yolov4:optimal speed and accuracy of object detection
YOLO V4 — 网络结构和损失函数解析(超级详细!) - 知乎1.前言最近用YOLO V4做车辆检测,配合某一目标追踪算法实现 车辆追踪+轨迹提取等功能,正好就此结合论文和代码来对YOLO V4做个解析。先放上个效果图(半成品),如下:话不多说,现在就开始对YOLO V4进行总结。 YO… https://zhuanlan.zhihu.com/p/150127712CSPNet——PyTorch实现CSPDenseNet和CSPResNeXt - 知乎代码已同步到GitHub:https://github.com/EasonCai-Dev/torch_backbones.git 1 论文关键信息论文链接: CSPNet: A New Backbone that can Enhance Learning Capability of CNN1.1 CSP结构论文提出Cross Stage Parti…https://zhuanlan.zhihu.com/p/263555330深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎因为工作原因,项目中经常遇到目标检测的任务,因此对目标检测算法会经常使用和关注,比如Yolov3、Yolov4、Yolov5、Yolox算法。 当然,实际项目中很多的第一步,也都是先进行 目标检测任务,比如人脸识别、多目标…https://zhuanlan.zhihu.com/p/143747206一张图梳理YOLOv4论文 - 知乎AlexeyAB大神继承了YOLOv3, 在其基础上进行持续开发,将其命名为YOLOv4。并且得到YOLOv3作者Joseph Redmon的承认,下面是Darknet原作者的在readme中更新的声明。 来看看YOLOv4和一些SOTA模型的对比,YOLOv4要比YOL…https://zhuanlan.zhihu.com/p/136115652rcnn中的Hard negative mining方法是如何实现的? - 知乎我的建议是不要关注RCNN的Hard Negative Mining的实现,因为它是用Matlab写的……不过,RCNN 的 Hard Neg…https://www.zhihu.com/question/46292829困难样本(Hard Sample)处理方法 - 知乎困难样本(Hard Sample)处理方法 如果按照学习的难以来区分,我们的训练集可以分为Hard Sample和Easy Sample. 顾名思义,Hard Sample指的就是难学的样本(loss大),Easy Sample就是好学的样本(loss小)。 举个…https://zhuanlan.zhihu.com/p/103477343GitHub - bubbliiiing/yolov4-pytorch: 这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。. Contribute to bubbliiiing/yolov4-pytorch development by creating an account on GitHub.
https://zhuanlan.zhihu.com/p/150127712CSPNet——PyTorch实现CSPDenseNet和CSPResNeXt - 知乎代码已同步到GitHub:https://github.com/EasonCai-Dev/torch_backbones.git 1 论文关键信息论文链接: CSPNet: A New Backbone that can Enhance Learning Capability of CNN1.1 CSP结构论文提出Cross Stage Parti…https://zhuanlan.zhihu.com/p/263555330深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎因为工作原因,项目中经常遇到目标检测的任务,因此对目标检测算法会经常使用和关注,比如Yolov3、Yolov4、Yolov5、Yolox算法。 当然,实际项目中很多的第一步,也都是先进行 目标检测任务,比如人脸识别、多目标…https://zhuanlan.zhihu.com/p/143747206一张图梳理YOLOv4论文 - 知乎AlexeyAB大神继承了YOLOv3, 在其基础上进行持续开发,将其命名为YOLOv4。并且得到YOLOv3作者Joseph Redmon的承认,下面是Darknet原作者的在readme中更新的声明。 来看看YOLOv4和一些SOTA模型的对比,YOLOv4要比YOL…https://zhuanlan.zhihu.com/p/136115652rcnn中的Hard negative mining方法是如何实现的? - 知乎我的建议是不要关注RCNN的Hard Negative Mining的实现,因为它是用Matlab写的……不过,RCNN 的 Hard Neg…https://www.zhihu.com/question/46292829困难样本(Hard Sample)处理方法 - 知乎困难样本(Hard Sample)处理方法 如果按照学习的难以来区分,我们的训练集可以分为Hard Sample和Easy Sample. 顾名思义,Hard Sample指的就是难学的样本(loss大),Easy Sample就是好学的样本(loss小)。 举个…https://zhuanlan.zhihu.com/p/103477343GitHub - bubbliiiing/yolov4-pytorch: 这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。. Contribute to bubbliiiing/yolov4-pytorch development by creating an account on GitHub. https://github.com/bubbliiiing/yolov4-pytorchGitHub - Tianxiaomo/pytorch-YOLOv4: PyTorch ,ONNX and TensorRT implementation of YOLOv4PyTorch ,ONNX and TensorRT implementation of YOLOv4 - GitHub - Tianxiaomo/pytorch-YOLOv4: PyTorch ,ONNX and TensorRT implementation of YOLOv4https://github.com/Tianxiaomo/pytorch-YOLOv4https://github.com/WongKinYiu/ScaledYOLOv4
https://github.com/bubbliiiing/yolov4-pytorchGitHub - Tianxiaomo/pytorch-YOLOv4: PyTorch ,ONNX and TensorRT implementation of YOLOv4PyTorch ,ONNX and TensorRT implementation of YOLOv4 - GitHub - Tianxiaomo/pytorch-YOLOv4: PyTorch ,ONNX and TensorRT implementation of YOLOv4https://github.com/Tianxiaomo/pytorch-YOLOv4https://github.com/WongKinYiu/ScaledYOLOv4 https://github.com/WongKinYiu/ScaledYOLOv4论文阅读笔记(YOLOv4之trick总结)(2) - 知乎上文记录了YOLOv4一文中所提到的不增加计算损耗的trick(Bag of freebies),本文用于记录仅增加微小的计算损耗的trick(Bag of specials)。 不增加计算损耗的trick(Bag of freebies):像素级数据增强(亮度、对…https://zhuanlan.zhihu.com/p/137387839目标检测入门之再读YOLOv4(二) - 知乎1 引言在上一节中我们重点介绍了YOLOv4的网络结构和相关图示说明,本节我们来介绍YOLOv4相关的优化技巧策略. YOLOv4的论文链接: 戳我闲话少述,我们直接开始 2 BOF and BOSBag-of-Freebies是指在网络训练时所用到的…https://zhuanlan.zhihu.com/p/439371735
https://github.com/WongKinYiu/ScaledYOLOv4论文阅读笔记(YOLOv4之trick总结)(2) - 知乎上文记录了YOLOv4一文中所提到的不增加计算损耗的trick(Bag of freebies),本文用于记录仅增加微小的计算损耗的trick(Bag of specials)。 不增加计算损耗的trick(Bag of freebies):像素级数据增强(亮度、对…https://zhuanlan.zhihu.com/p/137387839目标检测入门之再读YOLOv4(二) - 知乎1 引言在上一节中我们重点介绍了YOLOv4的网络结构和相关图示说明,本节我们来介绍YOLOv4相关的优化技巧策略. YOLOv4的论文链接: 戳我闲话少述,我们直接开始 2 BOF and BOSBag-of-Freebies是指在网络训练时所用到的…https://zhuanlan.zhihu.com/p/439371735
如何评价新出的YOLO v4 ? - 知乎YOLO原作者之前宣布退出CV界,近日arxiv上有了一篇名为Yolo v4的文章,看起来是集大成者,用了不少tricks…https://www.zhihu.com/question/390191723?rf=390194081
看yolov4就像是看技术报告一样,其实v4里面基本已经没有我在整个目标检测系列中最想强调的正负样本定义分配的问题了,只有一点,对最大gt的anchor不止一个了,作者让anchor大于一个iou阈值,也就是yolov3作者尝试过的不work的faster rcnn两个iou阈值的方案,xywh换成iou loss了。v4能够帮助我们更好的梳理目标检测的一些trick,全是面试高频题,但是我看了两个主流的pytorch版本的v4实现,其实原作者的很多trick都是没有实现的,但是在coco上map却比v4高,scaled-yolov4在yolov4的基础上做了简单修改,并且用pytorch实现,map高了原版很多,只能说作者在darknet基础上开发的yolov4其实在精度上差了pytorch版本很多。
1.related work
1.1 object detection models
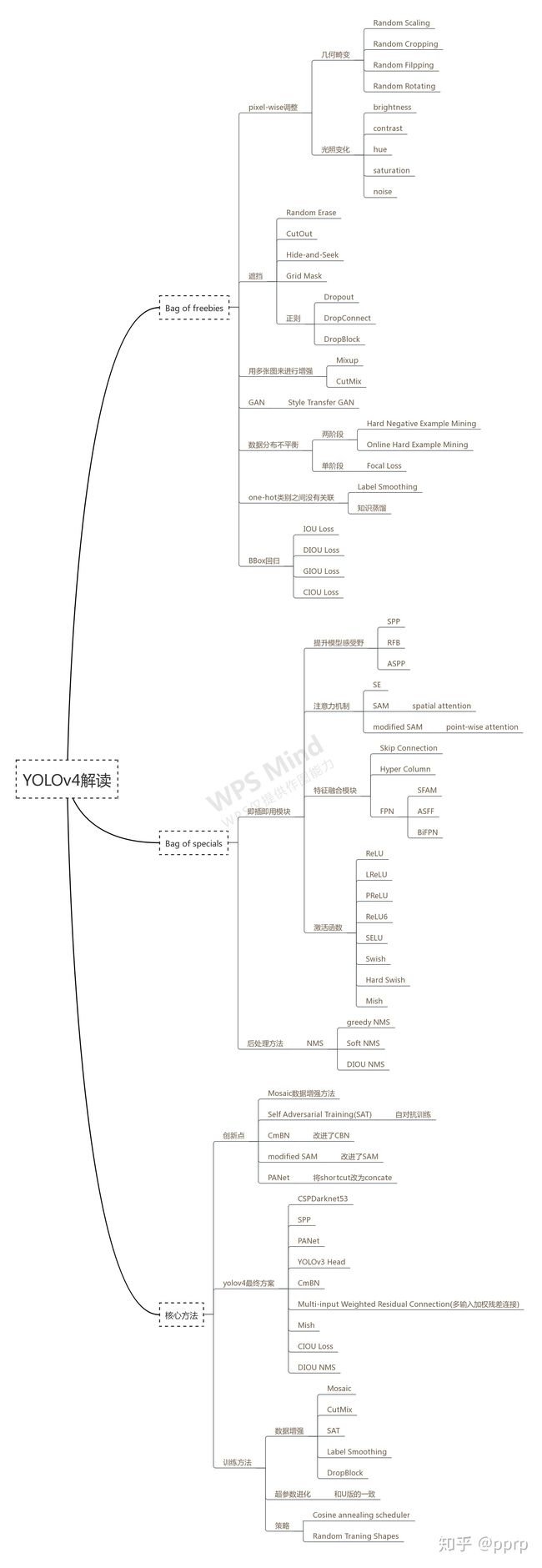
目标检测基本是backbone,neck,head的三级结构

这一块看mmdet也可以的,里面按照backbone,neck,head的很多算法模块,目前mmdet里面应该还没有yolov4,yolov5的实现。
1.2 bag of freebies
这一章还是有价值的,传统的目标检测器都是离线训练的,因此可以用更好的训练方法使目标检测器在不增加推理成本的情况下获得更好的精度,这种只改变训练策略或只增加培训成本的方法叫做bof。
1.2.1 data augmentation
数据增强的目的是增加输入数据的可变性,从而使所设计的目标检测模型在面对不同环境的图像时有更高的鲁棒性,这里我在看mixup论文时,作者也提到数据增强是对数据空间进行插值,从而降低模型复杂度,数据增强包括四大类:
1.pixel-wise adjustment,逐像素调整,保留调整区域中所有原始的像素信息,例如photometric distortions(光度畸变)和geometric distortions(几何畸变),photometric distortions包括brightness,contrast,hue,saturation和noise of an image,geometric distortions包括random scaling,cropping,flipping和rotating.
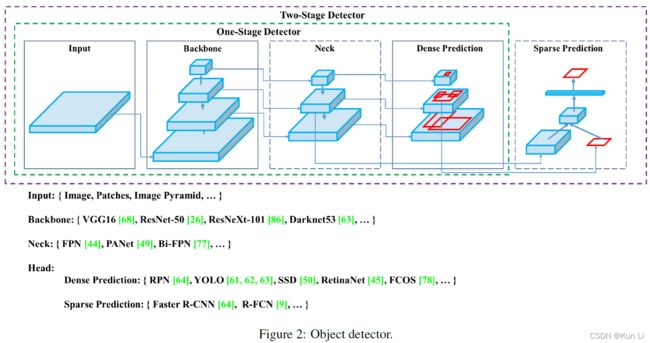
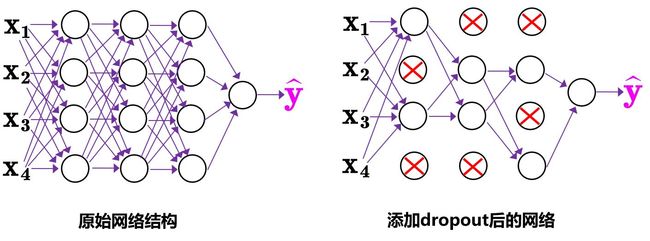
2.simulating object occlusion issues,对象遮挡,例如random erase,cutout,hide-and-seek,grid mask,如果将类似的操作用在feature map上,还有dropout,dropconnet和dropblock.

3.多图增强,例如mixup,cutmix.
4.gan,style transfer gan.
1.2.2 data imbalance between different classes
主要是解决语义分布偏差问题,包括hard negative example mining 或者 online hard example mining,二阶段检测器中的方法,难例挖掘,hard negative example是对难例中负样本进行挖掘,训练的时候,可以根据loss把一些难例拿出来放到决策期中反复的训。focal loss是一阶段中最常用的方法。
1.2.3 one-hot hard representation
one-hot很难表示不同类别之间的关联度关系,这个我在label confusion learning中有很详细的解释,one-hot编码其实有诸多的缺点,学不到标签之间的关系,可以用label smoothing或者knowledge distillation.
1.2.4 bbox regression
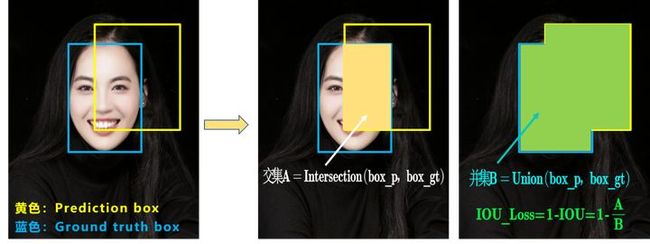
传统目标检测直接使用mse对bbox的中心点坐标和宽高直接回归,例如yolov1和centernet,fcos,anchor-based的方法是回归offset,retinanet,faster rcnn,yolov2/3,然后直接把bbox的每个点当成独立变量,不考虑对象本身的完整性,因此对xywh的回归可以用iou loss。Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020),这里上面的材料里面有非常详细的描述,iou loss不想交不可导且无法刻画预测框和gt之间的位置关系,giou引入了最小外界矩形,但是处理不了位置和预测框在gt内的情况,引入了diou,用两框中心点和最小外界矩形的对象线,但是解决不了形状不一样,但diou一样,因此引入了ciou,增加了一个形状因子。


1.3 bag of specials
对于那些只增加少量推理成本,却能显著提高目标检测精度的插件模块和后处理方法称之为bos。
1.3.1 enhance receptive field
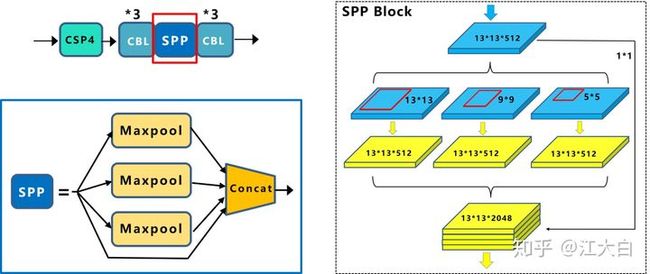
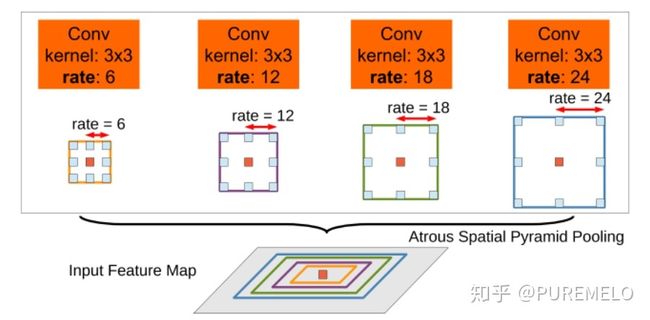
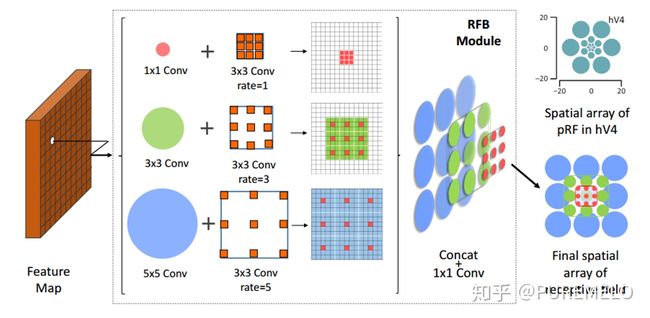
增加感受野,其实yolo中的spp更多是不同感受野的融合,因为其只在13x13的一层特征图上做了。增加感受野的模块包括spp,aspp,rfb。用spp,yolov3-608在coco上多花0.5%的计算成本ap50能涨2.7%,rfb,在ssd上,花7%的推理时间ap50能涨5.7%。
1.3.2 channel-wise attention and point-wise attention
典型的是se和sam(cbam),se在imagent分类上给resnet提高一个点top1,增加2%的计算量,在gpu上增加10%的推理时间,sam+resnet-se,增加0.1%计算涨点0.5%,gpu推理不增加时间。
1.3.3 feature integration
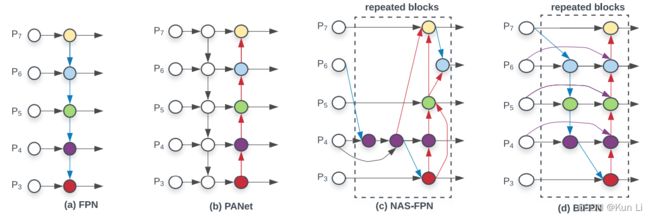
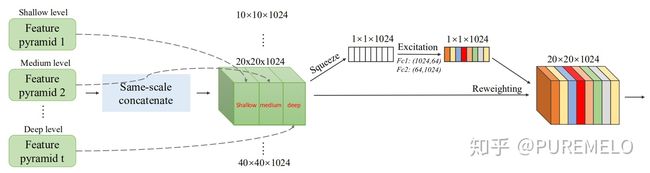
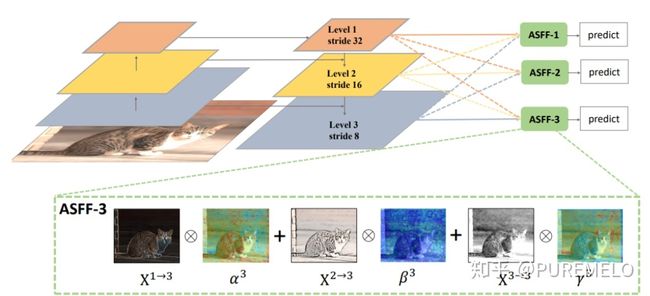
将低级特征集成到高级语义特征,fpn,sfam,asff,bifpn。bifpn中那条紫线就是本文中的multi-input weighted residual connections(miwrc),这条线带着权重的。
1.3.4 activation function
relu,lrelu,prelu,relu6,selu,swish,hard-swish,mish
1.3.5 nms
greedy nms,softmax nms,diou nms
2.methodology
2.1 selection of architecture
在imagenet上分类而言,cspresnext50比cspdarknet53要好,但是在coco检测上,cspdarknet53要比cspresnext50要好,对于分类来说最优的模型对于检测器来说不一定是最优的,retinking imagent pretrained里面也有分析。相比分类,检测需要考虑一下:
higher input network size(resolution):检测更小的目标;more layers:更大的感受野,覆盖更大的输入网络;more parameters:在单个图像中检测多个不同大小对象的能力。

最终选择了cspdarknet53 backbone,spp,panet path-aggregation neck ,yolov3(anchor-based head) as the architecture of yolov4.用spp增加感受野。模型结构这块没问题,几乎yolov4的多个pytorch版本都实现了cspdarknet53,spp,pan,yolohead这几块。
2.2 selection of bof and bos

一般cnn可选方法如上所示,激活函数上,prelu和selu很难训练,relu6专门为量化网络设计,选择了dropblock,本文还有一个很好的点,作者只用了一个gpu,因此bs不会太大,没用sn和gn。

2.3 additional improvements
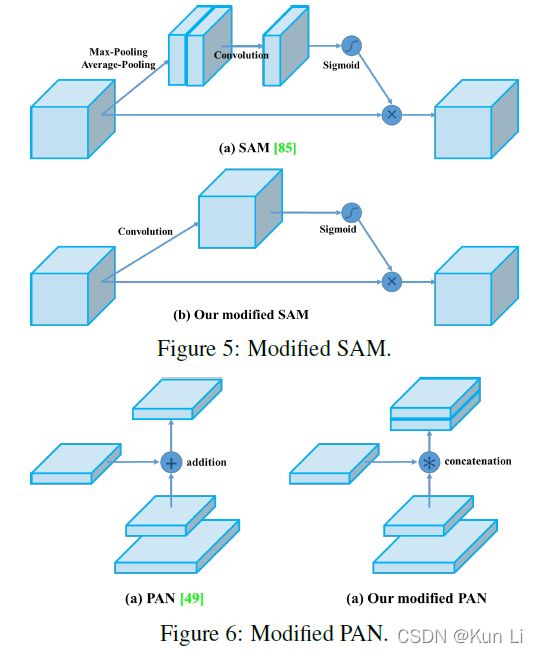
为了让模型在一个gpu上训练起来,作者也做了一些改进。训练方式用了mosaic和sat,使用遗传算法选择最优超参,modifed sam,modifed pan和cmbn。

mosaic混合了四张图,cutmix只混合了2张图,这个方法应该很有效,sam,sat和cmbn几乎没人实现,大多数用的还是bn,pan将融合从add改成concat,通道增加一倍。
2.4 yolov4

上面是yolov4的全貌,我们稍微分析一下,主要以几个主流的pytorch实现的yolov4做对比,backbone中的bof中选了cutmix,mosaic,dropblock和ls,这里面mosaic几乎都有实现,ls也有,但是cutmix和dropblock几乎都没用,bos中miwrc都是直接用的pan,检测器的bof,ciou-loss,mosaic,cosine annealing scheduler都有,eliminate grid sensitivity,multiple anchors for a single gt,random training shape这三个只有scaled-yolov4实现了,检测器的bos中,sam几乎都没有,diou-nms有的用的greedy-nms。
3.experiment
3.1 experiment setup
初始lr是0.01,mini-bs是4或8.
3.2 influence of different features on classifier training



其实yolov4的作者的这些trick,很多复现都没有全用,但是map比原版的还高,说明yolov4的原版实现darknet框架可能或多或少还是有些小问题,这里的一些测评有的也没有了太大意义,其实这也是通病,在一个数据集上测试的各个trick,其实有的数据关系还挺大的,就那么一两个点的差距,我自己做分类经常测也能遇到这个问题。在有的复现我看用了mixup也是涨点的。
3.3 influence of differnet features on dtector training
这里其实是我认为很重要的,甚至要比前面的一些结构要重要很多。
1 S:原始在回归tx,ty时用了sigmoid,sigmoid对于要接近cx,cx+1的值需要回归一个很大的tx,因此在sigmoid上乘以一个超过1.0的因子,从而解决网格对无法检测到对象的影响。这个只有scaled-yolov4实现了。
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]2 Mosaic,4张图一拼。
3.Iou threshold,用多个anchor去预测一个gt,通过anchor的gt的iou大于一个阈值,这个还是挺重要的,意思是希望增加正样本,yolov1/2/3中都是一个anchor负责一个gt,v4希望多整几个anchor,但是在yolov3中作者也做了这个实验,向faster rcnn一样设置两个iou阈值,超过第一个为正样本,低于第二个为负样本,但是没work,这一条在pytorch版本的复现几乎没人这么做,都还是用原版的yolov3,最大的iou来负责,scaled-yolov4这里和之前的写法都是不一样的,scaled-yolov4和yolov5是一致的,都是采用宽高比代替iou做筛选,也不再是一个anchor负责一个gt,而是三个特征图上可能存在多个anchor负责gt,同时也不再是一个网格单元,而是三个网格单元负责预测,至于yolov5和scaled-yolov4这个谁借鉴谁的,我也不知道。
yolov3:
pred_ious = bboxes_iou(pred[b].view(-1, 4), truth_box, xyxy=False)
pred_best_iou, _ = pred_ious.max(dim=1)
scaled-yolov4:
j = torch.max(r, 1. / r).max(2)[0] < model.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n) = wh_iou(anchors(3,2), gwh(n,2))
a, t = at[j], t.repeat(na, 1, 1)[j] # filter4.GA 前10%训练阶段,用已传算法选择最佳参数,这个几乎也没人实现。
5.label smoothing,scaled-yolov4和一些复现用了。
6.cmbn,几乎每人用,bn和sn都有。
7.CA,余弦退火都用了,
8.dm,dynamic mini-batch size,没见过用
9.OA,optimized anchor,优化了anchor。
10.几乎都用了ciou loss,用iou loss效果肯定会好,直接有很多把mse loss换成iou loss的都涨点了。
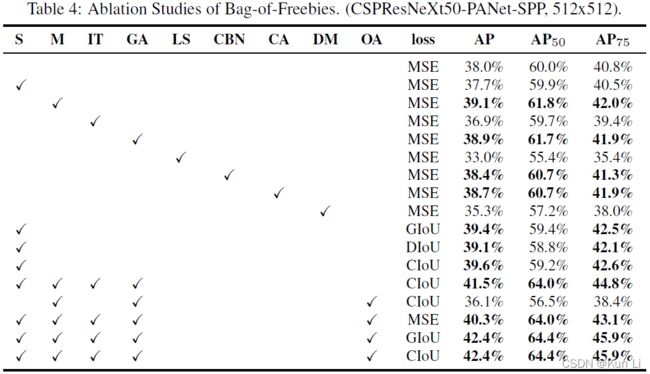
3.4 influence of different mini-batch size on detector training
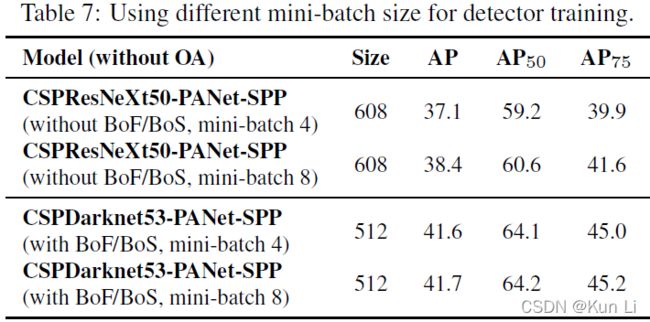
用了这些措施之后,小bs好像也不怎么影响效果了。
最后我们来看下yolov4的结构和效果。
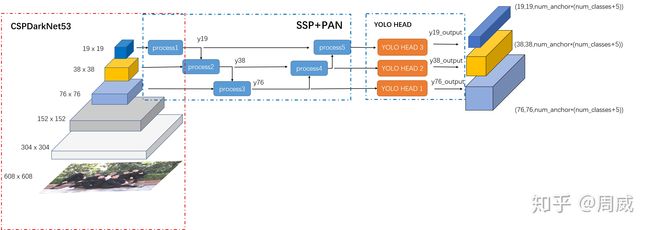
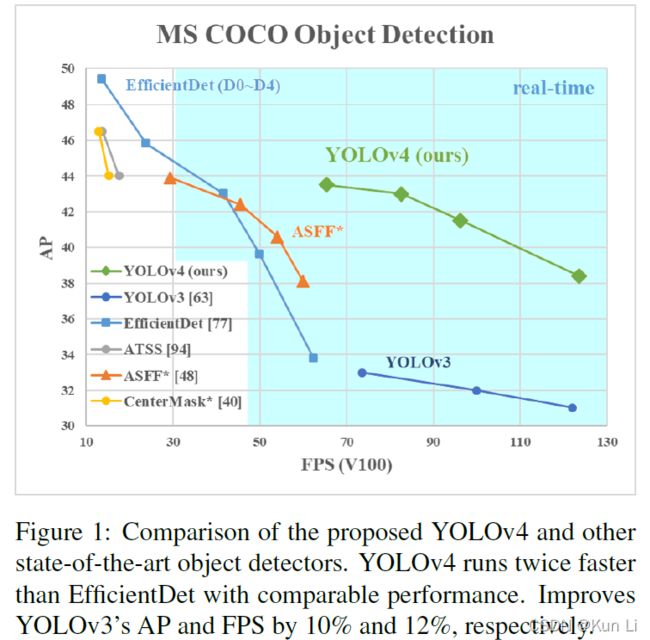
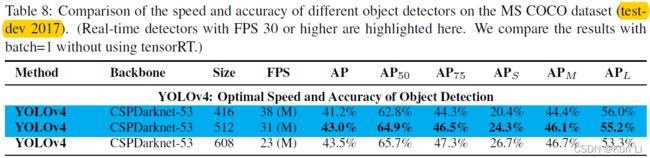
整体来看,yolov4在核心点上的改动很少,结构上用了csp,spp,pan,数据增强上主要是mosaic,cumix/mixup,损失上用了ciou loss,nms用了diou-nms,scaled-yolov4用的更全一点,anchor匹配也做了更改,直接map都上50+了,果然有生命力。