mysql必知必会学习笔记&mysql经典练习题
文章目录
-
- Lock wait timeout exceeded; try restarting transaction
- 修改字段中null为0,并设置默认值为0
- 内联结
- 组合查询
- 插入数据
- 更新、删除数据
- 插入中文报错
- 查看数据库表最近更新时间
- 经典五十题解答
- sql执行日志
- 批量清空库里的表
Lock wait timeout exceeded; try restarting transaction
mysql> show processlist;
#当前运行的所有事务
mysql> SELECT * FROM information_schema.INNODB_TRX;
#当前出现的锁
mysql> SELECT * FROM information_schema.INNODB_LOCKs;
#锁等待的对应关系
mysql> SELECT * FROM information_schema.INNODB_LOCK_waits;
Lock wait timeout exceeded; try restarting transaction
另外一个方案
修改字段中null为0,并设置默认值为0
--update null value rows
UPDATE enterprise
SET creation_date = CURRENT_TIMESTAMP
WHERE creation_date IS NULL;
ALTER TABLE enterprise
MODIFY creation_date TIMESTAMP NOT NULL
DEFAULT CURRENT_TIMESTAMP;
内联结
比如表B和表A中的字段都有id字段,B中的id字段来源于A,就可以用 WHERE B.id=A.id来建立内联结
子查询:
SELECT cust_name, cust_contact FROM Customers WHERE cust_id IN
(SELECT cust_id FROM Orders WHERE order_num IN (SELECT order_num
FROM OrderItems WHERE prod_id = 'RGAN01'));
联结
SELECT cust_name, cust_contact FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id AND OrderItems.order_num =
Orders.order_num AND prod_id = 'RGAN01';
别名
SELECT c1.cust_id, c1.cust_name, c1.cust_contact FROM Customers AS
c1, Customers AS c2 WHERE c1.cust_name = c2.cust_name AND
c2.cust_contact = 'Jim Jones';
等效语句:
SELECT cust_id, cust_name, cust_contact FROM Customers WHERE
cust_name = (SELECT cust_name FROM Customers WHERE cust_contact =
'Jim Jones');
组合查询
多数情况下,组合相同表的两个查询所完成的工作与具有多个WHERE子句条件的一个
查询所完成的工作相同。换句话说,任何具有多个WHERE子句的SELECT语句都可以
作为一个组合查询,在下面可以看到这一点。
SELECT cust_name, cust_contact, cust_email FROM Customers WHERE
cust_state IN ('IL','IN','MI');
SELECT cust_name, cust_contact, cust_email FROM Customers WHERE
cust_name = 'Fun4All';

等效用组合查询:
SELECT cust_name, cust_contact, cust_email FROM Customers WHERE
cust_state IN ('IL','IN','MI') UNION SELECT cust_name,
cust_contact, cust_email FROM Customers WHERE cust_name =
'Fun4All';
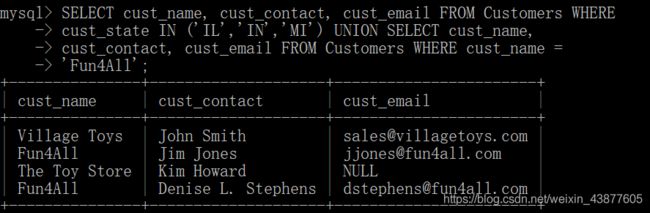
union会自动取消结果重复的数据,如果需要重复,则用unio all
插入数据
标准语句:
INSERT INTO Customers(cust_id, cust_name, cust_address, cust_city,
cust_state, cust_zip, cust_country) VALUES('1000000006', 'Toy
Land', '123 Any Street', 'New York', 'NY', '11111', 'USA');
插入检索出的语句:
INSERT INTO Customers(cust_id, cust_contact, cust_email, cust_name,cust_address, cust_city, cust_state, cust_zip, cust_country) SELECT
cust_id, cust_contact, cust_email, cust_name, cust_address,
cust_city, cust_state, cust_zip, cust_country FROM CustNew;
这个例子从一个名为CustNew的表中读出数据并插入到Customers表
导出数据:
SELECT * INTO CustCopy FROM Customers;
此处将customers中的数据导入到CustCopy中
更新、删除数据
最复杂的地方在于查询,掌握了查询,更新、删除不过是建立在查询上的一条命令罢了。
更新基本语句:
UPDATE Customers SET cust_email = '[email protected]' WHERE
cust_id = '1000000005';
删除基本语句:
DELETE FROM Customers WHERE cust_id = '1000000006';
不要把NULL值与空字符串相混淆。NULL值是没有值,不是空字符串。如果指
定’’(两个单引号,其间没有字符),这在NOT NULL列中是允许的。空字符串是一
个有效的值,它不是无值。NULL值用关键字NULL而不是空字符串指定。
插入中文报错
ERROR 1366 (HY000): Incorrect string value: '\xD5\xD4\xC0\xD7' for column 'Sname' at row 1
解决方案:
set character_set_client = gbk;
set names gbk;
stack回答
主要参考
查看数据库表最近更新时间
SELECT TABLE_NAME, UPDATE_TIME FROM INFORMATION_SCHEMA. TABLES WHERE TABLE_SCHEMA = 'awifi_capacity' and TABLE_NAME like 'capacity_ip%';
经典五十题解答
50题链接
1、查询和" 01 "号的同学学习的课程完全相同的其他同学的信息
select student.* from student where student.sid in (select sid from sc group by sid having count(*)=(select count(cid) as classnum from sc group by sid having sid=01) and sid !=01);
针对题目的特殊性,课程最多只有3门,01选择了三门,只要匹配课程数为3的学生即可,如果此时有4门课程,01只选择了3门,匹配数字就不对了
2、查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息
select student.* from student where student.sid in (select sid from sc where cid in (select cid from sc where sid=01) and sid !=01);
3、查询没有学全所有课程的同学的信息
select student.* from student where student.sid not in (select sid from sc group by sid having count(*)=(select count(cid) from course));
核心还是找出学满3门课程的sid,利用not in直接找出
4、查询学过「张三」老师授课的同学的信息
先看一种复杂的做法:
select student.* from student where student.sid in (select sc.sid from sc where sc.cid in (select cid from course where course.tid= (select tid from teacher where tname='张三')));
这种思路就是不断的用子查询,提取出关键字段进行匹配
其实完全不用这么麻烦,因为他们之间表都有各自公共匹配的字段比如cid,sid
select student.*
from teacher ,course ,student,sc
where teacher.Tname='张三'
and teacher.TId=course.TId
and course.CId=sc.CId
and sc.SId=student.SId
5、查询有成绩的学生
直接sc表和student表中的sid匹配即可,但要用distinct和student.*
select distinct student.* from student,sc where student.sid =sc.sid;
6、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为null)
这题稍微复杂一点,需要聚合函数和左联结,其实也是比较基本,核心思路用好group by,根据sid分组,求出每组的和,课程总数,这时已经有了sid就可以查出学生的基本信息,一个子查询就可以搞定
mysql> select sid, sum(score) as sum, count(*)as classnum from sc group by sid;
+------+-------+----------+
| sid | sum | classnum |
+------+-------+----------+
| 01 | 269.0 | 3 |
| 02 | 210.0 | 3 |
| 03 | 240.0 | 3 |
| 04 | 100.0 | 3 |
| 05 | 163.0 | 2 |
| 06 | 65.0 | 2 |
| 07 | 187.0 | 2 |
+------+-------+----------+
mysql> select result.*,student.* from student ,(select sid, sum(score) as sum, count(*)as classnum from sc group by sid )as result where student.sid=result.sid;
+------+-------+----------+------+-------+---------------------+------+
| sid | sum | classnum | SId | Sname | Sage | Ssex |
+------+-------+----------+------+-------+---------------------+------+
| 01 | 269.0 | 3 | 01 | 赵雷 | 1990-01-01 00:00:00 | 男 |
| 02 | 210.0 | 3 | 02 | 钱电 | 1990-12-21 00:00:00 | 男 |
| 03 | 240.0 | 3 | 03 | 孙风 | 1990-05-20 00:00:00 | 男 |
| 04 | 100.0 | 3 | 04 | 李云 | 1990-08-06 00:00:00 | 男 |
| 05 | 163.0 | 2 | 05 | 周梅 | 1991-12-01 00:00:00 | 女 |
| 06 | 65.0 | 2 | 06 | 吴兰 | 1992-03-01 00:00:00 | 女 |
| 07 | 187.0 | 2 | 07 | 郑竹 | 1989-07-01 00:00:00 | 女 |
+------+-------+----------+------+-------+---------------------+------+
7 rows in set (0.00 sec)
7、查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
一样也是使用group,和avg函数,
mysql> select avg(score) as average from sc group by sid having average >60;
+----------+
| average |
+----------+
| 89.66667 |
| 70.00000 |
| 80.00000 |
| 81.50000 |
| 93.50000 |
+----------+
5 rows in set (0.00 sec)
这只是找到了平均分大于60的,我们还要取出sid去跟student匹配
mysql> select student.* from student,(select sid,avg(score) as average from sc group by sid having average >60)as result where student.sid in (result.sid);
+------+-------+---------------------+------+
| SId | Sname | Sage | Ssex |
+------+-------+---------------------+------+
| 01 | 赵雷 | 1990-01-01 00:00:00 | 男 |
| 02 | 钱电 | 1990-12-21 00:00:00 | 男 |
| 03 | 孙风 | 1990-05-20 00:00:00 | 男 |
| 05 | 周梅 | 1991-12-01 00:00:00 | 女 |
| 07 | 郑竹 | 1989-07-01 00:00:00 | 女 |
+------+-------+---------------------+------+
5 rows in set (0.00 sec)
8、查询不存在" 01 “课程但存在” 02 "课程的学生情况
这是一个差集,也比较简单
mysql> select student.* from student where student.sid in (select sc.sid from sc where sc.sid not in (select sc.sid from sc where sc.cid=01) and sc.cid=02);
+------+-------+---------------------+------+
| SId | Sname | Sage | Ssex |
+------+-------+---------------------+------+
| 07 | 郑竹 | 1989-07-01 00:00:00 | 女 |
+------+-------+---------------------+------+
1 row in set (0.00 sec)
9、查询存在" 01 “课程但可能不存在” 02 "课程的情况(不存在时显示为 null )
这里考察的left join的使用,left join为以左边的数据表作为查找基础,如果右边的数据表里查不到左边表中的字段数据会记为null
内联结,左联结详情
mysql> select * from (select * from sc where cid=01) as t1 left join (select *from sc where cid=02) t2 on t1.sid=t2.sid;
+------+------+-------+------+------+-------+
| SId | CId | score | SId | CId | score |
+------+------+-------+------+------+-------+
| 01 | 01 | 80.0 | 01 | 02 | 90.0 |
| 02 | 01 | 70.0 | 02 | 02 | 60.0 |
| 03 | 01 | 80.0 | 03 | 02 | 80.0 |
| 04 | 01 | 50.0 | 04 | 02 | 30.0 |
| 05 | 01 | 76.0 | 05 | 02 | 87.0 |
| 06 | 01 | 31.0 | NULL | NULL | NULL |
+------+------+-------+------+------+-------+
6 rows in set (0.00 sec)
10、查询没学过"张三"老师讲授的任一门课程的学生姓名
mysql> select sname,student.sid from student where student.sid not in (select sc.sid from sc where sc.cid = (select cid from course where course.tid = (select teacher.tid from teacher where tname = '张三')));
+-------+------+
| sname | sid |
+-------+------+
| 吴兰 | 06 |
| 张三 | 09 |
| 李四 | 10 |
| 李四 | 11 |
| 赵六 | 12 |
| 孙七 | 13 |
+-------+------+
6 rows in set (0.00 sec)
这里一样是一层一层的往上扒,先根据老师的名字去teacher表里查出他的课程id也就是cid,这时只要在分数表sc里找到含有该cid的sid,之后取个差集,也就是在student表里的sid不等于在sc表里查到的sid便是没选该老师课程的学生,这样差集的话也一样包含了没有选课的学生,这里的纰漏就是把根本没上过任何课的人也包含进来了,实际数据统计时这些应该算是无效数据,其实这里题目做个限定更好,查询有上过课但是没有选张三老师的学生信息,这样就排除了没上课的人。
mysql> select sname,student.sid from student where student.sid not in (select sc.sid from sc where sc.cid = (select cid from course where course.tid = (select teacher.tid from teacher where tname = '张三'))) and student.sid in (select sc.sid from sc);
+-------+------+
| sname | sid |
+-------+------+
| 吴兰 | 06 |
+-------+------+
1 row in set (0.00 sec)
11、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
mysql> select sid,avg(score) as average,count(score) from sc where sc.score<60 group by sid having count(score)>=2;
+------+----------+--------------+
| sid | average | count(score) |
+------+----------+--------------+
| 04 | 33.33333 | 3 |
| 06 | 32.50000 | 2 |
+------+----------+--------------+
2 rows in set (0.00 sec)
12、检索" 01 "课程分数小于 60,按分数降序排列的学生信息
这个题目改为升序更好,mysql默认就是降序的
mysql> select student.*, result.score from student,(select sid, score from sc where score<60 and cid=01 order by score asc)as result where student.sid =result.sid order by result.score asc;
+------+-------+---------------------+------+-------+
| SId | Sname | Sage | Ssex | score |
+------+-------+---------------------+------+-------+
| 06 | 吴兰 | 1992-03-01 00:00:00 | 女 | 31.0 |
| 04 | 李云 | 1990-08-06 00:00:00 | 男 | 50.0 |
+------+-------+---------------------+------+-------+
2 rows in set (0.00 sec)
13、按平均成绩从高到低显示所有学生的信息以及平均成绩
mysql> select student.*, result.average from student,(select sid,avg(score) as average,count(score) from sc group by sid)as result where student.sid = result.sid order by average;
+------+-------+---------------------+------+----------+
| SId | Sname | Sage | Ssex | average |
+------+-------+---------------------+------+----------+
| 06 | 吴兰 | 1992-03-01 00:00:00 | 女 | 32.50000 |
| 04 | 李云 | 1990-08-06 00:00:00 | 男 | 33.33333 |
| 02 | 钱电 | 1990-12-21 00:00:00 | 男 | 70.00000 |
| 03 | 孙风 | 1990-05-20 00:00:00 | 男 | 80.00000 |
| 05 | 周梅 | 1991-12-01 00:00:00 | 女 | 81.50000 |
| 01 | 赵雷 | 1990-01-01 00:00:00 | 男 | 89.66667 |
| 07 | 郑竹 | 1989-07-01 00:00:00 | 女 | 93.50000 |
+------+-------+---------------------+------+----------+
7 rows in set (0.00 sec)
14、求各科成绩平均分,最高低分
以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
一点点来化解这个题目,先从求最高低分,平均分开始解决
mysql> select cname ,result.* from course,(select cid,avg(score)as average, max(score)as max,min(score)as min from sc group by cid)as result where course.cid = result.cid;
+-------+------+----------+------+------+
| cname | cid | average | max | min |
+-------+------+----------+------+------+
| 语文 | 01 | 64.50000 | 80.0 | 31.0 |
| 数学 | 02 | 72.66667 | 90.0 | 30.0 |
| 英语 | 03 | 68.50000 | 99.0 | 20.0 |
+-------+------+----------+------+------+
3 rows in set (0.00 sec)
sql执行日志
mysql -uroot -p -Dtest -tee=/tmp/mysql.log
# 注:这种如果在连接后删除了文件,日志文件不会被重建,除非重新连接
#在终端内执行
tee /tmp/mysql.log
-- 取消输出到日志
notee
批量清空库里的表
select CONCAT('truncate table ',table_schema,'.',TABLE_NAME, ';') from INFORMATION_SCHEMA.TABLES where table_schema in ('awifi_alf') AND table_name LIKE 'wii_user%';
先执行以上语句后,mysql命令行会显示语句,将其复制出来进行字符替换处理,再复制回去执行
MariaDB [awifi_capacity]> select CONCAT('truncate table ',table_schema,'.',TABLE_NAME, ';') from INFORMATION_SCHEMA.TABLES where table_schema in ('awifi_capacity');
+--------------------------------------------------------------------------------+
CONCAT('truncate table ',table_schema,'.',TABLE_NAME, ';')
+--------------------------------------------------------------------------------+
truncate table awifi_capacity.capacity_adaptor_config;
truncate table awifi_capacity.capacity_adaptor_param;
truncate table awifi_capacity.capacity_adaptor_param_fufu;
truncate table awifi_capacity.capacity_biz_log;
truncate table awifi_capacity.capacity_common_third_app;
truncate table awifi_capacity.capacity_ip_control;
truncate table awifi_capacity.capacity_ip_control_api;
truncate table awifi_capacity.capacity_ip_control_capacity;
truncate table awifi_capacity.capacity_ip_control_item;
truncate table awifi_capacity.capacity_operate_action;
truncate table awifi_capacity.capacity_operate_log;
truncate table awifi_capacity.capacity_portal_modules;
truncate table awifi_capacity.capacity_portal_modules_type;
truncate table awifi_capacity.capacity_portal_site;
truncate table awifi_capacity.capacity_portal_types_modules;
truncate table awifi_capacity.capacity_pricing_strategy;
truncate table awifi_capacity.capacity_pub_api;
truncate table awifi_capacity.capacity_pub_api_copy;
truncate table awifi_capacity.capacity_pub_api_copy2;
truncate table awifi_capacity.capacity_pub_api_group;
truncate table awifi_capacity.capacity_pub_api_status;