MotionNet 工程复现
MotionNet 工程复现
1. 下载工程和数据
1)通过下面的网站,注册下载software即可
https://www.merl.com/research/?research=license-request&sw=MotionNet
2)下载nusenes-mini的数据
参考:nuScenes介绍
主要包含内容如下:
Loading NuScenes tables for version v1.0-mini...
23 category,
8 attribute,
4 visibility,
911 instance,
12 sensor,
120 calibrated_sensor,
31206 ego_pose,
8 log,
10 scene, **
404 sample, **
31206 sample_data,
18538 sample_annotation,
4 map
注解:
scene:场景-20秒的汽车行程片段
sample:样本-特定时间戳的场景的标注快照
sample_data:样本数据-从特定传感器采集的数据
sample_annotation:样本标注-我们感兴趣的目标的标注实例
instance:实例-枚举我们观察到的所有目标实例
category:类别-目标类别的分类法(例如车辆、人)
attribute:属性-在类别保持不变的情况下可以更改的实例的属性
visibility:可见性-从6个不同摄像头采集的所有图像中可见的像素部分
sensor:传感器-特定传感器类型
calibrated sensor:校准传感器-在特定车辆上校准的特定传感器
ego_pose:自主姿态-自主车辆载具在特定时间戳的姿态
log:日志—从中提取数据的日志信息
map:映射—从自顶向下的视图中存储为二进制语义掩码的映射数据
2. 安装依赖
依赖较少,前期先安装下面的基础包即可,后期缺少什么包现安装即可,参考后面的疑问解答。
CUDA >= 9.0
- Python 3
- pyquaternion, Matplotlib, PIL, numpy, cv2, tqdm (and other relevant packages which can be easily installed with pip or conda)
- PyTorch >= 1.1
- Note that, the MGDA-related code currently can only run on PyTorch 1.1
3. 运行
1)添加目录到python环境中
export PYTHONPATH=/home/cui/workspace/deepLearning/MotionNet:$PYTHONPATH
export PYTHONPATH=/home/cui/workspace/deepLearning/MotionNet/nuscenes-devkit/python-sdk:$PYTHONPATH
2)生成所需要的数据
cd data
python gen_data.py --root /home/cui/data/nuscenes/v1.0-mini/ --split train --savepath /home/cui/data/nuscenes/preprocess_data
参数说明:
--root: 数据存放地址
--split: 数据拆分类型,支持train/val/test
--savepath: 数据保存地址
生成过程中,会看到类似如下的打印信息
>> Finish sample: 32, sequence 0
>> Finish sample: 32, sequence 1
>> Finish sample: 33, sequence 0
注意:生成过程比较慢,若遇到问题,可以参考以下第4部分的Q1-Q7。
3)训练生成的数据
此步骤可以省略,官方提供 预训练模型下载:multi_seq 和 multi_seq_MGDA
- 训练时空一致性loss模型
python train_multi_seq.py --data /data/nuScenes_preprocessed --batch 8 --nepoch 45 --nworker 4 --use_bg_tc --reg_weight_bg_tc 0.1 --use_fg_tc --reg_weight_fg_tc 2.5 --use_sc --reg_weight_sc 15.0 --log
- 训练带有MGDA框架模型
// 1. 新建一个logs文件夹
cd MotionNet
mkdir logs
// 2. 训练,模型保存在logs/train_multi_seq/最后一个文件夹内,如epoch_10.pth
python train_multi_seq_MGDA.py --data /home/cui/data/nuscenes/preprocess_data/ --batch 2 --nepoch 10 --nworker 4 --use_bg_tc --reg_weight_bg_tc 0.1 --use_fg_tc --reg_weight_fg_tc 2.5 --use_sc --reg_weight_sc 15.0 --reg_weight_cls 2.0 --log --logpath ./logs
注意:出现问题可以参考Q8、Q9
4)评估模型
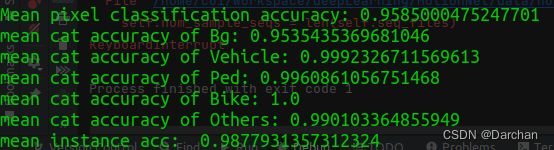
先使用第一步构建test_data测试数据,再运行评估脚本 eval.py
python eval.py --data /home/cui/data/nuscenes/test_data/ --model model/model.pth --split test --log . --bs 1 --net MotionNet
注意:可能会遇到问题,参考Q11
5)可视化
- 生成 .png 图像的预测结果
python plots.py --data /home/cui/data/nuscenes/v1.0-mini --version v1.0-mini --modelpath model/model.pth --net MotionNet --nframe 10 --savepath logs/gif
- 将生成的.png合成.gif 或者 .mp4
// 生成gif,保存位置logs/gif文件夹下,需要优先生成.png文件
python plots.py --data /home/cui/data/nuscenes/v1.0-mini --version v1.0-mini --modelpath model/model.pth --net MotionNet --nframe 10 --savepath logs/gif --video --format gif
// 生成MP4,保存位置logs/mp4文件夹下,需要优先生成.png文件
python plots.py --data /home/cui/data/nuscenes/v1.0-mini --version v1.0-mini --modelpath model/model.pth --net MotionNet --nframe 10 --savepath logs/mp4 --video --format mp4
参数说明:
--modelpath 模型存放地址
--net 使用网络名称
--nframe 生成多少帧
--savepath 保存地址
--format 生成的格式 mp4或者gif
注意:生成MP4,可能会出现问题,参考下面第4部分Q10.
4. 运行过程中问题:
- Q1:使用data/gen_data.py 脚本生成训练数据时候,ModuleNotFoundError: No module named ‘nuscenes’
解决:每一个终端都需要引入nuscenes-devkit工具包
export PYTHONPATH=/home/cui/workspace/deepLearning/MotionNet:$PYTHONPATH
export PYTHONPATH=/home/cui/workspace/deepLearning/MotionNet/nuscenes-devkit/python-sdk:$PYTHONPATH
- Q2:ModuleNotFoundError: No module named ‘pyquaternion’
解决:安装pyquaternion
pip install pyquaternion
- Q3:ModuleNotFoundError: No module named ‘cachetools’
pip install cachetools
- Q4:AssertionError: Database version not found: /home/cui/data/nuscenes/v1.0-mini/v1.0-trainval
解决:数据的version不对,因为使用的是mini的数据集,将gen_data.py 24行修改为,主要是version
nusc = NuScenes(version='v1.0-mini', dataroot=args.root, verbose=True)
- Q5:curr_scene = nusc.scene[scene_idx] ,IndexError: list index out of range
解决:nusc.scene中的只包含10个list,而scene_idx达到411 超限,故在for scene_idx in res_scenes: 之后添加
if scene_idx > len(nusc.scene):
continue
- Q6: AttributeError: type object ‘LidarPointCloud’ has no attribute ‘from_file_multisweep_bf_sample_data’
解决:原因是在单步调试模式下,没有引入Q1中的环境变量,编辑单步配置(Edit Configurations),添加Q1中的两行代码到Environment variables, 中间用;隔开,保存即可。
## 调整了一下代码中参数顺序,应该可以不调整
all_pc, all_times, trans_matrices = \
LidarPointCloud.from_file_multisweep_bf_sample_data(nusc, curr_sample_data,
nsweeps_back=nsweeps_back, nsweeps_forward=nsweeps_forward,
return_trans_matrix=True, min_distance=1.0)
-
Q7:FileNotFoundError: [Errno 2] No such file or directory: ‘/home/cui/data/nuscenes/preprocess_data/2_0’
解决:241行,会进行check_folder, 即文件夹检查,上面的目录下还未建立此文件夹。
在home/cui/data/nuscenes/ 目录下建立名字为preprocess_data 的空文件夹即可。 -
Q8: view size is not compatible with input tensor’s size and stride
解决:
参考:view size is not compatible with input tensor‘s size and stride
用多卡训练的时候tensor不连续,即tensor分布在不同的内存或显存中。
查找view,在前面加上contiguous(),如下train_multi_seq_MGDA.py文件,337行、466行
loss_disp = loss_disp.contiguous().view(map_shape[0], -1, map_shape[-3], map_shape[-2], map_shape[-1])
-
Q9:RuntimeError: CUDA out of memory. Tried to allocate 640.00 MiB (GPU 0; 5.79 GiB total capacity; 2.84 GiB already allocated; 502.94 MiB free; 3.46 GiB reserved in total by PyTorch)
解决:显卡显存太小,减少训练时的batch数目,–batch 2 -
Q10: 使用脚本生成mp4时,未看到保存的结果,且缺少库
解决:先安装imageio-ffmpeg库,plots.py修改如下两行代码,同时主要生成gif或者mp4需要先在同文件夹下生成.png图像,再执行生成gif或者mp4的脚本。
pip install imageio-ffmpeg
## plots.py修改内容
## 755行,添加
out_format = args.format
## 770行,修改为
gen_scene_prediction_video(args.savepath, args.savepath, out_format)
- Q11:使用eval脚本评估模型时候,实际数据test_data已经加载完成,但是执行评估脚本提示The number of test sequences: 0
解决:原因在于库中的一个函数有小问题,判断是否为测试数据是路径,库中判断是否为文件,具体修改3处地方:
参考:Problems training train_single_seq
## nuscenes_dataloader.py 文件中修改第171行:
if os.path.isdir(os.path.join(self.dataset_root, d))]
## nuscenes_dataloader.py 文件中修改第172、173行注释放开
seq_files = [os.path.join(seq_dir, f) for seq_dir in seq_dirs for f in os.listdir(seq_dir)
if os.path.isfile(os.path.join(seq_dir, f))]
## nuscenes_dataloader.py 文件中修改第175行:
self.seq_files = seq_files
顺利修改完,评估结果类似下图所示:
5. 结果
