SAX方式实现Excel导入
SAX解析Excel
上篇讲到了DOM解析Excel , 这篇记录工作中用到的SAX方式解析Excel的封装实现,
说明: 以下代码基于poi-3.17版本实现, poi-3.17及以上版本相比3.17以下版本样式设置的api改动比较大, 可能存在数据类型获取api过时或报错等, 请参考 Poi版本升级优化
1. 读取Excel公共方法
com.poi.util.PoiUtil#readExcel
/**
* 上传excel文件到服务器后,从服务器获取上传的文件并解析文件的数据
*
* @param parseType 解析类型 DOM SAX
* @param fileName 要解析的excel文件路径
* @param rowReader 扩展接口,方便对解析的每行数据做处理
* @return 返回解析的数据
* @throws Exception
*/
public static List<List<String>> readExcel(String parseType, String fileName, ExcelRowReader rowReader) throws Exception {
PoiUtil.validatorExcel(fileName);
List<List<String>> rowsDataList = new ArrayList<List<String>>();
int totalRows = 0;// 总行数
if (CSISCONSTANT.EXCEL_PARSE_DOM.equals(parseType)) { // DOM解析
ExcelReaderOfDom excelDom = new ExcelReaderOfDom();
rowsDataList = excelDom.readExcelByDom(fileName);
} else if (CSISCONSTANT.EXCEL_PARSE_SAX.equals(parseType)) {
// SAX解析 2003版 excel
if (fileName.endsWith(CSISCONSTANT.EXCEL03_EXTENSION)) {
ExcelXlsReaderOfSax excelXls = new ExcelXlsReaderOfSax();
excelXls.setRowReader(rowReader);
totalRows = excelXls.process(fileName);
rowsDataList = excelXls.getRowsData();
} else if (fileName.endsWith(CSISCONSTANT.EXCEL07_EXTENSION)) {
// SAX解析 2007版 excel
ExcelXlsxReaderOfSax excelXlsx = new ExcelXlsxReaderOfSax();
excelXlsx.setRowReader(rowReader);
totalRows = excelXlsx.process(fileName);
rowsDataList = excelXlsx.getRowsData();
}
}
totalRows = rowsDataList.size();
logger.info(">>>>总行数: {}", totalRows);
return rowsDataList;
}
2. 校验Excel文件格式
com.poi.util.PoiUtil#validatorExcel
/**
* 校验excel文件格式
* @param fileName
* @return
* @throws MyException
*/
public static boolean validatorExcel(String fileName) throws MyException {
if (StringUtils.isEmpty(fileName)) {
throw new MyException(CSISERRORCODE.FILE_PATH_IS_NULL_ERROR_CODE,
CSISERRORCODE.FILE_PATH_IS_NULL_ERROR_INFO);
}
if (!(isExcel2003(fileName) || isExcel2007(fileName))) {
throw new MyException(CSISERRORCODE.UPLOAD_EXCEL_EXTENSION_ERROR_CODE,
CSISERRORCODE.UPLOAD_EXCEL_EXTENSION_ERROR_INFO);
}
File file = new File(fileName);
if (file == null || !file.exists()) {
throw new MyException(CSISERRORCODE.FILE_NOT_EXIST_ERROR_CODE,
CSISERRORCODE.FILE_NOT_EXIST_ERROR_INFO);
}
return true;
}
3. 解析Excel的委托接口
委托接口 com.poi.service.ExcelRowReader
package com.poi.service;
import java.util.List;
/**
* 读取excel文件的委托接口
* @author wang_qz
*
*/
public interface ExcelRowReader {
/**
* 读取每一行记录
* totalRows=curRow
* @param sheetIndex 当前sheet页索引
* @param totalRows 解析的行记录总数
* @param curRow 当前行
* @param rowList 当前行的数据记录
*/
void readExcelData(int sheetIndex, int totalRows, int curRow,
List<String> rowList);
}
委托接口实现类 com.poi.service.ExcelReaderImpl
package com.poi.service;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
/**
* 读取excel文件的委托接口实现类
* @author wang_qz
*
*/
public class ExcelReaderImpl implements ExcelRowReader {
private static Logger logger = LoggerFactory.getLogger(ExcelReaderImpl.class);
@Override
public void readExcelData(int sheetIndex, int totalRows, int curRow,
List<String> rowList) {
// 因为解析的行记录是从索引0开始计数,我们习惯从1开始计数,所以打印的结果进行+1处理
logger.info("解析第" + sheetIndex + "个sheet页的第" + curRow + "行,
已解析总行数:" + totalRows + ", 当前行数据:" + rowList);
}
}
4. 2003版SAX解析
com.poi.service.ExcelXlsReaderOfSax
package com.poi.service;
import org.apache.poi.hssf.eventusermodel.EventWorkbookBuilder.
SheetRecordCollectingListener;
import org.apache.poi.hssf.eventusermodel.*;
import org.apache.poi.hssf.eventusermodel.dummyrecord.LastCellOfRowDummyRecord;
import org.apache.poi.hssf.eventusermodel.dummyrecord.MissingCellDummyRecord;
import org.apache.poi.hssf.model.HSSFFormulaParser;
import org.apache.poi.hssf.record.*;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.poifs.filesystem.POIFSFileSystem;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* sax解析2003版本的excel文件 xls
* 空行没用自动过滤掉,以后有时间再研究
* @author wang_qz
*/
public class ExcelXlsReaderOfSax implements HSSFListener {
private static Logger logger =
LoggerFactory.getLogger(ExcelXlsReaderOfSax.class);
private int minColumns = -1;
/**
* 解析excel的文件系统api
*/
private POIFSFileSystem fs;
/**
* 上一行
*/
private int lastRowNumber;
/**
* 上一列(单元格)
*/
private int lastColumnNumber;
/**
* should we ouput the formula(公式), or the value it has?
* true 输出公式的值
* false 输出公式
*/
private boolean outputFormulaValue = true;
/**
* 监听器
*/
private SheetRecordCollectingListener workbookBuildingListener;
/**
* excel2003工作簿
*/
private HSSFWorkbook stubWorkbook;
private SSTRecord sstRecord;
/**
* 监听器
*/
private FormatTrackingHSSFListener formatListener;
/**
* 表索引
*/
private int sheetIndex = -1;
/**
* 存放sheet页的record容器
*/
private BoundSheetRecord[] orderedBSRs;
@SuppressWarnings("unchecked")
private ArrayList boundSheetRecords = new ArrayList();
/**
* 下一行
*/
private int nextRow;
/**
* 下一列-单元格
*/
private int nextColumn;
/**
* 输出下一个字符串记录
*/
private boolean outputNextStringRecord;
/**
* 记录解析的当前行
*/
private int curRow = 0;
/**
* 记录当前解析的总行数
*/
private int totalRows = 0;
/**
* 存储当前行记录的容器
*/
private List<String> rowList = new ArrayList<String>();
/**
* 存储每行记录的数据集合
*/
private List<List<String>> dataList = new ArrayList<List<String>>();
private List<String> temList = null;
/**
* 是否允许空行记录
*/
private boolean allowNullRow = true;
/**
* sheet表名称
*/
private String sheetName;
/**
* 委托读取excel数据的接口对象
*/
private ExcelRowReader rowReader;
public void setRowReader(ExcelRowReader rowReader) {
this.rowReader = rowReader;
}
public ExcelRowReader getRowReader() {
return this.rowReader;
}
/**
* 获取读取的excel数据
*
* @return
*/
public List<List<String>> getRowsData() {
return this.dataList;
}
/**
* 遍历excel下的所有sheet表
*
* @param filePath 要解析的excel文件路径
* @return 返回解析的总记录行数,包含标题行
* @throws IOException
*/
public int process(String filePath) throws IOException {
this.fs = new POIFSFileSystem(new FileInputStream(filePath));
MissingRecordAwareHSSFListener listener = new
MissingRecordAwareHSSFListener(this);
formatListener = new FormatTrackingHSSFListener(listener);
HSSFEventFactory factory = new HSSFEventFactory();
HSSFRequest request = new HSSFRequest();
// 添加监听事件
if (outputFormulaValue) {
request.addListenerForAllRecords(formatListener);
} else {
workbookBuildingListener = new
SheetRecordCollectingListener(formatListener);
request.addListenerForAllRecords(workbookBuildingListener);
}
factory.processWorkbookEvents(request, fs);
/**
* {@link ExcelXlsReaderOfSax#processRecord} 解析完成后,返回总行数
*/
return totalRows;
}
/**
* HSSFListener 监听方法, 处理Record
*/
@Override
public void processRecord(Record record) {
int thisRow = -1; // 当前行数
int thisColumn = -1; // 当前列数(单元格)
String thisStr = null; // 当前单元格的内容值
String value = null;
// 根据解析的当前行的记录类型,做不同方式的处理 (sax是一行一行解析)
switch (record.getSid()) {
case BoundSheetRecord.sid: // short 133
boundSheetRecords.add(record);
break;
case BOFRecord.sid: // short 2057
BOFRecord br = (BOFRecord) record;
if (br.getType() == BOFRecord.TYPE_WORKSHEET) {
// 如果有需要, 则建立工作簿
if (workbookBuildingListener != null && stubWorkbook == null) {
stubWorkbook =
workbookBuildingListener.getStubHSSFWorkbook();
}
sheetIndex++;
if (orderedBSRs == null) {
orderedBSRs =
BoundSheetRecord.orderByBofPosition(boundSheetRecords);
}
sheetName = orderedBSRs[sheetIndex].getSheetname();
}
break;
case SSTRecord.sid: // short 252
sstRecord = (SSTRecord) record;
break;
case BlankRecord.sid: // short 513 空行类型
BlankRecord brec = (BlankRecord) record;
thisRow = brec.getRow(); // 获取当前行
thisColumn = brec.getColumn(); // 获取当前列
thisStr = "";
// 填充当前行列(单元格)数据到数据记录容器集合中
rowList.add(thisColumn, thisStr);
break;
case BoolErrRecord.sid: // short 517 布尔类型
BoolErrRecord berec = (BoolErrRecord) record;
thisRow = berec.getRow();
thisColumn = berec.getColumn();
thisStr = String.valueOf(berec.getBooleanValue()); // 布尔值
rowList.add(thisColumn, thisStr);
break;
case FormulaRecord.sid: // short 6 公式类型
FormulaRecord frec = (FormulaRecord) record;
thisRow = frec.getRow();
thisColumn = frec.getColumn();
if (outputFormulaValue) {
// 输出公式的值
if (Double.isNaN(frec.getValue())) { // 当前记录值不是数字
outputNextStringRecord = true; // 输出下一个字符串记录
nextRow = frec.getRow();
nextColumn = frec.getColumn();
} else {
thisStr = formatListener.formatNumberDateCell(frec);
}
} else {
// 解析输出公式表达式
thisStr = '"' + HSSFFormulaParser.toFormulaString(stubWorkbook, frec.getParsedExpression());
}
rowList.add(thisColumn, thisStr);
break;
case StringRecord.sid: // short 519 字符串类型
if (outputNextStringRecord) {
StringRecord srec = (StringRecord) record;
thisStr = srec.getString();
thisRow = nextRow;
thisColumn = nextColumn;
outputNextStringRecord = false;
}
break;
case LabelRecord.sid: // short 516 标签类型
LabelRecord lrec = (LabelRecord) record;
curRow = thisRow = lrec.getRow();
thisColumn = lrec.getColumn();
value = lrec.getValue().trim();
value = "".equals(value) ? "" : value;
rowList.add(thisColumn, value);
break;
case LabelSSTRecord.sid: // short 253
LabelSSTRecord lsrec = (LabelSSTRecord) record;
curRow = thisRow = lsrec.getRow();
thisColumn = lsrec.getColumn();
if (sstRecord == null) {
rowList.add(thisColumn, "");
} else {
value =
sstRecord.getString(lsrec.getSSTIndex()).toString().trim();
value = "".equals(value) ? "" : value;
rowList.add(thisColumn, value);
}
break;
case NumberRecord.sid: // short 515 数字类型
NumberRecord numrec = (NumberRecord) record;
curRow = thisRow = numrec.getRow();
thisColumn = numrec.getColumn();
value = formatListener.formatNumberDateCell(numrec).trim();
value = "".equals(value) ? "" : value;
rowList.add(thisColumn, value);
break;
default:
break;
}
// 遇到新行的操作
if (thisRow != -1 && thisRow != lastRowNumber) {
lastColumnNumber = -1;
}
// 如果遇到空值的操作
if (record instanceof MissingCellDummyRecord) {
MissingCellDummyRecord mc = (MissingCellDummyRecord) record;
curRow = thisRow = mc.getRow();
thisColumn = mc.getColumn();
rowList.add(thisColumn, "");
}
// 更新行和列的值
if (thisRow > -1) {
lastRowNumber = thisRow;
}
if (thisColumn > -1) {
lastColumnNumber = thisColumn;
}
// 行结束时的操作
if (record instanceof LastCellOfRowDummyRecord) {
if (minColumns > 0) {
//列值重新置空
if (lastColumnNumber == -1) {
lastColumnNumber = 0;
}
}
// 每行结束时调用readExcelData()方法, 可以在该方法中对每行记录的数据进行操作
if (rowReader != null) {
rowReader.readExcelData(sheetIndex, totalRows, curRow, rowList);
}
// 将每一行记录的数据存入大集合中 因为解析完一行记录后会将rowList清空,
// 需要用中间集合变量存已经解析的数据, 再添加到大集合
if (curRow > 0) { // 0-第一行是标题行,不添加到集合中
temList = new ArrayList<String>();
temList.addAll(rowList);
dataList.add(temList);
}
// 清空容器
lastColumnNumber = -1;
rowList.clear(); // 清空容器会将已经存入的数据也清空掉
totalRows++; // 当前行解析完毕,监听解析下一行,row++
}
}
private boolean isWriteRow(List list) {
boolean flag = false; // 记录为空的标志 false 空 ; true 不为空
for (int i = 0; i < list.size(); i++) {
if (list.get(i) != null && !"".equals(list.get(i))) {
flag = true;
break;
}
}
if (allowNullRow) {
if (!flag) {
flag = true; // 允许为空
}
}
return flag;
}
}
5. 2007版SAX解析
com.poi.service.ExcelXlsxReaderOfSax
package com.poi.service;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.openxml4j.exceptions.OpenXML4JException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.ss.usermodel.BuiltinFormats;
import org.apache.poi.ss.usermodel.DataFormatter;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.model.StylesTable;
import org.apache.poi.xssf.usermodel.XSSFCellStyle;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.xml.sax.Attributes;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
/**
* sax事件驱动解析2007版本的excel文件 xlsx
* 继承{@link DefaultHandler},重写里面的三个方法 {@link DefaultHandler#startElement}、
* {@link DefaultHandler#characters}、 {@link DefaultHandler#endElement}
* sax解析执行顺序{@link ExcelXlsxReaderOfSax#startElement}、
* {@link ExcelXlsxReaderOfSax#characters}、 {@link ExcelXlsxReaderOfSax#endElement}
*
* SAX全称Simple API for XML,它是一种XML解析的替代方法,不同于DOM解析XML文档时把所有内容一次性
* 加载到内存中的方式,它逐行扫描文档,一边扫描,一边解析。
* 所以那些只需要单遍读取内容的应用程序就可以从SAX解析中受益,这对大型文档的解析是个巨大优势。
*
* 空行和空单元格的问题都已经解决
* @author wang_qz
*/
public class ExcelXlsxReaderOfSax extends DefaultHandler {
/**
* 共享字符串表
*/
private SharedStringsTable sst;
/**
* 上一次的内容或上一次的索引值
*/
private String lastContents;
/**
* excel文件的绝对路径
*/
private String filePath;
/**
* 字符串标识
*/
private boolean nextIsString;
/**
* sheet工作表索引
*/
private int sheetIndex = -1;
/**
* sheet表名
*/
private String sheetName = "";
/**
* 总行数
*/
private int totalRows = 0;
/**
* 行集合
*/
private List<String> rowList = new ArrayList<>();
/**
* 判断整行是否为空行的标记 flase 空行 ; true: 不是空行
*/
private boolean flag = false;
/**
* 当前行
*/
private int curRow = 0;
/**
* 当前列
*/
private int curCol = 0;
/**
* T元素标识
*/
private boolean isTElement;
/**
* 异常信息, 如果为空则表示没有异常
*/
private String exceptionMessage;
/**
* 单元格的数据可能出现的数据类型
*/
enum CellDataType {
BOOL, ERROR, INLINESTR, SSTINDEX, FORMULA, NUMBER, DATE, NULL
}
/**
* 单元格数据类型, 默认为字符串类型
*/
private CellDataType nextDataType = CellDataType.SSTINDEX;
/**
* 数据格式
*/
private final DataFormatter formatter = new DataFormatter();
/**
* 单元格日期格式的索引
*/
private short formatIndex;
/**
* 日期格式字符串
*/
private String formatString;
/**
* 定义前一个元素和当前元素的位置, 用来计算其中空的单元格数量, 如A6和A8等
*/
private String preRef = null, ref = null;
/**
* 定义该文档一行最大的单元格数, 用来补全一行最后可能缺失的单元格
*/
private String maxRef = null;
/**
* 单元格
*/
private StylesTable stylesTable;
/**
* 存储每行记录的数据集合
*/
private List<List<String>> dataList = new ArrayList<List<String>>();
private List<String> temList = null;
/**
* 委托读取excel数据的接口对象
*/
private ExcelRowReader rowReader;
public void setRowReader(ExcelRowReader rowReader) {
this.rowReader = rowReader;
}
public ExcelRowReader getRowReader() {
return this.rowReader;
}
/**
* 获取读取的excel数据
*
* @return
*/
public List<List<String>> getRowsData() {
return this.dataList;
}
/**
* 解析2007版本Excel的方法入口
* @param fileName 要解析的excel文件路径
* @return
* @throws IOException
* @throws OpenXML4JException
* @throws SAXException
*/
public int process(String fileName) throws IOException, OpenXML4JException,
SAXException {
this.filePath = fileName;
OPCPackage pkg = OPCPackage.open(fileName);
XSSFReader xssfReader = new XSSFReader(pkg);
stylesTable = xssfReader.getStylesTable(); // 获取单元格
// 获取共享字符串表
SharedStringsTable sst = xssfReader.getSharedStringsTable();
XMLReader parser = this.fetchSheetParser(sst);
// 两种方式都可以
// 得到所有的sheet表格
// Iterator sheets = xssfReader.getSheetsData();
// 得到所有的sheet表格
XSSFReader.SheetIterator sheets = (XSSFReader.SheetIterator)
xssfReader.getSheetsData();
while (sheets.hasNext()) {
curRow = 0;// 当前行索引从0开始, 标记初始为第一行
sheetIndex++; // sheet工作表索引 ++
InputStream sheetInputStream = sheets.next(); // 得到每一个sheet表的输入流对象
sheetName = sheets.getSheetName();
InputSource sheetSource = new InputSource(sheetInputStream);
//解析excel的每条记录,在这个过程中startElement()、characters()、endElement()
// 这三个函数会依次执行
parser.parse(sheetSource);
sheetInputStream.close();
}
return totalRows; // 返回excel文档的总行数
}
/**
* 获取XMLReader解析流对象
*
* @param sst
* @return
* @throws SAXException
*/
public XMLReader fetchSheetParser(SharedStringsTable sst) throws SAXException {
String arg0 = "org.apache.xerces.parsers.SAXParser";
XMLReader parser = XMLReaderFactory.createXMLReader(arg0);
this.sst = sst; // 共享字符串表
parser.setContentHandler(this);
return parser;
}
/**
* sax解析重写,第一个执行 , 解析一行的开始处理
* 因为底层不会解析空行和空单元格,会自动过滤掉;方法中的空单元格的问题被我解决了,心情爽啊;
// 空行的问题不用考虑
* @param uri
* @param localName
* @param qName 解析的标签
* @param attributes 解析的标签属性
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 获取总行号 格式A1:B5 取最后一个值即可
if ("dimension".equals(qName)) {
String demensionStr = attributes.getValue("ref");
// 这里放开会导致每次解析完的行数totalRows多加1
// totalRows = Integer.parseInt(demensionStr.substring(
// demensionStr.indexOf(":") + 2)) - 1;
}
// 行开始
if ("row".equals(qName)) {
}
// 列-单元格-c
if ("c".equals(qName)) { // cell
// 前一个单元格的位置 null表示是新的一行
if (preRef == null) {
preRef = attributes.getValue("r");
// 因为 attributes.getValue("r") 会自动过滤掉空单元格,所以如果第一列
// 是空单元格,那么取不到 A1/A2/A3..每行的第一列
if (!"A".equals(preRef.substring(0, 1))) {
// 第一列是空单元格,添加空字符串占位
rowList.add(curCol, "");
curCol++;
}
} else {
// preRef不为null, 表示当前行解析到第1+N列(不是第一列)
// 解析当前行的下一个单元格, 将刚刚在endElement解析完的单元格ref赋值给preRef,
// 变为上一个单元格
preRef = ref;
// 当前单元格的位置
// 如果中间没用空单元格 ref应该是preRef+1的位置
ref = attributes.getValue("r");
//与上一单元格相差2, 说明中间有空单元格 A2 B2 C2 如果B2为空单元格,
// 那么将A和C转换成char进行计算
int gap = ref.substring(0, 1).charAt(0) -
preRef.substring(0, 1).charAt(0);
if (gap > 1) {
gap -= 1; // 中间的空单元格数量
while (gap > 0) {
// 空单元格,添加空字符串占位
rowList.add(curCol, "");
curCol++;
gap--;
}
}
}
// 当前单元格的位置
ref = attributes.getValue("r");
// 设定单元格类型
this.setNextDataType(attributes);
// Figure out if the value is an index in the SST
String cellType = attributes.getValue("t");
if (cellType != null && cellType.equals("s")) {
nextIsString = true;// 字符串标识
} else {
nextIsString = false;
}
} else if ("t".equals(qName)) {
isTElement = true; // T元素标识
} else {
isTElement = false;
}
// 上一次的内容置空 clear contents cache
lastContents = "";
}
/**
* sax解析重写,第二个执行
* 得到单元格对应的索引值或内容值(解析的标签体内容)
* 如果单元格类型是字符串/INLINESTR/数字/日期, 则lastIndex是索引值
* 如果单元格类型是布尔值/错误/公式类型, 则lastIndex是内容值
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// 得到单元格内容的值
lastContents += new String(ch, start, length);
}
@Override
public void startPrefixMapping(String prefix, String uri) throws SAXException {
super.startPrefixMapping(prefix, uri);
}
/**
* sax解析重写,最后执行, 解析一行的结束处理
*
* @param uri
* @param localName
* @param qName 解析的标签
* @throws SAXException
* @see ExcelXlsxReaderOfSax#characters(char[], int, int)
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// 根据SST的索引值获取单元格真正想要存储的字符串
// 这时characters()方法可能会被调用多次
if (nextIsString && StringUtils.isNotEmpty(lastContents) &&
StringUtils.isNumeric(lastContents)) {
int idx = Integer.parseInt(lastContents);
// 单元格内容转换
lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString();
nextIsString = false;
}
/*if (!nextIsString && StringUtils.isEmpty(lastContents)) {
// 如果当前单元格为空,用空字符串占位
rowList.add(curCol, "");
curCol++;
nextIsString = false;
}*/
// t 元素也包含字符串
if (isTElement) {
//将单元格内容加入行集合 rowList中,在这之前先去掉字符串前后的空白字符
String value = lastContents.trim();
rowList.add(curCol, value); // 将当前列的值添加到当前单元格的位置
curCol++;
isTElement = false;
// 如果里面某个单元格含有值, 则标识该行不为空
if (value != null && !"".equals(value)) {
flag = true; // 该行不为空
}
}
if ("v".equals(qName)) {
// v-单元格的值, 如果单元格是字符串, 则v标签的值为该字符串在SST中的索引
String value = this.getDataValue(lastContents.trim(), "");
// 补齐单元格之间的空单元格 要注释掉,否则正常含内容的单元格之间也会添加很多空单元格
/*if (!ref.equals(preRef)) {
int len = countNullCell(ref, preRef);
for (int i = 0; i < len; i++) {
rowList.add(curCol, "");
curCol++;
}
}*/
rowList.add(curCol, value);
curCol++;
// 如果里面某个单元格含有值, 则标识该行不为空
if (value != null && !"".equals(value)) {
flag = true; // 该行不为空
}
} else {
// 行结束 如果标签名称为row, 这说明已经到达行尾,调用optRows()方法
if ("row".equals(qName)) {
// 默认第一行为表头, 以该行单元格数目为最大数目
if (curRow == 0) {
maxRef = ref; // 最大单元格数等于当前单元格数
}
// 补全一行尾部可能缺失的单元格 要注释掉,
// 否则正常含内容的单元格之间也会添加很多空单元格
/*if (maxRef != null) {
int len = countNullCell(maxRef, ref);
for (int i = 0; i <= len; i++) {
rowList.add(curCol, "");
curCol++;
}
}*/
// 每行记录解析完后可以调用readExcelData()方法对每行数据进行操作
rowReader.readExcelData(sheetIndex, totalRows, curRow, rowList);
// 将每一行记录的数据存入大集合中 因为解析完一行记录后会将rowList清空,
// 需要用中间集合变量存已经解析的数据, 再添加到大集合
if (flag && curRow > 0) { // 0-第一行是标题行
temList = new ArrayList<String>();
temList.addAll(rowList);
dataList.add(temList);
}
// 解析完每行记录后清空
rowList.clear();
curRow++;
curCol = 0;
preRef = null;
ref = null;
flag = false;
// 下一行
totalRows++;
}
}
}
/**
* 对解析出来的数据进行类型处理
*
* @param value 单元格的值(这时候是一串数字)
* value解析: BOOL的为0或1
* ERROR/FORMULA/NUMBER/DATE为内容值
* INLINESTR/SSTINDEX的为索引值需要转换为内容值
* @param thisStr 一个空字符串
* @return
*/
public String getDataValue(String value, String thisStr) {
switch (nextDataType) {
// 这几个顺序不能随便交换,交换了可能会导致数据错误
case BOOL: // 布尔值
char first = value.charAt(0);
thisStr = (first == '0' ? "FALSE" : "TRUE");
break;
case ERROR: // 错误
thisStr = "\"ERROR:" + value.toString() + '"';
break;
case FORMULA: // 公式
thisStr = '"' + value.toString() + '"';
break;
case INLINESTR:
XSSFRichTextString rtsi = new XSSFRichTextString(value.toString());
thisStr = rtsi.toString();
rtsi = null;
break;
case SSTINDEX: // 字符串
String sstIndex = value.toString();
try {
int idx = Integer.parseInt(sstIndex);
//根据idx索引值获取内容值
XSSFRichTextString rtss = new
XSSFRichTextString(sst.getEntryAt(idx));
thisStr = rtss.toString();
rtss = null;
} catch (NumberFormatException ex) {
thisStr = value.toString();
}
break;
case NUMBER: // 数字
if (formatString != null) {
thisStr = formatter.formatRawCellContents(
Double.parseDouble(value), formatIndex, formatString).trim();
} else {
thisStr = value;
}
thisStr = thisStr.replace("_", "").trim();
break;
case DATE: // 日期
thisStr = formatter.formatRawCellContents(
Double.parseDouble(value), formatIndex, formatString);
//对日期字符串做特殊处理 , 去掉T
thisStr = thisStr.replace("T", " ");
break;
default:
thisStr = "";
break;
}
return thisStr;
}
/**
* 计算两个单元格之间的单元格数目(同一行)
*
* @param ref
* @param preRef
* @return
*/
public int countNullCell(String ref, String preRef) {
// excel2007最大行数1048576 , 最大列数 16384 , 最后一列列名是 XFD
String xfd = ref.replaceAll("\\+d", ""); // \\+d 表示数字[0-9]出现1次或多次
String xfd_1 = preRef.replaceAll("\\+d", "");
xfd = fillChar(xfd, 3, '@', true);
xfd_1 = fillChar(xfd_1, 3, '@', true);
char[] letter = xfd.toCharArray();
char[] letter_1 = xfd_1.toCharArray();
int res = (letter[0] - letter_1[0]) * 26 * 26 + (
letter[1] - letter_1[1]) * 26 + (letter[2] - letter_1[2]);
return res - 1;
}
/**
* 字符串的填充
*
* @param str str 要填充的原字符串
* @param len 要填充的字符串长度
* @param fillChar 要填充到原字符串的字符
* @param isPre
* @return
*/
public String fillChar(String str, int len, char fillChar, boolean isPre) {
int len_1 = str.length();
if (len_1 < len) {
if (isPre) {
for (int i = 0; i < (len - len_1); i++) {
str = str + fillChar;
}
} else {
for (int i = 0; i < (len - len_1); i++) {
str = str + fillChar;
}
}
}
return str;
}
/**
* 处理数据类型
*
* @param attributes
*/
public void setNextDataType(Attributes attributes) {
// 单元格数据类型
this.nextDataType = CellDataType.NUMBER; // cellType为空, 则表示该单元格数字
formatIndex = -1;
formatString = null;
String cellType = attributes.getValue("t");// 单元格类型
String cellStyleStr = attributes.getValue("s"); //
String columData = attributes.getValue("r"); // 获取单元格的位置, 如A1, B1
if ("b".equals(cellType)) { // 布尔值
this.nextDataType = CellDataType.BOOL;
} else if ("e".equals(cellType)) { // 错误
this.nextDataType = CellDataType.ERROR;
} else if ("inlineStr".equals(cellType)) { // 字符串
this.nextDataType = CellDataType.INLINESTR;
} else if ("s".equals(cellType)) { // 字符串
this.nextDataType = CellDataType.SSTINDEX;
} else if ("str".equals(cellType)) { //
this.nextDataType = CellDataType.FORMULA;
}
if (cellStyleStr != null) { // 处理日期
int styleIndex = Integer.parseInt(cellStyleStr);
XSSFCellStyle style = stylesTable.getStyleAt(styleIndex);
formatIndex = style.getDataFormat();
formatString = style.getDataFormatString();
if (formatString.contains("m/d/yy") ||
formatString.contentEquals("yyyy/mm/dd") ||
formatString.contentEquals("yyyy/m/d")) {
this.nextDataType = CellDataType.DATE;
formatString = "yyyy-MM-dd HH:mm:ss";
}
if (formatString == null) {
this.nextDataType = CellDataType.NULL;
formatString = BuiltinFormats.getBuiltinFormat(formatIndex);
}
}
}
}
6. 测试SAX解析Excel
6.1 测试代码
com.poi.service.ExcelReaderImpl#readExcelData
/**
* 测试上传excel
* 一般场景是读取用户上传的excel文件,解析里面的数据,存入db
*
* @throws Exception
*/
@Test
public void testReadExcel() throws Exception {
// String filePath = "D:\\study\\excel/poi_my.xls"; // 2003版
String filePath = "D:\\study\\excel/poi_my.xlsx"; // 2007版
// String parseType = "DOM";
String parseType = "SAX";
long start = System.currentTimeMillis();
List<List<String>> dataList = PoiUtil.readExcel(parseType, filePath,
new ExcelReaderImpl());
long end = System.currentTimeMillis();
/**
* 65536行记录耗时、cpu利用率比较
* DOM 2003版 986ms 77%
* DOM 2007版 4429ms 80%
* SAX 2003版 417ms 63%
* SAX 2007版 5978ms 80%
*/
logger.info("解析excel耗时:" + (end - start) + "ms!");
logger.info("dataList size is:" + dataList.size());
dataList.forEach(System.out::println);
}
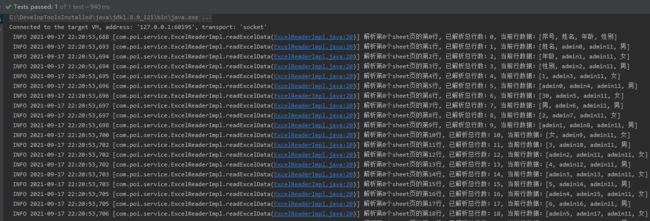
6.2 测试结果
通过控制台日志, 查看读取Excel文件效果
7. Web端测试
7.1 编写controller
com.poi.controller.ExcelController
package com.poi.controller;
import com.constant.CSISCONSTANT;
import com.exception.MyException;
import com.poi.entity.Employee;
import com.poi.service.ExcelReaderImpl;
import com.poi.util.PoiTemplateUtil;
import com.poi.util.PoiUtil;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.Part;
import java.io.*;
import java.net.URLEncoder;
import java.util.*;
/**
* 类描述:文件上传下载
* @Author wang_qz
* @Date 2021/8/14 21:07
* @Version 1.0
*/
@Controller
@RequestMapping("/excel")
public class ExcelController {
@RequestMapping("/toExcelPage2")
public String todownloadPage2() {
return "excelPage2";
}
/**
* 经过服务器临时上传目录中转的实现
* @param file
* @return
* @throws Exception
*/
@PostMapping("/uploadExcel2")
@ResponseBody
public String uploadExcel2(@RequestParam("file") MultipartFile file)
throws Exception {
// 上传文件名称, 因为当前读取excel的工具类中是去服务器中去读取文件的,
// 所以需要先将导入的文件上传到服务器
String filename = file.getOriginalFilename();
// 解决文件名中文乱码问题
filename = new String(filename.getBytes(), "utf-8");
String uploadName = CSISCONSTANT.TEMP_UPLOAD_DIR + filename;
FileOutputStream write = new FileOutputStream(uploadName);
InputStream read = file.getInputStream();
byte[] bys = new byte[1024];
while (read.read(bys) != -1) {
write.write(bys, 0, bys.length);
write.flush();
}
write.close();
// 读取上传的Excel并解析数据 SAX方法解析
List<List<String>> dataList = PoiUtil.readExcel(
CSISCONSTANT.EXCEL_PARSE_SAX, uploadName, new ExcelReaderImpl());
dataList.forEach(System.out::println);
return "upload successful!";
}
}
7.2 编写jsp页面
webapp/WEB-INF/jsp/excelPage2.jsp
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<html>
<head>
<title>测试excel文件下载title>
head>
<body>
<h3>点击下面链接, 进行excel文件下载h3>
<a href="' /excel/downloadExcel2'/>">Excel文件下载a>
<hr/>
<hr/>
<h3>点击下面按钮, 进行excel文件上传h3>
<form action="' /excel/uploadExcel2'/>" method="post" enctype="multipart/form-data">
<input type="file" name="file"/><br/>
<input type="submit" value="上传Excel"/>
form>
body>
html>
启动tomcat, 访问http://localhost:8080/excel/toExcelPage2, 进入测试页面
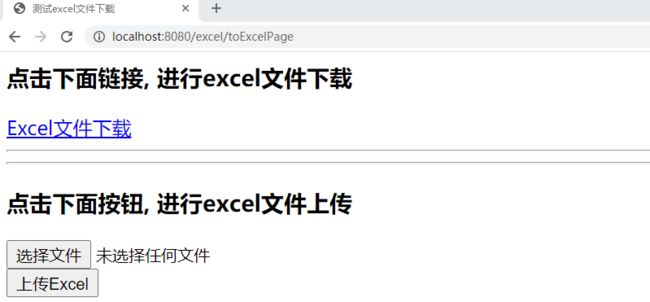
7.3 测试结果
通过控制台日志, 查看读取Excel文件效果
相关推荐
数据分流写入Excel
Poi版本升级优化
StringTemplate实现Excel导出
Poi模板技术
SAX方式实现Excel导入
DOM方式实现Excel导入
Poi实现Excel导出
EasyExcel实现Excel文件导入导出
EasyPoi实现excel文件导入导出
个人博客
欢迎各位访问我的个人博客: https://www.crystalblog.xyz/
备用地址: https://wang-qz.gitee.io/crystal-blog/