ResNet-系列 实现对自己的数据集进行分类
本文以ResNet-50为例
准备好自己的数据集
新建data.py对数据进行训练、验证、测试划分。
import os
import glob
import random
import shutil
dataset_dir = './data/'
train_dir = './images/train/'
valid_dir = './images/valid/'
test_dir = './images/test/'
train_per = 0.8
valid_per = 0.1
test_per = 0.1
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
for root, dirs, files in os.walk(dataset_dir):
for sDir in dirs:
imgs_list = glob.glob(os.path.join(root, sDir)+'/*.jpg')
random.seed(666)
random.shuffle(imgs_list)
imgs_num = len(imgs_list)
train_point = int(imgs_num * train_per)
valid_point = int(imgs_num * (train_per + valid_per))
for i in range(imgs_num):
if i < train_point:
out_dir = train_dir + sDir + '/'
elif i < valid_point:
out_dir = valid_dir + sDir + '/'
else:
out_dir = test_dir + sDir + '/'
makedir(out_dir)
out_path = out_dir + os.path.split(imgs_list[i])[-1]
shutil.copy(imgs_list[i], out_path)
print('Class:{}, train:{}, valid:{}, test:{}'.format(sDir, train_point, valid_point-train_point, imgs_num-valid_point))
准备好数据集以后运行main.py
import torch
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import numpy as np
import matplotlib.pyplot as plt
import os
#一堆数据增强的trick
image_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
#输入数据路径
dataset = './images'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'valid')
#batch_size以及类别数
batch_size = 32
num_classes = 2
data = {
'train': datasets.ImageFolder(root=train_directory, transform=image_transforms['train']),
'valid': datasets.ImageFolder(root=valid_directory, transform=image_transforms['valid'])
}
train_data_size = len(data['train'])
valid_data_size = len(data['valid'])
train_data = DataLoader(data['train'], batch_size=batch_size, shuffle=True)
valid_data = DataLoader(data['valid'], batch_size=batch_size, shuffle=True)
print(train_data_size, valid_data_size)
resnet50 = models.resnet50(pretrained=True)
for param in resnet50.parameters():
param.requires_grad = False
#resnet50
fc_inputs = resnet50.fc.in_features
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.5),
#nn.Linear output layer
nn.Linear(256, 2),
nn.LogSoftmax(dim=1)
)
resnet50 = resnet50.to('cuda:0')
loss_func = nn.NLLLoss()
optimizer = optim.Adam(resnet50.parameters())
def train_and_valid(model, loss_function, optimizer, epochs=25):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
history = []
best_acc = 0.0
best_epoch = 0
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch + 1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(train_data):
inputs = inputs.to(device)
labels = labels.to(device)
# 因为这里梯度是累加的,所以每次记得清零
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(valid_data):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_function(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss / train_data_size
avg_train_acc = train_acc / train_data_size
avg_valid_loss = valid_loss / valid_data_size
avg_valid_acc = valid_acc / valid_data_size
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if best_acc < avg_valid_acc:
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
print(
"Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch + 1, avg_valid_loss, avg_train_acc * 100, avg_valid_loss, avg_valid_acc * 100,
epoch_end - epoch_start
))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
torch.save(model, 'models/' + dataset + '_model_' + str(epoch + 1) + '.pt')
return model, history
#迭代次数设置
num_epochs = 15
trained_model, history = train_and_valid(resnet50, loss_func, optimizer, num_epochs)
#模型保存的路径
torch.save(history, 'models/' + dataset + '_history.pt')
history = np.array(history)
plt.plot(history[:, 0:2])
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1)
plt.savefig(dataset + '_loss_curve.png')
plt.show()
plt.plot(history[:, 2:4])
plt.legend(['Tr Accuracy', 'Val Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig(dataset + '_accuracy_curve.png')
plt.show()
训练验证结果如下图所示
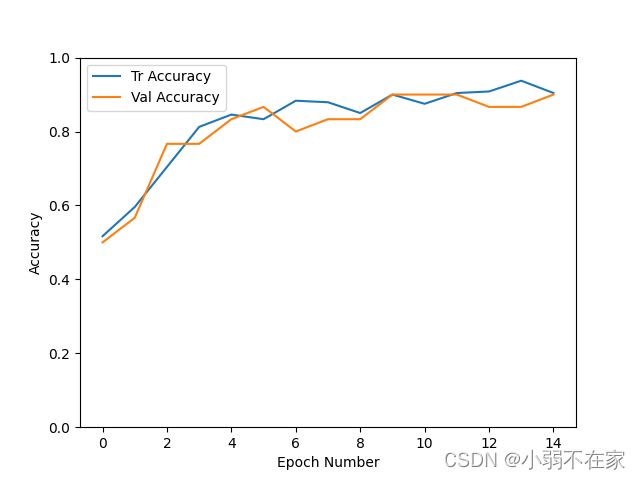

调训练好的模型测试一下
import torch
import torchvision
import torchvision.transforms as transforms
from PIL import Image
def pridict():
device="cuda" if torch.cuda.is_available() else "cpu"
path= 'images_model_15.pt'
model = torch.load(path)
model=model.to(device)
model.eval()
img=Image.open('XXXX')
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.226, 0.224, 0.225])
])
img = img.convert("RGB") # 如果是标准的RGB格式,则可以不加
img = transform(img)
img = img.unsqueeze(0)
img = img.to(device)
with torch.no_grad():
py = model(img)
'''
torch.max()这个函数返回的是两个值,第一个值是具体的value(我们用下划线_表示),第二个值是value所在的index
下划线_ 表示的就是具体的value,也就是输出的最大值。
数字1其实可以写为dim=1,这里简写为1,python也可以自动识别,dim=1表示输出所在行的最大值
'''
_,predicted = torch.max(py, 1) # 获取分类结果
#预测结果的标签
classIndex = predicted.item()
print("预测结果",classIndex)
if __name__ == '__main__':
pridict()