Python 网络爬虫实战:手把手教你爬取微博评论区数据
大家好,我是机灵鹤。
前几天群里有个粉丝问我,怎么爬取 新浪微博的评论 ,他希望爬取人民日报的微博评论区数据,然后做一些相关的数据分析。
本篇博客,我会手把手教你们如何爬取新浪微博的评论区数据。
1. 思路分析
本节中,我会详细讲解如何分析网站,如何抓包,如何抓取关键参数等,想要学习爬虫的同学,建议耐心看完。
1.1 分析网站
如下,是博主 吃花椒的喵酱 发布的一条微博,我们以此条微博为例进行分析。
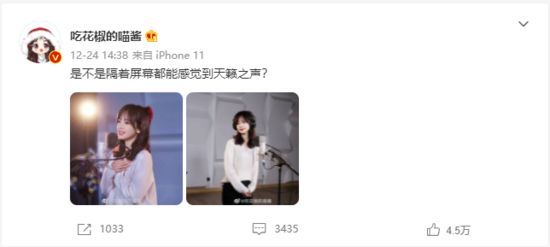
当点击中间的 评论 图标时,会显示部分评论数据。
评论区划到最下方,显示 查看全部3436条评论> 字样,点击后,可以加载显示全部的评论。当评论区滚动条不断下划时,新的评论数据会源源不断 动态加载 进来,直到全部显示完。
1.2 抓包分析
接下来,我们在浏览器中(按 F12 )打开 开发者工具 ,切换到 Network 页签,开始抓包。
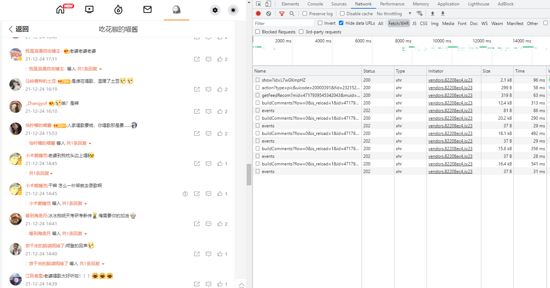
当评论区页面不断下划时,右侧随之不断出现新的请求消息,这个过程就是所谓的 抓包 ,右侧的请求列表就是我们抓到的 包 。点击列表里的每个包,可以查看该包的请求头,响应数据等。
在预览列表中 buildComments?fl... 包的响应内容时,我们惊奇的发现,评论数据就包含在这条请求里,包括了 评论内容 , 评论时间 , 评论点赞数 , 评论回复数 ,以及 评论者信息 等数据。
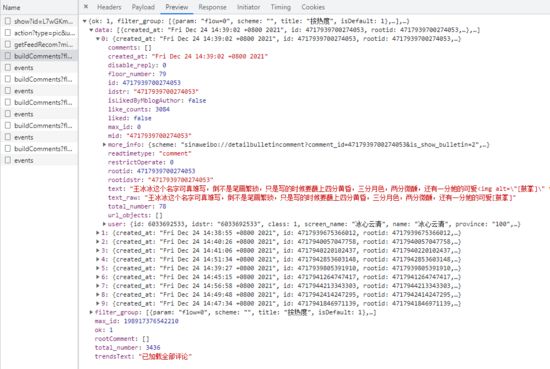
也就是说,只要我们通过代码去模拟发出这条请求,便可以获得这条请求中的评论数据。
1.3 模拟请求
那么,如何去模拟这条请求呢?
下图是这条请求的请求头信息(切换到 Headers 页签可以查看到)。
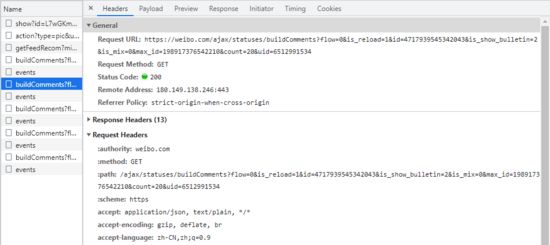
请求地址如下:
https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4717939545342043&is_show_bulletin=2&is_mix=0&max_id=198917376542210&count=20&uid=6512991534
有一些前端基础的同学可能知道,网址中 ? 后面的部分是这条请求的参数,格式为 key=value ,参数间通过 & 进行分隔。
为了看起来更清晰一些,我们将请求地址整理成如下形式:
url = "https://weibo.com/ajax/statuses/buildComments"
params = {
"flow" : 0,
"is_reload" : 1,
"id" : 4717939545342043,
"is_show_bulletin" : 2,
"is_mix" : 0,
"max_id" : 198917376542210,
"count" : 20,
"uid" : 6512991534
}
在此基础上,我们简单写一段 Python 代码,模拟请求,看能否正确获取数据:
import requests
def fetchUrl():
# url
url = "https://weibo.com/ajax/statuses/buildComments"
# 请求头
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
# 参数
params = {
"flow" : 0,
"is_reload" : 1,
"id" : 4717939545342043,
"is_show_bulletin" : 2,
"is_mix" : 0,
"max_id" : 198917376542210,
"count" : 20,
"uid" : 6512991534
}
r = requests.get(url, headers = headers, params = params)
return r.json()
fetchUrl()
运行结果,成功获取到了评论数据
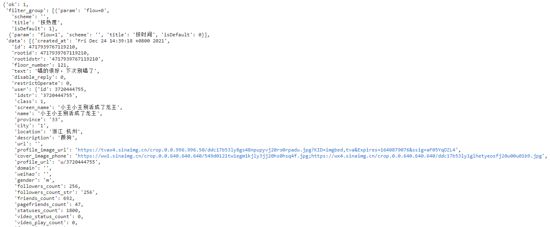
1.4 数据解析
经过前面的分析,我们可以成功模拟请求,获得评论数据了,那返回的评论数据是什么格式的呢?如何从中提取自己想要的内容呢?
以下是我简化后的返回数据:
{
'data': [
{
'created_at': 'Fri Dec 24 14:39:18 +0800 2021',
"id": 4717939767119210,
"text": "唱的很好,下次别唱了",
'like_counts': 14,
'total_number': 0,
'user': {
'id': 3720444755,
'name': '小王小王别活成了龙王',
'location': '浙江 杭州',
.....
}
},
{
......},
{
......}
],
"total_number": 3438,
"max_id": 142979722418635,
"trendsText": "已加载全部评论"
}
可以看到,返回的数据是 json 格式,评论数据以数组的形式放在 'data' 节点下。
解析的话,我们可以通过 python 自带的 json 库来解析,示例代码如下:
# 假设 jsonObj 是返回的数据
data = jsonObj["data"]
for item in data:
# 评论id
comment_Id = item["id"]
# 评论内容
content = BeautifulSoup(item["text"], "html.parser").text
# 评论时间
created_at = item["created_at"]
# 点赞数
like_counts = item["like_counts"]
# 评论数
total_number = item["total_number"]
# 评论者 id
userID = item["user"]["id"]
# 评论者昵称
userName = item["user"]["name"]
# 评论者城市
userCity = item["user"]["location"]
max_id = jsonObj["max_id"]
通过上述的方法,可以将我们需要的数据解析出来。
1.5 循环爬取
通过前面的 模拟请求 和 解析数据 环节,我们可以成功的获取并解析出一条请求中的评论数据。
那么,如何才能循环爬取整个评论区呢?
这就需要找到请求中参数的规律,自行构造并发起请求。
我们回过头来看这条请求的参数。
params = {
"flow" : 0,
"is_reload" : 1,
"id" : 4717939545342043,
"is_show_bulletin" : 2,
"is_mix" : 0,
"max_id" : 198917376542210,
"count" : 20,
"uid" : 6512991534
}
请求中有很多参数,如 flow , is_reload , id , is_show_bulletin 等等,每个参数是什么意思,其实我也不知道,只能根据字面意思去猜,或者找规律。
经过一番探索,我终于搞明白了其中几个关键参数的含义。
-
flow:推测是排序方式,0 表示按热度排序,1 表示按时间排序。 -
id:是指该条微博的 id,如果爬取单条微博的评论区,id 值是固定的。 -
max_id:具体含义不明,推断是用来控制页码的,后一条请求的 max_id 可以从前一条请求数据中取到。 -
count:每页的评论条数,20 表示该请求返回 20 条评论数据。 -
uid:该条微博的博主用户 id,如果爬取单条微博的评论区,uid 值也是固定的。 -
其他的参数意义暂时没搞懂,不过不重要。
找到规律后,我们可以通过构造参数,实现循环爬取,示例代码如下:
首先我们将 fetchUrl 函数改造一下,微博 id,用户 id 和 max_id 作为参数传进去,其余参数可以固定写死。
def fetchUrl(pid, uid, max_id):
url = "https://weibo.com/ajax/statuses/buildComments"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
params = {
"flow" : 0,
"is_reload" : 1,
"id" : pid,
"is_show_bulletin" : 2,
"is_mix" : 0,
"max_id" : max_id,
"count" : 20,
"uid" : uid,
}
r = requests.get(url, headers = headers, params = params)
return r.json()
然后在数据解析函数中,解析得到 max_id 并返回,以便作为下一条请求中得参数。
def parseJson(jsonObj):
data = jsonObj["data"]
for item in data:
# 解析数据
pass
return jsonObj["max_id"]
最后在主函数中,通过循环实现整个评论区爬取。
if __name__ == "__main__":
pid = 4717939545342043 # 微博id,固定
uid = 6512991534 # 用户id,固定
# max_id 为 0 时爬取第一页,后续请求的 max_id 可以从前一条请求中解析得到
max_id = 0
while(True):
html = fetchUrl(pid, uid, max_id)
# 解析数据的时候,动态改变 max_id 的值
max_id = parseJson(html)
# max_id 为 0 时,表示爬取结束
if max_id == 0:
break;
至此,微博评论区爬虫的思路分析部分完成。
通过上述方式,我们可以爬取到单条微博的评论区的全部主评论数据。
下面进入正式的编码环节。
2. 编码环节
本节中,我会将本爬虫的源代码整理贴出,可以直接使用。
2.1 导入需要的库
import requests from bs4 import BeautifulSoup import pandas as pd import os
2.2 发起网络请求
def fetchUrl(pid, uid, max_id):
url = "https://weibo.com/ajax/statuses/buildComments"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
}
params = {
"flow" : 0,
"is_reload" : 1,
"id" : pid,
"is_show_bulletin" : 2,
"is_mix" : 0,
"max_id" : max_id,
"count" : 20,
"uid" : uid,
}
r = requests.get(url, headers = headers, params = params)
return r.json()
2.3 解析json数据
def parseJson(jsonObj):
data = jsonObj["data"]
max_id = jsonObj["max_id"]
commentData = []
for item in data:
# 评论id
comment_Id = item["id"]
# 评论内容
content = BeautifulSoup(item["text"], "html.parser").text
# 评论时间
created_at = item["created_at"]
# 点赞数
like_counts = item["like_counts"]
# 评论数
total_number = item["total_number"]
# 评论者 id,name,city
user = item["user"]
userID = user["id"]
userName = user["name"]
userCity = user["location"]
dataItem = [comment_Id, created_at, userID, userName, userCity, like_counts, total_number, content]
print(dataItem)
commentData.append(dataItem)
return commentData, max_id
2.4 保存数据
def save_data(data, path, filename):
if not os.path.exists(path):
os.makedirs(path)
dataframe = pd.DataFrame(data)
dataframe.to_csv(path + filename, encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )
2.5 主函数
if __name__ == "__main__":
pid = 4717939545342043 # 微博id,固定
uid = 6512991534 # 用户id,固定
max_id = 0
path = "D:/Data/" # 保存的路径
filename = "comments.csv" # 保存的文件名
csvHeader = [["评论id", "发布时间", "用户id", "用户昵称", "用户城市", "点赞数", "回复数", "评论内容"]]
save_data(csvHeader, path, filename)
while(True):
html = fetchUrl(pid, uid, max_id)
comments, max_id = parseJson(html)
save_data(comments, path, filename)
# max_id 为 0 时,表示爬取结束
if max_id == 0:
break;
以上便是本爬虫的全部源码,如果运行时遇到什么问题,都可以留言联系我。
3. 运行爬虫
本节简单讲解如何将爬虫运行起来,并展示爬虫运行的部分效果图。
3.1 如何运行
首先,要在自己机器上搭建好 Python 开发环境,并且安装好需要的库。
然后,复制上一节中提供的爬虫源码。
代码中有几个参数 pid , uid , path , filename 需要根据自己的需求进行更改。
pid (微博id)和 uid (用户id)的获取方式,在第一节的抓包分析中有详细讲解,如果你没有细看的话,这里简单介绍一下如何获取。
打开 开发者工具 和要爬取的微博的 评论区 。
向下划动滚动条让页面加载更多评论。
在开发者工具中,找到 buildComments 的请求,打开。
在 Request URL 中可以找到这两个参数的值。
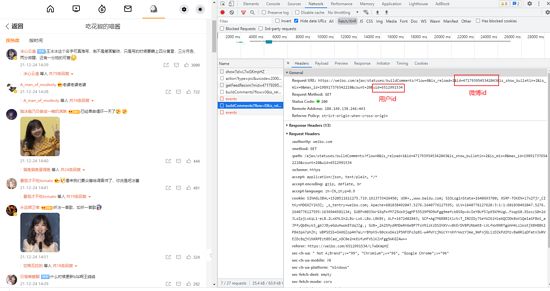
path 就是你爬好的数据要保存的文件夹路径。
filename 就是你爬好的数据保存的文件名。
参数设定好以后,运行代码,即可。
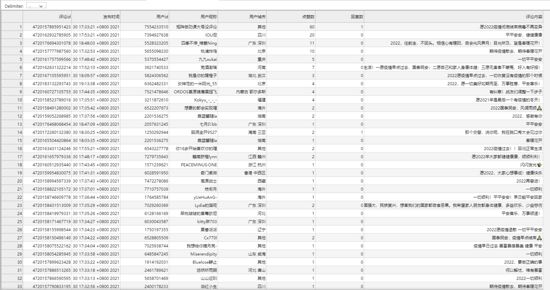
3.2 运行效果
代码运行结果

保存好的 csv 文件