前言
本来想写word转pdf和pdf转word的代码呢,没想到word转pdf就写了很多很多行代码才实现,为了方便大家消化理解,先写了word转pdf方法实现作为一篇文章。
word转pdf实现思路
代码实现主要依赖两个第三方jar包,一个是pdfbox,一个是aspose-words。pdfbox包完全开源免费,aspose-words免费版生成有水印,且生成数量有限制。单纯用pdfbox 实现word转pdf的话,实现非常复杂,且样式和原来样式,保持一致的的比例很低。所以,我先用aspose-words生成了带水印的pdf,再用pdfbox去除aspose-words生成的水印的,最终得到了一个无水印的pdf。
项目远程仓库
aspose-words 这个需要配置单独的仓库地址才能下载,不会配置的可以去官网直接下载jar引入项目代码中。
AsposeJavaAPI Aspose Java API https://repository.aspose.com/repo/
Maven项目pom文件依赖
org.apache.pdfbox pdfbox 3.0.0-RC1 com.github.jai-imageio jai-imageio-jpeg2000 1.3.0 com.aspose aspose-words 21.9 pom
核心代码实现
import com.aspose.words.Document;
import com.aspose.words.SaveFormat;
import org.apache.pdfbox.Loader;
import org.apache.pdfbox.contentstream.operator.Operator;
import org.apache.pdfbox.cos.COSArray;
import org.apache.pdfbox.cos.COSDictionary;
import org.apache.pdfbox.cos.COSName;
import org.apache.pdfbox.cos.COSString;
import org.apache.pdfbox.pdfparser.PDFStreamParser;
import org.apache.pdfbox.pdfwriter.ContentStreamWriter;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.pdmodel.PDResources;
import org.apache.pdfbox.pdmodel.common.PDStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class PDFHelper3 {
public static void main(String[] args) throws IOException {
doc2pdf("C:\\Users\\liuya\\Desktop\\word\\帆软报表帮助文档.docx");
}
//替换pdf文本内容
public static void replaceText(PDPage page, String searchString, String replacement) throws IOException {
PDFStreamParser parser = new PDFStreamParser(page);
List tokens = parser.parse();
for (int j = 0; j < tokens.size(); j++) {
Object next = tokens.get(j);
if (next instanceof Operator) {
Operator op = (Operator) next;
String pstring = "";
int prej = 0;
if (op.getName().equals("Tj")) {
COSString previous = (COSString) tokens.get(j - 1);
String string = previous.getString();
string = string.replaceFirst(searchString, replacement);
previous.setValue(string.getBytes());
} else if (op.getName().equals("TJ")) {
COSArray previous = (COSArray) tokens.get(j - 1);
for (int k = 0; k < previous.size(); k++) {
Object arrElement = previous.getObject(k);
if (arrElement instanceof COSString) {
COSString cosString = (COSString) arrElement;
String string = cosString.getString();
if (j == prej) {
pstring += string;
} else {
prej = j;
pstring = string;
}
}
}
if (searchString.equals(pstring.trim())) {
COSString cosString2 = (COSString) previous.getObject(0);
cosString2.setValue(replacement.getBytes());
int total = previous.size() - 1;
for (int k = total; k > 0; k--) {
previous.remove(k);
}
}
}
}
}
List contents = new ArrayList<>();
Iterator streams = page.getContentStreams();
while (streams.hasNext()) {
PDStream updatedStream = streams.next();
OutputStream out = updatedStream.createOutputStream(COSName.FLATE_DECODE);
ContentStreamWriter tokenWriter = new ContentStreamWriter(out);
tokenWriter.writeTokens(tokens);
contents.add(updatedStream);
out.close();
}
page.setContents(contents);
}
//移除图片水印
public static void removeImage(PDPage page, String cosName) {
PDResources resources = page.getResources();
COSDictionary dict1 = resources.getCOSObject();
resources.getXObjectNames().forEach(e -> {
if (resources.isImageXObject(e)) {
COSDictionary dict2 = dict1.getCOSDictionary(COSName.XOBJECT);
if (e.getName().equals(cosName)) {
dict2.removeItem(e);
}
}
page.setResources(new PDResources(dict1));
});
}
//移除文字水印
public static boolean removeWatermark(File file) {
try {
//通过文件名加载文档
PDDocument document = Loader.loadPDF(file);
PDPageTree pages = document.getPages();
Iterator iter = pages.iterator();
while (iter.hasNext()) {
PDPage page = iter.next();
//去除文字水印
replaceText(page, "Evaluation Only. Created with Aspose.Words. Copyright 2003-2021 Aspose", "");
replaceText(page, "Pty Ltd.", "");
replaceText(page, "Created with an evaluation copy of Aspose.Words. To discover the full", "");
replaceText(page, "versions of our APIs please visit: https://products.aspose.com/words/", "");
replaceText(page, "This document was truncated here because it was created in the Evaluation", "");
//去除图片水印
removeImage(page, "X1");
}
document.removePage(document.getNumberOfPages() - 1);
file.delete();
document.save(file);
document.close();
return true;
} catch (IOException ex) {
ex.printStackTrace();
return false;
}
}
//doc文件转pdf(目前最大支持21页)
public static void doc2pdf(String wordPath) {
long old = System.currentTimeMillis();
try {
//新建一个pdf文档
String pdfPath=wordPath.substring(0,wordPath.lastIndexOf("."))+".pdf";
File file = new File(pdfPath);
FileOutputStream os = new FileOutputStream(file);
//Address是将要被转化的word文档
Document doc = new Document(wordPath);
//全面支持DOC, DOCX, OOXML, RTF HTML, OpenDocument, PDF, EPUB, XPS, SWF 相互转换
doc.save(os, SaveFormat.PDF);
os.close();
//去除水印
removeWatermark(new File(pdfPath));
//转化用时
long now = System.currentTimeMillis();
System.out.println("Word 转 Pdf 共耗时:" + ((now - old) / 1000.0) + "秒");
} catch (Exception e) {
System.out.println("Word 转 Pdf 失败...");
e.printStackTrace();
}
}
}
结果分析
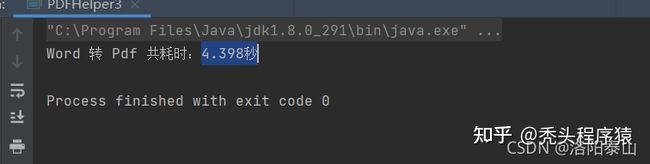
以一个带文字和图片,工21页的doc文件为例,word转pdf花费时长4.398秒

原word样式

转化后pdf效果图


通过对比,word原来的样式和转换pdf文件后的样式基本没有变化。
到此这篇关于Java实现无损Word转PDF的示例代码的文章就介绍到这了,更多相关Java无损Word转PDF内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!