一、prim算法
时间复杂度较之kruskal较高


通俗的解释就是:
(1)从哪个点开始生成最小生成树都一样,最后的权值都是相同的
(2)从哪个点开始,先标记这个点是访问过的,用visited数组表示所有节点的访问情况
(3)访问节点开始都每个没访问结点的距离选取形成的边的权值最小值
综合以上三点就是我们prim算法写代码实现的重要思路
代码实现:
package Prim;
import java.util.Arrays;
public class PrimAlgorithm {
public static void main(String[] args) {
//测试看看图是否创建ok
char[] data = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
int verxs = data.length;
//邻接矩阵的关系使用二维数组表示,10000这个大数,表示两个点不联通
int[][] weight = new int[][]{
{10000, 5, 7, 10000, 10000, 10000, 2},
{5, 10000, 10000, 9, 10000, 10000, 3},
{7, 10000, 10000, 10000, 8, 10000, 10000},
{10000, 9, 10000, 10000, 10000, 4, 10000},
{10000, 10000, 8, 10000, 10000, 5, 4},
{10000, 10000, 10000, 4, 5, 10000, 6},
{2, 3, 10000, 10000, 4, 6, 10000},};
MGraph mGraph = new MGraph(verxs);
MinTree minTree = new MinTree();
minTree.createGraph(mGraph, verxs, data, weight);
minTree.showGraph(mGraph);
minTree.Prim(mGraph, 0);
}
}
class MinTree {
/**
* 创造图
* @param graph 图对象
* @param verxs 图节点个数
* @param data 图每个顶点的数据值
* @param weight 图的边(邻接矩阵)
*/
public void createGraph(MGraph graph, int verxs, char[] data, int[][] weight) {
int i, j;
for (i = 0; i < verxs; i++) {
graph.data[i] = data[i];
for (j = 0; j < verxs; j++) {
graph.weight[i][j] = weight[i][j];
}
}
}
// 显示图的邻接矩阵
public void showGraph(MGraph graph) {
for (int[] link : graph.weight) {
System.out.println(Arrays.toString(link));
}
}
/**
* 编写prim算法
*
* @param graph 图对象
* @param v 从哪个节点开始生成最小生成树
*/
public void Prim(MGraph graph, int v) {
//定义一个数组,判断节点是不是被访问过了
int[] visited = new int[graph.verxs];
//v这个点已经被访问了,从这个点开始访问
visited[v] = 1;
//找到节点下标
int h1 = -1;
int h2 = -1;
int minWeight = 10000;//定义初始值为最大值,只要出现小的就会替换
int sum = 0;
// 从1开始循环,相当于就是生成graph.verx - 1条边
for (int k = 1; k < graph.verxs; k++) {
for (int i = 0; i < graph.verxs; i++) {//遍历已经访问过的点
if (visited[i] == 1){
for (int j = 0; j < graph.verxs; j++) {//遍历没有访问过的点
//在未访问点中寻找所有与访问过的点相连的边中权值最小值
if (visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight) {
minWeight = graph.weight[i][j];
h1 = i;
h2 = j;
}
}
}
}
sum += minWeight; // 求最小生成熟的总权值
//此时已经找到一条边是最小了
System.out.println("边<" + graph.data[h1] + "," + graph.data[h2] + "> 权值:" + minWeight);
//然后标记点
visited[h2] = 1;
//将权值重新变成最大值
minWeight = 10000;
}
System.out.println("最小生成树的权值是:" + sum);
}
}
// 图
class MGraph {
int verxs; // 表示图节点个数
char[] data; // 表示节点数据
int[][] weight; // 表示边
public MGraph(int verxs) {
this.verxs = verxs;
data = new char[verxs];
weight = new int[verxs][verxs];
}
}
二、kruskal算法
时间复杂度低一些,但是代码量会大一些
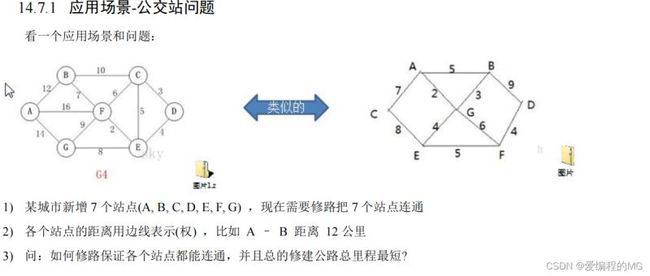


对克鲁斯卡尔算法的通俗解释:
(1)对每条边的权值进行排序
(2)按照从小到大依次选取边构成最小生成树,但是要注意是否构成回路,树的概念是不能生成回路
(3)此处用的方法比较巧妙使用了getEnd方法来判断两者终点是不是一样,用ends数组保存最小生成树中每个顶点的终点
代码实现:
package Kruskal;
import java.util.Arrays;
public class KruskalCase {
private int edgeNum; //边的个数
private char[] vertexs; //顶点数组
private int[][] matrix; //邻接矩阵
//使用 INF 表示两个顶点不能连通
private static final int INF = Integer.MAX_VALUE;
public static void main(String[] args) {
char[] vertexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
//克鲁斯卡尔算法的邻接矩阵
int matrix[][] = {
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ {0, 12, INF, INF, INF, 16, 14},
/*B*/ {12, 0, 10, INF, INF, 7, INF},
/*C*/ {INF, 10, 0, 3, 5, 6, INF},
/*D*/ {INF, INF, 3, 0, 4, INF, INF},
/*E*/ {INF, INF, 5, 4, 0, 2, 8},
/*F*/ {16, 7, 6, INF, 2, 0, 9},
/*G*/ {14, INF, INF, INF, 8, 9, 0}};
//大家可以在去测试其它的邻接矩阵,结果都可以得到最小生成树.
//创建KruskalCase 对象实例
KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);
//输出构建的
kruskalCase.print();
kruskalCase.kruskal();
}
//构造器
public KruskalCase(char[] vertexs, int[][] matrix) {
//初始化顶点数和边的个数
int vlen = vertexs.length;
//初始化顶点, 复制拷贝的方式
this.vertexs = new char[vlen];
for (int i = 0; i < vertexs.length; i++) {
this.vertexs[i] = vertexs[i];
}
//初始化边, 使用的是复制拷贝的方式
this.matrix = new int[vlen][vlen];
for (int i = 0; i < vlen; i++) {
for (int j = 0; j < vlen; j++) {
this.matrix[i][j] = matrix[i][j];
}
}
//统计边的条数
for (int i = 0; i < vlen; i++) {
for (int j = i + 1; j < vlen; j++) {
if (this.matrix[i][j] != INF) {
edgeNum++;
}
}
}
}
public void kruskal() {
int index = 0; //表示最后结果数组的索引
int[] ends = new int[edgeNum]; //用于保存"已有最小生成树" 中的每个顶点在最小生成树中的终点
//创建结果数组, 保存最后的最小生成树
EData[] rets = new EData[edgeNum];
//获取图中 所有的边的集合 , 一共有12边
EData[] edges = getEdges();
System.out.println("图的边的集合=" + Arrays.toString(edges) + " 共" + edges.length); //12
//按照边的权值大小进行排序(从小到大)
sortEdges(edges);
//遍历edges 数组,将边添加到最小生成树中时,判断是准备加入的边否形成了回路,如果没有,就加入 rets, 否则不能加入
for (int i = 0; i < edgeNum; i++) {
//获取到第i条边的第一个顶点(起点)
int p1 = getPosition(edges[i].start); //p1=4
//获取到第i条边的第2个顶点
int p2 = getPosition(edges[i].end); //p2 = 5
//获取p1这个顶点在已有最小生成树中的终点
int m = getEnd(ends, p1); //m = 4
//获取p2这个顶点在已有最小生成树中的终点
int n = getEnd(ends, p2); // n = 5
//是否构成回路
if (m != n) { //没有构成回路
ends[m] = n; // 设置m 在"已有最小生成树"中的终点 [0,0,0,0,5,0,0,0,0,0,0,0]
rets[index++] = edges[i]; //有一条边加入到rets数组
}
}
// 。
//统计并打印 "最小生成树", 输出 rets
System.out.println("最小生成树为");
for (int i = 0; i < index; i++) {
System.out.println(rets[i]);
}
}
//打印邻接矩阵
public void print() {
System.out.println("邻接矩阵为: \n");
for (int i = 0; i < vertexs.length; i++) {
for (int j = 0; j < vertexs.length; j++) {
System.out.printf("%12d", matrix[i][j]);
}
System.out.println();//换行
}
}
/**
* 功能:对边进行排序处理, 冒泡排序
*
* @param edges 边的集合
*/
private void sortEdges(EData[] edges) {
for (int i = 0; i < edges.length - 1; i++) {
for (int j = 0; j < edges.length - 1 - i; j++) {
if (edges[j].weight > edges[j + 1].weight) {//交换
EData tmp = edges[j];
edges[j] = edges[j + 1];
edges[j + 1] = tmp;
}
}
}
}
/**
* @param ch 顶点的值,比如'A','B'
* @return 返回ch顶点对应的下标,如果找不到,返回-1
*/
private int getPosition(char ch) {
for (int i = 0; i < vertexs.length; i++) {
if (vertexs[i] == ch) {//找到
return i;
}
}
//找不到,返回-1
return -1;
}
/**
* 功能: 获取图中边,放到EData[] 数组中,后面我们需要遍历该数组
* 是通过matrix 邻接矩阵来获取
* EData[] 形式 [['A','B', 12], ['B','F',7], .....]
*
* @return
*/
private EData[] getEdges() {
int index = 0;
EData[] edges = new EData[edgeNum];
for (int i = 0; i < vertexs.length; i++) {
for (int j = i + 1; j < vertexs.length; j++) {
if (matrix[i][j] != INF) {
edges[index++] = new EData(vertexs[i], vertexs[j], matrix[i][j]);
}
}
}
return edges;
}
/**
* 功能: 获取下标为i的顶点的终点(), 用于后面判断两个顶点的终点是否相同
*
* @param ends : 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成
* @param i : 表示传入的顶点对应的下标
* @return 返回的就是 下标为i的这个顶点对应的终点的下标, 一会回头还有来理解
*/
private int getEnd(int[] ends, int i) { // i = 4 [0,0,0,0,5,0,0,0,0,0,0,0]
while (ends[i] != 0) {
i = ends[i];
}
return i;
}
}
//创建一个类EData ,它的对象实例就表示一条边
class EData {
char start; //边的一个点
char end; //边的另外一个点
int weight; //边的权值
//构造器
public EData(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
//重写toString, 便于输出边信息
@Override
public String toString() {
return "EData [<" + start + ", " + end + ">= " + weight + "]";
}
}
到此这篇关于Java实现最小生成树MST的两种解法的文章就介绍到这了,更多相关Java最小生成树内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!