caffe模型训练与使用极简版(windows平台)
前言
本文训练模型是在 windows 系统上完成的,在训练模型之前,需要在自己的设备上编译好 caffe 。
windows 下编译 caffe 的教程:https://blog.csdn.net/apple_54470279/article/details/124993901
为了避免不必要的错误,请在桌面上新建一个文件夹【项目文件夹】,用来存放本次训练的所有文件。
建议大家把 caffe-windows 安装在 D盘 根目录,这样就不需要频繁更改路径!
获取数据集
在项目文件夹中新建一个 sources 文件夹用来保存数据源,准备好相应的图片。本文用来训练的图片是从网上下载的牵牛花、玫瑰花和向日葵各100张,分别保存在morning glory 、rose 、sunflower 文件夹中。当然,文件夹可以根据图片类型命名,目录结构如下:
准备工作
准备工作的任务:
- 重命名图片
- 将所有图片分成训练集和测试集
- 生成 .txt 格式的图片标签文件
- 将图片转换为 lmdb 格式
- 准备 .prototxt 文件
- 生成 .binaryproto 和 .npy 格式的均值文件
这一步可以通过 Python 代码来完成,在根目录下新建 prepare.py 文件,复制以下代码(需要对程序开头的部分路径进行修改):
'''
初始化程序
'''
import os
import re
import numpy as np
import caffe
from shutil import copyfile
# 获取当前根目录
root = os.getcwd()
# 获取数据源
sources = root + "\\sources"
# .prototxt 文件所在位置(改为自己本地对应的路径)
train_proto = r"D:\caffe-windows\models\bvlc_reference_caffenet\train_val.prototxt"
deploy_proto = r"D:\caffe-windows\models\bvlc_reference_caffenet\deploy.prototxt"
solver_proto = r"D:\caffe-windows\models\bvlc_reference_caffenet\solver.prototxt"
# convert_imageset.exe 程序路径(改为自己本地对应的路径)
imageset_exe = r"D:\caffe-windows\scripts\build\tools\Release\convert_imageset.exe"
# compute_image_mean.exe 程序路径(改为自己本地对应的路径)
imagemean_exe = r"D:\caffe-windows\scripts\build\tools\Release\compute_image_mean.exe"
# caffe.exe 程序路径(改为自己本地对应的路径)
caffe_exe = r"D:\caffe-windows\scripts\build\tools\Release\caffe.exe"
def main():
# 获取数据源中的分类数据
source_list = os.listdir(sources)
if len(source_list) == 0:
print("No sourses!")
return 0
# 对数据源中的图片进行重命名
print("图片重命名中...")
for item in source_list:
img_path = "{}\\{}\\".format(sources, item)
mark = item[:3]
rename(img_path, mark)
# 数据集划分
for item in source_list:
img_path = "{}\\{}\\".format(sources, item)
dataset_cut(img_path)
print("训练集共 {} 张图片。".format(len(os.listdir(root + "\\data\\train"))))
print("测试集共 {} 张图片。".format(len(os.listdir(root + "\\data\\test"))))
print("数据集划分完成!")
# 生成图片标签
dir_path = root + "\data"
create_label("train", dir_path)
create_label("test", dir_path)
labels_path = root + "\data\labels.txt"
with open(labels_path, 'w') as f:
i = 0
for item in source_list:
f.writelines('{} {}\n'.format(i, item.replace(' ', '_')))
i += 1
print("生成 labels.txt 文件...")
# 创建 models 文件夹
print("生成 models 文件夹...")
os.makedirs(root + "\\data\\models", exist_ok=True)
# 创建 CaffeNet 文件夹
print("生成 CaffeNet 文件夹...")
os.makedirs(root + "\\data\\CaffeNet", exist_ok=True)
# 创建 img_test 文件夹
print("生成 img_test 文件夹...")
os.makedirs(root + "\\img_test", exist_ok=True)
# 写入 .prototxt 文件
if os.path.exists(root + "\\data\\CaffeNet\\train_val.prototxt"):
print("train_val.prototxt文件已存在...")
else:
print("生成 train_val.prototxt 文件...")
copyfile(train_proto, root + "\\data\\CaffeNet\\train_val.prototxt")
if os.path.exists(root + "\\data\\CaffeNet\\deploy.prototxt"):
print("deploy.prototxt 文件已存在...")
else:
print("生成 deploy.prototxt 文件...")
copyfile(deploy_proto, root + "\\data\\CaffeNet\\deploy.prototxt")
if os.path.exists(root + "\\data\\CaffeNet\\solver.prototxt"):
print("solver.prototxt 文件已存在...")
else:
print("生成 solver.prototxt 文件...")
copyfile(solver_proto, root + "\\data\\CaffeNet\\solver.prototxt")
# 创建 mean_data 文件夹
print("生成 mean_data 文件夹...")
os.makedirs(root + "\\data\\mean_data", exist_ok=True)
# 执行 cmd 命令
print("\n=============\n")
choos = input("是否生成 lmdb 文件?( y / n):")
print("\n=============\n")
if choos in ['Y', 'y']:
if os.path.exists(r'{}\data\train_leveldb'.format(root)):
os.remove(r'{}\data\train_leveldb'.format(root))
os.system(r'{} --resize_height=100 --resize_width=100 --shuffle --backend=lmdb {}\data\train/ {}\data\train.txt {}\data\train_leveldb'.format(imageset_exe, root, root, root))
if os.path.exists(r'{}\data\test_leveldb'.format(root)):
os.remove(r'{}\data\test_leveldb'.format(root))
os.system(r'{} --resize_height=100 --resize_width=100 --shuffle --backend=lmdb {}\data\test/ {}\data\test.txt {}\data\test_leveldb'.format(imageset_exe, root, root, root))
print("\n=============\n")
choos = input("是否生成均值文件?( y / n):")
print("\n=============\n")
if choos in ['Y', 'y']:
os.system(r'{} {}\data\train_leveldb {}\data\mean_data\mean.binaryproto'.format(imagemean_exe, root, root))
print("已生成 .binaryproto 均值文件!")
tonpy()
# 生成 train.bat 脚本
print("生成 train.bat 脚本文件...")
create_bat()
# 重命名图片
def rename(img_path, mark):
img_list = os.listdir(img_path)
i = 1
for item in img_list:
os.rename(img_path+item, img_path+'{}{:0>5}.png'.format(mark, i))
i += 1
# 数据划分
def dataset_cut(img_path):
os.makedirs(root + "\\data\\train", exist_ok=True) # 创建训练集文件夹
os.makedirs(root + "\\data\\test", exist_ok=True) # 创建测试集文件夹
img_list = os.listdir(img_path)
for img in img_list[:int(len(img_list)*0.8)]:
copyfile(img_path + img, root + "\\data\\train\\" + img)
for img in img_list[-int(len(img_list)*0.2):]:
copyfile(img_path + img, root + "\\data\\test\\" + img)
# 生成图片标签
def create_label(dir_name, dir_path):
img_list = os.listdir(dir_path + "\{}".format(dir_name)) # 获取训练集图片的名称
print("共获取 {} 张图片".format(len(img_list)))
# 获取图片名前缀
lab = []
for item in img_list:
if item[:3] not in lab:
lab.append(item[:3])
# 写入图片名及标签
with open(dir_path + "\{}.txt".format(dir_name), "w") as f:
i = 0
for item in lab:
for img in img_list:
if re.match(item+'+', img):
f.writelines("{} {}\n".format(img, i))
i += 1
print("生成 {}.txt 文件...".format(dir_name))
# 生成 .bat 脚本
def create_bat():
# 生成 train.bat 脚本
content = []
content.append('{} train -solver={}\\data\\CaffeNet\\solver.prototxt'.format(caffe_exe, root))
content.append('pause')
with open(root+r"\train.bat", 'w') as f:
for item in content:
f.writelines(item+'\n')
# 转换均值文件
def tonpy():
# .binaryproto 格式均值文件路径
path1 = root + r'\data\mean_data\mean.binaryproto'
# .npy 格式均值文件的生成路径
path2 = root + r'\data\mean_data\mean.npy'
blob = caffe.proto.caffe_pb2.BlobProto()
data = open(path1, 'rb' ).read()
blob.ParseFromString(data)
array = np.array(caffe.io.blobproto_to_array(blob))
mean_npy = array[0]
np.save(path2 ,mean_npy)
print("已生成 .npy 均值文件!")
if __name__ == "__main__":
main()
配置 train_val.prototxt 文件
上一步完成后,会在项目文件夹的根目录下生成【data】文件夹,打开该文件夹下的【CaffeNet】文件夹,会看到如下三个文件:

用记事本或者其他编辑器打开并修改 train_val.prototxt 文件,一共需要修改 5 处,具体修改内容如下(将\符号全部替换为/,否则会报错!):
# 第一处(11行左右):
transform_param {
mirror: true
# 裁剪图片尺寸
crop_size: 100
# 下面的路径改为自己均值文件的路径
mean_file: "C:/Users/CoolTea/Desktop/caffe-flower/data/mean.binaryproto"
}
# 第二处(27行左右):
data_param {
# 下面的路径改为自己 train_leveldb 文件夹的路径
source: "C:/Users/CoolTea/Desktop/caffe-flower/data/train_leveldb"
# 样本数量(不大于训练集图片)
batch_size: 80
backend: LMDB
}
# 第三处(44行左右):
transform_param {
mirror: false
# 裁剪图片尺寸
crop_size: 100
# 下面的路径改为自己均值文件的路径
mean_file: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/mean.binaryproto"
}
# 第四处(60行左右):
data_param {
# 下面的路径改为自己 test_leveldb 文件夹的路径
source: "C:/Users/CoolTea/Desktop/caffe-flower/DataSet/test_leveldb"
# 样本数量(不大于测试集图片)
batch_size: 20
backend: LMDB
}
# 第五处(385行左右):
inner_product_param {
# 本文一共有三类图片,因此这里的数字最好大于自己图片的种类
num_output: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
crop_size:
在 caffe 中,如果定义了 crop_size,那么在train时会对大于 crop_size 的图片进行随机裁剪,而在test时只是截取中间部分。
batch_size:
若 batch_size= m(训练集样本数量),相当于直接抓取整个数据集,训练时间长。但梯度准确,不适用于大样本训练,只适用于小样本训练,但小样本训练一般会导致过拟合现象,因此不建议如此设置。
配置 solver.prototxt 文件
用记事本或者其他编辑器打开并修改 solver.prototxt 文件,具体修改内容如下(将\符号全部替换为/,否则会报错!):
# 改为自己本地 train_val.prototxt 文件的路径
net: "C:/Users/CoolTea/Desktop/demo/data/CaffeNet/train_val.prototxt"
# 测试数据的迭代次数,根据测试图片的数量决定,本文测试数据比较少,可以调小数值
test_iter: 3
# 测试间隔,每训练多少次进行一次测试。
test_interval: 200
# 这个参数代表的是此网络最开始的学习速率
base_lr: 0.01
# 学习率调整策略
lr_policy: "step"
# 这个参数就是和学习率相关的
gamma: 0.1
# 这个参数表示我们应该多长时间(在某个迭代次数)进入下一个训练“步骤”。该值是一个正整数。
stepsize: 200
# 训练多少次对在屏幕上显示一次
display: 50
# 最大迭代次数,这个数值告诉网络何时停止训练,太小会达不到收敛,太大会导致震荡,为正整数。
max_iter: 600
# 上一次梯度更新的权重
momentum: 0.9
# 权重衰减项,用于防止过拟合。
weight_decay: 0.0005
# 训练多少次后保存一次model和solverstate
snapshot: 200
# 在数据集下新建 model 文件夹,用来存放模型
snapshot_prefix: "C:/Users/CoolTea/Desktop/demo/data/models/"
# 使用 CPU 还是 GPU 训练
solver_mode: CPU
训练模型
执行 prepare.py 程序后,会在根目录下生成 train.bat 脚本文件,双击运行该脚本即可开始训练,训练过程会花费一定的时间,最终结果如下:

accuracy 的值约为:1,表示其模型准确率接近 100% 。
使用模型
执行 prepare.py 程序后,会在根目录下生成 img_test 文件夹,从网上下载几张花朵图片存入该文件夹,做一下标识,以便查看!

使用记事本或者编辑器打开 deploy.prototxt 文件,并对该文件进行两处修改:
# 第一处(8行左右)
layer {
name: "data"
type: "Input"
top: "data"
# 对以下内容进行修改:
input_param { shape: { dim: 1 dim: 3 dim: 100 dim: 100 } }
}
# 第二处(209行左右)
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
inner_product_param {
# 改为 train_val.prototxt 文件最后 num_output 相同的值。
num_output: 4
}
}
dim: 1
对待识别样本进行数据增广的数量,可自行定义。一般会进行 5 次 crop ,之后分别 flip 。如果该值为 10 则表示一个样本会变成10个,之后输入到网络进行识别。如果不进行数据增广,可以设置成 1 。
dim: 3
通道数,表示RGB三个通道
dim: 100
图像的长和宽,通过 crop_size 获取,本文中我们定义为 100 。
编写 Python 识别代码,在根目录下新建 distinguish.py 文件,复制以下代码:
import os
import caffe
import numpy as np
# 根目录
root = os.getcwd()
# deploy 文件所在目录(数据集目录下)
deploy_path = root + r"\data\CaffeNet\deploy.prototxt"
# 训练好的模型所在目录(选数字最大的那个,后缀 .caffemodel)
model_path = root + r"\data\models\_iter_600.caffemodel"
# 识别标签文件所在路径(test 文件夹下)
labels_path = root + r"\data\labels.txt"
# npy 格式均值文件所在位置
npy_path = root + r"\data\mean_data\mean.npy"
# 测试图片所在目录
images_path = root + r"\img_test"
# 加载 model 和 network
net = caffe.Net(deploy_path, model_path, caffe.TEST)
# 设定图片的 shape 格式 (1,3,28,28)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
# 改变维度的顺序,由原始图片 (28,28,3) 变为 (3,28,28)
transformer.set_transpose('data', (2,0,1))
# 减去均值
transformer.set_mean('data', np.load(npy_path).mean(1).mean(1))
# 缩放到 (0, 100) 之间
transformer.set_raw_scale('data', 100)
# 交换通道,将图片由 RGB 变为 BGR
transformer.set_channel_swap('data', (2,1,0))
# 获取所有图片名,存入列表
image_list = os.listdir(images_path)
# 获取标签
lable = []
with open(labels_path, 'r') as f:
lines = f.readlines()
for item in lines:
lable.append(item.replace('\n', '').split(' '))
# 识别所有图片
for item in image_list:
img = caffe.io.load_image(images_path+"\\"+item)
net.blobs['data'].data[...] = transformer.preprocess('data', img)
out = net.forward()
prob = net.blobs['prob'].data[0].flatten()
order = prob.argsort()[-1]
for lab in lable:
if str(order) in lab:
print("{} ===> {}".format(item , lab[1]))
运行代码,结果如下:
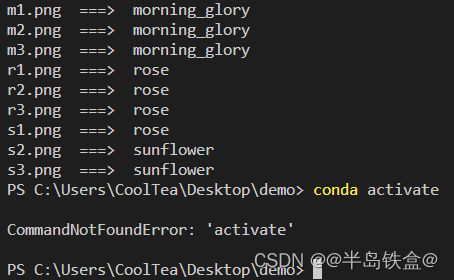
可以看到,识别的准去率还是很高的!