Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(7)——卷积神经网络详解与实现
-
- 0. 前言
- 1. 传统神经网络的缺陷
-
- 1.1 构建传统神经网络
- 1.2 传统神经网络的缺陷
- 2. 使用 Python 从零开始构建CNN
-
- 2.1 卷积神经网络的基本概念
- 2.2 卷积和池化相比全连接网络的优势
- 3. 使用 Keras 构建卷积神经网络
-
- 3.1 CNN 使用示例
- 3.2 验证 CNN 输出
- 4. 构建 CNN 模型识别 MNIST 手写数字
-
- 4.1 任务与模型分析
- 4.2 CNN 模型构建与训练
- 相关链接
0. 前言
我们已经学习了传统的深度前馈神经网络(也可以称为全连接神经网络),传统深度前馈神经网络的局限性之一是它并不满足平移不变性,也就是说,在传统神经网络看来,图像右上角的猫与位于图像中心的猫被视为不同对象,即使实际上这是同一只猫。另外,传统的神经网络受对象大小的影响,如果训练集中大多数图像中的对象较大,而训练数据集图像中包含相同的对象但占据图像画面的比例较小,则传统的神经网络可能无法对图像进行正确分类。
卷积神经网络 (Convolutional Neural Network, CNN) 的提出正是用于解决传统神经网络的这些缺陷。鉴于即使对象位于图片中的不同位置或其在图像中具有不同占比,CNN 也能够正确的处理这些图像,因此在对象分类/检测任务中更加有效。
1. 传统神经网络的缺陷
为了了解卷积神经网络 (Convolutional Neural Network, CNN) 的优势,我们首先了解为什么在图像中,如果对象平移或比例改变时前馈神经网络 (Neural Network, NN) 性能欠佳,然后了解 CNN 对比传统前馈神经网络的改进。
我们首先考虑使用以下策略,以了解 NN 模型的缺陷:
- 建立一个
NN模型,以预测MNIST手写数字标签 - 获取所有标签为
1的图像,并取这些图像的均值生成新图像 - 使用构建的
NN预测在上一步中生成的均值图像的标签 - 将均值图像向左或向右平移若干个像素,生成新图像,并使用
NN模型对生成的新图像进行预测
1.1 构建传统神经网络
接下来,根据上述策略,编写代码实现如下。
- 加载所需库和
MNIST数据集:
from keras.datasets import mnist
from keras.layers import Flatten, Dense
from keras.models import Sequential
import matplotlib.pyplot as plt
from keras.utils import np_utils
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
- 获取训练集中标签为
1的数字图片:
x_train1 = x_train[y_train==1]
- 将训练数据整形以符合网络输入尺寸要求,并进行数据规范化:
num_pixels = x_train.shape[1] * x_train.shape[2]
x_train = x_train.reshape(x_train.shape[0], num_pixels).astype('float32')
x_test = x_test.reshape(x_test.shape[0], num_pixels).astype('float32')
x_train = x_train / 255.
x_test = x_test / 255.
- 对图像标签进行独热编码:
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
- 然后,构建模型并进行拟合:
model = Sequential()
model.add(Dense(1024, input_dim=num_pixels, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=5,
batch_size=1024,
verbose=1)
- 接下来,使用标签为
1的所有图像的均值生成新图像,并使用训练后的模型预测此图像的标签。首先,生成图像:
pic = np.zeros((x_train1.shape[1], x_train1.shape[2]))
pic2 = np.copy(pic)
for i in range(x_train1.shape[0]):
pic2 = x_train1[i,:,:]
pic = pic + pic2
pic = pic / x_train1.shape[0]
plt.imshow(pic, cmap='gray')
plt.show()
在代码中,我们初始化了一个尺寸为 28 x 28 的空白图像,并通过循环遍历 x_train1 中的所有值,即标签为 1 的所有图像,将图像中各个像素位置值进行加和,求取平均像素值。生成的图像显示如下:

在上图中,像素越白,表示人们在此位置书写的频率就越高;像素越黑的位置表示书写频率越低。可以看到,中间的像素是最白的,这是因为大多数人,都习惯于在中间位置书写数字。
- 最后,查看神经网络对于此图像的预测:
p = model.predict(pic.reshape(1, -1)/255.)
print(p)
c = np.argmax(p)
print('神经网络预测结果:', c)
np.argmax() 函数用于返回一个 Numpy 数组中最大值的索引,在以上示例中,最大值的索引就是模型预测概率最大的类别。以上拟合后的模型,输出的预测结果如下:
[[8.6497545e-05 9.2336720e-01 2.6006915e-03 5.4899454e-03 4.6638816e-04
8.7751285e-04 6.4074027e-04 2.3328003e-03 6.3134938e-02 1.0033193e-03]]
神经网络预测结果: 1
1.2 传统神经网络的缺陷
情景 1:创建一个新图像,将上一节由所有标签为 1 的图像生成均值图像向左平移 1 个像素。使用以下代码,我们遍历图像的各列,并将下一列的像素值复制到当前列,从而完成向左平移:
for i in range(pic.shape[0]):
if i < 20:
pic[:,i]=pic[:,i+1]
plt.imshow(pic, cmap='gray')
plt.show()
向左平移 1 个像素后的均值图像如下所示:

使用训练完成的的模型预测图像的标签:
p = model.predict(pic.reshape(1, -1)/255.)
print(p)
c = np.argmax(p)
print('神经网络预测结果:', c)
该模型对平移后图像的预测如下:
[[2.3171112e-03 5.3161561e-01 2.6453543e-02 8.1305495e-03 5.2826328e-04
3.4600161e-02 4.3771293e-02 3.4394194e-04 3.5101682e-01 1.2227822e-03]]
神经网络预测结果:1
我们可以看到尽管模型可以将其正确预测为 1,但是其预测概率要比未平移像素时的概率小的多。
情景 2:创建一个新图像,将原始平均图像的像素向右移动了 2 个像素:
pic=np.zeros((x_train1.shape[1], x_train1.shape[2]))
pic2=np.copy(pic)
for i in range(x_train1.shape[0]):
pic2=x_train1[i,:,:]
pic=pic+pic2
pic=(pic/x_train1.shape[0])
pic2=np.copy(pic)
for i in range(pic.shape[0]):
if ((i>6) and (i<26)):
pic[:,i]=pic2[:,(i-3)]
plt.imshow(pic, cmap='gray')
plt.show()
平移后的平均图像如下所示:

然后,对该图像进行预测:
p = model.predict(pic.reshape(1, -1)/255.)
print(p)
c = np.argmax(p)
print('神经网络预测结果:', c)
该模型对平移后图像的预测如下:
[[0.00519334 0.0018531 0.07164755 0.33244154 0.3407778 0.00380969
0.00090572 0.19745363 0.0096615 0.03625605]]
神经网络预测结果:4
可以看到模型输出了错误的预测结果:4,以上这些问题的存在就是我们需要使用 CNN 的原因。
2. 使用 Python 从零开始构建CNN
在本节中,首先介绍卷积神经网络 (CNN) 的相关概念与组成,以便了解CNN提高平移图像预测准确率的原理。然后,我们将使用 NumPy 从零开始构建 CNN,来了解 CNN 的工作原理。
2.1 卷积神经网络的基本概念
我们已经学习了如何构建经典神经网络,在本节中,我们了详细介绍 CNN 中卷积过程的工作原理和相关组件。
2.1.1 卷积
卷积是两个矩阵间的乘法——通常一个矩阵具有较大尺寸,另一个矩阵则较小。要了解卷积,首先讲解以下示例。给定矩阵 A 和矩阵 B 如下:

在进行卷积时,我们将较小的矩阵在较大的矩阵上滑动,在上述两个矩阵中,当较小的矩阵 B 需要在较大矩阵 A 的整个区域上滑动时,会得到 9 次乘法运算,过程如下。
在矩阵 A 中从第 1 个元素开始选取与矩阵 B 相同尺寸的子矩阵 [ 1 2 0 1 1 1 3 3 2 ] \left[ \begin{array}{ccc} 1 & 2 & 0\\ 1 & 1 & 1\\ 3 & 3 & 2\\\end{array}\right] ⎣⎡113213012⎦⎤ 和矩阵 B 相乘并求和:

1 × 3 + 2 × 1 + 0 × 1 + 1 × 2 + 1 × 3 + 1 × 1 + 3 × 2 + 3 × 2 + 2 × 3 = 29 1\times 3+2\times 1+0\times 1+1\times 2+1\times 3+1\times 1+3\times 2+3\times 2 + 2\times 3=29 1×3+2×1+0×1+1×2+1×3+1×1+3×2+3×2+2×3=29
然后,向右滑动一个窗口,选择第 2 个与矩阵 B 相同尺寸的子矩阵 [ 2 0 2 1 1 2 3 2 1 ] \left[ \begin{array}{ccc} 2 & 0 & 2\\ 1 & 1 & 2\\ 3 & 2 & 1\\\end{array}\right] ⎣⎡213012221⎦⎤ 和矩阵 B 相乘并求和:

2 × 3 + 0 × 1 + 2 × 1 + 1 × 2 + 1 × 3 + 2 × 1 + 3 × 2 + 2 × 2 + 1 × 3 = 28 2\times 3+0\times 1+2\times 1+1\times 2+1\times 3+2\times 1+3\times 2+2\times 2 + 1\times 3=28 2×3+0×1+2×1+1×2+1×3+2×1+3×2+2×2+1×3=28
然后,再向右滑动一个窗口,选择第 3 个与矩阵 B 相同尺寸的子矩阵 [ 0 2 3 1 2 0 2 1 2 ] \left[ \begin{array}{ccc} 0 & 2 & 3\\ 1 & 2 & 0\\ 2 & 1 & 2\\\end{array}\right] ⎣⎡012221302⎦⎤ 和矩阵 B 相乘并求和:

0 × 3 + 2 × 1 + 3 × 1 + 1 × 2 + 2 × 3 + 0 × 1 + 2 × 2 + 1 × 2 + 2 × 3 = 25 0\times 3+2\times 1+3\times 1+1\times 2+2\times 3+0\times 1+2\times 2+1\times 2 + 2\times 3=25 0×3+2×1+3×1+1×2+2×3+0×1+2×2+1×2+2×3=25
当向右滑到尽头时,向下滑动一个窗口,并从矩阵 A 左边开始,选择第 4 个与矩阵 B 相同尺寸的子矩阵 [ 1 1 1 3 3 2 1 0 2 ] \left[ \begin{array}{ccc} 1 & 1 & 1\\ 3 & 3 & 2\\ 1 & 0 & 2\\\end{array}\right] ⎣⎡131130122⎦⎤ 和矩阵 B 相乘并求和:

1 × 3 + 1 × 1 + 1 × 1 + 3 × 2 + 3 × 3 + 2 × 1 + 1 × 2 + 0 × 2 + 2 × 3 = 30 1\times 3+1\times 1+1\times 1+3\times 2+3\times 3+2\times 1+1\times 2+0\times 2 + 2\times 3=30 1×3+1×1+1×1+3×2+3×3+2×1+1×2+0×2+2×3=30
然后,继续向右滑动,并重复以上过程滑动矩阵窗口,直到滑动到最后一个子矩阵为止,得到最终的结果 [ 29 28 25 30 30 27 20 24 34 ] \left[ \begin{array}{ccc} 29 & 28 & 25\\ 30 & 30 & 27\\ 20 & 24 & 34\\\end{array}\right] ⎣⎡293020283024252734⎦⎤:

完整的卷积计算过程如以下动图所示:

通常,我们把较小的矩阵 B 称为滤波器 (filter) 或卷积核 (kernel),使用 ⊗ \otimes ⊗ 表示卷积运算,较小矩阵中的值通过梯度下降被优化学习,卷积核中的值则为网络权重。卷积后得到的矩阵,也称为特征图 (feature map)。
卷积核的通道数与其所乘矩阵的通道数相等。例如,当图像输入形状为 5 x 5 x 3 时(其中 3 为图像通道数),形状为 3 x 3 的卷积核也将具有 3 个通道,以便进行矩阵卷积运算:

可以看到无论卷积核有多少通道,一个卷积核计算后都只能得到一个通道。多为了捕获图像中的更多特征,通常我们会使用多个卷积核,得到多个通道的特征图,当使用多个卷积核时,计算过程如下:
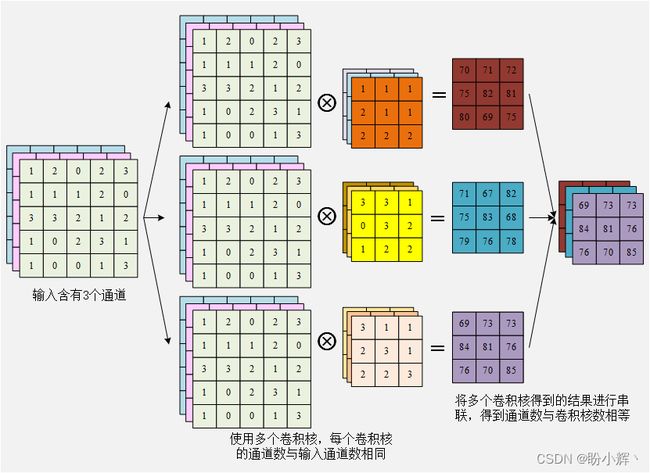
需要注意的是,卷积并不等同于滤波,最直观的区别在于滤波后的图像大小不变,而卷积会改变图像大小,关于它们之间更详细的计算差异,并非本节重点,因此不再展开介绍。
2.1.2 步幅
在前面的示例中,卷积核每次计算时在水平和垂直方向只移动一个单位,因此可以说卷积核的步幅 (Strides) 为 (1, 1),步幅越大,卷积操作跳过的值越多,例如以下为步幅为 (2, 2) 时的卷积过程:

2.1.3 填充
在前面的示例中,卷积操作对于输入矩阵的不同位置计算的次数并不相同,具体来说对于边缘的数值在卷积时,仅仅使用一次,而位于中心的值则会被多次使用,因此可能导致卷积错过图像边缘的一些重要信息。如果要增加对于图像边缘的考虑,我们将在输入矩阵的边缘周围的填充 (Padding) 零,下图展示了用 0 填充边缘后的矩阵进行的卷积运算,这种填充形式进行的卷积,称为 same 填充,卷积后得到的矩阵大小为 ⌊ d + s − 1 s ⌋ \lfloor\frac {d+s-1} s\rfloor ⌊sd+s−1⌋,其中 s s s 表示步幅。而未进行填充时执行卷积运算,也称为 valid 填充。

2.1.4 激活函数
在传统神经网络中,隐藏层不仅将输入值乘以权重,而且还会对数据应用非线性激活函数,将值通过激活函数传递。CNN 中同样包含激活函数,CNN 支持我们已经学习的所有可用激活函数,包括 Sigmoid,ReLU,tanh 和 LeakyReLU 等。
2.1.5 池化
研究了卷积的工作原理之后,我们将了解用于卷积操作之后的另一个常用操作:池化 (Pooling)。假设卷积操作的输出如下,为 2 x 2:
[ 29 28 20 24 ] \left[ \begin{array}{cc} 29 & 28\\ 20 & 24\\\end{array}\right] [29202824]
假设使用池化块(或者类比卷积核,我们也可以称之为池化核)为 2 x 2 的最大池化,那么将会输出 29 作为池化结果。假设卷积步骤的输出是一个更大的矩阵,如下所示:
[ 29 28 25 29 20 24 30 26 27 23 26 27 24 25 23 31 ] \left[ \begin{array}{cccc} 29 & 28 & 25 & 29\\ 20 & 24 & 30 & 26\\ 27 & 23 & 26 & 27\\ 24 & 25 & 23 & 31\\\end{array}\right] ⎣⎢⎢⎡29202724282423252530262329262731⎦⎥⎥⎤
当池化核为 2 x 2,且步幅为 2 时,最大池化会将此矩阵划分为 2 x 2 的非重叠块,并且仅保留每个块中最大的元素值,如下所示:
[ 29 28 ∣ 25 29 20 24 ∣ 30 26 — — — — — 27 23 ∣ 26 27 24 25 ∣ 23 31 ] = [ 29 30 27 31 ] \left[ \begin{array}{ccccc} 29 & 28 & | & 25 & 29\\ 20 & 24 & | & 30 & 26\\ —&—&—&—&—\\ 27 & 23 & | & 26 & 27\\ 24 & 25 & | & 23 & 31\\\end{array}\right]=\left[ \begin{array}{cc} 29 & 30\\ 27 & 31\\\end{array}\right] ⎣⎢⎢⎢⎢⎡2920—27242824—2325∣∣—∣∣2530—26232926—2731⎦⎥⎥⎥⎥⎤=[29273031]
从每个池化块中,最大池化仅选择具有最高值的元素。除了最大池化外,也可以使用平均池化,其将输出每个池化块中的平均值作为结果,在实践中,与其他类型的池化相比,最常使用的池化为最大池化。
2.2 卷积和池化相比全连接网络的优势
在以上 MNIST 手写数字识别示例中,可以看出传统神经网络的缺点之一是每个像素都具有不同的权重。因此,如果当这些权重用于除原始像素以外的相邻像素,则神经网络得到的输出将不是非常准确(如情景 1 的示例,像素稍微向左侧移动后,准确率就大幅下降)。
使用 CNN 可以解决这一问题,因为图像中的像素共享由卷积核构成的权重。所有像素都乘以构成卷积核的所有权重;在池化层中,仅选择卷积后具有最高值的输出。这样,无论要识别的对象像素是位于中心还是偏离中心,输出通常都是期望值。但是,当要识别的像素距离中心很远时,问题仍然存在,这是由于靠近中心的像素在 CNN 能够会被卷积核更频繁的划过。
3. 使用 Keras 构建卷积神经网络
为了进一步加深对卷积神经网络 (Convolutional Neural Network, CNN) 的理解,我们将使用 Keras 构建基于 CNN 的体系结构,并通过使用 Keras 和 Numpy 从输入开始构建 CNN 前向传播过程获得输出,来增强我们对 CNN 的理解。
3.1 CNN 使用示例
我们首先定义一个输入和预期输出数据的简单示例来实现 CNN。
- 创建输入和输出数据集:
import numpy as np
x_train = np.array([[[1,2,3,3],
[2,3,4,5],
[4,5,6,7],
[1,3,4,6]],
[[-1,2,3,-5],
[2,-2,4,5],
[-3,5,-4,9],
[-1,-3,-2,-5]]])
y_train = np.array([0, 1])
在以上代码中,我们创建了以下数据:输入全为正数得到的输出为 0,带有负值的输入则得到 1 作为输出。
- 缩放输入数据集:
x_train = x_train / 9
- 对输入数据集的形状进行整形,以使每个输入图像都以
(宽度 x 高度 x 通道数)的格式表示:
x_train = x_train.reshape(x_train.shape[0], x_train.shape[1], x_train.shape[1], 1)
- 准备数据后,构建模型架构,导入相关方法后实例化模型:
from keras.models import Sequential
from keras.layers import Conv2D, Flatten, MaxPooling2D
model = Sequential()
- 接下来,我们将执行卷积操作:
model.add(Conv2D(1, (3, 3), input_shape=(4, 4, 1), activation='relu'))
在上述代码中,我们对输入数据执行 2D 卷积 Conv2D,其中有 1 个大小为 3 x 3 的卷积核,由于这是实例化模型中的第一层,我们需要指定输入形状,为 (4, 4, 1);最后,我们在卷积的输出之上使用 ReLU 激活函数。由于我们没有对输入进行填充,因此输出的特征图大小将缩小,卷积运算输出的形状为 2 x 2 x 1。
- 接下来,我们将添加一个执行最大池化操作的网络层
MaxPooling2D,如下所示:
model.add(MaxPooling2D(pool_size=(2, 2)))
我们在上一层获得的输出之上执行最大池化 (池化核大小为 2 x 2),这表示需要计算图像每个滑动窗口 2 x 2 部分中的最大值,得到池化运算输出的形状为 1 x 1 x 1。
- 接下来,展平池化层的输出:
model.add(Flatten())
一旦执行了展平 Flatten 处理,展平层的操作十分简单——将多维的输入整形为一维数组,Flatten操作不影响第一维的 batch_size,在本例中,执行 Flatten 操作后,数据形状由 (batch_size, 1,1,1) 变为 (batch_size, 1)。之后就与在标准前馈神经网络中执行的过程非常相似,先连接到若干隐藏层,最后连接到输出层。在这里,我们使用 sigmoid 激活函数,并直接将展平层的输出连接到输出层:
model.add(Dense(1, activation='sigmoid'))
查看该模型的相关信息:
model.summary()
输出的模型简要信息如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 2, 2, 1) 10
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 1, 1, 1) 0
_________________________________________________________________
flatten (Flatten) (None, 1) 0
_________________________________________________________________
dense (Dense) (None, 1) 2
=================================================================
Total params: 12
Trainable params: 12
Non-trainable params: 0
_________________________________________________________________
如上所示,卷积层中有 10 个参数,因为一个 3 x 3 的卷积核,其具有 9 个权重和 1 个偏置项。池化层和展平层没有任何参数,因为它们只需某个区域中提取最大值(最大池化 MaxPooling2D),或者展平前一层的输出(展平层 Flatten),因此不需要在其中一个权重进行修改的操作这些层。输出层具有两个参数,因为展平层只有一个输出,该输出连接到具有一个值的输出层,因此具有一个权重和一个偏置项来连接展平层和输出层。
- 最后,编译并拟合模型:
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['acc'])
model.fit(x_train, y_train, epochs=50)
在上述代码中,我们将损失指定为二进制交叉熵,因为输出结果是 1 或 0。
3.2 验证 CNN 输出
在上一节中,我们已经拟合了模型,接下来,通过实现 CNN 的前向传播过程来验证从模型中获得的输出。
- 首先,我们提取权重和偏置的相关信息:
print(model.get_weights())
输出结果如下:
[<tf.Variable 'conv2d/kernel:0' shape=(3, 3, 1, 1) dtype=float32, numpy=
array([[[[ 0.1985341 ]],
[[ 0.27599618]],
[[ 0.20717546]]],
[[[-0.41702896]],
[[-0.21289168]],
[[ 0.12980239]]],
[[[-0.14379142]],
[[ 0.55261314]],
[[-0.49706236]]]], dtype=float32)>,
<tf.Variable 'conv2d/bias:0' shape=(1,) dtype=float32, numpy=array([0.04198299], dtype=float32)>,
<tf.Variable 'dense/kernel:0' shape=(1, 1) dtype=float32, numpy=array([[1.5805249]], dtype=float32)>,
<tf.Variable 'dense/bias:0' shape=(1,) dtype=float32, numpy=array([-0.28272304], dtype=float32)>]
可以看到,首先显示了卷积层的权重,然后是偏置,最后是输出层中的权重和偏置。卷积层中权重的形状为 (3, 3, 1, 1),因为卷积核的形状为 3 x 3 x 1 (形状中的前三个值),形状中的第四个值 1 用于在卷积层中指定卷积核的数量。如果我们指定 64 作为卷积中的卷积核数量,则权重的形状为 3 x 3 x 1 x 64,而如果对具有 3 个通道的图像执行卷积运算,则每个卷积核的形状将为 3 x 3 x 3。
- 使用
model的weights属性提取各层的权重值:
print(model.weights)
接下来,我们使用模型计算第一个输入 x_train[0] 的输出,以便我们可以通过前向传播查看 CNN 计算结果:
print(model.predict(x_train[0].reshape(1,4,4,1)))
# 输出如下
# [[0.04299431]]
以上代码对输入数据整形,同时将其传递给预测方法,因为模型希望接受输入的形状为 (None, 4, 4, 1),其中 None 用于指定批大小,可以是任何数字。我们运行的模型预测输出为 0.04299431。
- 接下来,我们通过模拟卷积过程进行验证,对输入数据执行卷积,输入图像的形状为
4 x 4,而卷积核的形状为3 x 3,在代码中沿着行和列执行矩阵乘法(卷积):
sumprod = []
for i in range(x_train[0].shape[0]-model.get_weights()[0].shape[0]+1):
for j in range(x_train[0].shape[0]-model.get_weights()[0].shape[0]+1):
img_subset = np.array(x_train[0,i:(i+3),j:(j+3),0])
filter = model.get_weights()[0].reshape(3,3)
val = np.sum(img_subset*filter) + model.get_weights()[1]
sumprod.append(val)
在以上代码中,我们初始化一个名为 sumprod 的空列表,用于存储卷积核与输入数据的每个子矩阵卷积的输出。
- 整形
sumprod的输出,以便将其传递到池化层:
sumprod = np.array(sumprod).reshape(2, 2, 1)
- 在卷积的输出传递到池化层之前,先对其使用激活函数:
sumprod = np.where(sumprod>0, sumprod, 0)
- 将卷积输出传递到池化层,根据以上模型定义,考虑到卷积的输出为
2 x 2,根据最大池化层的定义我们取输出中的最大值:
pooling_layer_output = np.max(sumprod)
- 将池化层的输出连接到输出层,将池化层的输出乘以输出层中的权重,然后在输出层中加上偏置值:
intermediate_output_value = pooling_layer_output * model.get_weights()[2] + model.get_weights()[3]
- 计算
Sigmoid输出:
print(1/(1+np.exp(-intermediate_output_value)))
以上操作的输出如下:
[[0.42994314]]
可以看到输出与我们使用 model.predict 方法获得的输出相同,从而加深了我们对 CNN 工作流程的了解。
4. 构建 CNN 模型识别 MNIST 手写数字
4.1 任务与模型分析
在前面的部分中,我们了解了传统神经网络的问题以及 CNN 的工作原理。在本节中,我们将构建 CNN 模型用来识别经过平移的 MNIST 手写数字。我们采用的以下策略构建 CNN 模型:
- 输入形状为
28 x 28 x 1,使用的卷积核尺寸为3 x 3 x 1- 需要注意的是,卷积核的大小可以更改,但是通道数不能更改,需要与输入通道数相同
- 使用
10个卷积核
- 输入图像经过卷积层后,使用池化层:
- 输出的图像尺寸减半
- 展平池化后获得的输出
- 展平层连接到一个具有
1000个单位的隐藏层 - 最后,将隐藏层连接到输出层,输出层中有
10类(包括数字0-9)
建立模型后,我们使用所有标签为 1 的图像生成均值图像,并平移 1 个像素,然后在平移后的图像上测试 CNN 模型的性能;在第 1 节中,我们已经知道,全连接神经网络无法争取预测该均值图像的类别。
4.2 CNN 模型构建与训练
接下来,使用 Keras 实现上述定义的 CNN 架构,以了解如何在 MNIST数据上使用 CNN 模型。
- 加载并预处理数据:
from keras.layers import Dense,Conv2D,MaxPool2D,Flatten
from keras.models import Sequential
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], x_train.shape[1], x_train.shape[1], 1)
x_test = x_test.reshape(x_test.shape[0], x_test.shape[1], x_test.shape[1], 1)
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
预处理步骤与我们在《构建深度前馈神经网络》中使用的方法完全相同。
- 建立并编译模型:
model = Sequential()
model.add(Conv2D(10, (3, 3), input_shape=(28, 28, 1), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
可以获取我们在前面的代码中初始化的模型的简要架构信息:
model.summary()
输出该模型的简要架构信息如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 10) 100
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 10) 0
_________________________________________________________________
flatten (Flatten) (None, 1690) 0
_________________________________________________________________
dense (Dense) (None, 512) 865792
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 871,022
Trainable params: 871,022
Non-trainable params: 0
_________________________________________________________________
卷积层中总共有 100 个参数,因为卷积层中有 10 个 3 x 3 x 1 的卷积核,因此总共有 90 个权重参数和 10 个偏置项(每个卷积核中 1 个),共 100 个参数。最大池化层没有任何参数,因为它只需要计算每个大小为 2 x 2 的池化核中的最大值。可以看到使用 CNN 模型可以大幅降低网络参数量。
- 最后,拟合模型:
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
epochs=10,
batch_size=1024,
verbose=1)
以上模型在 10 个 epoch 训练后,可以达到 98% 的准确率:
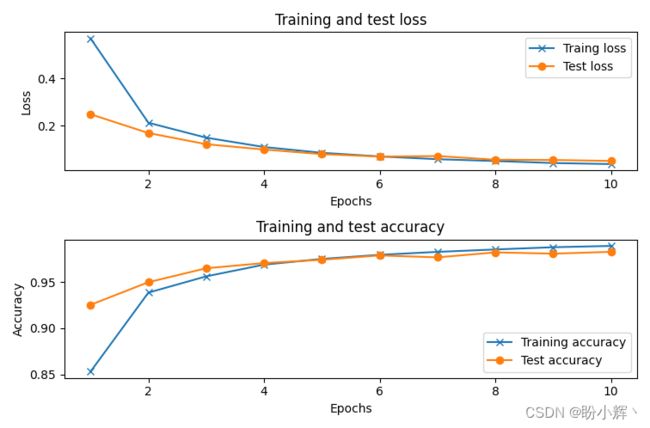
4. 接下来,使用所有标签为 1 的图像生成均值图像,并平移 1 个像素:
# 获取标签为1的所有图像输入
x_test1 = x_test[y_test[:, 1]==1]
# 利用所有标签为1的图像生成均值图像
pic = np.zeros((x_test.shape[1], x_test.shape[2]))
pic2 = np.copy(pic)
for i in range(x_test1.shape[0]):
pic2 = x_test1[i, :, :, 0]
pic = pic + pic2
pic = (pic / x_test1.shape[0])
# 将均值图像中的每个像素向左平移一个像素
for i in range(pic.shape[0]):
if i < 21:
pic[:, i] = pic[:, i+1]
# 对平移后的图像进行预测
p = model.predict(pic.reshape(1, x_test.shape[1], x_test.shape[2], 1))
print(p)
c = np.argmax(p)
print('CNN预测结果:', c)
得到的模型输出结果如下所示:
[[1.3430370e-05 9.9989212e-01 2.0535077e-05 2.6301734e-07 4.3278211e-05
5.9122913e-06 1.5874346e-05 6.2533190e-06 2.0079199e-06 4.1732173e-07]]
CNN预测结果: 1
看以看到,与深度前馈神经网络模型的情况相比,使用 CNN 架构得到的预测结果能够以更大的输出概率将平移后的图像预测为 1。
相关链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法