redis底层数据结构详解
redis 底层数据结构总共有6种:
- 简单动态字符串
- 字典
- 列表
- 压缩列表
- 跳跃表
- 整数集合
接下来我们依次看一下几种数据结构:
1. 简单动态字符串
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串),而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型,并将SDS用作Redis的默认字符串表示。
当Redis需要的不仅仅是一个字符串字面量,而是一个可以被修改的字符串值时,Redis就会使用SDS来表示字符串值,比如在Redis的数据库里面,包含字符串值的键值对在底层都是由SDS实现的。
那么Redis将在数据库中创建一个新的键值对,其中:
- 键值对的键是一个字符串对象,对象的底层实现是一个保存着字符串"msg"的SDS。
- 键值对的值也是一个字符串对象,对象的底层实现是一个保存着字符串"hello world"的SDS。
又比如,如果客户端执行命令:
那么Redis将在数据库中创建一个新的键值对,其中:
- 键值对的键是一个字符串对象,对象的底层实现是一个保存了字符串"fruits"的SDS。
- 键值对的值是一个列表对象,列表对象包含了三个字符串对象,这三个字符串对象分别由三个SDS实现:第一个SDS保存着字符串"apple",第二个SDS保存着字符串"banana",第三个SDS保存着字符串"cherry"。
除了用来保存数据库中的字符串值之外,SDS还被用作缓冲区(buffer):AOF模块中的AOF缓冲区,以及客户端状态中的输入缓冲区,都是由SDS实现的,在之后介绍AOF持久化和客户端状态的时候,我们会看到SDS在这两个模块中的应用。
1.1 SDS的定义
每个sds.h/sdshdr结构表示一个SDS值:
struct sdshdr {
// 记录buf数组中已使用字节的数量
// 等于SDS所保存字符串的长度
int len;
// 记录buf数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
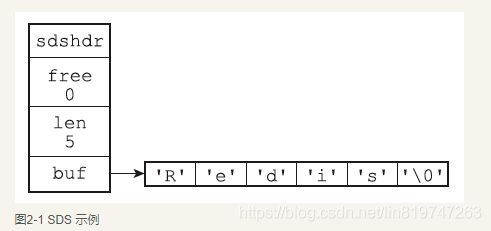
- free属性的值为0,表示这个SDS没有分配任何未使用空间。
- len属性的值为5,表示这个SDS保存了一个五字节长的字符串。
- buf属性是一个char类型的数组,数组的前五个字节分别保存了’R’、‘e’、‘d’、 ‘i’、‘s’五个字符,而最后一个字节则保存了空字符’\0’。
1.2 二进制安全
1.3 空间预分配
空间预分配用于优化SDS的字符串增长操作:当SDS的API对一个SDS进行修改,并且需要对SDS进行空间扩展的时候,程序不仅会为SDS分配修改所必须要的空间,还会为SDS分配额外的未使用空间。
其中,额外分配的未使用空间数量由以下公式决定:
- 如果对SDS进行修改之后,SDS的长度(也即是len属性的值)将小于1MB,那么程序分配和len属性同样大小的未使用空间,这时SDS len属性的值将和free属性的值相同。举个例子,如果进行修改之后,SDS的len将变成13字节,那么程序也会分配13字节的未使用空间,SDS的buf数组的实际长度将变成13+13+1=27字节(额外的一字节用于保存空字
- 如果对SDS进行修改之后,SDS的长度将大于等于1MB,那么程序会分配1MB的未使用空间。举个例子,如果进行修改之后,SDS的len将变成30MB,那么程序会分配1MB的未使用空间,SDS的buf数组的实际长度将为30 MB + 1MB + 1byte。
Redis只会使用C字符串作为字面量,在大多数情况下,Redis使用SDS(Simple Dynamic String,简单动态字符串)作为字符串表示。
总结:比起C字符串,SDS具有以下优点:
- 常数复杂度获取字符串长度。
- 杜绝缓冲区溢出。
- 减少修改字符串长度时所需的内存重分配次数。
- 二进制安全。
- 兼容部分C字符串函数。
SDS与C语言字符串对比: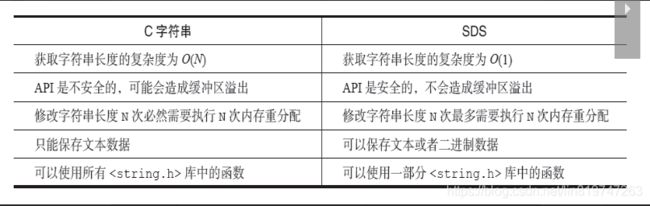
2.链表
链表提供了高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活地调整链表的长度。
作为一种常用数据结构,链表内置在很多高级的编程语言里面,因为Redis使用的C语言并没有内置这种数据结构,所以Redis构建了自己的链表实现。
链表在Redis中的应用非常广泛,比如列表键的底层实现之一就是链表。当一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的字符串时,Redis就会使用链表作为列表键的底层实现。
3.1 链表和链表节点的实现
每个链表节点使用一个adlist.h/listNode结构来表示:
typedef struct listNode {
// 前置节点
struct listNode * prev;
// 后置节点
struct listNode * next;
// 节点的值
void * value;
}listNode;
Redis的链表实现的特性可以总结如下:
- 双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(1)。
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问以NULL为终点。
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度为O(1)。
- 带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)。
- 多态:链表节点使用void*指针来保存节点值,并且可以通过list结构的dup、free
3.字典
字典,又称为符号表(symbol table)、关联数组(associative array)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。
在字典中,一个键(key)可以和一个值(value)进行关联(或者说将键映射为值),这些关联的键和值就称为键值对。
4. 跳跃表
5.整数集合
6.压缩列表
7.对象
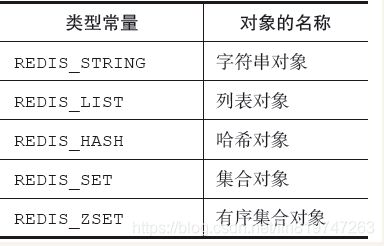
Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象,每种对象都用到了至少一种我们前面所介绍的数据结构。
Redis中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的三个属性分别是type属性、encoding属性和ptr属性:
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
类型
对象的ptr指针指向对象的底层实现数据结构,而这些数据结构由对象的encoding属性决定。
encoding属性记录了对象所使用的编码,也即是说这个对象使用了什么数据结构作为对象的底层实现,这个属性的值可以是表8-3列出的常量的其中一个。
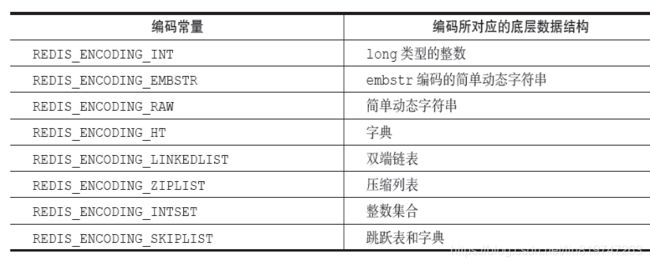
每种类型的对象都至少使用了两种不同的编码,表8-4列出了每种类型的对象可以使用的编码
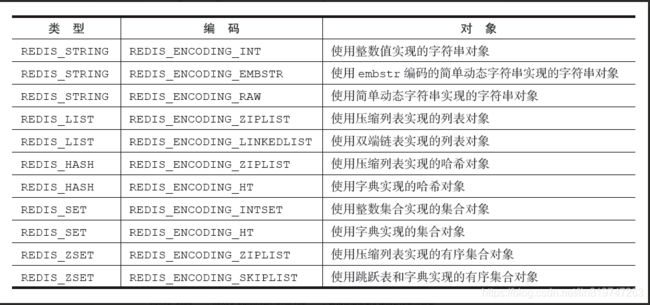
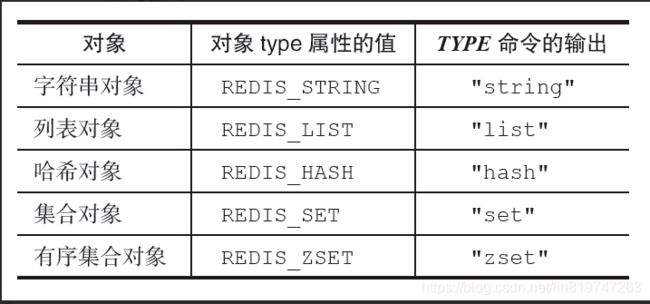
使用OBJECT ENCODING命令可以查看一个数据库键的值对象的编码: