Pytorch 语义分割DeepLabV3+ 训练自己的数据集
照葫芦画瓢总结记录了一下DeepLab分割系列,并对Deeplab V3++实现
一、DeepLab系列理解
1、DeepLab V1
原文:Semantic image segmentation with deep convolutional nets and fully connected CRFs(https://arxiv.org/pdf/1412.7062v3.pdf)
收录:ICLR 2015 (International Conference on Learning Representations)
Backbone: VGG16
Contributions:
Atrous convolution
CRF
DeepLab V1是基于VGG16网络改写的,一共做了三件事。
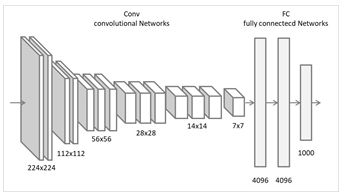
首先,去掉了最后的全连接层。做语义分割使用全卷积网络是大势所趋。
然后,去掉了最后两个池化层。池化层是神经网络中的一个经典结构,BP解决了神经网络训练的软件问题(权重更新),pooling解决了训练的硬件问题(对计算资源的需求)。这就是池化层的第一个作用,缩小特征层的尺寸。池化层还有另一个重要作用,快速扩大感受野。为什么要扩大感受野呢?为了利用更多的上下文信息进行分析。
在实验中发现 DCNNs 做语义分割时精准度不够的问题,根本原因是 DCNNs 的高级特征的平移不变性,即高层次特征映射,根源于重复的池化和下采样。
针对信号下采样或池化降低分辨率,DeepLab 采用的空洞卷积算法扩展感受野,获取更多的语境信息。
语义分割是一个end-to-end的问题,需要对每个像素进行精确的分类,对像素的位置很敏感,pooling是一个不断丢失位置信息的过程,而语义分割又需要这些信息,矛盾就产生了。没办法,只好去掉pooling喽。全去掉行不行,理论上是可行的,实际使用嘛,一来显卡没那么大的内存,二来费时间。所以只去掉了两层。
(PS:在DeepLab V1原文中,作者还指出一个问题,使用太多的pooling,特征层尺寸太小,包含的特征太稀疏了,不利于语义分割)
去了两个pooling,感受野又不够了怎么办?把atrous convolution借来用一下,这也是对VGG16的最后一个修改。atrous convolution人称空洞卷积(好像多称为dilation convolution),相比于传统卷积,可以在不增加计算量的情况下扩大感受野。

空洞卷积与传统卷积的区别在于,传统卷积是三连抽,感受野是3,空洞卷积是跳着抽,也就是使用图中的rate,感受野一下扩大到了5(rate=2),相当于两个传统卷积,而通过调整rate可以自由选择感受野。这样感受野的问题就解决了。
另外,原文指出,空洞卷积的优势在于增加了特征的密度。这张图你不能单独看,上边的传统卷积是经过pooling以后的第一个卷积层,而下边卷积输入的浅粉色三角正是被pooling掉的像素。所以,下边的输出是上边的两倍,特征多出了一倍。
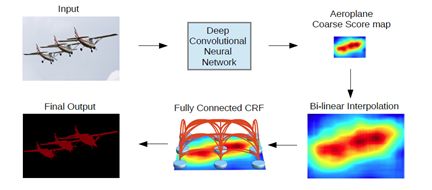
DeepLab V1的另一个贡献是使用条件随机场CRF提高分类精度。效果如下图,可以看到提升是非常明显的。具体CRF是什么原理呢?没有去研究,因为懒到了V3就舍弃了CRF。采用完全连接的条件随机场(CRF)提高模型捕获细节的能力,简单来说,就是对一个像素进行分类的时候,不仅考虑DCNN的输出,而且考虑该像素点周围像素点的值,这样语义分割结果边界清楚。
除空洞卷积和 CRFs 之外,论文使用的 tricks 还有 Multi-Scale features,与FCN skip layer类似,具体实现上,在输入图片与前四个 max pooling 后添加卷积层,这四个预测结果和模型输出拼接。
DeepLab V1的全流程图,其中上采样直接使用了双线性采样。
2、DeepLab V2
原文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs( https://arxiv.org/abs/1606.00915)
收录:TPAMI2017 (IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017)
Backbone:ResNet-101
Contributions:
ASPP
在DeepLab V2中,可能是觉得VGG16表达能力有限,于是大神换用了更复杂,表达能力更强的ResNet-101

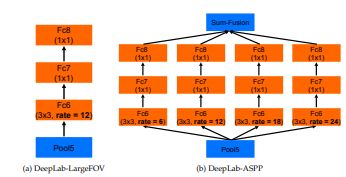
在V2中,大神同样对ResNet动了刀,刀法和V1相同。V2的贡献在于更加灵活的使用了atrous convolution,提出了空洞空间金字塔池化ASPP。还是先给图

ASPP的作用,说白了就是利用空洞卷积的优势,从不同的尺度上提取特征。这么做的原因也很简单,因为相同的事物在同一张图或不同图像中存在尺度上的差异。还是以这张图为例,图中的树存在多种尺寸,使用ASPP就能更好的对这些树进行分类。
至于ASPP如何融合到ResNet中,将VGG16的conv6,换成不同rate的空洞卷积,再跟上conv7,8,最后做个大融合(对应相加或1*1卷积)就OK了。
3、DeepLab V3
原文:Rethinking Atrous Convolution for Semantic Image Segmentation( https://arxiv.org/abs/1706.05587)
Backbone:ResNet-101
Contributions:
ASPP
Going deeper with atrous convolution
Remove CRF
舍弃了CRF,因为分类结果精度已经提高到不需要CRF了。
另外两个贡献,一个是改进了ASPP,另一个是使用空洞卷积加深网络,这两者算是一个二选一吧,是拓展网络的宽度,还是增加网络的深度。一般说起DeepLab V3模型指的是前者,因为从大神给出的结果和后续发展来看,明显前者效果更好一些。
对于ASPP,V3中做了两点改进。一是在空洞卷积之后使用batch normalization,对训练很有帮助。第二点是增加了 1 ∗ 1 1*1 1∗1卷积分支和image pooling分支。增加这两个分支是为了解决使用空洞卷积带来的问题,随着rate的增大,一次空洞卷积覆盖到的有效像素(特征层本身的像素,相应的补零像素为非有效像素)会逐渐减小到1。这就与我们的初衷(获取更大范围的特征)相背离了。所以为了解决这个问题,一是使用 1 ∗ 1 1*1 1∗1的卷积,也就是当rate增大以后 3 ∗ 3 3*3 3∗3卷积的退化形式,替代 3 ∗ 3 3*3 3∗3卷积,减少参数个数;另一点就是增加image pooling,可以叫做全局池化,来补充全局特征。具体做法是对每一个通道的像素取平均,之后再上采样到原来的分辨率。
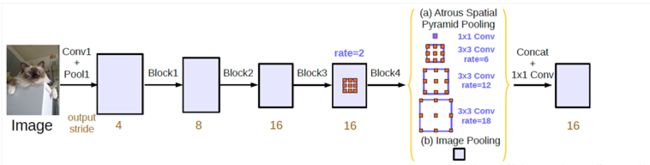
ASPP的变化就这么多,再来简单说说另一种思路Going deeper with atrous convolution。为什么要加深网络呢,我理解的是为了获取更大的感受野。提到感受野自然离不开空洞卷积。还是看图说话,很显然pooling用多了特征层都快小的看不见了,所以大神给出了使用空洞卷积不断加深网络的一种思路。
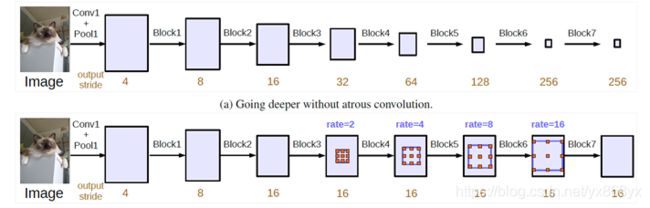
4、DeepLab V3+
原文:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation( https://arxiv.org/abs/1802.02611)
Backbone:Xception
Contributions:
Xception
Encoder-decoder structure
DeepLab V3+再次修改了主网络,将ResNet-101升级到了Xception。在原始的Xception的基础上,大神进行了三点修改:
(1)使用更深的网络;
(2)将所有的卷积层和池化层用深度分离卷积Depthwise separable convolution进行替代,也就是下图中的Sep Conv;
(3)在每一次3*3 depthwise convolution之后使用BN和ReLU。
因为V3+使用深度分离卷积替代了pooling,那么为了缩小特征层尺寸,有几个block的最后一层的stride就必须为2,也就是下图中标红的层。具体有几个取决于输出output stride(下采样的大小)的设置。

Xception的核心是使用了Depthwise separable convolution。Depthwise separable convolution的思想来自inception结构,是inception结构的一种极限情况。Inception 首先给出了一种假设:卷积层通道间的相关性和空间相关性是可以退耦合的,将它们分开映射,能达到更好的效果。在inception结构中,先对输入进行 1 ∗ 1 1*1 1∗1的卷积,之后将通道分组,分别使用不同的 3 ∗ 3 3*3 3∗3卷积提取特征,最后将各组结果串联在一起作为输出。
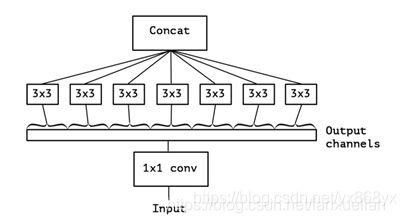
Depthwise separable convolution是将这种分组演化到了极致,即把每一个通道作为一组。先对输入的每一个通道做 3 ∗ 3 3*3 3∗3的卷积,将各个通道的结果串联后,再通过 1 ∗ 1 1*1 1∗1的卷积调整到目标通道数。

使用depthwise separable convolution的好处。好处也很简单,大幅缩减参数个数。假设输入输出都是64通道,卷积核采用3*3,那么传统卷积的参数个数为
3∗3∗64∗64=36864
而Depthwise separable convolution为
3 ∗ 3 ∗ 64 + 1 ∗ 1 ∗ 64 ∗ 64 = 4672 3364+1164*64=4672
3∗3∗64+1∗1∗64∗64=4672
说完了backbone,再来说说V3+的整体结构。前三个版本都是backbone(ASPP)输出的结果直接双线性上采样到原始分辨率,非常简单粗暴的方法,下图中的(a)。用了三个版本,大神也觉得这样做太粗糙了,于是吸取Encoder-Deconder的结构,下图中的(b),增加了一个浅层到输出的skip层,下图中的( c)。
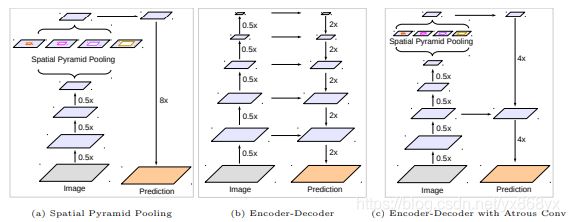
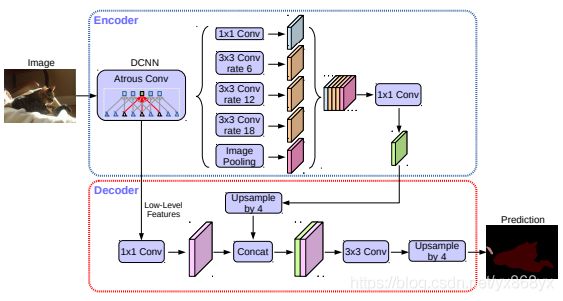
具体的skip方法。首先,选取block2中的第二个卷积输出(看代码这个是固定的),使用 1 ∗ 1 1*1 1∗1卷积调整通道数到48(减小通道数是为了降低其在最终结果中的比重),然后resize到指定的尺寸,也就是output stride。然后,将ASPP的输出resize到output stride。最后将两部分串联起来做两次 3 ∗ 3 3*3 3∗3的卷积。最后的最后再做一次1*1的卷积,得到分类结果。最后的最后的最后将分类结果resize到原来的分辨率,采用双线性采样。
完整的流程图:
二、DeepLabV3+实现(cuda9.0,pytorch1.5)
1、数据:
之前用labellme打过标签的Abyssinian数据集
如何制作分割数据集见:https://blog.csdn.net/yx868yx/article/details/105641947(标注、生成label.png) 和
https://blog.csdn.net/yx868yx/article/details/105642324(所有json文件夹中提取所有的label.png图片)
数据集形式:
| ImageSets | Segmentation(train.txt,val.txt) | ||
|---|---|---|---|
| VOCdevkit | Abyssinian | JPEGImages | 训练和验证的图片 |
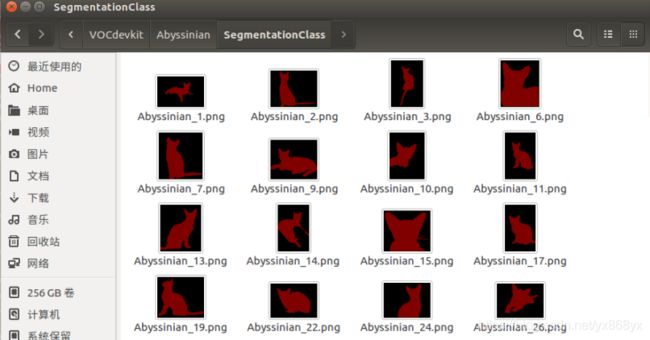
| SegmentationClass | 训练和验证的mask图片 |
如图:
2、环境配置:
环境 ubantu16.04+cudnn7.0+cuda_9.0.176
Pytorch 1.5.1
3、clone工程: https://github.com/jfzhang95/pytorch-deeplab-xception
4、修改mypath.py
添加上自己的数据集名字和所在的路径。代码如下
class Path(object):
@staticmethod
def db_root_dir(dataset):
if dataset == 'pascal':
return '/path/to/datasets/VOCdevkit/VOC2012/' # folder that contains VOCdevkit/.
elif dataset == 'sbd':
return '/path/to/datasets/benchmark_RELEASE/' # folder that contains dataset/.
elif dataset == 'cityscapes':
return '/path/to/datasets/cityscapes/' # foler that contains leftImg8bit/
elif dataset == 'coco':
return '/path/to/datasets/coco/'
#添加我自己制作的Abyssinian数据集
elif dataset == 'Abyssinian':
return '/home/yuxin/pytorch-deeplab-xception-master/VOCdevkit/Abyssinian'
else:
print('Dataset {} not available.'.format(dataset))
raise NotImplementedError
5 、创建Abyssinian.py文件
然后在dataloaders/datasets路径下创建自己的数据集文件,这里创建为Abyssinian.py,因为我们是按照VOC数据集格式,所以直接将pascal.py内容复制过来修改,这里将类别数和数据集改成自己的数据集,类别记得加上背景类,我这里一共是2类:
from __future__ import print_function, division
import os
from PIL import Image
import numpy as np
from torch.utils.data import Dataset
from mypath import Path
from torchvision import transforms
from dataloaders import custom_transforms as tr
class VOCSegmentation(Dataset):
"""
PascalVoc dataset
"""
#Abyssinian类和背景类
NUM_CLASSES = 2
def __init__(self,
args,
#修改为Abyssinian
base_dir=Path.db_root_dir('Abyssinian'),
split='train',
):
"""
:param base_dir: path to VOC dataset directory
:param split: train/val
:param transform: transform to apply
"""
super().__init__()
self._base_dir = base_dir
self._image_dir = os.path.join(self._base_dir, 'JPEGImages')
self._cat_dir = os.path.join(self._base_dir, 'SegmentationClass')
if isinstance(split, str):
self.split = [split]
else:
split.sort()
self.split = split
self.args = args
_splits_dir = os.path.join(self._base_dir, 'ImageSets', 'Segmentation')
self.im_ids = []
self.images = []
self.categories = []
for splt in self.split:
with open(os.path.join(os.path.join(_splits_dir, splt + '.txt')), "r") as f:
lines = f.read().splitlines()
for ii, line in enumerate(lines):
_image = os.path.join(self._image_dir, line + ".jpg")
_cat = os.path.join(self._cat_dir, line + ".png")
assert os.path.isfile(_image)
assert os.path.isfile(_cat)
self.im_ids.append(line)
self.images.append(_image)
self.categories.append(_cat)
assert (len(self.images) == len(self.categories))
# Display stats
print('Number of images in {}: {:d}'.format(split, len(self.images)))
def __len__(self):
return len(self.images)
def __getitem__(self, index):
_img, _target = self._make_img_gt_point_pair(index)
sample = {'image': _img, 'label': _target}
for split in self.split:
if split == "train":
return self.transform_tr(sample)
elif split == 'val':
return self.transform_val(sample)
def _make_img_gt_point_pair(self, index):
_img = Image.open(self.images[index]).convert('RGB')
_target = Image.open(self.categories[index])
return _img, _target
def transform_tr(self, sample):
composed_transforms = transforms.Compose([
tr.RandomHorizontalFlip(),
tr.RandomScaleCrop(base_size=self.args.base_size, crop_size=self.args.crop_size),
tr.RandomGaussianBlur(),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
return composed_transforms(sample)
def transform_val(self, sample):
composed_transforms = transforms.Compose([
tr.FixScaleCrop(crop_size=self.args.crop_size),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
return composed_transforms(sample)
def __str__(self):
return 'VOC2012(split=' + str(self.split) + ')'
if __name__ == '__main__':
from dataloaders.utils import decode_segmap
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import argparse
parser = argparse.ArgumentParser()
args = parser.parse_args()
args.base_size = 513
args.crop_size = 513
voc_train = VOCSegmentation(args, split='train')
dataloader = DataLoader(voc_train, batch_size=5, shuffle=True, num_workers=0)
for ii, sample in enumerate(dataloader):
for jj in range(sample["image"].size()[0]):
img = sample['image'].numpy()
gt = sample['label'].numpy()
tmp = np.array(gt[jj]).astype(np.uint8)
segmap = decode_segmap(tmp, dataset='pascal')
img_tmp = np.transpose(img[jj], axes=[1, 2, 0])
img_tmp *= (0.229, 0.224, 0.225)
img_tmp += (0.485, 0.456, 0.406)
img_tmp *= 255.0
img_tmp = img_tmp.astype(np.uint8)
plt.figure()
plt.title('display')
plt.subplot(211)
plt.imshow(img_tmp)
plt.subplot(212)
plt.imshow(segmap)
if ii == 1:
break
plt.show(block=True)
6、修改dataloaders/utils.py
在文件中创建一个get_Abyssinian_labels()函数,根据自己的类别数,我这里只有两类,一类是背景,一类是我要分割的类,所以只定义了两种mask颜色
from __future__ import print_function, division
import os
from PIL import Image
import numpy as np
from torch.utils.data import Dataset
from mypath import Path
from torchvision import transforms
from dataloaders import custom_transforms as tr
import matplotlib.pyplot as plt
import numpy as np
import torch
def decode_seg_map_sequence(label_masks, dataset='pascal'):
rgb_masks = []
for label_mask in label_masks:
rgb_mask = decode_segmap(label_mask, dataset)
rgb_masks.append(rgb_mask)
rgb_masks = torch.from_numpy(np.array(rgb_masks).transpose([0, 3, 1, 2]))
return rgb_masks
def decode_segmap(label_mask, dataset, plot=False):
"""Decode segmentation class labels into a color image
Args:
label_mask (np.ndarray): an (M,N) array of integer values denoting
the class label at each spatial location.
plot (bool, optional): whether to show the resulting color image
in a figure.
Returns:
(np.ndarray, optional): the resulting decoded color image.
"""
if dataset == 'pascal' or dataset == 'coco':
n_classes = 21
label_colours = get_pascal_labels()
elif dataset == 'cityscapes':
n_classes = 19
label_colours = get_cityscapes_labels()
#添加Abyssinian
elif dataset ==‘Abyssinian':
n_classes = 2
label_colours = get_Abyssinian_labels()
else:
raise NotImplementedError
r = label_mask.copy()
g = label_mask.copy()
b = label_mask.copy()
for ll in range(0, n_classes):
r[label_mask == ll] = label_colours[ll, 0]
g[label_mask == ll] = label_colours[ll, 1]
b[label_mask == ll] = label_colours[ll, 2]
rgb = np.zeros((label_mask.shape[0], label_mask.shape[1], 3))
rgb[:, :, 0] = r / 255.0
rgb[:, :, 1] = g / 255.0
rgb[:, :, 2] = b / 255.0
if plot:
plt.imshow(rgb)
plt.show()
else:
return rgb
def encode_segmap(mask):
"""Encode segmentation label images as pascal classes
Args:
mask (np.ndarray): raw segmentation label image of dimension
(M, N, 3), in which the Pascal classes are encoded as colours.
Returns:
(np.ndarray): class map with dimensions (M,N), where the value at
a given location is the integer denoting the class index.
"""
mask = mask.astype(int)
label_mask = np.zeros((mask.shape[0], mask.shape[1]), dtype=np.int16)
for ii, label in enumerate(get_pascal_labels()):
label_mask[np.where(np.all(mask == label, axis=-1))[:2]] = ii
label_mask = label_mask.astype(int)
return label_mask
def get_cityscapes_labels():
return np.array([
[128, 64, 128],
[244, 35, 232],
[70, 70, 70],
[102, 102, 156],
[190, 153, 153],
[153, 153, 153],
[250, 170, 30],
[220, 220, 0],
[107, 142, 35],
[152, 251, 152],
[0, 130, 180],
[220, 20, 60],
[255, 0, 0],
[0, 0, 142],
[0, 0, 70],
[0, 60, 100],
[0, 80, 100],
[0, 0, 230],
[119, 11, 32]])
def get_pascal_labels():
"""Load the mapping that associates pascal classes with label colors
Returns:
np.ndarray with dimensions (21, 3)
"""
return np.asarray([[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]])
#添加get_Abyssinian_labels()函数
def get_Abyssinian_labels():
return np.asarray([
[0, 0, 0],
[128, 0, 0]])
7、修改__init__.py
from dataloaders.datasets import cityscapes, coco, combine_dbs, pascal, sbd
from torch.utils.data import DataLoader
def make_data_loader(args, **kwargs):
if args.dataset == 'pascal':
train_set = pascal.VOCSegmentation(args, split='train')
val_set = pascal.VOCSegmentation(args, split='val')
if args.use_sbd:
sbd_train = sbd.SBDSegmentation(args, split=['train', 'val'])
train_set = combine_dbs.CombineDBs([train_set, sbd_train], excluded=[val_set])
num_class = train_set.NUM_CLASSES
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, **kwargs)
val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, **kwargs)
test_loader = None
return train_loader, val_loader, test_loader, num_class
elif args.dataset == 'cityscapes':
train_set = cityscapes.CityscapesSegmentation(args, split='train')
val_set = cityscapes.CityscapesSegmentation(args, split='val')
test_set = cityscapes.CityscapesSegmentation(args, split='test')
num_class = train_set.NUM_CLASSES
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, **kwargs)
val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, **kwargs)
test_loader = DataLoader(test_set, batch_size=args.batch_size, shuffle=False, **kwargs)
return train_loader, val_loader, test_loader, num_class
elif args.dataset == 'coco':
train_set = coco.COCOSegmentation(args, split='train')
val_set = coco.COCOSegmentation(args, split='val')
num_class = train_set.NUM_CLASSES
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, **kwargs)
val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, **kwargs)
test_loader = None
return train_loader, val_loader, test_loader, num_class
#添加Abyssinian
elif args.dataset == 'Abyssinian':
train_set = pascal.VOCSegmentation(args, split='train')
val_set = pascal.VOCSegmentation(args, split='val')
'''
if args.use_sbd:
sbd_train = sbd.SBDSegmentation(args, split=['train', 'val'])
train_set = combine_dbs.CombineDBs([train_set, sbd_train], excluded=[val_set])
'''
num_class = train_set.NUM_CLASSES
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, **kwargs)
val_loader = DataLoader(val_set, batch_size=args.batch_size, shuffle=False, **kwargs)
test_loader = None
return train_loader, val_loader, test_loader, num_class
else:
raise NotImplementedError
8、修改train.py
在这个程序中,作者提供了四种的backbone,分别是:resnet、xception、drn、mobilenet,并且提供了预训练权重,在训练开始时会自动下载,可以根据自己电脑的配置进行选择,如果配置稍微差一点的话建议使用mobilenet作为backbone,在训练开始之前,打开train文件,在这里把自己的类别添加上去:
main函数的部分程序:
def main():
parser = argparse.ArgumentParser(description="PyTorch DeeplabV3Plus Training")
parser.add_argument('--backbone', type=str, default='resnet',
choices=['resnet', 'xception', 'drn', 'mobilenet'],
help='backbone name (default: resnet)')
parser.add_argument('--out-stride', type=int, default=16,
help='network output stride (default: 8)')
#添加Abyssinian
parser.add_argument('--dataset', type=str, default='pascal',
choices=['pascal', 'coco', 'cityscapes','Abyssinian'],
help='dataset name (default: pascal)')
parser.add_argument('--use-sbd', action='store_true', default=True,
help='whether to use SBD dataset (default: True)'
9、训练
在终端运行命令:
python train.py --backbone mobilenet --lr 0.007 --workers 1 --epochs 50 --batch-size 8 --gpu-ids 0 --checkname deeplab-mobilenet --dataset Abyssinian
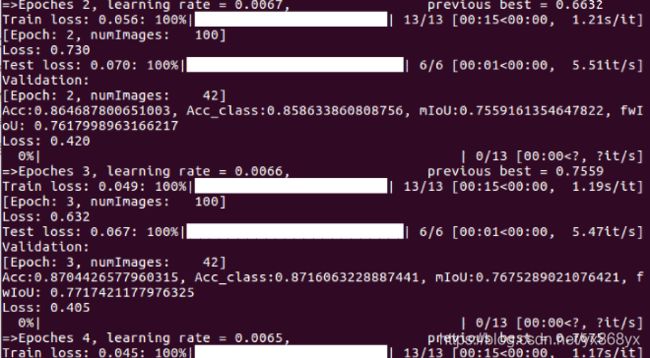

每个轮次训练完后都会对验证集进行评估,会按照mIOU最优结果进行模型的保存,最后的模型的训练结果会保存在run文件夹中:
10、测试
添加测试代码:
#
# demo.py
#
import argparse
import os
import numpy as np
import time
from modeling.deeplab import *
from dataloaders import custom_transforms as tr
from PIL import Image
from torchvision import transforms
from dataloaders.utils import *
from torchvision.utils import make_grid, save_image
def main():
parser = argparse.ArgumentParser(description="PyTorch DeeplabV3Plus Training")
parser.add_argument('--in-path', type=str, required=True, help='image to test')
# parser.add_argument('--out-path', type=str, required=True, help='mask image to save')
parser.add_argument('--backbone', type=str, default='resnet',
choices=['resnet', 'xception', 'drn', 'mobilenet'],
help='backbone name (default: resnet)')
parser.add_argument('--ckpt', type=str, default='deeplab-resnet.pth',
help='saved model')
parser.add_argument('--out-stride', type=int, default=16,
help='network output stride (default: 8)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--gpu-ids', type=str, default='0',
help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')
parser.add_argument('--dataset', type=str, default='pascal',
choices=['pascal', 'coco', 'cityscapes','invoice'],
help='dataset name (default: pascal)')
parser.add_argument('--crop-size', type=int, default=513,
help='crop image size')
parser.add_argument('--num_classes', type=int, default=2,
help='crop image size')
parser.add_argument('--sync-bn', type=bool, default=None,
help='whether to use sync bn (default: auto)')
parser.add_argument('--freeze-bn', type=bool, default=False,
help='whether to freeze bn parameters (default: False)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
if args.sync_bn is None:
if args.cuda and len(args.gpu_ids) > 1:
args.sync_bn = True
else:
args.sync_bn = False
model_s_time = time.time()
model = DeepLab(num_classes=args.num_classes,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=args.sync_bn,
freeze_bn=args.freeze_bn)
ckpt = torch.load(args.ckpt, map_location='cpu')
model.load_state_dict(ckpt['state_dict'])
model = model.cuda()
model_u_time = time.time()
model_load_time = model_u_time-model_s_time
print("model load time is {}".format(model_load_time))
composed_transforms = transforms.Compose([
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
for name in os.listdir(args.in_path):
s_time = time.time()
image = Image.open(args.in_path+"/"+name).convert('RGB')
# image = Image.open(args.in_path).convert('RGB')
target = Image.open(args.in_path+"/"+name).convert('L')
sample = {'image': image, 'label': target}
tensor_in = composed_transforms(sample)['image'].unsqueeze(0)
model.eval()
if args.cuda:
tensor_in = tensor_in.cuda()
with torch.no_grad():
output = model(tensor_in)
grid_image = make_grid(decode_seg_map_sequence(torch.max(output[:3], 1)[1].detach().cpu().numpy()),
3, normalize=False, range=(0, 255))
save_image(grid_image,args.in_path+"/"+"{}_mask.png".format(name[0:-4]))
u_time = time.time()
img_time = u_time-s_time
print("image:{} time: {} ".format(name,img_time))
# save_image(grid_image, args.out_path)
# print("type(grid) is: ", type(grid_image))
# print("grid_image.shape is: ", grid_image.shape)
print("image save in in_path.")
if __name__ == "__main__":
main()
# python demo.py --in-path your_file --out-path your_dst_file
在终端运行:
python demo.py --in-path /home/yuxin/pytorch-deeplab-xception-master/test_pic --ckpt run/Abyssinian/deeplab-mobilenet/model_best.pth.tar --backbone mobilenet
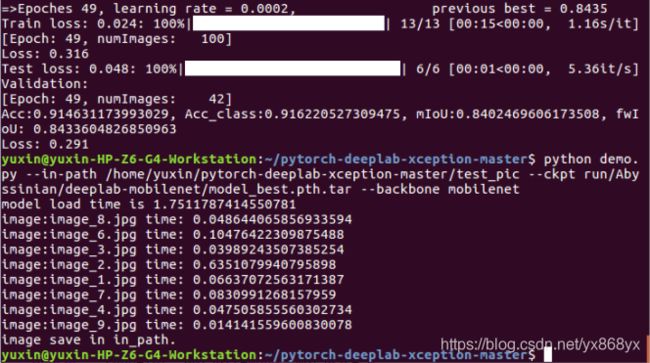
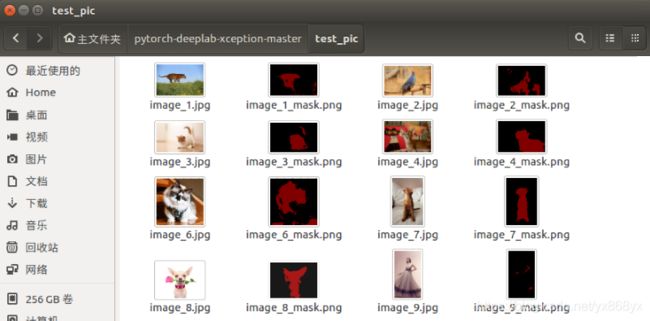
效果如下图:
参考:
https://blog.csdn.net/fanxuelian/article/details/85145558
https://www.jianshu.com/p/026c5d78d3b1
https://blog.csdn.net/qq_39056987/article/details/106455828
https://blog.csdn.net/weixin_41919571/article/details/107906066 等