吴恩达机器学习(八)聚类与降维(K-Means,PCA)
∗ ∗ ∗ 点 击 查 看 : 吴 恩 达 机 器 学 习 — — 整 套 笔 记 + 编 程 作 业 详 解 ∗ ∗ ∗ \color{#f00}{***\ 点击查看\ :吴恩达机器学习 \ —— \ 整套笔记+编程作业详解\ ***} ∗∗∗ 点击查看 :吴恩达机器学习 —— 整套笔记+编程作业详解 ∗∗∗
本章对应编程练习:编程作业(python)| 吴恩达机器学习(7)K-Means,PCA
本章目录
- 1. 聚类——K均值算法
-
- 1.1 K-Means的优化目标
- 1.2 随机初始化
- 1.3 选择聚类数
- 2. 降维
-
- 2.1 PCA 的思想
- 2.2 PCA 的步骤
- 2.3 PCA反向压缩——原始数据重现
- 2.4 如何选择主成分的数量
- 2.5 应用 PCA 的建议
1. 聚类——K均值算法
(Clustering——K-Means Algorithm )
聚类算法将样本聚类分成不同的簇(cluster),其中K-means是最普及的一种聚类算法,它的思想其实就是迭代,假设我们想要将数据聚类成k个簇,其步骤为:
-
首先选择K个随机的点,称为聚类中心(cluster centroids);(图a,b,以K=2为例)
-
对于数据集中的每个点,按照与聚类中心的距离,将其与距离最近的聚类中心点聚成一类;(图c)
-
计算每一个组的平均值(重心位置),将该组所关联的中心点移动到平均值的位置;(图d)
重复步骤 2、3 直至中心点不再变化(即算法收敛)。(图e,f为第二轮迭代)

1.1 K-Means的优化目标
在大多数我们已经学到的 监督学习算法中。 算法都有一个优化目标函数(代价函数),需要通过算法进行最小化 。
K均值的优化目标为: J ( c ( 1 ) , … , c ( m ) , μ 1 , … , μ K ) = 1 m ∑ i = 1 m ∥ X ( i ) − μ c ( i ) ∥ 2 J\left(c^{(1)}, \ldots, c^{(m)}, \mu_{1}, \ldots, \mu_{K}\right)=\frac{1}{m} \sum_{i=1}^{m}\left\|X^{(i)}-\mu_{c^{(i)}}\right\|^{2} J(c(1),…,c(m),μ1,…,μK)=m1i=1∑m∥∥∥X(i)−μc(i)∥∥∥2其中:
- c ( i ) c^{(i)} c(i) 表示当前样本点 x ( i ) x^{(i)} x(i) 对应聚类中心的索引;
- μ k \mu_k μk 表示第 k k k 个聚类中心;
- μ c ( i ) \mu_{c^{(i)}} μc(i) 代表与样本点 x ( i ) x^{(i)} x(i) 最近的聚类中心点。
从公式上不难理解,k均值的优化目标就是让每一个样本点找到最优的聚类中心。
找出使得代价函数最小的 c ( 1 ) , c ( 2 ) , … , c ( m ) c^{(1)}, c^{(2)}, \ldots, c^{(m)} c(1),c(2),…,c(m) 和 μ 1 , μ 2 , … , μ K \mu_{1}, \mu_{2}, \ldots, \mu_{K} μ1,μ2,…,μK,即:
min c ( 1 ) , … , c ( m ) μ 1 , … , μ K J ( c ( 1 ) , … , c ( m ) , μ 1 , … , μ K ) \begin{array}{l} \displaystyle\min_{ \begin{matrix} c^{(1)}, \ldots, c^{(m)} \\ \mu_{1}, \ldots, \mu_{K} \end{matrix} } J\left(c^{(1)}, \ldots, c^{(m)}, \mu_{1}, \ldots, \mu_{K}\right) \end{array} c(1),…,c(m)μ1,…,μKminJ(c(1),…,c(m),μ1,…,μK)
1.2 随机初始化
在运行K-均值算法的之前,我们首先要随机初始化所有的聚类中心点:
- 我们应该选择 K < m K
K<m ,即聚类中心点的个数要小于所有训练集实例的数量; - 随机选择 K K K 个样本点作为初始聚类中心。
K-均值的一个问题在于,不同的初始化位置会有不同的聚类结果,而且结果有可能会停留在一个局部最小值处,而这取决于初始化的情况。如下图三种随机初始化:

解决方法是多次初始化聚类中心,然后计算K-Means的代价函数,根据代价函数的大小选择最优解。

这种方法在较小的时候还是可行的,但是如果 K K K 较大,这么做也可能不会有明显地改善。
1.3 选择聚类数
了解了算法原理后,面对实际问题时,我们怎么决定聚类数呢?K=?
效果较差的 —— “ 肘部法则 ”
改变 K 值,获得不同 K值和代价函数最小值的关系曲线:
- 理想情况下我们可能会得到左下图中类似 “肘部” 的额曲线,该处的 K 值即为最佳聚类数。
- 但是实际情况却是像由下图那样,曲线较为平滑,无法判断哪里是 “肘部”
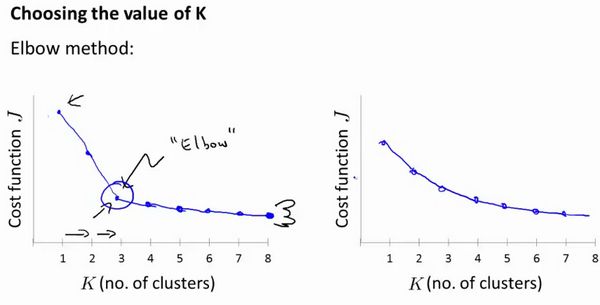
因此,没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题需求,人工进行选择的。选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
例如,我们的 T-恤制造例子中,我们要将用户按照身材聚类,我们可以分成3个尺寸:S,M,L,也可以分成5个尺寸:XS,S,M,L,XL,这样的选择是建立在回答“聚类后我们制造的T-恤是否能较好地适合我们的客户”这个问题的基础上作出的。
2. 降维
(Dimensionality Reduction)
简言之,降维就是降低特征的维数,例如每个样本点有1000个特征,通过降维,可以用100个特征来替代原来的1000个特征。
降维的好处在于:
- Data compression 数据压缩,可以提高运算速度和减少存储空间。
- Data Visualization 数据可视化,得到更直观的视图
如下图是一个将 3 维特征转换为 2 维特征的例子
2.1 PCA 的思想
对于降维问题来说,目前最流行最常用的算法是 主成分分析法 (Principal Componet Analysis, PCA)
PCA是寻找到一个 低维的空间 对数据进行 投影 ,以便 最小化投影误差的平方( 最小化每个点 与投影后的对应点之间的距离的平方值 ),例如:
- 2维→1维:点到直线的垂直距离
- 3维→2维:点到平面的垂直距离

如上图所示,低维空间是由其中的特征向量 u ( i ) u^{(i)} u(i) 来确定的,因此PCA算法的核心就是寻找 低维空间的特征向量。
PCA与LR的区别
线性回归(Linear Regression,LR)与 2维PCA的区别:虽然都是找一条直线去拟合,但是计算 loss (损失/代价函数)的方式不同。
- PCA计算的是投影误差(垂直距离),而LR计算的是预测值与实际值的误差(竖直距离);
- PCA中只有特征没有标签数据y(非监督学习),LR中既有特征样本也有标签数据(监督学习)。

2.2 PCA 的步骤
利用 PCA 将 n维 降到 k维 的步骤:
-
特征缩放(均值归一化),使得特征的数值在可比较的范围之内。
-
计算协方差矩阵(covariance matrix),用 Σ \Sigma Σ 表示(大写的Sigma,不是求和符号): Σ n × n = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T \Sigma_{n×n}=\frac{1}{m} \sum_{i=1}^{n}\left(x^{(i)}\right)\left(x^{(i)}\right)^{T} Σn×n=m1i=1∑n(x(i))(x(i))T
-
利用奇异值分解(SVD)来分解协方差矩阵,得到的特征向量 U n × n U_{n×n} Un×n 是一个具有与数据之间最小投射误差的方向向量构成的矩阵
[ U , S , V ] = s v d ( Σ ) [U, S, V]= svd(\Sigma) [U,S,V]=svd(Σ) U n × n = [ ∣ ∣ ∣ ∣ ∣ u ( 1 ) u ( 2 ) u ( 3 ) … u ( n ) ∣ ∣ ∣ ∣ ∣ ] U_{n \times n}=\left[\begin{array}{ccccc} | & | & | & | & | \\ u^{(1)} & u^{(2)} & u^{(3)} & \ldots & u^{(n)} \\ | & | & | & | & | \end{array}\right] Un×n=⎣⎡∣u(1)∣∣u(2)∣∣u(3)∣∣…∣∣u(n)∣⎦⎤ -
取出 U n × n U_{n×n} Un×n 的前 k k k 个向量作为降维后的特征矩阵 U r e d u c e U_{reduce} Ureduce,将原始样本 x ( 1 ) , x ( 2 ) , x ( 3 ) , … … … x ( m ) ( x ∈ R n ) x^{(1)}, x^{(2)}, x^{(3)}, \ldots \ldots \ldots x^{(m)}\left(x \in R^{n}\right) x(1),x(2),x(3),………x(m)(x∈Rn) 转化为新的特征向量下的新样本点 z ( 1 ) , z ( 2 ) , z ( 3 ) , … … . . z ( m ) z^{(1)}, z^{(2)}, z^{(3)}, \ldots \ldots . . z^{(m)} z(1),z(2),z(3),……..z(m)
z ( i ) = U r e d u c e T x ( i ) = [ ∣ ∣ ∣ ∣ ∣ u ( 1 ) u ( 2 ) u ( 3 ) … u ( k ) ∣ ∣ ∣ ∣ ∣ ] T x ( i ) z^{(i)}=U_{r e d u c e}^{T}\ x^{(i)}=\left[\begin{array}{ccccc} | & | & | & | & | \\ u^{(1)} & u^{(2)} & u^{(3)} & \ldots & u^{(k)} \\ | & | & | & | & | \end{array}\right]^{T}x^{(i)} z(i)=UreduceT x(i)=⎣⎡∣u(1)∣∣u(2)∣∣u(3)∣∣…∣∣u(k)∣⎦⎤Tx(i)
2.3 PCA反向压缩——原始数据重现
既然PCA可以将高维数据压缩到低维,那么反着使用PCA则可以将低维数据恢复到高维。
因为 z = U reduce T x z=U_{\text {reduce}}^{T} x z=UreduceTx,那么反过来: x a p p o x = U r e d u c e ⋅ z ≈ x x_{a p p o x}=U_{r e d u c e} \cdot z\approx x xappox=Ureduce⋅z≈x
注意这里的 x a p p o x x_{a p p o x} xappox 只是近似值。

2.4 如何选择主成分的数量
在 PCA 算法中,我们把 n n n 维特征变量 降维到 k k k 维特征变量 。这个数字 k k k 也被称作 主成分的数量 或者说是我们保留的主成分的数量 。
首先来看看以下两个值:
-
PCA 的 投射平均均方误差 (Average Squared Projection Error) :
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 \frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}-x_{a p p r o x}^{(i)}\right\|^{2} m1i=1∑m∥∥∥x(i)−xapprox(i)∥∥∥2 -
训练集的方差,它的意思是 平均来看 我的训练样本 距离零向量多远 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 \frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}\right\|^{2} m1i=1∑m∥∥∥x(i)∥∥∥2
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 k k k 值:
1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 ≤ 0.01 ( 1 % ) \frac{\frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}-x_{a p p r o x}^{(i)}\right\|^{2}}{\frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}\right\|^{2}} \leq 0.01(1 \%) m1∑i=1m∥∥x(i)∥∥2m1∑i=1m∥∥∥x(i)−xapprox(i)∥∥∥2≤0.01(1%)我们把两个数的比值作为衡量PCA算法的有效性,例如比值小于 1 % 1\% 1% 时,说明PCA算法保留了原始数据 99 % 99\% 99% 的差异性。(一般选择保留90%即可)
-
因此我们可以先定义一个阈值,然后不断实验 k,直到获得满足阈值的最小 k k k 值。
-
此外,还可以利用奇异值 S i j S_{ij} Sij 来计算平均均方误差与训练集方差的比例。 [ U , S , V ] = s v d ( Σ ) [U, S, V]= svd(\Sigma) [U,S,V]=svd(Σ) 其中的 S n × n S_{n×n} Sn×n为对角矩阵:

有: 1 m ∑ i = 1 m ∥ x ( i ) − x a p p r o x ( i ) ∥ 2 1 m ∑ i = 1 m ∥ x ( i ) ∥ 2 = 1 − Σ i = 1 k S i i Σ i = 1 m S i i ≤ 1 % \frac{\frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}-x_{a p p r o x}^{(i)}\right\|^{2}}{\frac{1}{m} \sum_{i=1}^{m}\left\|x^{(i)}\right\|^{2}}=1-\frac{\Sigma_{i=1}^{k} S_{i i}}{\Sigma_{i=1}^{m} S_{i i}} \leq 1 \% m1∑i=1m∥∥x(i)∥∥2m1∑i=1m∥∥∥x(i)−xapprox(i)∥∥∥2=1−Σi=1mSiiΣi=1kSii≤1%即: ∑ i = 1 k S i i ∑ i = 1 n S i i ≥ 0.99 \frac{\sum_{i=1}^{k} S_{i i}}{\sum_{i=1}^{n} S_{i i}} \geq 0.99 ∑i=1nSii∑i=1kSii≥0.99
2.5 应用 PCA 的建议
PCA主要用在以下情况:
- 数据压缩,可以提高运算速度和减少存储空间。
- 数据可视化,得到更直观的视图
并注意:
- 有些人觉的PCA也可以用来防止过拟合,但是这是不对的。应该用正则化。正则化使用y标签最小化损失函数,使用了y标签信息。而PCA只单纯的看x的分部就删除了一些特征,损失了很多信息。
- 另一个常见的错误是,默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
参考:机器学习笔记week8