StructuredStreaming知识总结
一、StructuredStreaming的简介
1.1 为什么要引入StructuredStreaming
spark生态系统中的sparkStreaming是一个micro-batch的准实时计算框架,它也需要一个实时计算框架,因此引入了一个新的模块,就是StructuredStreaming.
1.2 StructuredStreaming是什么
1. StructuredStreaming是一个实时计算框架
2. 是一个基于Spark SQL引擎构建的可伸缩的且具有容错性的实时流处理引擎,使用的数据模型是Dataset。
3. 也可以使用Scala,Java或Python编程语言调用StructuredStreaming的API
4. 内部的优化是SparkSql执行引擎的自动优化策略(logical plan)
5. 可以通过checkpoint和WAL进行数据容错
6. 可以保证exactly once语义
7. 可以理解为StructuredStreaming是sparkStreaming的进化版
hello world
hello world spark
hello world spark
hello world spark
hello world spark
hello world spark
1.3 Dataset与Dataframe、RDD的比较
- `RDD` 的优点
1. 面向对象的操作方式
2. 可以处理任何类型的数据
- `RDD` 的缺点
1. 运行速度比较慢, 执行过程没有优化
2. `API` 比较僵硬, 对结构化数据的访问和操作没有优化
- `DataFrame` 的优点
1. 针对结构化数据高度优化, 可以通过列名访问和转换数据
2. 增加 `Catalyst` 优化器, 执行过程是优化的, 避免了因为开发者的原因影响效率
- `DataFrame` 的缺点
1. 只能操作结构化数据
2. 只有无类型的 `API`, 也就是只能针对列和 `SQL` 操作数据, `API` 依然僵硬
- `Dataset` 的优点
1. 结合了 `RDD` 和 `DataFrame` 的 `API`, 既可以操作结构化数据, 也可以操作非结构化数据
2. 既有有类型的 `API` 也有无类型的 `API`, 灵活选择
二、StructuredStreaming的体系结构
2.1 数据模型
可以理解为 Spark 中的数据模型 Dataset 有两种形式, 一种是处理静态批量数据的 Dataset, 一种是处理动态实时流的 Dataset, 这两种 Dataset 之间的区别如下
- 流式的
Dataset需要使用readStream读取外部数据源并返回, 使用writeStream将数据写入外部存储,即StructuredStreaming的数据模型 - 批式的
Dataset需要使用read读取外部数据源并返回, 使用write将数据写入外部存储,即SparkSql的数据模型
如下图所示:
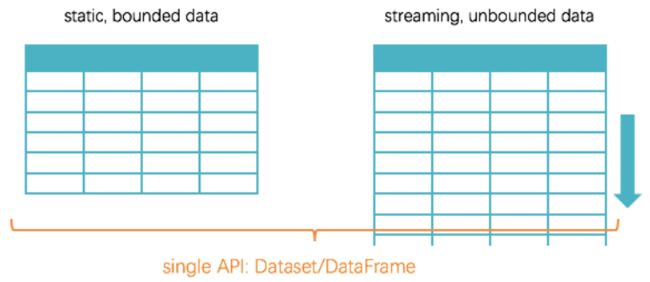
针对于StructuredStreamming,可以这样理解:
1、可以把流式的数据想象成一个不断增长, 无限无界的表
2、无论是否有界, 全都使用 Dataset 这一套 API
3、通过这样的做法, 就能完全保证流和批的处理使用完全相同的代码, 减少这两种处理方式的差异
2.2 体系结构
在 Structured Streaming 中负责整体流程和执行的驱动引擎叫做 StreamExecution
StreamExecution 如何工作?

StreamExecution 分为三个重要的部分
Source, 从外部数据源读取数据LogicalPlan, 逻辑计划, 在流上的查询计划(解析,优化,计算)Sink, 对接外部系统, 写入结果
总结
StreamExecution是整个Structured Streaming的核心, 负责在流上的查询StreamExecution中三个重要的组成部分, 分别是Source负责读取每个批量的数据,Sink负责将结果写入外部数据源,Logical Plan负责针对每个小批量生成执行计划StreamExecution中使用StateStore来进行状态的维护
三、入门案例的演示
3.1 代码演示
package com.qf.sparkstreaming.day03
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{Dataset, KeyValueGroupedDataset, SparkSession}
/**
* StuncturedStreaming的入门案例:进行单词统计
* 步骤如下:
* 1. `Socket Server` 等待 `Structured Streaming` 程序连接
* 2. `Structured Streaming` 程序启动, 连接 `Socket Server`, 等待 `Socket Server` 发送数据
* 3. `Socket Server` 发送数据, `Structured Streaming` 程序接收数据
* 4. `Structured Streaming` 程序接收到数据后处理数据
* 5. 数据处理后, 生成对应的结果集, 在控制台打印
*
*
* 代码实现如下:
*/
object _05StructuredStreamingDemo {
def main(args: Array[String]): Unit = {
//获取SparkSql的上下文对象
val spark: SparkSession = SparkSession.builder().appName("test1").master("local[*]").getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
//接收nc发送过来的数据
import spark.implicits._
val ds: Dataset[String] = spark.readStream //是一个实时的读取流对象,因此不会只读一次
.format("socket")
.option("host", "qianfeng01")
.option("port", 10087)
.load().as[String]
//数据处理
val value: KeyValueGroupedDataset[String, (String, Int)] = ds.flatMap(_.split(" ")).map((_, 1)).groupByKey(_._1)
//统计一个key中有多少对的(key,1)
val value1: Dataset[(String, Long)] = value.count()
//StruncturedStreaming必须使用writeStream.start()来执行
value1.writeStream
/**
* OutputMode.Complete():全局的数据流进行汇总,此模式一定要在聚合时才能应用
* OutputMode.APPEND():只会将新数据追加到接收器中,不能用于带有聚合的查询,是默认的
* OutputMode.UPDATE():只会将更新的数据添加到接收器中,如果没有聚合操作,相当于APPEND
*/
.outputMode(OutputMode.Complete())
.format("console")
.start() //启动数据流计算程序
.awaitTermination() //防止没有数据产生时,停止程序
}
}
3.2 WordCount 的原理
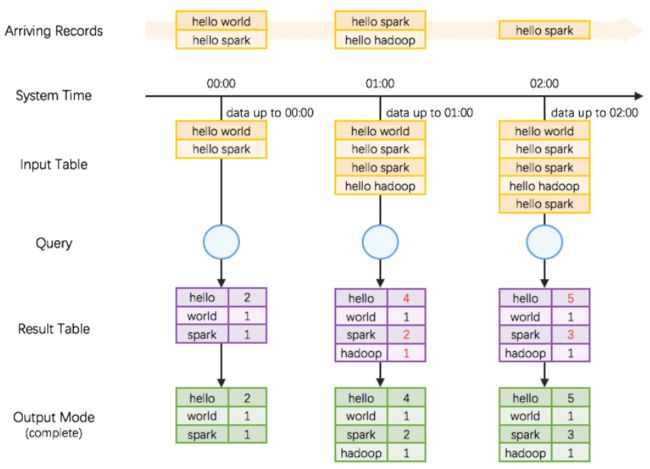
整个计算过程大致上分为如下三个部分
1、Source, 读取数据源
2、Query, 在流式数据上的查询
3、Result, 结果集生成
整个的过程如下
1、随着时间段的流动, 对外部数据进行批次的划分
2、在逻辑上, 将缓存所有的数据, 生成一张无限扩展的表, 在这张表上进行查询
3、根据要生成的结果类型, 来选择是否生成基于整个数据集的结果
总结
Dataset不仅可以表达流式数据的处理, 也可以表达批量数据的处理Dataset之所以可以表达流式数据的处理, 因为Dataset可以模拟一张无限扩展的表, 外部的数据会不断的流入到其中
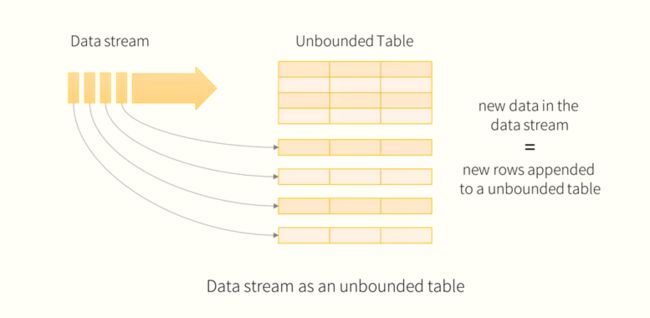
3.3 输出模式的介绍
OutputMode.Append: 追加模式,表示当DataFrame/Dataset中有新数据时,可以被写入到sink里。注意,前提是中间过程中没有聚合操作
OutputMode.Complete : 完全模式,表示当DataFrame/Dataset中有新数据时,所有行都被写入到sink里,注意,前提是中间过程中有聚合操作
OutputMode.Update: 更新模式,表示当DataFrame/Dataset中有数据更新时,只有更新的数据被写入到sink里。如果没有聚合操作,相当于Append
四、StructuredStreming的Source
4.1 读取HDFS上的json文件
4.1.1 说明
因为在生产环境中,有些数据是源源不断生产,并保存到HDFS上的,可以会产生很多很多的小文件,所以我们就可以直接使用StructuredStreaming对新产生的文件进行监听并读取,然后直接进行计算。
下面主要使用就是python脚本来模拟持续不断产生新的小文件,StructuredStreaming监听并直接计算的过程。
4.1.2 流程介绍:
第一步)使用python脚本来模拟向hdfs上写入大量的小文件
- `Python` 是解释型语言, 其程序可以直接使用命令运行无需编译, 所以适合编写快速使用的程序, 很多时候也使用 `Python` 代替 `Shell`
- 使用 `Python` 程序创建新的文件, 并且固定的生成一段 `JSON` 文本写入文件
- 在真实的环境中, 数据也是一样的不断产生并且被放入 `HDFS` 中, 但是在真实场景下, 可能是 `Flume` 把小文件不断上传到 `HDFS` 中, 也可能是 `Sqoop` 增量更新不断在某个目录中上传小文件
第二步)使用 Structured Streaming 汇总数据
- `HDFS` 中的数据是不断的产生的, 所以也是流式的数据
- 数据集是 `JSON` 格式, 要有解析 `JSON` 的能力
- 因为数据是重复的, 要对全局的流数据进行汇总和去重, 其实真实场景下的数据清洗大部分情况下也是要去重的
第三步)使用控制台展示数据
- 最终的数据结果以表的形式呈现
- 使用控制台展示数据意味着不需要在修改展示数据的代码, 将 `Sink` 部分的内容放在下一个大章节去说明
- 真实的工作中, 可能数据是要落地到 `MySQL`, `HBase`, `HDFS` 这样的存储系统中
4.1.3 程序测试
1)编写代码
package com.qf.sparkstreaming.day04
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
/**
* structuredStreaming从hdfs上读取数据
*/
object _01SourceHDFS {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder()
.appName("test1")
.master("local[*]")
.getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//为读取到的数据维护一个元数据schema.
val schemahdfs = StructType(Array(
StructField("name",DataTypes.StringType),
StructField("age",DataTypes.IntegerType)
))
//读取数据
val ds: DataFrame = session.readStream
.schema(schemahdfs) //设置表头的元数据
.json("hdfs://qianfeng01/structure") //指定hdfs的路径,读取json文件,这个目录必须提前存在
//进行数据处理,去重
//val ds: Dataset[Row] = ds.distinct()
ds.writeStream
.outputMode(OutputMode.Append())
.format("console").start()
.awaitTermination()
}
}
2)使用python脚本模拟实时上传文件到hdfs上
比如文件名:files.py 位置:/root下
import os
for index in range(10):
content = """
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
"""
file_name = "/root/text{0}.json".format(index)
with open(file_name, "w") as file:
file.write(content)
os.system("/usr/local/hadoop/bin/hdfs dfs -mkdir -p /structure/")
os.system("/usr/local/hadoop/bin/hdfs dfs -put {0} /structure/".format(file_name))
3)运行脚本,上传文件,查看idea中的console
[root@qianfeng01 ~]# python files.py
4.2 读取Kafka里的消息
4.2.1 说明
1. structuredstreaming的source接口API,有一个是KafkaSource, 用于从Kafka中读取数据。
2. 该API接口中维护着一个KafkaSourceRDD的源码,作用就是将Kafka的主题的一个分区映射成KafkaSourceRDD的一个分区
因此,可以并行的处理Kafka中的消息队列。
当然,读取kafka中的数据,可以根据偏移量的指定方式分为三种情况
earliest: 从一个分区的最早一条开始读取
latest: 从分区的最新数据开始读取
offset: 可以手动指定偏移量进行读取
4.2.2 案例
1)案例需求解析
从kafka上读取 JSON 格式的内容
##### 需求介绍
- 有一个智能家居品牌叫做 `Nest`, 他们主要有两款产品, 一个是恒温器, 一个是摄像头
- 恒温器的主要作用是通过感应器识别家里什么时候有人, 摄像头主要作用是通过学习算法来识别出现在摄像头中的人是否是家里人, 如果不是则报警
- 所以这两个设备都需要统计一个指标, 就是家里什么时候有人, 此需求就是针对这个设备的一部分数据, 来统计家里什么时候有人
Kafka生产者的数据格式:
{
"devices": {
"cameras": {
"device_id": "awJo6rH",
"last_event": {
"has_sound": true,
"has_motion": true,
"has_person": true,
"start_time": "2016-12-29T00:00:00.000Z",
"end_time": "2016-12-29T18:42:00.000Z"
}
}
}
}
使用 Structured Streaming 来过滤出来家里有人的数据
把数据转换为 时间 → 是否有人 这样类似的形式
2) 代码实现:
因为需要和 Kafka 整合, 所以在启动的时候需要加载和 Kafka 整合的包 spark-sql-kafka-0-10
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_2.11artifactId>
<version>2.2.3version>
dependency>
package com.qf.sparkstreaming.day04
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.{DataTypes, StructType}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* {
* "devices": {
* "cameras": {
* "device_id": "awJo6rH",
* "last_event": {
* "has_sound": true,
* "has_motion": true,
* "has_person": true,
* "start_time": "2016-12-29T00:00:00.000Z",
* "end_time": "2016-12-29T18:42:00.000Z"
* }
* }
* }
* }
*/
object _03KafkaSourceJson {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("test1").master("local[*]").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers","qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
.option("startingOffsets","earliest")
.option("subscribe","student").load()
//处理kafka中的数据
val last_event = new StructType()
.add("has_sound",DataTypes.BooleanType)
.add("has_motion",DataTypes.BooleanType)
.add("has_person",DataTypes.BooleanType)
.add("start_time",DataTypes.DateType)
.add("end_time",DataTypes.DateType)
val cameras = new StructType()
.add("device_id",DataTypes.StringType)
.add("last_event",last_event)
val devices = new StructType()
.add("cameras",cameras)
val schema = new StructType()
.add("devices",devices)
//映射时间格式
val jsonOptions = Map("timestampFormat" -> "yyyy-MM-dd'T'HH:mm:ss.sss'Z'")
import session.implicits._
import org.apache.spark.sql.functions._
//处理value是json的数据,然后返回的是字段value的数据是一个json数据
val frame1: DataFrame = frame.selectExpr("cast(value as String)")
.select(from_json('value, schema, jsonOptions).alias("value"))
//查询value里的has_person ,start_time,end_time
val frame2: DataFrame = frame1.
selectExpr("value.devices.cameras.last_event.has_person",
"value.devices.cameras.last_event.start_time",
"value.devices.cameras.last_event.end_time"
)
.filter($"has_person"===true)
.groupBy($"has_person",$"start_time")
.count()
frame2.writeStream
.outputMode(OutputMode.Update())
.format("console")
.start()
.awaitTermination()
}
}
测试)开启生产者,输入json数据
{"devices":{"cameras":{"device_id":"awJo6rH","last_event":{"has_sound":true,"has_motion":true,"has_person":true,"start_time":"2016-12-29T00:00:00.000Z","end_time":"2016-12-29T18:42:00.000Z"}}}}
{"devices":{"cameras":{"device_id":"awJo6rH","last_event":{"has_sound":true,"has_motion":true,"has_person":false,"start_time":"2016-12-29T00:00:00.000Z","end_time":"2016-12-29T18:42:00.000Z"}}}}
{"devices":{"cameras":{"device_id":"awJo6rH","last_event":{"has_sound":true,"has_motion":true,"has_person":true,"start_time":"2016-12-29T00:00:00.000Z","end_time":"2016-12-29T18:42:00.000Z"}}}}
{"devices":{"cameras":{"device_id":"awJo6rH","last_event":{"has_sound":true,"has_motion":true,"has_person":false,"start_time":"2016-12-29T00:00:00.000Z","end_time":"2016-12-29T18:42:00.000Z"}}}}
{"devices":{"cameras":{"device_id":"awJo6rH","last_event":{"has_sound":true,"has_motion":true,"has_person":true,"start_time":"2016-12-29T00:00:00.000Z","end_time":"2016-12-29T18:42:00.000Z"}}}}
4.2.3案例
1001 毛衣 10
1002 牙刷 1
1001 毛衣 12
读取kafka的上的student主题,别忘记开启生产者进行测试
package com.qf.sparkstreaming.day04
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{DataFrame, SparkSession}
object _02KafkaSource {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("test1").master("local[*]").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers","qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
.option("startingOffsets","earliest")
.option("subscribe","pet").load()
//处理kafka中的数据
import session.implicits._
val frame1: DataFrame = frame
.selectExpr("cast(value as string)","cast(key as string)") //kafka的value是一个字节数组,将数据转成字符串
.select($"key",$"value")
frame1.writeStream
.outputMode(OutputMode.Update())
.format("console")
.start()
.awaitTermination()
}
}
五、StructuredStreming的Sink
5.1 HDFS sink
5.1.1 案例需求
从 `Kafka` 接收数据, 从给定的数据集中, 裁剪部分列, 落地于 `HDFS`
**实现步骤**
1. 从 `Kafka` 读取数据, 生成源数据集
1. 连接 `Kafka` 生成 `DataFrame`
2. 从 `DataFrame` 中取出表示 `Kafka` 消息内容的 `value` 列并转为 `String` 类型
2. 对源数据集选择列
1. 解析 `CSV` 格式的数据
2. 生成正确类型的结果集
3. 落地 `HDFS`
5.1.2 代码实现
package com.qf.sparkstreaming.day04
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object _04SinkHdfs {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder()
.appName("test1")
.master("local[*]").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers",
"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
// .option("startingOffsets","earliest")
.option("subscribe","pet").load()
//处理一下数据
val frame1: DataFrame = frame.selectExpr("cast(value as String)")
//保存到本地磁盘
frame1.writeStream
.format("text")
// .option("path","out4") //存储到本地磁盘
.option("path","hdfs://qianfeng01/hdfssink")
.option("checkpointLocation", "checkpoint")
.start()
.awaitTermination()
}
}
5.2 Kafka sink
案例1)
package com.qf.sparkstreaming.day04
import org.apache.spark.sql.{DataFrame, SparkSession}
object _05SinkKafka {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder()
.appName("test1").master("local[*]").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers",
"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
// .option("startingOffsets","earliest")
.option("subscribe","pet").load()
//处理一下数据
val frame1: DataFrame = frame.selectExpr("cast(value as String)")
//保存到kafka中
frame1.writeStream
.format("kafka")
.option("checkpointLocation", "checkpoint")
.option("topic","good")
.option("kafka.bootstrap.servers",
"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
.start()
.awaitTermination()
}
}
案例2)
package com.qf.sparkstreaming.day04
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object _06SinkKafka {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("test1").master("local[*]").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers",
"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
// .option("startingOffsets","earliest")
.option("subscribe","pet").load()
import session.implicits._
//处理一下数据
val frame1: Dataset[String] = frame
.selectExpr("cast(value as String)").as[String]
val frame2: Dataset[String] = frame1.map(x => {
val arr: Array[String] = x.split("::")
(arr(0).toInt, arr(1), arr(2))
}).as[(Int, String, String)]
.filter(_._3.contains("Comedy")).toDF("id", "name", "info")
//落地到kafka时,如果dataset描述的是多个字段的表格形式,应该合并成一个字段,才会被当成kafka的value值进行保存。
.map(row => {
"" + row.getAs("id") + row.getAs("name") + row.getAs("info")
})
// frame2.writeStream
// .format("console")
// .start()
// .awaitTermination()
//
// //保存到kafka中
frame2.writeStream
.format("kafka")
.outputMode(OutputMode.Append())
.option("checkpointLocation", "checkpoint")
.option("topic","good")
.option("kafka.bootstrap.servers",
"qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
.start()
.awaitTermination()
}
}
5.3 Mysql Sink
5.3.1 说明
我们可以将structuredStreaming处理的数据落地到mysql中,这样的sink,需要我们自定义。
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.21version>
dependency>
5.3.2 案例演示1
案例1)PreparedStatement
package com.qf.sparkstreaming.day04
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{DataFrame, Dataset, ForeachWriter, Row, SparkSession}
object _06SinkMysql {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("test1").master("local[*]").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers","qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
// .option("startingOffsets","earliest")
.option("subscribe","pet").load()
import session.implicits._
//处理一下数据
val frame1: Dataset[String] = frame.selectExpr("cast(value as String)").as[String]
val frame2: DataFrame = frame1.map(x => {
val arr: Array[String] = x.split("::")
(arr(0).toInt, arr(1), arr(2))
}).as[(Int, String, String)].filter(_._3.contains("Comedy")).toDF("id", "name", "info")
//保存到mysql中
frame2.writeStream
.foreach(new MyWriter)
.start()
.awaitTermination()
}
}
class MyWriter extends ForeachWriter[Row]{
private var connection:Connection = _
private var statement:PreparedStatement = _
//连接mysql,打开连接
override def open(partitionId: Long, version: Long): Boolean = {
//加载驱动
Class.forName("com.mysql.jdbc.Driver")
connection= DriverManager.getConnection("jdbc:mysql://localhost:3306/sz2003_db", "root", "123456")
statement= connection.prepareStatement(s"insert into movie values (?,?,?)")
true
}
/**
* 处理方法,用于向数据库中插入数据
* @param value
*/
override def process(value: Row): Unit = {
//给问号赋值
statement.setInt(1,value.getAs("id"))
statement.setString(2,value.get(1).toString)
statement.setString(3,value.get(2).toString)
//执行
statement.execute()
}
/**
* 释放连接
* @param errorOrNull
*/
override def close(errorOrNull: Throwable): Unit = {
connection.close()
}
}
案例2)使用Statement
package com.qf.sparkstreaming.day04
import java.sql.{Connection, DriverManager, Statement}
import org.apache.spark.sql.{DataFrame, Dataset, ForeachWriter, Row, SparkSession}
object _08SinkMysql {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkSession
val session = SparkSession.builder()
.appName("hdfs_sink")
.master("local[6]")
.getOrCreate()
import session.implicits._
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers","qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
// .option("startingOffsets","earliest")
.option("subscribe","pet").load()
import session.implicits._
//处理一下数据
val frame1: Dataset[String] = frame.selectExpr("cast(value as String)").as[String]
val frame2: DataFrame = frame1.map(x => {
val arr: Array[String] = x.split("::")
(arr(0).toInt, arr(1), arr(2))
}).as[(Int, String, String)].toDF("id", "name", "category")
// 4. 落地到 MySQL
class MySQLWriter extends ForeachWriter[Row] {
private val driver = "com.mysql.jdbc.Driver"
private var connection: Connection = _
private val url = "jdbc:mysql://localhost:3306/sz2003_db"
private var statement: Statement = _
override def open(partitionId: Long, version: Long): Boolean = {
Class.forName(driver)
connection = DriverManager.getConnection(url,"root","123456")
statement = connection.createStatement()
true
}
/**
* 如果用的是Statement接口,那么要注意类型的问题,比如字符串,那就需要单引号
* 如果是PreparedStatement子接口,就不需要注意这些问题了
* @param value
*/
override def process(value: Row): Unit = {
statement.executeUpdate(s"insert into movie values(${value.get(0)}, '${value.get(1)}', '${value.get(2)}')")
}
override def close(errorOrNull: Throwable): Unit = {
connection.close()
}
}
frame2.writeStream
.foreach(new MySQLWriter)
.start()
.awaitTermination()
}
}
5.4 Trigger
package com.qf.sparkstreaming.day04
import org.apache.spark.sql._
import org.apache.spark.sql.streaming.Trigger
/**
* trigger函数:
* sparkStreaming是一个准实时的计算框架,微批处理
* structuredStreaming是一个实时的计算框架,但是底层使用的sparksql的api,
* 并且是sparkStreaming的进化版,比微批处理更快,也有微小的时间段,最快可以达到 `100ms` 左右的端到端延迟。
* 而使用trigger函数可以做到1ms的端到端延迟。
*/
object _09Trigger {
def main(args: Array[String]): Unit = {
val session: SparkSession = SparkSession.builder().appName("test1").master("local[*]").getOrCreate()
session.sparkContext.setLogLevel("ERROR")
//作为消费者,从kafka读取数据,获取到的数据有schema,
// 分别是 key|value|topic|partition|offset|timestamp|timestampType|
val frame: DataFrame = session.readStream.format("kafka")
.option("kafka.bootstrap.servers","qianfeng01:9092,qianfeng02:9092,qianfeng03:9092")
// .option("startingOffsets","earliest")
.option("subscribe","pet").load()
//处理一下数据
val frame1: DataFrame = frame.selectExpr("cast(value as String)")
//保存到kafka中
frame1.writeStream
.format("console")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()
}
}