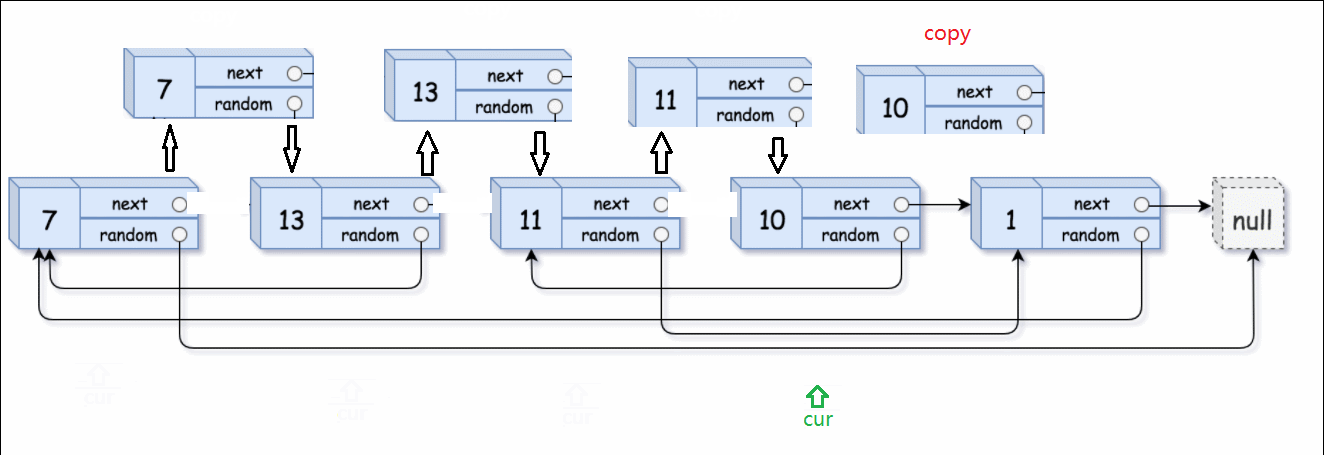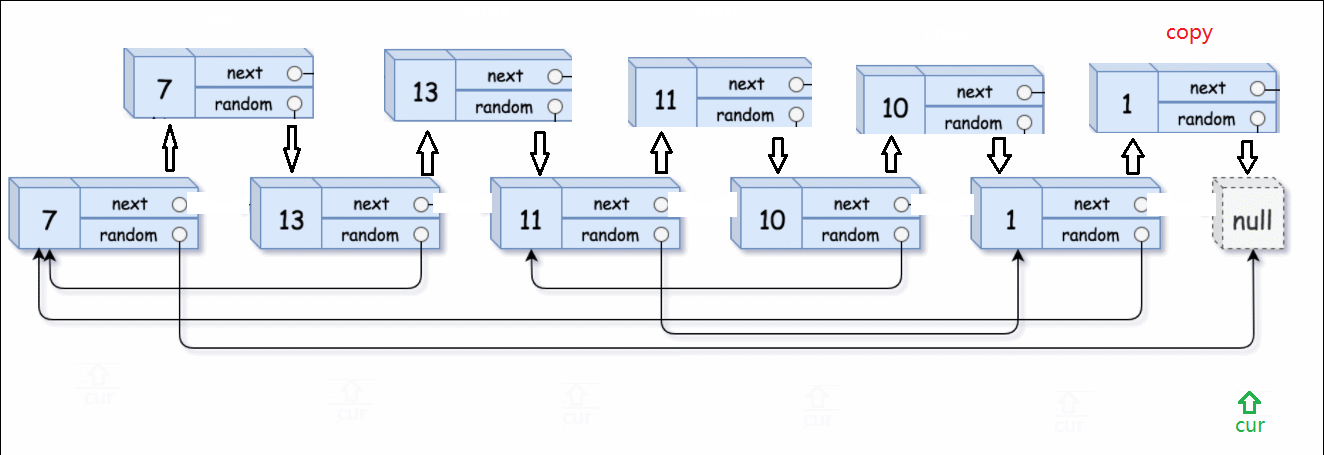
然后借助原链表找到random,random的下一个就是我们要找的复制链表的random。
举个例子:13的random是指向7的指针。原链表13->random的next,就是上一个步骤里插入的copy链表中13要找的random。这一点很重要,顺藤摸瓜就是顺着原链表的藤,摸到copy链表的瓜。
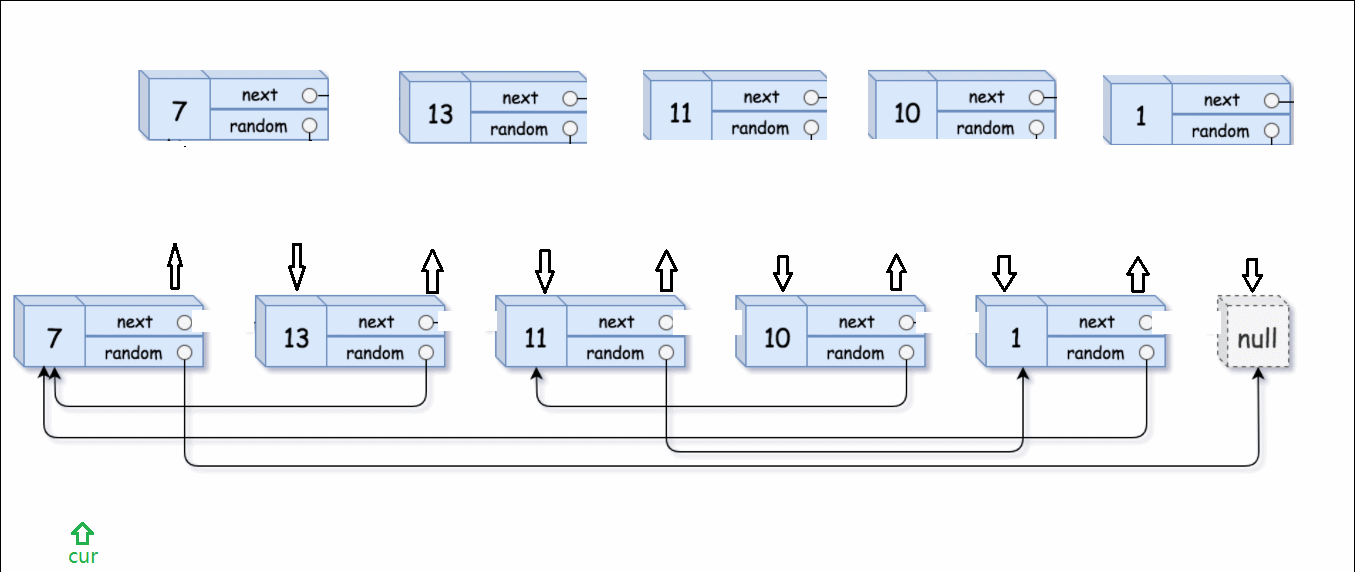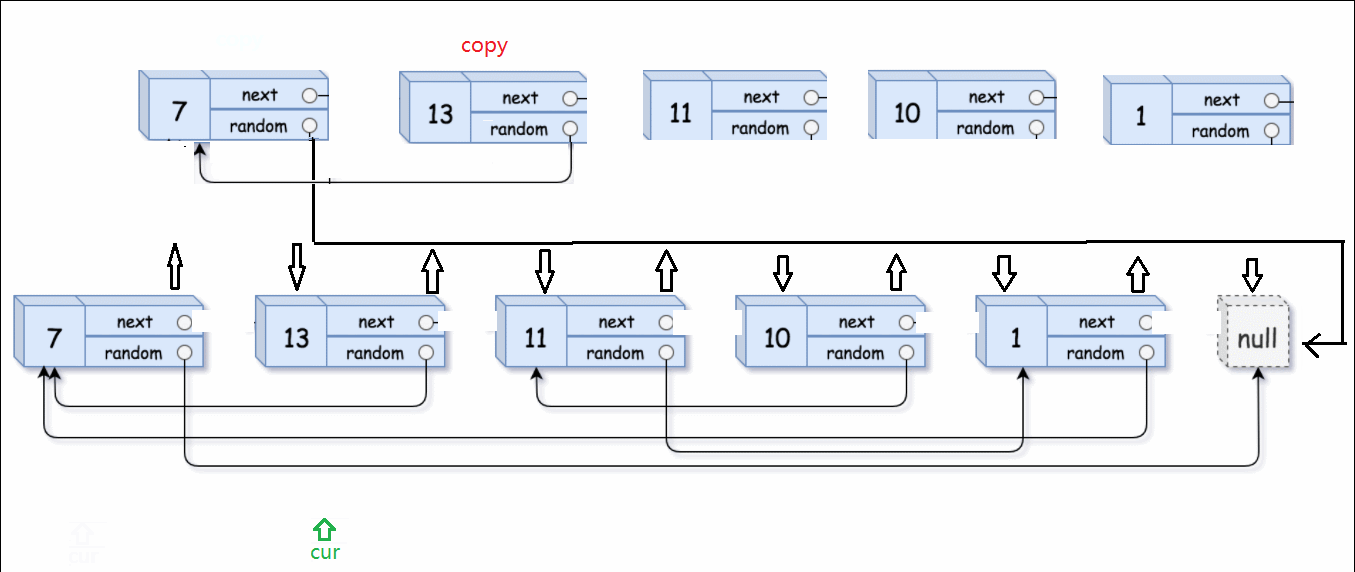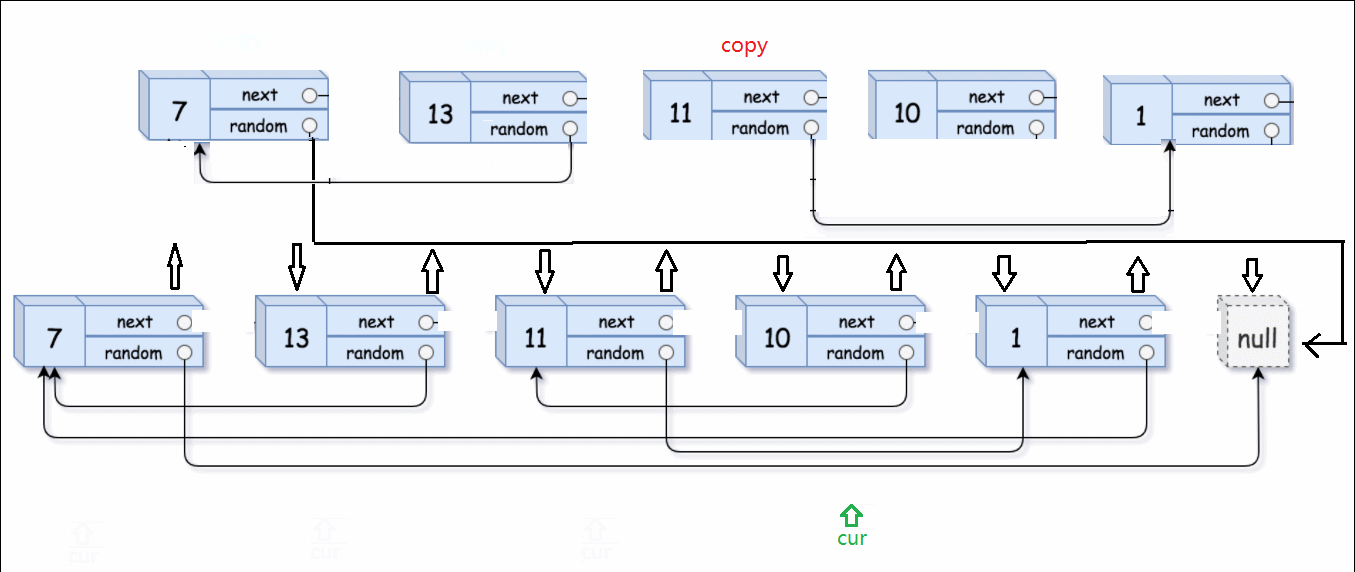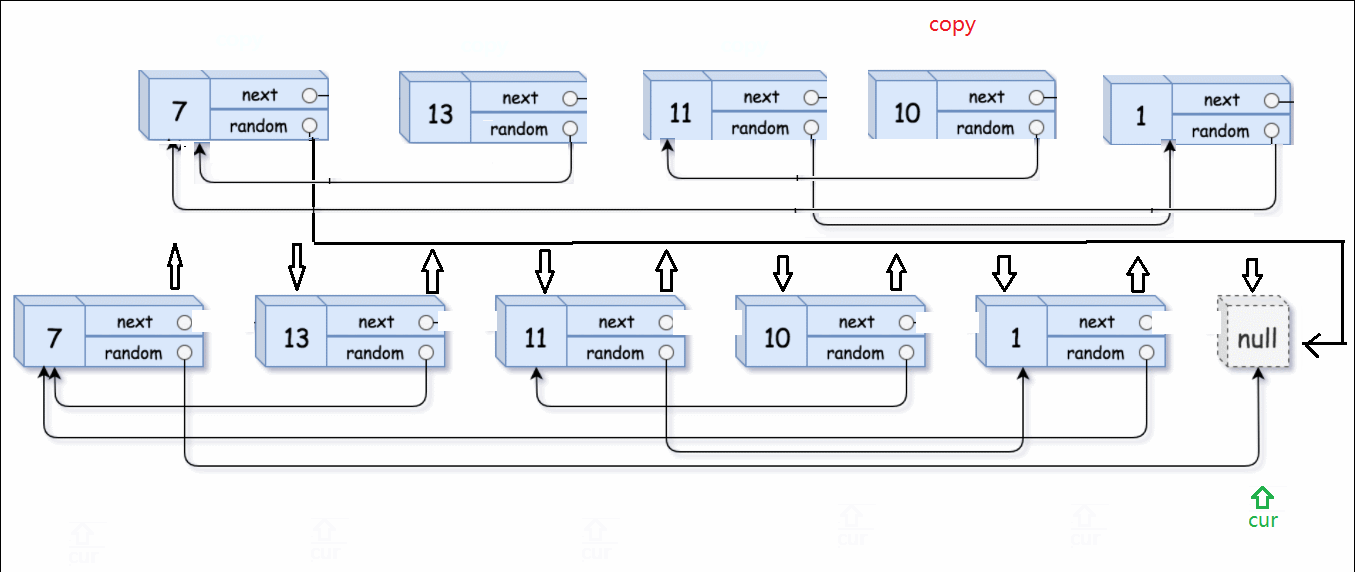
最后就要剪切拆分两个链表,并恢复原链表。

【参考代码】
struct Node* copyRandomList(struct Node* head) {
//把新链表跟到原链表的后面
struct Node* cur = head;
while(cur)
{
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val = cur->val;
copy->next = cur->next;
cur->next = copy;
cur = cur->next->next;
}
//寻找,复制random指针
cur = head;
while(cur)
{
struct Node* copy = cur->next;
if(cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;
}
cur = cur->next->next;
}
//剪切拆分两个链表,并恢复原链表
cur = head;
struct Node* copyHead = NULL,* copyTail = NULL;
while(cur)
{
struct Node* copy = cur->next, *next = copy->next;
cur->next = next;//恢复原链表
if(copyTail == NULL)
{
copyHead = copy;
copyTail = copyHead;
}
else
{
copyTail->next = copy;
copyTail = copyTail->next;
}
cur = next;
}
return copyHead;
}
【链接】
力扣138. 复制带随机指针的链表
看完这么多是不是很蒙,成功不是一蹴而就的,慢慢跟着练习不断进步最终也能到达你想到达到高度。加油!