Pytorch深度学习——AlexNet及数据集花分类
使用Pytorch实现AlexNet
AlexNet结构
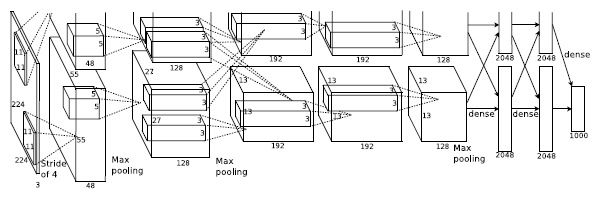
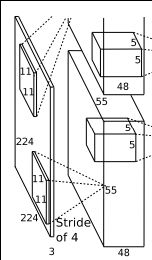
input是224×224x3,此处padding应为[1,2],即在特征矩阵左边加上一列0,右边加上两列0,上面加上一列0,下面加上两列0
特点
- 使用Relu替换之前的sigmoid的作为激活函数
- 使用数据增强Data Augmentation抑制过拟合,比如增加噪声,翻转,随机裁剪等
- 使用LRN局部响应归一化
- 在全连接层使用Dropout随机失活防止过拟合
- 使用两块GPU 进行并行计算
第一层
Conv1的处理流程是: 卷积–>ReLU–>池化–>归一化。
- 卷积,input是224×224x3,此处padding应为[1,2],即在特征矩阵左边加上一列0,右边加上两列0,上面加上一列0,下面加上两列0.使用48*2=96个11×11×3的卷积核,stride=4得到的FeatureMap为55×55×96,即output.{( 224-11+(1+2))/4+1=55}
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中,即input是55×55×96.
- 池化Maxpool1,使用3×3步长为2的池化单元,padding=0(重叠池化,步长小于池化单元的宽度),输出为27×27×96 {55−3)/2+1=27}
- 局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为27×27×96,输出分为两组,每组的大小为27×27×48
第二层

Conv2的处理流程是:卷积–>ReLU–>池化–>归一化
- 卷积,输入是2组27×27×48。使用2组,每组128个,尺寸为5×5×48的卷积核,并作了边缘填充padding=2,卷积的步长stride=1. 则输出的FeatureMap为2组,每组的大小为27×27x128. {(27+2∗2−5)/1+1=27}
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 池化运算的尺寸为3×3,步长为2,padding=0,池化后图像的尺寸为(27−3)/2+1=13,输出为13×13×256
- 局部响应归一化,使用k=2,n=5,α=10−4,β=0.75进行局部归一化,输出的仍然为13×13×256,输出分为2组,每组的大小为13×13×128
第三层
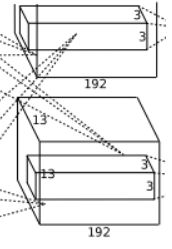
Conv3的处理流程是: 卷积–>ReLU
- 卷积,输入是13×13×256,使用2组共384,尺寸为3×3×2563的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13x384
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
第四层

Conv4和Conv3类似
- 卷积,输入是13×13×384,分为两组,每组为13×13×192.使用2组,每组192个尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13x384,分为两组,每组为13×13×192
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
第五层
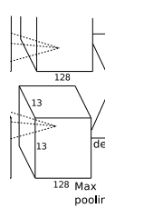
Conv5处理流程为:卷积–>ReLU–>池化
- 卷积,输入为13×13×384,分为两组,每组为13×13×192。使用2组,每组为128,尺寸为3×3×192的卷积核,做了边缘填充padding=1,卷积的步长为1.则输出的FeatureMap为13×13×256
- ReLU,将卷积层输出的FeatureMap输入到ReLU函数中
- 池化,池化运算的尺寸为3×3,步长为2,池化后图像的尺寸为 (13−3)/2+1=6,即池化后的输出为6×6×256
第六层
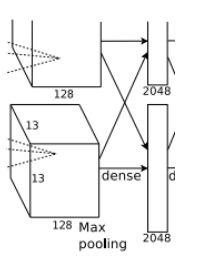
FC6全连接 -->ReLU -->Dropout
- 卷积->全连接:
输入为6×6×256,该层有4096个卷积核,每个卷积核的大小为6×6×256。由于卷积核的尺寸刚好与待处理特征图(输入)的尺寸相同,即卷积核中的每个系数只与特征图(输入)尺寸的一个像素值相乘,一一对应,因此,该层被称为全连接层。由于卷积核与特征图的尺寸相同,卷积运算后只有一个值,因此,卷积后的像素层尺寸为4096×1×1,即有4096个神经元。 - ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
- Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
第七层

FC7全连接–>ReLU–>Dropout
- 全连接,输入为4096的向量
- ReLU,这4096个运算结果通过ReLU激活函数生成4096个值
- Dropout,抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
第八层
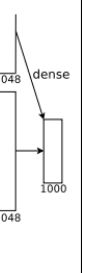
最后一步不进行失活
第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果。
参数表

数据准备
数据集下载
(此处膜拜一波大佬)-----------太阳花的小绿豆

具体实现(由于原文是使用两块GPU进行并行运算,此处我们之分析一半的模型)
model.py
import torch.nn as nn
import torch
'''
使用nn.Sequential, 将一系列的层结构打包,形成一个整体
'''
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
# 专门用来提取图像特征
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True), # inPlace=True, 增加计算量减少内存使用的一个方法
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
# 将全连接层作为一个整体,通过Dropout使其防止过拟合,一般放在全连接层和全连接层之间
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # 展平处理,从channel维度开始展平,(第一个维度为channel)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): # 返回一个迭代器,遍历我们网络中的所有模块
if isinstance(m, nn.Conv2d): # 判断层结构是否为所给定的层,比如此处判断是否为卷积层
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None: # 此处判断该层偏置是否为空
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear): # 如果是全连接层
nn.init.normal_(m.weight, 0, 0.01) # 通过正态分布来给权重赋值
nn.init.constant_(m.bias, 0)
train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from model import AlexNet
import os
import json
import time
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# 数据预处理,定义data_transform这个字典
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪,裁剪到224*224
transforms.RandomHorizontalFlip(), # 水平方向随机翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# os.getcwd()获取当前文件所在目录, "../.."返回上上层目录,".."返回上层目录
data_root = os.path.abspath(os.path.join(os.getcwd(), "..")) # get data root path
image_path = data_root + "/data_set/flower_data/" # flower data set path
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx # 获取分类的名称所对应的索引,即{'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
cla_dict = dict((val, key) for key, val in flower_list.items()) # 遍历获得的字典,将key和value反过来,即key变为0,val变为daisy
# 将key和value反过来的目的是,预测之后返回的索引可以直接通过字典得到所属类别
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file: # 保存入json文件
json_file.write(json_str)
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % flower_list[test_label[j]] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
pata = list(net.parameters()) # 查看net内的参数
optimizer = optim.Adam(net.parameters(), lr=0.0002)
save_path = './AlexNet.pth'
best_acc = 0.0
for epoch in range(10):
# train
net.train() # 在训练过程中调用dropout方法
running_loss = 0.0
t1 = time.perf_counter() # 统计训练一个epoch所需时间
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
print(time.perf_counter()-t1)
# validate
net.eval() # 在测试过程中关掉dropout方法,不希望在测试过程中使用dropout
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for data_test in validate_loader:
test_images, test_labels = data_test
outputs = net(test_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == test_labels.to(device)).sum().item()
accurate_test = acc / val_num
if accurate_test > best_acc:
best_acc = accurate_test
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, acc / val_num))
print('Finished Training')
训练结果 
predict.py
用自己数据集运算时,要将num_classes改为自己数据集类别的数目
import torch
from model import AlexNet
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("../tulips.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img) # 预处理的时候已经将channel这个维度提到最前面
# expand batch dimension
img = torch.unsqueeze(img, dim=0) # 在最前面增加一个batch维度
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = AlexNet(num_classes=5)
# load model weights
model_weight_path = "./AlexNet.pth"
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) # 将batch维度压缩掉
predict = torch.softmax(output, dim=0) # 变成概率分布
predict_cla = torch.argmax(predict).numpy() # 获得最大概率处的索引值
print(class_indict[str(predict_cla)], predict[predict_cla].item())
plt.show()
训练结果

数据存放
1、./是当前目录
2、…/是父级目录
3、/是根目录
根目录指逻辑驱动器的最上一级目录,它是相对子目录来说的。打开“我的电脑”,双击C盘就进入C盘的根目录,双击D盘就进入D盘的根目录。其它类推。根目录在文件系统建立时即已被创建,其目的就是存储子目录(也称为文件夹)或文件的目录项。电脑中的子目录很好理解,例如:1、C:\是父目录,C:\Windows就是C:\的子目录。2、C:\Windows\System32\就是C:\Windows的子目录。

训练自己的数据集
创建新的文件夹,每个文件夹对应一个类别,文件夹下存放同一类别的图片,修改split_data.py,比如修改父文件夹,子文件夹名称,路径等进行数据集和测试集的划分.
最后再从网上下载某一类别的图片来进行预测,观察模型准确率.
split_data.py
import os
from shutil import copy
import random
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
file = 'flower_data/flower_photos'
flower_class = [cla for cla in os.listdir(file) if ".txt" not in cla]
mkfile('flower_data/train')
for cla in flower_class:
mkfile('flower_data/train/'+cla)
mkfile('flower_data/val')
for cla in flower_class:
mkfile('flower_data/val/'+cla)
split_rate = 0.1
for cla in flower_class:
cla_path = file + '/' + cla + '/'
images = os.listdir(cla_path)
num = len(images)
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
image_path = cla_path + image
new_path = 'flower_data/val/' + cla
copy(image_path, new_path)
else:
image_path = cla_path + image
new_path = 'flower_data/train/' + cla
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
参考文章
参考WZMIAOMIAO的Github
AlexNet详细解读
AlexNet论文