Self Attention 详解
Self Attention 详解
前言
注意力机制(Attention),之前也是一直有所听闻的,也能够大概理解 Attention 的本质就是加权,对于 Google 的论文《Attention is all you need》也只是一直听闻,现在乘着机会也是好好读一读。
什么是注意力机制?
Attention 机制最初是模仿人类注意力而提出的一种方法,原理也非常简单。
举个例子,当我们在观察一张图片时,我们往往会首先注意到「主体」,而后才会注意到「背景」,也就是说人类往往能够快速的从大量信息中快速提取出「主体」,也就是包含高价值的信息;
但另外一方面,我们都知道,一般来说,对于计算机来说,每个像素,每个信息都同样重要,它也不会去加以区分。
因此,Attention 机制正是希望将有限的注意力集中在重点信息上,快速得到最有效的信息。
Encoder-Decoder
Attention 经常会与 Encoder-Decoder 一起说,但事实上 Attention 并不一定要在 Encoder-Decoder 框架下才能使用的,本质上来说,「带权求和」就可以简单的解释 Attention 机制,也因此它可以放到任何你需要的地方。
这里我们不关注 Encoder-Decoder 的细节,还是回到 Attention 中。
Attention 原理
正如我们上面提到的,Attention 机制正是希望将有限的注意力集中在重点信息上,快速得到最有效的信息,那么一个最简单最有效的思路就是「加权」。对于每一个输入,我们都希望能够得到一个权重,权重越大,输入越重要。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
上面就是我们经常见到的 Attention 公式。最开始接触 self attention 的时候,最不理解的就是 Q , K , V Q, K, V Q,K,V 到底是什么东西,为什么又要按照上面的式子去这样计算。
下面我们对其每一个部分进行分析。
相似度矩阵
第一个问题: Q K T QK^T QKT代表什么?
我们抛开 Q , K , V Q, K, V Q,K,V, 简单把它们理解成 X X X, 现在只关注 X X T XX^T XXT。
X X T XX^T XXT简单来说也就是一个矩阵 X X X乘以自身的转置
我们知道,两个向量点乘的几何意义是一个向量在另一个向量上的投影,也就是 a ⃗ \vec a a 投影在 b ⃗ \vec b b 上的长度与 b ⃗ \vec b b 长度的乘积。
更进一步地,值越大,可以认为两个向量的相关度越高。
那么我们将其延伸到矩阵上来,将矩阵以行向量,列向量的角度理解,其几何意义也就是:将右边矩阵中的每一列向量变换到左边矩阵中每一行向量为基所表示的空间中去

因此,我们可以这样理解,通过 Q K T QK^T QKT点积计算得到了相似度矩阵。
缩放
第二个问题: 为什么要除以 d k d_k dk?
论文给出的解释是:假设 Q Q Q 和 K K K 都是独立的随机变量,满足均值为 0,方差为 1,则点乘后结果均值为 0,方差为 d k d_k dk。也即方差会随维度 d k d_k dk 的增大而增大,而大的方差导致极小的梯度。所以为了防止梯度消失,论文中用内积除以维度的开方,使之变为均值为 0,方差为 1。
简而言之,就是为了使内积不过大,是一些细节上的问题。
归一化
s o f t m a x ( z i ) = e z i ∑ j = 1 j = n e z j softmax(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{j=n}e^{z_j}} softmax(zi)=∑j=1j=nezjezi

对于 softmax 相信也不需要太多的解释,也就是进行归一化。
加权求和
通过上面的计算,我们得到了 s o f t m a x ( Q K T d k ) softmax(\frac{QK^T}{\sqrt{d_k}}) softmax(dkQKT),这也就是我们期望得到的「权重」

而后,我们便可以通过加权计算得到带权的表示。
Query, Key, Value
最后,我们回到原始式子上来
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
我们知晓了上式所表示的含义,那么又如何得到 Q , K , V Q, K, V Q,K,V 呢?

Q = X W Q K = X W K V = X W V Q = XW_Q \\ K = XW_K \\ V = XW_V Q=XWQK=XWKV=XWV
简单来说, Q , K , V Q, K, V Q,K,V都是 X X X 的线性变化,这样做的目的也很明显,就是为了提升模型的效果,而不是直接使用输入 X X X。
至此,我们已经对 Attention 公式的每一个部分进行了分析,我相信你对这个公式也有了初步的了解。
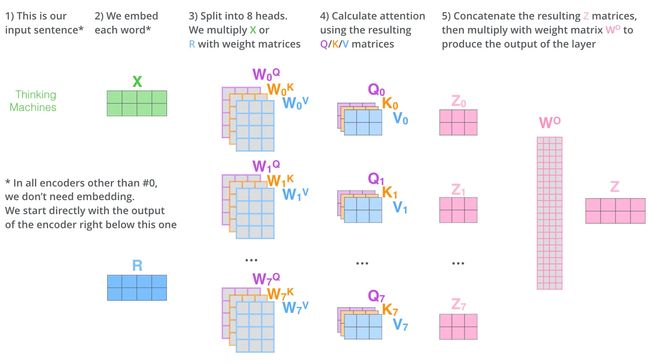
Multi-Head Attention
在论文《Attention is all you need》中,通过添加「多头」注意力的机制进一步完善了自注意力机制
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , . . . , h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) \begin{aligned} MultiHead(Q, K, V) &= Concat(head_1, head_2, ..., head_h)W^O \\ where \quad head_i &= Attention(QW_i^Q, KW_i^K, VW_i^V) \end{aligned} MultiHead(Q,K,V)whereheadi=Concat(head1,head2,...,headh)WO=Attention(QWiQ,KWiK,VWiV)
如果将前面得到的 Q , K , V Q, K, V Q,K,V整体看做一个「头」,那么「多头」需要我们为每个头维护单独的 Q , K , V Q, K, V Q,K,V 权重矩阵,从而产生不同的 Q , K , V Q, K, V Q,K,V 矩阵。正如我们之前所做的那样,我们将 X X X 乘以 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 矩阵以产生 Q , K , V Q, K, V Q,K,V 矩阵。
只是使用不同的权重矩阵进行 h h h 次不同的计算,我们最终会得到 h h h 个不同的矩阵
然后,连接这 h h h 个矩阵,然后将它们乘以一个额外的权重矩阵 W O W^O WO,然后就得到了我们需要的带权矩阵。
Attention 实现
待施工…
参考资料
- The Illustrated Transformer
- Attention is all you need
- 超详细图解 Self-Attention