MAML阅读笔记
MAML阅读笔记
Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[J]. arXiv preprint arXiv:1703.03400, 2017.
为什么我今天这么晚还在工作呢?因为我今天下午又浪费了一下午的光阴……所以罚自己今晚完成任务。。。其实也是因为任务没有完成55555,所以来熬夜完成任务…
背景
又是一篇高被引论文,MAML可谓是元学习的里程碑之作,当然说到这篇文献,就不得不提到李宏毅老师的Meta—Learning课程,有好心人已经上传到B站了,大家可以去B站看看。什么叫元?在数据库里元指的是数据的数据,元信息就是信息的信息,那么元学习呢?就是学习去学习,即Learn to learn,后面这一个learn指的就是经典机器学习里的学习器的学习过程,经典机器学习里还有什么需要学习的呢?超参,网络结构等等……这些大量人工设计或者设置的参数往往也是基于人的经验,还记得上一篇文章里我提到过1997年Mitchell给机器学习下的形式化定义吗,他说机器学习是程序给定任务下利用经验得到的表现,然而我又提到了我们在做调参侠的时候这些超参又是在利用经验,所以就有人想到,能不能用学习的思想来学习超参,或者是网络中的参数初始化方案,或者是模型其他的结构比如网络结构、损失、优化函数等等?这就是meta learning。
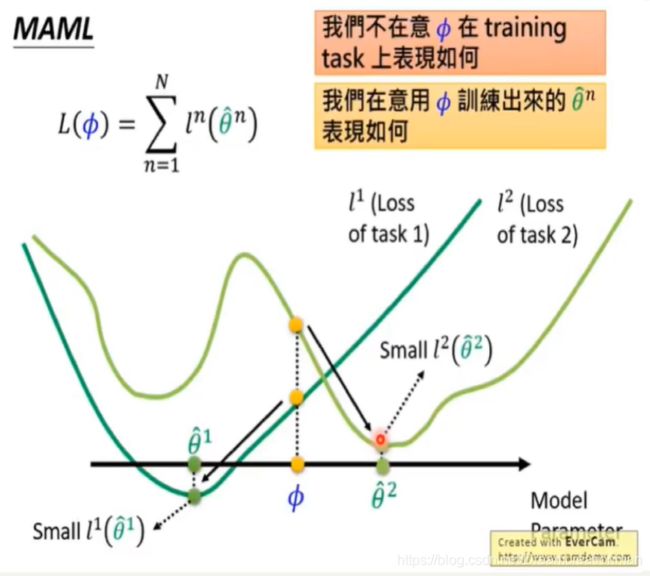
这里特别提示,这篇文章是希望模型是学习的参数。我们现在想想我们平时网络的参数是怎么初始化的,大多时候是在一个给定样本分布下的随机采样,或者按照一定方式采样,或者直接简单粗暴随机初始化,但是这样是不是最优呢?No,很多时候这样都不能避免zero point或者local minima。这时候调参侠发话了,我一般不会这么low,我有其他办法,我可以先让模型在大规模数据上预训练,然后再把参数进行fine-tuning或者部分retrain,这样的表现一般都比前面的方法有更好的Performance,这种方法其实就是我们前面在FSL里也提到的Transfer Learning,但是Transfer Learning有一个Constrain,隐含的前提是预训练过程使用到的数据分布一定要和当前的任务数据分布相近,不然表现也是一塌糊涂,即使抛开这个问题我们来谈谈这样是不是一个最优解?援引李宏毅老师PPT的一张图:

上图中绿色的两条线代表两个不同人物的loss,横轴表示模型参数,假设我们在task2上获得了一个较好的表现,然后将参数迁移到task 1上,大可能在经过retrain或者fine-tuning模型会陷入一个局部最优。So,既然我提到这个问题说明Meta Learning一定程度上能够避免这个问题,那我们现在走吧。
文章主要思想
文章的主要思想就是能不能把模型拿来训练?WTF,没开玩笑吧,模型怎么拿来训练?巧了,还真可以。。。
Details
一些pre-knowledge
传统的机器学习方法以样本作为输入,以label作为输出,样本又分为训练集和测试集(这里暂不考虑validation set),我们说Meta Learning是以模型作为输入,也就是说一个Meta Learning Model里应该有很多个任务,所以我们应该要把这些任务分为训练任务和测试任务,即Training Tasks和Test Tasks,但是每个任务又应该有训练集和测试集,所以这里为了避免混淆,将单个任务的训练集叫做Support Set,测试集叫做Query Set。
MAML的全称是Model-Agnostic Meta-Learning,怎么去理解这个Model-Agnostic?与模型无关,这个也就是MAML论文花了大量的篇幅在说的事情了,其实个人认为整个MAML有点像是开发里的框架,比如Spring,他和你的业务没有任何关系,什么业务都可以用Spring来开发(感觉这例子不恰当,但是熬夜这会儿床的磁场太强大,现在不想动脑子了……)。这里你可能会在网上听到一些名词,叫做meta-learner和base-learner,前者就是指的MAML用模型训练的模型 的的部分,后者指的是MAML用真实数据训练的模型那部分,而后者那个用什么模型来fit真实数据是可以换掉的,作者在文中使用了Regression,Classification和Reinforcement Learning来说明这个model-agnostic。
N-way K-shot这个名FSL里的重要内容,way指的是类别,K指的是样本数量, N-way K-shot就指的是Support Set中有N个类别,每个类别下有K个标记数据。。一个episode就是一次选择support set和query set的过程,即选择某几个类别的数据训练一次模型,下一个episode,再选择其他几个类训练模型。一个epoch中存在多个episode。每个episode对应着一个N-way K-shot图像分类任务分类任务。
在本文中我是把Model和Task这两个名词混用了的,隐含的假设就是特定的Model解决特定类的Task。
方法细节
Ok,有了前面的知识铺垫这里就可以深入模型了,首先对于单个任务T定义为: T = { L ( x 1 , a 1 . . . . x H , a H ) , q ( x 1 ) , q ( x t + 1 ∣ x t , a t ) , H } \mathcal{T}=\{\mathcal{L}(x_1,a_1....x_H,a_H), q(x_1),q(x_{t+1}|x_t,a_t), H\} T={L(x1,a1....xH,aH),q(x1),q(xt+1∣xt,at),H},其中 L \mathcal{L} L表示Loss, x i x_i xi表示模型的输入, a i a_i ai表示模型的输出, H H H表示一次episode的长度。下图是原论文中给出的Meta Learning的伪代码:

这里我解释一下这个代码, p ( T ) \mathcal{p}(\mathcal{T}) p(T)表示所有的任务分布,怎么理解?假设我们要做一个10way-10Shot的分类任务,一共100个类别(包含我们需要适应的新任务的那10个类别)。那么我们就拿这个目标的10个类别(10-way)作为Test Tasks,每个类别10张训练图片(即Test Task的Support Set,10-Shot),然后每个人物还需要测试图片(即Test Task的Query Set,人为设定,这里假设20),所以测试任务数据集一共就是10 *(10+20)=300张图片(即Test Task的数据及大小)。那么我们就需要从剩下的90个任务中抽一些组成和测试任务样本大小一样的出来作为Training Tasks,即每次要随机sample 10个类别(即TrainTask的Support Set,10-Shot),每个类别sample 10个样本,然后再随机Sample一些图片作为测试图片(即Train Task的Query Set,和前述一致为20),然后重复取样。 α , β \alpha, \beta α,β分别表示不同的学习率,至于什么时候会用到后面会讲。 θ \theta θ是模型的参数向量。
首先我们随机初始化参数向量 θ \theta θ,然后进行epoch循环,这里的结束条件可以根据自己来设定,你可以设定更新多少步后停止,也可以设定某个参数不再更新后停止。然后就是我们上面说的,从剩下的90个任务中sample N个类别(N-way),K个样本(K-Shot),然后随机Sample 一些(人为设定)样本作为Query Set。
然后对每个任务利用batch中的每一个task,分别对模型的参数进行更新。伪代码这里有问题,事实上作者在代码中这一段是可以循环执行的了,也就是说这里可以进行多次iteration更新的。这是MAML的第一次参数更新。然后所有任务都执行完这个过程后相当于才跑过一次iteration,也就是一个batch,这时候应该对meta-model的参数进行第二次更新,也就是第八行。然后循环直到epoch结束。
这里提一下两个loss计算而第四行的loss是指的是单个任务的loss,比如mse,交叉熵等等,第八行的loss是计算一个batch的loss总和,然后再进行随机梯度下降SGD。同时这里在计算loss的时候由于样本比较少,author为了避免过拟合,只采用了query set作为进行loss计算。这里loss计算的公式还是有点意思建议有空的话去看看李宏毅老师的视频,讲的非常清楚。
My comment
事实上MAML的思想非常简单,而且表现也很不错,由于MAML的Training Setup的Motivation也导致很多人直接把MAML的目的直接等同于Meta Learning的目的,然后得出FSL=Meta Learning的结论,个人觉得这样有失偏颇。说回论文上来,这篇文章的整体工作还是挺饱满的,而且个人觉得最优秀的就是这个model-agnostic,你看实际上我上面就是以Classification来举例了,但是并没有提出Classification的具体model,所以你可以用卷积,也可以用全连接,等等,所以给了实用性很强。后面会再深入看看这篇文章相关的工作。
然后回到最开始的那张图我们就可以知道,MAML其实并不是在寻找某个或某几个Task上的最优参数,他想找的是在几个目标Task上经过训练后的最优参数,如下图所示:
结果
今天下午也把pytorch版本搞下来再miniImageNet下试了试,参数:
epoch=60000, imgc=3, imgsz=84, k_qry=15, k_spt=1, meta_lr=0.001, n_way=5, task_num=4, update_lr=0.01, update_step=5, update_step_test=10,模型架构如下:
Meta(
(net): Learner(
conv2d:(ch_in:3, ch_out:32, k:3x3, stride:1, padding:0)
relu:(True,)
bn:(32,)
max_pool2d:(k:2, stride:2, padding:0)
conv2d:(ch_in:32, ch_out:32, k:3x3, stride:1, padding:0)
relu:(True,)
bn:(32,)
max_pool2d:(k:2, stride:2, padding:0)
conv2d:(ch_in:32, ch_out:32, k:3x3, stride:1, padding:0)
relu:(True,)
bn:(32,)
max_pool2d:(k:2, stride:2, padding:0)
conv2d:(ch_in:32, ch_out:32, k:3x3, stride:1, padding:0)
relu:(True,)
bn:(32,)
max_pool2d:(k:2, stride:1, padding:0)
flatten:()
linear:(in:800, out:5)
(vars): ParameterList(
(0): Parameter containing: [torch.cuda.FloatTensor of size 32x3x3x3 (GPU 0)]
(1): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(2): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(3): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(4): Parameter containing: [torch.cuda.FloatTensor of size 32x32x3x3 (GPU 0)]
(5): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(6): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(7): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(8): Parameter containing: [torch.cuda.FloatTensor of size 32x32x3x3 (GPU 0)]
(9): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(10): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(11): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(12): Parameter containing: [torch.cuda.FloatTensor of size 32x32x3x3 (GPU 0)]
(13): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(14): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(15): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(16): Parameter containing: [torch.cuda.FloatTensor of size 5x800 (GPU 0)]
(17): Parameter containing: [torch.cuda.FloatTensor of size 5 (GPU 0)]
)
(vars_bn): ParameterList(
(0): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(1): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(2): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(3): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(4): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(5): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(6): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
(7): Parameter containing: [torch.cuda.FloatTensor of size 32 (GPU 0)]
)
)
)
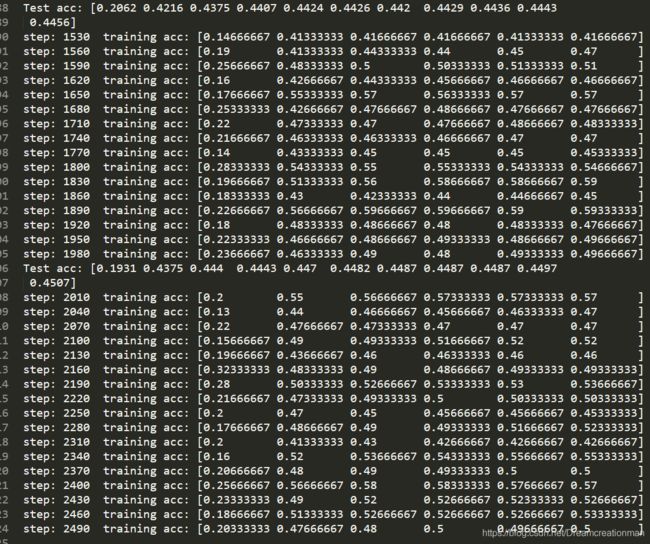
在单3090上跑了大概5小时,显存占用6G,效果如下,和论文里给出的48.07%还有一点差距,但是也远高于当时其他网络了:
Future Work
想法
MAML有一个问题就是所有的Learner的model Structure必须一样,但是后来看李宏毅老师的视频他也说有模型已经解决这个问题了,后面可以看看哈哈哈,为什么要后面看呢,主要是我现在实在遭不住了,已经两点了…睡了睡了

硬核引流:欢迎大家推广关注我的公众号啊(洋可喵)!!!
