mmsegmentation教程1:自定义数据集、config文件修改、训练教程
简介
mmsegmentation作为OpenLab重要的开源分割训练框架,统一了之前大家各写个的训练网络,导致很多工作无法复现。并且每次大家下载开源项目一打开项目,要面对各种千奇百怪的风格的代码,每次都要花费时间去适应,降低工作效率。
OpenLab的mmsegmentation统一了训练分割框架代码,把重要部分全面模块化,只要按照API,就可以很轻松的添加自己的工作,个人是很喜欢OpenLab的mm系列的。
但是OpenLab的工作给适应了之前千奇百怪代码的朋友们一定的难度,OpenLab的代码风格一打开,如果代码能力不是特别强的话,肯定是懵逼状态的。
其实mm系列需要修改的地方挺少的,以mmsegmentation为例,你要是想成功跑起来,只需要修改以下几个地方:
1、在mmseg/datasets下面对数据集进行初始定义
2、在configs/base/datasets下面对数据加载进行定义
3、在configs/下面选择你需要的模型参数进行修改
4、返回tools/train.py进行训练
其他的mmclassfication和mmdetection的修改方式也是相似的,下面进行具体讲解
文章目录
- 简介
- 下载和基础环境安装
- 在mmseg/datasets下面对数据集进行初始定义
- 在configs/_ _base_ _/datasets下面对数据加载进行定义
- 在configs/下面选择你需要的模型参数进行修改
- 返回tools/train.py进行训练
- 测试的还没看
下载和基础环境安装
下载
https://github.com/open-mmlab/mmsegmentation
打不开的话就用下面这个(我下的是这个)
https://gitee.com/monkeycc/mmsegmentation
我使用实验室的Ubuntu环境,所以只需要下一个mmcv-full
pip install mmcv-full
ps:我下的这个包下面要求mmcv-full在1.3.13到1.5.0之间
在mmseg/datasets下面对数据集进行初始定义
由于自身水平有限,没法根据自己数据集原有的格式去修改框架中数据集读取方式,所以只能按照框架中规定的数据格式去更改自己数据集的格式:
-
按照官方给的文档,先把自己的数据集改成官方存放数据集格式
├── data │ ├── my_dataset │ │ ├── img_dir │ │ │ ├── train │ │ │ │ ├── xxx{img_suffix} │ │ │ │ ├── yyy{img_suffix} │ │ │ │ ├── zzz{img_suffix} │ │ │ ├── val │ │ ├── ann_dir │ │ │ ├── train │ │ │ │ ├── xxx{seg_map_suffix} │ │ │ │ ├── yyy{seg_map_suffix} │ │ │ │ ├── zzz{seg_map_suffix} │ │ │ ├── valimg_dir中全部存在原图
ann_dir中全部存放mask -
dataset class文件配置;
在mmseg/datasets/目录下找到stare.py文件

复制一份stare.py并粘贴在mmseg/datasets/目录下,重命名为my_dataset.py,打开my_dataset.py
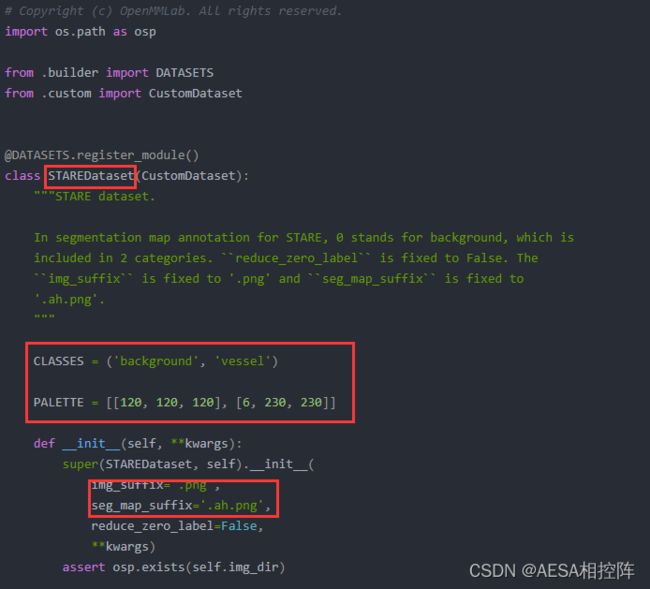
你需要修改标红的三个地方
STAREDataset:表示你定义的数据的名字,顺便取一个名字即可
CLASSES:表示你数据集的背景+类别
PALETTE :表示你数据集各类别的像素值
img_suffix:原图图像后缀
seg_map_suffix:mask图像后缀
比如我的数据集就需要修改为以下内容# Copyright (c) OpenMMLab. All rights reserved. import os.path as osp from .builder import DATASETS from .custom import CustomDataset @DATASETS.register_module() class MyDataset(CustomDataset): """DRIVE dataset. In segmentation map annotation for DRIVE, 0 stands for background, which is included in 2 categories. ``reduce_zero_label`` is fixed to False. The ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to '_manual1.png'. """ CLASSES = ('background', 'egc') PALETTE = [[0, 0, 0], [255, 255, 255]] def __init__(self, **kwargs): super(MyDataset, self).__init__( img_suffix='.jpg', seg_map_suffix='.png', reduce_zero_label=False, **kwargs) assert osp.exists(self.img_dir)PALETTE好像是调色板,我随便更改里面的数值发现对训练没啥影响,翻了一下其他大佬的回答,这个好像是训练完后进行测试后的结果保存,mmseg默认为把分割出来的mask结果直接画在原图上进行显示,PALETTE好像指定了画上原图的mask蒙版的颜色。
PS:mmseg要求mask的像素在[0,num_classes-1]范围内,比如我是2分类,背景像素值为0,那么目标像素值应该为1。如果你也是二分类,mask为单通道(8 bit)二值化的0(背景)/255(目标)图像的话,先去把图像改为0(背景)/1(目标)图像,否则能跑起来,但是指标异常,几乎全是0。(这是个大坑!!!一定要注意)
修改mmseg/datasets/目录下的_init_.py

把图中标红的加到原_init_.py中
在configs/_ base _/datasets下面对数据加载进行定义
在configs/__ base __/datasets/目录下找到stare.py文件,复制一份重命名为my_dataset.py。进行修改
# dataset settings
dataset_type = 'MyDataset' #上一步中你定义的数据集的名字
data_root = '/data/egc224mmsegStyle' #数据集存储路径
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) #数据集的均值和标准差,空引用默认的,也可以网上搜代码计算
crop_size = (224, 224) #数据增强时裁剪的大小
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', reduce_zero_label=True),
dict(type='Resize', img_scale=(224, 224), ratio_range=(0.5, 2.0)), #img_scale图像尺寸
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(224, 224), #img_scale图像尺寸
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=16, #batch_size
workers_per_gpu=1, #nums gpu
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='img_dir/train', #训练图像路径
ann_dir='ann_dir/train', #训练mask路径
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='img_dir/val', #验证图像路径
ann_dir='ann_dir/val', #验证mask路径
pipeline=test_pipeline),
#我的数据集没有测试集,和验证集用同一路径,问题不大
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='img_dir/val', #测试图像路径
ann_dir='ann_dir/val', #测试mask路径
pipeline=test_pipeline)
)
需要修改的地方在上面的代码中用中文标出来了
在configs/下面选择你需要的模型参数进行修改
以DANet为例子吗,找到configs/danet/下的danet_r50-d8_512x512_20k_voc12aug.py

打开并修改这几个位置

_base_ = [
'../_base_/models/danet_r50-d8.py', #这个是网络的骨架,使用单卡记得去骨架模型里将SyncBN改成BN
'../_base_/datasets/my_dataset.py', #换成自己定义的数据集
'../_base_/default_runtime.py',
'../_base_/schedules/schedule_20k.py'
]
model = dict(
decode_head=dict(num_classes=2), auxiliary_head=dict(num_classes=2)) #换成自己的分类类别数
找到configs/base/models/下面的danet_r50-d8.py
# model settings
norm_cfg = dict(type='BN', requires_grad=True) #SyncBN代表分布式训练,单卡训练将其改成BN
model = dict(
type='EncoderDecoder',
pretrained='open-mmlab://resnet50_v1c',
backbone=dict(
type='ResNetV1c',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
dilations=(1, 1, 2, 4),
strides=(1, 2, 1, 1),
norm_cfg=norm_cfg,
norm_eval=False,
style='pytorch',
contract_dilation=True),
decode_head=dict(
type='DAHead',
in_channels=2048,
in_index=3,
channels=512,
pam_channels=64,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='DiceLoss', use_sigmoid=False, loss_weight=1.0)), #type处可以指定loss类型
auxiliary_head=dict(
type='FCNHead',
in_channels=1024,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='DiceLoss', use_sigmoid=False, loss_weight=0.4)), #type处可以指定loss类型
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))
需要修改的地方在代码中已经中文注释
同理,如果你要是用其他的模型,同样需要修改两个地方就行上面提到的模型骨架和数据集即可
返回tools/train.py进行训练
弄完上面那些就可以基本开始训练了,官方的训练教程是
python tools/train.py ${配置文件} --work-dir ${YOUR_WORK_DIR}
${配置文件}:表示你配置文件的位置,也就是上一步的danet_r50-d8_512x512_20k_voc12aug.py所在位置
work-dir:是用来存储模型和日志的地方,你可以自己指定,不指定的话会自己创建
我觉得这样每次打太烦了,就在tools/train.py里面进行指定,随后直接运行train.py就行
在train.py中你需要修改的只有以下几个内容:
1、–config指定网络文件加载配置文件的位置
2、–work-dir是你结果存储路径
3、–gpu-id是你指定哪个GPU进行训练,–gpus与–gpu-id作者在API文档中已经介绍这两弃用了,至于为啥不删,估计是在其他地方还在加载。
# Copyright (c) OpenMMLab. All rights reserved.
def parse_args():
parser = argparse.ArgumentParser(description='Train a segmentor')
parser.add_argument('--config',
default='/home/hdc1996dl/MyProject/mmsegmentation-master/configs/'
'RepLKNet/RepLKNet-31B_1Kpretrain_upernet_80k_egc.py',
help='train config file path')
parser.add_argument('--work-dir',
default='/data/hdc1996dl/segDatasates/save/'
'mmseg/upernet_RepLKNet',
help='the dir to save logs and models')
#已弃用
group_gpus.add_argument(
'--gpus',
type=int,
help='(Deprecated, please use --gpu-id) number of gpus to use '
'(only applicable to non-distributed training)')
# 已弃用
group_gpus.add_argument(
'--gpu-ids',
type=int,
nargs='+',
help='(Deprecated, please use --gpu-id) ids of gpus to use '
'(only applicable to non-distributed training)')
#指定GPU
group_gpus.add_argument(
'--gpu-id',
type=int,
default=0,
help='id of gpu to use '
'(only applicable to non-distributed training)')
运行起来大致是这样的

如果报错
未发现mmseg包
最简单的方式直接把train.py赋值粘贴到根目录下,再run就行
测试的还没看
看完这个,想深入了解mmseg怎么用的,可以移步这里
mmsegmentation教程2:如何修改loss函数、指定训练策略、修改评价指标、指定iterators进行val指标输出
参考:
> https://blog.csdn.net/weixin_44044411/article/details/118196847