C语言突破进阶-指针进阶
C语言突破进阶-指针进阶
- 0. Intro
- 1. 字符指针
-
- 1.1 字符串的首地址
- 1.2 练习题(from 剑指offer)
- 2. 指针数组
-
- 2.0 回忆指针数组是什么
- 2.1 指针数组的定义和打印方式
- 3. 数组指针
-
- 3.1 数组指针的定义
- 3.2 &数组名VS数组名
- 3.3 使用数组指针
- 3.4 数组指针的加减
- 4. 数组参数、指针参数
-
- 4.1 一维数组传参
- 4.2 二维数组传参
- 4.3 一级指针传参
- 4.4 二级指针传参
- 5. 函数指针
-
- 5.1 函数有地址
- 5.2 书写函数指针
- 5.3 使用函数指针
- 5.4 阅读两段有趣的代码
- 5.5 函数指针练习
- 6. 函数指针数组
-
- 6.1 转移表
- 7. 指向函数指针数组的指针
- 8. 回调函数
-
- 8.0 什么是回调函数
- 8.1 思考冒泡排序的问题
- 8.2 回调函数,模拟实现qsort
-
- 8.2.1 实现cmp函数
-
- 8.2.1.1 `void*`
- 8.2.1.2 利用`void*`完成cmp
- 8.2.2 用冒泡排序模拟实现qsort
- 9. sizeof/strlen练习题
-
- 9.1 sizeof+数组
- 9.2 sizeof和strlen
-
- 9.2.1 没有`\0`存在
- 9.2.2 有`\0`存在
- 9.2.3 指针形式
- 9.3 二维数组
- 10. 指针练习题
-
- 10.1
- 10.2
- 10.3
- 10.4
- 10.5
- 10.6
- 10.7
- 10.8
深入理解指针的准备前提是知道指针是什么,之前也已经有所大致了解了,指针,数组指针,指针数组,或是二级指针的概念,下面先做一个回顾
0. Intro
- 指针就是个变量,用来存放地址,地址唯一标识一块内存空间。
- 指针的大小是固定的4/8个字节(32位平台/64位平台)。
- 指针是有类型,指针的类型决定了指针的±整数的步长,指针解引用操作的时候的权限。
- 指针的运算。
1. 字符指针
1.1 字符串的首地址
对于1个单一的字符,放到指针变量中去
char ch = 'w';
char* p = &ch;
那对于一个字符串
char* p1 = "abcdcef";
这样的一行代码的意思实际上是把这个字符串的第一个字符放到了变量中,也就是首字符的地址
倘若我要进行如下操作
char* p1 = "abcdcef";
*p1 = 'w';
是不可以的,因为这个首地址是只读的,相当于
const char*p1="abcdcef";
1.2 练习题(from 剑指offer)
int main()
{
char str1[] = "abcdef";
char str2[] = "abcdef";
char* str3 = "abcdef";
char* str4 = "abcdef";
if (str1 == str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if (str3 == str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}
这里str3和str4指向的是一个同一个常量字符串。C/C++会把常量字符串存储到单独的一个内存区域,当几个指针。指向同一个字符串的时候,他们实际会指向同一块内存。但是用相同的常量字符串去初始化不同的数组的时候就会开辟出不同的内存块。所以str1和str2不同,str3和str4相同。
2. 指针数组
2.0 回忆指针数组是什么
int* arr1[10]; //整形指针的数组 存放的是int*
char *arr2[4]; //一级字符指针的数组 存放的是char*
char **arr3[5];//二级字符指针的数组 存放的是
初始化
int** arr[4] = { 0 };
2.1 指针数组的定义和打印方式
char* arr[] = { "abcdef", "qwer", "zhangsan" };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
{
printf("%s\n", arr[i]);
}

3. 数组指针
3.1 数组指针的定义
什么是数组指针?
我们已经熟悉:
整形指针: int * pint; 能够指向整形数据的指针。
浮点型指针: float * pf; 能够指向浮点型数据的指针。
那数组指针应该是:能够指向数组的指针。
下面来对于数组指针和指针数组做一个区分对比
int *p1[10];
int (*p2)[10];
//p1, p2分别是什么?
我们应该这么看,首先,看到前一个先p1先是和数组结合的,那么说明本质上首先它是一个数组,其次,看到左边的int * 说明数组里面放的是指针
那么int (*p2)[10];呢?
解释:p先和
*结合,说明p是一个指针变量,然后指着指向的是一个大小为10个整型的数组。所以p是一个指针,指向一个数组,叫数组指针。
这里要注意:[]的优先级要高于*号的,所以必须加上()来保证p先和*结合。
3.2 &数组名VS数组名
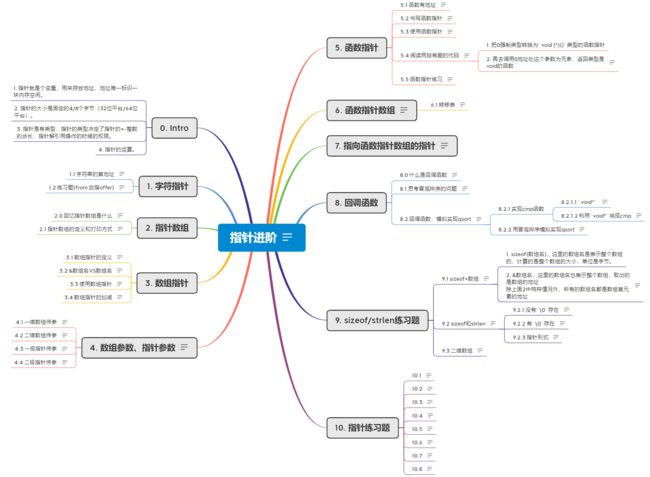
欲探讨&数组名和数组名的关系,我们来看一下如下的代码
int main()
{
int arr[10] = { 0 };
printf("%p\n", arr);
printf("%p\n", arr+1);
printf("%p\n", &(arr[0]));
printf("%p\n", &(arr[0])+1);
printf("%p\n", &arr);
printf("%p\n", &arr+1);
return 0;
}
首先可以发现前两组的输出是完全一样的,那么我们可以得出这两组其实是一样的,数组名在这里就是首元素的地址
但是第三组数据并不一样,
arr+1和&arr+1不同,其实计算一下发现&arr和&arr+1之间相差了40字节(DEC),这是因为拿出的是第三组是整个数组的地址⚡️实际上⚡️ &arr 表示的是数组的地址,而不是数组首元素的地址。
3.3 使用数组指针
//存了char数组
char arr[5];
char(*pa)[5] = &arr;
//数组中存放的是指针,再用指针变量来保存
int* parr[6];
int* (*pp)[6] = &arr;
示意图如下:

说了半天,那数组指针有什么用呢?
难道是这样用的吗?
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int*p = arr;
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", *(p + i));
}
return 0;
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int(*p)[10] = &arr;
for (int i = 0; i < 10; i++)
{
printf("%d", *((*p) + 1));
}
return 0;
}
用下面这种数组指针的方法来取代上面整形指针的方法?不,这恰恰使得更复杂
一般常常使用在二维数组中
示例如下
void print(int a[3][5], int r, int c)
{
int i = 0;
int j = 0;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", a[i][j]);
}
printf("\n");
}
}
//传的是数组指针
void print(int(*p)[5], int r, int c)
{//二维数组的数组名表示首元素地址,表示的是第一行
int i = 0;
for (i = 0; i < r; i++)
{
int j = 0;
for (j = 0; j < c; j++)
{
//*(p+i) 相当于拿到了二维数组的第i行,也相当于第i行的数组名
//数组名表示首元素的地址,其实也是第i行第一个元素的地址
printf("%d ", *(*(p + i) + j));
// p[i][j]
//p是第一行的地址
//p+i是第i行的地址
//*(p+i) 是第i行第一个元素的地址
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
print(arr,3,5);
return 0;
}
小结: 分辨如下的几个分别是什么
int arr[5]; int *parr1[10]; int (*parr2)[10]; int (*parr3[10])[5];
最后一个比较难以理解,图示解释一下


3.4 数组指针的加减
//数组指针 - 指向数组的指针
int arr[10];
int* p = arr;
int (*p2)[10] = &arr;//取出的是数组的地址,既然是数组的地址,就应该放到数组指针变量中,int (*)[10]
//p2就是一个数组指针

4. 数组参数、指针参数
我们之所以要常常用到复杂的指针类型,似乎都是因为在函数的传递时,我们会常常把【数组】或者【指针】传给函数
4.1 一维数组传参
下面哪些是不对的?
#include 先是传test(arr)
我们知道数组传参的时候,形参是可以写成数组形式的
数组名相当于首元素地址所以写成指针也可以通过
因此前三者是对的书写方式
再看test2(arr2)
那么如果我要传的是指针数组,函数内接收参数也可以选择把首元素地址化成指针也可以用数组形式
所以后面两种情况也是正确的输入方式
4.2 二维数组传参
void test(int arr[3][5])//ok?
{}
void test(int arr[][])//ok?
{}
void test(int arr[][5])//ok?
{}
//总结:二维数组传参,函数形参的设计只能省略第一个[]的数字。
//因为对一个二维数组,可以不知道有多少行,但是必须知道一行多少元素。
//这样才方便运算。
void test(int* arr)//ok?
{}
void test(int* arr[5])//ok?
{}
void test(int(*arr)[5])//ok?
{}
void test(int** arr)//ok?
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);
}
我们还是区分一下上半区(传数组形式)和下半区(传指针形式)
先看上半区
第二种写法是错的,因为形参是二维数组,行是可以省略的,但是列不可以省略再看下半区,分析一下指针形式,由于传的是数组的首元素地址,所以相当于是第一行的地址,那么类型就应该是
int(*)[5],
第一种写法是错的,传了整个二维数组却用一个整形指针接收肯定是错的
第二种也是错的,因为这个是数组,但是我们明显要的是指针
第四种也是错的,因为参数是二级指针对应传的时候应该是&arr才对,只要传的参数是对的话,可以这样当作形参
4.3 一级指针传参
#include 4.4 二级指针传参
#include 当函数的参数为二级指针的时候,可以接收什么参数?
void test(char** p)
{
}
int main()
{
char c = 'b';
char* p = &c;
char** pp = &pc;
char* arr[10];
test(&p);
test(pp);
test(arr);
return 0;
}
5. 函数指针
5.1 函数有地址
函数指针就是一个指向函数的指针,这个有点难度
首先谈到指针,先找地址,函数是可以%p打出地址的
int Add(int x, int y)
{
return x + y;
}
int main()
{
printf("%p\n", &Add);
printf("%p\n", Add);
}
先明确一点,&Add其实和Add是一样的,这毋庸置疑
5.2 书写函数指针
接下来我们就要用指针变量来保存函数地址,对于上述函数来说
其实就是和数组指针一样,先判断类型
int (*) ( int , int );
然后给他名字
int (*pAdd) ( int , int )=&Add;
下面来测试一下写一个
void test(char* str)的指针
答案是void (*ptest) (char *)=test;
5.3 使用函数指针
int (* pAdd)(int, int) = &Add;//pf是函数指针
int sum = (*pAdd)(2,3);
printf("%d\n", sum);
这里操作实际上在将存函数的指针变量解引用,然后传参数,最后将返回值给到sum,那么如果这里打印出来sum的就是相当于我执行了函数,输出5
继续尝试
这次我定义好指针之后直接就调用
int (* pf)(int, int) = Add;//pf是函数指针
int sum = pf(2, 3);
printf("%d\n", sum);
也是可以正常输出5
小结:
所以说我们用函数指针的话呢,既可以使用带*的也可以使用不带星号的这直接写指针变量名,但是要注意凡是要带星号的话一定要记住打上括号,不然就错了
5.4 阅读两段有趣的代码
下面的代码来自于《C陷阱和缺陷》
//代码1
(*(void (*)())0)();
//代码2
void (*signal(int , void(*)(int)))(int);
第一段代码
- 把0强制类型转换为
void (*)()类型的函数指针 - 再去调用0地址处这个参数为无参,返回类型是void的函数
第二段代码
signal是一个函数声明,这个函数的函数参数有两个,第一个是int类型,第二个是函数指针,该指针指向的函数参数int,返回类型是void
signal函数的返回类型也是函数指针,该指针指向的函数参数int,返回类型是void
可以试着简化一下
typedef void(* pfun_t)(int);//把函数指针重新命名
pfun_t signal(int, pfun_t);
5.5 函数指针练习
⚡️设有以下函数void fun(int n,char *s){……},则下面对函数指针的定义和赋值
答:void (*pf)(int n,char *s); pf=fun;
⚡️定义一个函数指针,指向的函数有两个int形参并且返回一个函数指针,返回的指针指向一个有一个int形参且返回int的函数?下面哪个是正确的?
答:int (*(*F)(int, int))(int)
6. 函数指针数组
存放函数指针的数组,那这个数组就叫函数指针数组
定义方法
int (*parr1[10])();
下面有几个函数,注意这些函数的返回值都是一样的,可以放入函数指针数组
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int (*pf1)(int, int) = Add;
int (*pf2)(int, int) = Sub;
int (*pf3)(int, int) = Mul;
int (*pf4)(int, int) = Div;
int (*pfArr[4])(int, int) = {Add, Sub, Mul, Div};//函数指针数组
return 0;
}
下面如果我要打印一下这个函数
int i = 0;
for (i = 0; i < 4; i++)
{
//int ret = (*pfArr[i])(8, 4);
int ret = pfArr[i](8, 4);
printf("%d\n", ret);
}
return 0;
以上加✳号与否都是正确的
6.1 转移表
函数指针数组的用途:转移表
函数指针数组实现简易计算器的例子
#include 7. 指向函数指针数组的指针
套一下娃
指向函数指针数组的指针是一个指针,指针指向一个数组,数组的元素都是函数指针
int Add(int x, int y)
{
return x + y;
}
int main()
{
int (*pa)(int, int) = Add;//函数指针
int (* pfA[4])(int, int);//函数指针的数组
int (* (*ppfA)[4])(int, int) = &pfA;//ppfA 是一个指针,该指针指向了一个存放函数指针的数组
return 0;
}
8. 回调函数
8.0 什么是回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一
个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该
函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或
条件进行响应。
接下来用回调函数来实现一下计算器
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void calc(int (*pf)(int, int))
{
int x = 0;
int y = 0;
int ret = 0;
printf("输入2个操作数:>");
scanf("%d %d", &x, &y);
ret = pf(x, y);
printf("ret = %d\n", ret);
}
int main()
{
int input = 0;
do{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input){
case 1:
calc(Add);
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误\n");
break;
}
} while (input);
return 0;
}
8.1 思考冒泡排序的问题
void bubble_sort(int arr[], int sz)
{
//趟数
int i = 0;
for (i = 0; i < sz - 1; i++){
//每一趟冒泡排序的过程
//确定的一趟排序中比较的对数
int j = 0;
for (j = 0; j < sz-1-i; j++){
if (arr[j] > arr[j + 1]){
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
先写一个冒泡排序,我们发现其实这个冒泡排序函数的功能是极度有限的,因为似乎只能对int类型进行排序,倘若我要对double,float,甚至自定义的结构体进行排序,这些都是实现不了的,于是思考如何实现
我们利用qsort库函数可以实现
对qsort本质感兴趣的可以看看之前写的一篇八大排序–高质量总结 干净又卫生https://blog.csdn.net/Allen9012/article/details/121818012
8.2 回调函数,模拟实现qsort
我们结合使用回调函数,模拟实现qsort(采用冒泡的方式)
先看一下MSDN中关于qsort的使用说明

参数很多,关键在于需要传函数作为参数,这个函数是需要自己自定义提供的
我们接下来使用一下qsort函数,在此之前先解释一下qsort的参数
8.2.1 实现cmp函数
8.2.1.1 void*
在写cmp之前先写一下void*
void* 是一种无类型的指针,无具体类型的指针
void* 的指针变量可以存放任意类型的地址
int a = 10; void* p = &a;
void* 的指针不能直接进行解引用操作
但是可以强制类型转换到其他类型指针后再解引用
void* 的指针不能直接进行±整数
8.2.1.2 利用void*完成cmp
我们现在设计的cmp是针对于int类型的一个升序qsort
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++){
printf("%d ", arr[i]);
}
printf("\n");
}
//比较e1和e2指向的元素
int cmp_int(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;
}
//测试qsort排序整型数组
void test1()
{
int arr[] = { 1,4,2,6,5,3,7,9,0,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
}
int main()
{
test1();
return 0;
}
![]()
下面再对结构体进行定制
struct Stu
{
char name[20];
int age;
float score;
};
//为什么这里要分开来写成三个?是因为防止相减减到0.1之后int强转为0,返回相等
int cmp_stu_by_socre(const void* e1, const void* e2)
{
if (((struct Stu*)e1)->score > ((struct Stu*)e2)->score) {
return 1;
}
else if (((struct Stu*)e1)->score < ((struct Stu*)e2)->score) {
return -1;
}
else {
return 0;
}
}
int cmp_stu_by_age(const void* e1, const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
int cmp_stu_by_name(const void* e1, const void* e2)
{
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
void print_stu(struct Stu arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s %d %f\n", arr[i].name, arr[i].age, arr[i].score);
}
printf("\n");
}
//测试qsort排序结构体数据
void test2()
{
struct Stu arr[] = { {"zhangsan",20,87.5f},{"lisi",22,99.0f},{"wangwu", 10, 68.5f} };
//按照成绩来排序
int sz = sizeof(arr) / sizeof(arr[0]);
//qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_socre);
//qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_age);
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_name);
print_stu(arr, sz);
}
int main()
{
test2();
return 0;
}
小结:对于不同的数据类型,我们只要定制不同数据类型的cmp函数就可以实现所想要的排序
8.2.2 用冒泡排序模拟实现qsort
那么知道qsort函数是如何工作的我们是否可以尝试来模拟实现qsort函数,其本质就是运用到了回调函数
思考qsort的每一个参数都有存在的意义,然后我们借助冒泡排序算法的思想,结合qsort参数的定义,来实现一个和qsort一样的可以自己定制排序要求的函数
Swap(char* buf1,char* buf2,int width)
{
int i = 0;
for (int i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void bubble_sort(void *base ,int sz, int width,int (*cmp)(const void *e1,const void *e2) )
{
//趟数
int i = 0;
for (i = 0; i < sz - 1; i++)
{
//每一趟冒泡排序的过程
//确定的一趟排序中比较的对数
int j = 0;
for (j = 0; j < sz-1-i; j++)
{
if (cmp((char*)base+j*width,(char*)base+(j+1)*width)>0)
{
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
}
}
}
void test3()
{
int arr[] = { 1,4,2,6,5,3,7,9,0,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
}
int main()
{
test3();
return 0;
}
而实现这样的模拟恰恰非常依赖于函数指针,没有函数指针是根本不能实现的
bubble_sort中void*是一个关键点,因为不知道使用者要求的是什么类型的数据,所以干脆设置成为void*,cmp函数会自定义,此时自动化成想要的指针类型,要用的时候再通过提供的width来获取数组中下一个数据的地址,来实现交换
9. sizeof/strlen练习题
9.1 sizeof+数组
求以下代码的输出结果
int main()
{
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));//数组名a单独放在sizeof内部,计算的整个数组的大小,单位是字节,4*4 = 16
printf("%d\n", sizeof(a + 0));//a表示的首元素的地址,a+0还是数组首元素的地址,是地址大小4/8
printf("%d\n", sizeof(*a));//a表示的首元素的地址,*a就是对首元素的地址的解引用,就是首元素,大小是4个字节
printf("%d\n", sizeof(a + 1));//a表示的首元素的地址,a+1是第二个元素的地址,是地址,大小就4/8个字节
printf("%d\n", sizeof(a[1]));//a[1]是数组的第二个元素,大小是4个字节
printf("%d\n", sizeof(&a)); //&a 表示是数组的地址,数组的地址也是地址,地址大小就是4/8字节
printf("%d\n", sizeof(*&a));//可以理解为*和&抵消效果,*&a相当于a,sizeof(a)是16
printf("%d\n", sizeof(&a + 1));//&a是数组的地址,&a+1 跳过整个数组后的地址,是地址就是4/8
printf("%d\n", sizeof(&a[0]));//&a[0]取出数组第一个元素的地址,是地址就是4/8
printf("%d\n", sizeof(&a[0] + 1));//&a[0]+1就是第二个元素的地址,是地址大小就是4/8个字节
return 0;
}
数组名
数组名是数组首元素的地址
这里有2个例外:
- sizeof(数组名),这里的数组名是表示整个数组的,计算的是整个数组的大小,单位是字节。
- &数组名,这里的数组名也表示整个数组,取出的是数组的地址
除上面2中特殊情况外,所有的数组名都是数组首元素的地址X86下结果:

9.2 sizeof和strlen
sizeof只关注占用空间的大小,单位是字节
sizeof不关注类型
sizeof是操作符strlen关注的字符串中
\0的为止,计算的是\0之前出现了多少个字符
strlen只针对字符串
strlen是库函数
9.2.1 没有\0存在
#include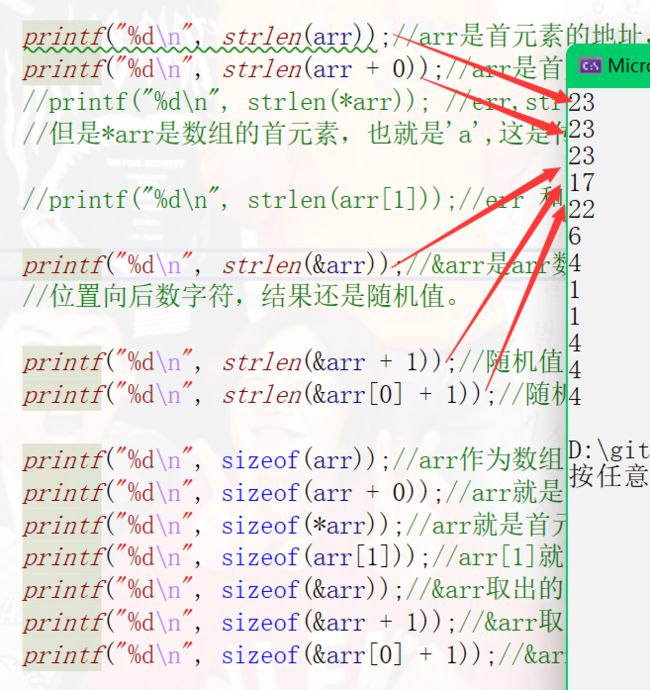
9.2.2 有\0存在
int main()
{
char arr[] = "abcdef";
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));//err
printf("%d\n", strlen(arr[1]));//err
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));//跨过一个数组的随机值
printf("%d\n", strlen(&arr[0] + 1));
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
return 0;
}

9.2.3 指针形式
现在我们不用数组形式写字符串,我么用指针形式写字符串

int main()
{
char* p = "abcdef";
printf("%d\n", strlen(p));//p中存放的是'a'的地址,strlen(p)就是从'a'的位置向后求字符串的长度,长度是6
printf("%d\n", strlen(p + 1));//p+1是'b'的地址,从b的位置开始求字符串长度是5
//printf("%d\n", strlen(*p));//err
//printf("%d\n", strlen(p[0]));//err
printf("%d\n", strlen(&p));//随机值
printf("%d\n", strlen(&p + 1));//随机值
printf("%d\n", strlen(&p[0] + 1));//p[0] -> *(p+0) -> *p ->'a' ,&p[0]就是首字符的地址,&p[0]+1就是第二个字符的地址
//从第2 字符的位置向后数字符串,长度是5
printf("%d\n", sizeof(p)); //p是一个指针变量,sizeof(p)计算的就是指针变量的大小,4 / 8个字节
printf("%d\n", sizeof(p + 1));//p是指针变量,是存放地址的,p+1也是地址,地址大小就是4/8字节
printf("%d\n", sizeof(*p));//*p访问的是1个字节
printf("%d\n", sizeof(p[0]));//p[0]--> *(p+0) -> *p 1个字节
printf("%d\n", sizeof(&p));//&p也是地址,是地址就是4/8字节,&p是二级指针
printf("%d\n", sizeof(&p + 1)); //&p是地址, + 1后还是地址,是地址就是4 / 8字节
//&p + 1,是p的地址+1,在内存中跳过p变量后的地址
printf("%d\n", sizeof(&p[0] + 1));//p[0]就是a,&p[0]就是a的地址,&p[0]+1就是b的地址,是地址就是4/8字节
return 0;
}
解释以下为什么
strlen(&p));//随机值
strlen(&p + 1)//随机值是随机值,因为传过去的是p的地址也就是说,是对于p再进行匀运算和字符串无关了


9.3 二维数组
看过一维数组之后我们来看看二维数组
int main()
{
//二维数组
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));//数组名单独放在sizeof内部,计算的是整个数组的大小
printf("%d\n", sizeof(a[0][0]));//一个元素, 4个字节
printf("%d\n", sizeof(a[0]));//a[0]表示第一行的数组名,a[0]作为数组名单独放在sizeof内部,计算的是第一行的大小。
printf("%d\n", sizeof(a[0] + 1));//(4/8)
printf("%d\n", sizeof(*(a[0] + 1)));//第一行第二个元素
printf("%d\n", sizeof(a + 1));//4/8
printf("%d\n", sizeof(*(a + 1)));//第二行大小也就是16个字节
printf("%d\n", sizeof(&a[0] + 1));//&a[0]是第一行的地址,&a[0]+1就是第二行的地址,4/8
printf("%d\n", sizeof(*(&a[0] + 1)));//相当于整个第二行,放在sizeof中就是整个第二行的大小16个字节
printf("%d\n", sizeof(*a));//没有单独发给在sizeof内部,a表示首元素的地址,*a就是二维数组的首元素,也就是第一行,16个字节
printf("%d\n", sizeof(a[3]));//感觉越界了,但是也能够计算,自动推导也是16个
return 0;
}
解释一下
sizeof(a[0] + 1)
a[0]作为第一行的数组名,没有单独放在sizeof内,所以表示首元素地址,也就是a[0][0],a[0]+1就是第一行第二个元素的地址(4/8)可以看到下面就是第一行第一个元素和第一行第二个元素,差4个字节
printf("%p\n", &a[0][0]); printf("%p\n", a[0] + 1);
解释一下
sizeof(a + 1)a是二维数组的数组名,没有&没有单独放在szieof中,a表示首元素的地址,即第一行的地址,a+1就是第二行的地址,类型是
int (*)[4]数组指针,是地址就是4/8个字节



10. 指针练习题
10.1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
2,5
10.2
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
注:0x开头代表的是16进制
第一个应该是指针+1,也就是偏移一个Test变量大小 所以是0x100014
第二个转成长整形,整形+1就是数字加减,所以应该是0x100001
第三个转成整形指针,整形指针+1就是一次加4个字节,所以是0x100004

10.3
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}
4, 2
要分析一下第二个输出的值,是很有难度的
由于通常都是在小端字节序的机器上操作,由低到高的地址,先是把整形指针化为整数后+1,又化成整形指针赋给ptr2,得到的应该是下图的位置,然后再打印的时候按照十六进制打印,取出4个字节应该是00 00 00 02,还原成小端字节序输出应该是20 00 00 00

10.4
#include 注意数组里面存放的应该是1 3 5 0 0 0,因为中间是小括号包着逗号表达式,而不是大括号,a[0]这里没有sizeof和&符号所以应该是首元素地址即第一行第一个元素的意思,则p相当于指向于1的位置,那么p[0]相当于就是1
10.5
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p, %d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}

10.6
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
10.7
int main()
{
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
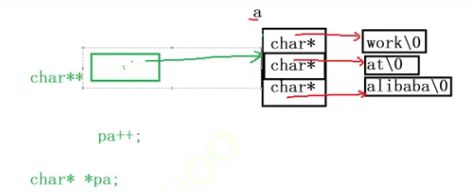
10.8
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}
这道题目的关键在于一定要注意++会使得之发生变化,同时回顾之前几道题的知识
先画一张图翻译一下
然后按照要求不断打印和移动二级指针
第一次操作之后CPP指向C+2,第二次操作之后CPP指向C+1,C+1指向"ENTER",第三次操作之后CPP[-2]指向C+3,但是不会改变CPP位置,最后一次操作CPP同样道理

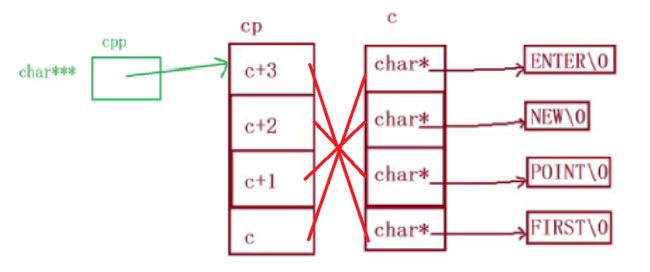

小结:
指针进阶有难度,需要更多思考和复习
关于指针问题就这么多,老铁们有收获的话一定要给个赞,多多评论哦