pytorch学习之基于resnet训练flower图像分类模型
数据预处理部分:
数据增强:torchvision中transforms模块自带功能,比较实用
数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可
DataLoader模块直接读取batch数据
首先,导入需要的各种库
import os
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
from torchvision import transforms, models, datasets
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image
step1.数据预处理
1.引入数据路径
data_dir = './flower_data/'
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'
flower_data文件夹:

train文件夹,同一类别的花放在一个文件夹,按序命名,方面后续datasets.ImageFolder操作
2.制作数据源:
data_transforms中指定了所有图像预处理操作
data_transforms = {
'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(224),#从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
]),
'valid': transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
注:
transforms使用中文文档:https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-transform/
ImageFolder假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字
batch_size = 8
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}
class_names = image_datasets['train'].classes #获得每种花组成的列表
注:
datasets使用中文文档:https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-datasets/
datasets.ImageFolder详解参考:https://blog.csdn.net/qq_39507748/article/details/105394808
torch.utils.data.DataLoader使用中文文档:https://pytorch-cn.readthedocs.io/zh/latest/package_references/data/
打印image_datasets包含的信息:
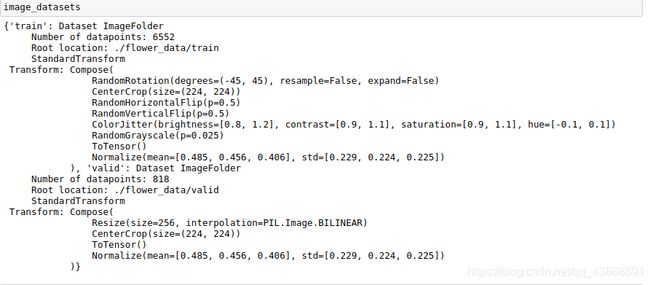
打印dataloaders返回训练集和验证集的迭代器:

打印训练集和验证集的图片数量:

3.读取标签对应的实际名字
with open('cat_to_name.json', 'r') as f:
cat_to_name = json.load(f)
打印输出

``
4. 展示数据
注意tensor的数据需要转换成numpy的格式,而且还需要还原回标准化的结果
def im_convert(tensor):
""" 展示数据"""
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1,2,0)
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))
image = image.clip(0, 1)
return image
fig=plt.figure(figsize=(20, 12))
columns = 4
rows = 2
dataiter = iter(dataloaders['valid'])
inputs, classes = dataiter.next()
for idx in range (columns*rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))])
plt.imshow(im_convert(inputs[idx]))
plt.show()
结果:

step2.加载models中提供的模型
,并且直接用训练的好权重当做初始化参数
1.是否用GPU训练
# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
![]()
2.我们使用训练好的resnet
model_ft = models.resnet152()
model_ft
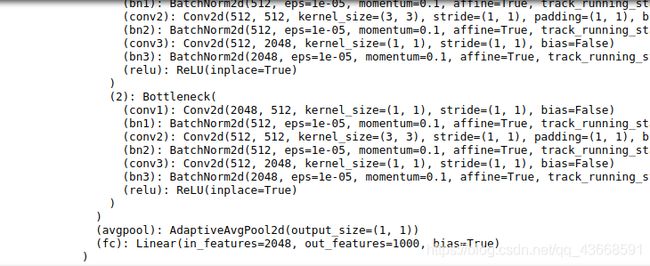
截取最后输出部分,可以看到全连接层out_feature=1000,我们要修改为自己的输出
3.参考pytorch官网例子,定义图像分类模型
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
#是否用人家训练好的特征来做
feature_extract = True
def set_parameter_requires_grad(model, feature_extracting): #使用resnet训练好的权重参数,不再训练
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# 选择合适的模型,不同模型的初始化方法稍微有点区别
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet152
"""
model_ft = models.resnet152(pretrained=use_pretrained) #下载resnet模型到本地
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102), #全连接层输出改为我们的图像类别102
nn.LogSoftmax(dim=1)) #在softmax的结果上再做多一次log运算
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg16(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
4.设置哪些层需要训练
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)
#GPU计算
model_ft = model_ft.to(device)
# 模型保存
filename='checkpoint.pth'
# 是否训练所有层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
打印
![]()
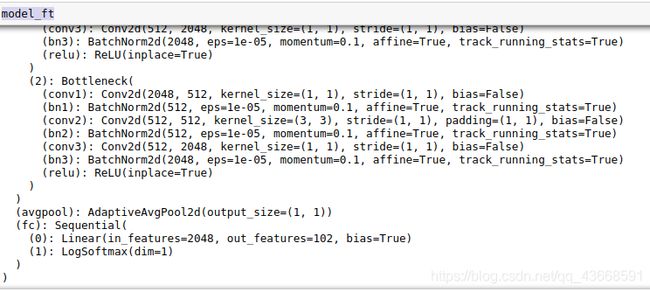
打印模型,可以看到最后全连接层的输出已经改为102
**
5.优化器设置
# 优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#optim.lr_scheduler学习率调整策略,学习率每7个epoch衰减成原来的1/10
#最后一层已经LogSoftmax()了,所以不能nn.CrossEntropyLoss()来计算了,nn.CrossEntropyLoss()相当于logSoftmax()和nn.NLLLoss()整合
criterion = nn.NLLLoss()
6.训练模块
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename): #is_inception是否使用其他的网络
since = time.time()
best_acc = 0
"""
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
model.class_to_idx = checkpoint['mapping']
"""
model.to(device)
val_acc_history = []
train_acc_history = []
train_losses = []
valid_losses = []
LRs = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 训练和验证
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # 训练
else:
model.eval() # 验证
running_loss = 0.0
running_corrects = 0
# 把数据都取个遍
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 清零
optimizer.zero_grad()
# 只有训练的时候计算和更新梯度
with torch.set_grad_enabled(phase == 'train'):
if is_inception and phase == 'train':
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:#resnet执行的是这里
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# 训练阶段更新权重
if phase == 'train':
loss.backward()
optimizer.step()
# 计算损失
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
time_elapsed = time.time() - since
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 得到最好那次的模型
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
state = {
'state_dict': model.state_dict(),
'best_acc': best_acc,
'optimizer' : optimizer.state_dict(),
}
torch.save(state, filename)
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
scheduler.step(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRs.append(optimizer.param_groups[0]['lr'])
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 训练完后用最好的一次当做模型最终的结果
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
训练中动态调整学习率lr,optimizer.param_groups可看:https://blog.csdn.net/bc521bc/article/details/85864555
model.parameters()与model.state_dict()说明可参考:https://zhuanlan.zhihu.com/p/270344655
step3.开始训练
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))
输出结果(我的电脑训练了一个多小时):
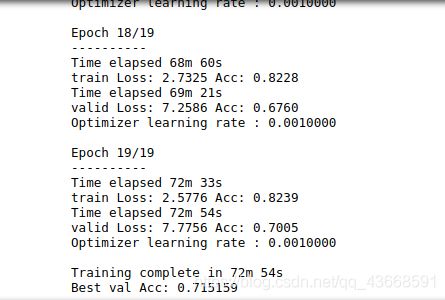
准确率达到百分之七十多还算不错
接下来,可以使用已保存的最优参数权重和优化器对所有层再进行训练,因为跑的结果比较久,先给出当前结果展示
step4.展示预测结果
1.测试数据预处理
测试数据处理方法需要跟训练时一致
crop操作的目的是保证输入的大小是一致的
标准化操作也是必须的,用跟训练数据相同的mean和std,但是需要注意一点训练数据是在0-1上进行标准化,所以测试数据也需要先归一化
最后一点,PyTorch中颜色通道是第一个维度,跟很多工具包都不一样,需要转换
def process_image(image_path):
# 读取测试数据
img = Image.open(image_path)
# Resize,thumbnail方法只能进行缩小,所以进行了判断
if img.size[0] > img.size[1]:
img.thumbnail((10000, 256))
else:
img.thumbnail((256, 10000))
# Crop操作,将图片转化为224*224
left_margin = (img.width-224)/2
bottom_margin = (img.height-224)/2
right_margin = left_margin + 224
top_margin = bottom_margin + 224
img = img.crop((left_margin, bottom_margin, right_margin,
top_margin))
# 相同的预处理方法
img = np.array(img)/255 #归一化
mean = np.array([0.485, 0.456, 0.406]) #provided mean
std = np.array([0.229, 0.224, 0.225]) #provided std
img = (img - mean)/std #标准化
# 注意颜色通道应该放在第一个位置
img = img.transpose((2, 0, 1))
return img
注:crop()图像剪裁函数,可参考:https://blog.csdn.net/qq_28641891/article/details/104306864
2.展示数据
def imshow(image, ax=None, title=None):
"""展示数据"""
if ax is None:
fig, ax = plt.subplots()
# 颜色通道还原
image = np.array(image).transpose((1, 2, 0))
# 预处理还原
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
image = np.clip(image, 0, 1)
ax.imshow(image)
ax.set_title(title)
return ax
image_path = 'image_06621.jpg'
img = process_image(image_path)
imshow(img)
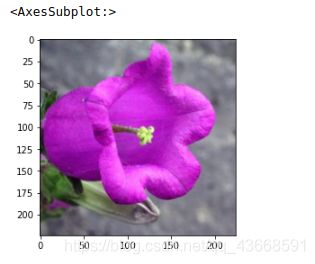
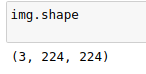
3.对一个batch的数据进行测试
# 得到一个batch的测试数据
dataiter = iter(dataloaders['valid'])
images, labels = dataiter.next()
model_ft.eval()
if train_on_gpu:
output = model_ft(images.cuda()) #utput表示对一个batch中每一个数据得到其属于各个类别的可能性
else:
output = model_ft(images)
打印output,有8张图片,每个图片有102种分类结果

_, preds_tensor = torch.max(output, 1) #得到概率最大的那个
preds = np.squeeze(preds_tensor.numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())
preds
![]()
展示预测结果:
fig=plt.figure(figsize=(20, 12))
columns =4
rows = 2
for idx in range (columns*rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
plt.imshow(im_convert(images[idx]))
ax.set_title("{} ({})".format(cat_to_name[str(preds[idx])], cat_to_name[str(labels[idx].item())]),
color=("green" if cat_to_name[str(preds[idx])]==cat_to_name[str(labels[idx].item())] else "red"))
plt.show() #绿色名字为预测正确,红色名字为预测错误

深度学习小白,欢迎交流