2021亚太杯C题(塞罕坝)赛后总结
赛后总结
- 比赛总结
-
- 一、比赛思路
- 二、评价类模型
-
- 1.熵权法
- 2.AHP层次分析法
- 三、相关性分析
- 四、聚类模型
-
- 1.欧氏距离—对城市按照某些指标进行聚类
- 2.最短距离法(最邻近法)
- 五、四分位模型
比赛总结
本人11月下旬参加了亚太杯数学建模比赛,虽然题目很困难,但还是尽自己的能力把它做完了,最主要的是学到了不少知识。总结一下这次比赛用到的算法。
一、比赛思路
问题一:建立综合评价模型,建立三级指标,确定各级指标评价值和权值,对塞罕坝地区恢复后对环境的影响做出了定量评价,并给出塞罕坝地区环境条件随时间变化的对比图。
针对问题二:首先根据北京统计年鉴以及其他社会研究报告,得到了北京市逐年气候条件数据和塞罕坝森林数据,根据研究报告选择塞罕坝地区二等森林指标和北京市合适的气候条件指标,使用相关性分析模型,对于选择的5个指标进行了6次相关性分析,定量评价了塞罕坝在北京抵御沙尘暴中的作用。
针对问题三:首先根据中国统计年鉴、北京统计年鉴和其他各省统计年鉴,得到全国各个省份的数据,并通过数据精确计算了各个省份逐年的碳排放量和碳吸收量,使用聚类模型对各个年份的省份进行分类。将各个省份经纬度转换为坐标,使用最短距离模型对各个省份的坐标进行二次聚类,单独一个省份为一类的单独建立自然保护区,多个省份在一类里的建立一个大的生态圈。
二、评价类模型
1.熵权法

%{选择下面一行,F9运行。新建空矩阵R,将19年*6个变量(x1到x6)的数据粘贴入矩阵R
R=[
]
%}clear
%1
[rows,cols]=size(R); % 输入矩阵的大小,rows为对象个数,cols为指标个数
k=1/log(rows); % 求k
Rmin = min(R);
Rmax = max(R);
A = max(R) - min(R);
y = R - repmat(Rmin,19,1);
for j = 1 : size(y,2)
y(:,j) = y(:,j)/A(j)
end
%2 求Y(i,j)
S = sum(y,1)
Y = zeros(rows,cols);
for i = 1 : size(Y,2)
Y(:,i) = y(:,i)/S(i)
end
%3
lnYij=zeros(rows,cols); % 初始化lnYij
% 计算lnYij
for i=1:rows
for j=1:cols
if Y(i,j)==0
lnYij(i,j)=0;
else
lnYij(i,j)=log(Y(i,j));
end
end
end
ej=-k*(sum(Y.*lnYij,1)); % 计算熵值Hj
%4
weights=(1-ej)/(cols-sum(ej));
%5
F = zeros(rows,cols);
for k = 1 : size(R,2)
F(:,k) = weights(k)*y(:,k)
end
format long
F = sum(F,2) %F即为对6个变量进行熵权法客观赋权后,计算获得的51年来的综合评分
得到19年的综合评价和6个指标的权值如下图所示

2.AHP层次分析法

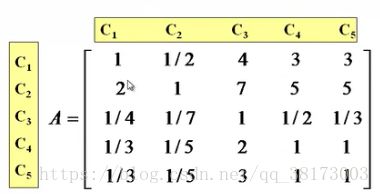

disp('请输入判断矩阵A')
A=input('A=');
[n,n] = size(A);
% % % % % % % % % % % % %方法1: 算术平均法求权重% % % % % % % % % % % % %
Sum_A = sum(A);
SUM_A = repmat(Sum_A,n,1);
Stand_A = A ./ SUM_A;
disp('算术平均法求权重的结果为:');
disp(sum(Stand_A,2)./n)
% % % % % % % % % % % % %方法2: 几何平均法求权重% % % % % % % % % % % % %
Prduct_A = prod(A,2);
Prduct_n_A = Prduct_A .^ (1/n)
disp('几何平均法求权重的结果为:');
disp(Prduct_n_A ./ sum(Prduct_n_A))
% % % % % % % % % % % % %方法3: 特征值法求权重% % % % % % % % % % % % %
[V,D] = eig(A);
Max_eig = max(max(D));
[r,c]=find(D == Max_eig , 1);
disp('特征值法求权重的结果为:');
disp( V(:,c) ./ sum(V(:,c)) )
% % % % % % % % % % % % %下面是计算一致性比例CR的环节% % % % % % % % % % % % %
CI = (Max_eig - n) / (n-1);
RI=[0 0.0001 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
% 这里n=2时,一定是一致矩阵,所以CI = 0,我们为了避免分母为0,将这里的第二个元素改为了很接近0的正数
CR=CI/RI(n);
disp('一致性指标CI=');disp(CI);
disp('一致性比例CR=');disp(CR);
if CR<0.10
disp('因为CR<0.10,所以该判断矩阵A的一致性可以接受!');
else
disp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!');
end
得到结果如下图
三、相关性分析
对查到的相关指标用spss进行相关性分析


相关性系数对应的相关性表
| 相关系数 | 相关性 |
|---|---|
| 0-0.09 | 没有相关性 |
| 0.1-0.3 | 弱相关 |
| 0.3-0.5 | 中等相关 |
| 0.5-1.0 | 强相关 |
四、聚类模型
1.欧氏距离—对城市按照某些指标进行聚类
clc,clear
gj=[
]
gj=zscore(gj); %数据标准化
y=pdist(gj); %求对象间的欧氏距离,每行是一个对象
z=linkage(y,'average'); %按类平均法聚类
dendrogram(z); %画聚类图
for k=3:5
fprintf('划分成%d类的结果如下:\n',k)
T=cluster(z,'maxclust',k); %把样本点划分成k类
for i=1:k
tm=find(T==i); %求第i类的对象
tm=reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类的有%s\n',i,int2str(tm)); %显示分类结果
end
if k==5
break
end
fprintf('**********************************\n');
end
收集到的数据为每隔两年各个省份的碳转化率,对收集到数据的年份进行城市间的聚类,可以直观地看出哪些城市需要保护,哪些城市环境质量较好(碳吸收量大于碳排放量),可以得到聚类图,如下图所示。

2.最短距离法(最邻近法)

对城市的地理位置进行聚类,首先利用在线工具把需要建立生态保护区的城市的经纬度转化成坐标x,y的形式,然后对城市坐标进行聚类,在一个类里的城市可以共享一个生态保护区,即建立一个大的生态圈,生态圈的城市数目越多,则生态圈的级别越高。
clc,clear
a=[116.24 39.54
117.12 39.5
114.30 38.2
112.33 37.52
123.27 41.40
121.28 31.13
118.47 32.3
117.13 31.49
117.7 36.39
106.13 38.29]
;
%73.4,31.25;71.41,29.2;74.21,31.33
[m,n]=size(a);
d=zeros(m);
for i=1:m
for j=i+1:m
d(i,j)=mandist(a(i,:),a(j,:)');
%求第一个矩阵的行向量与第二个矩阵的列向量之间对应的绝对值距离
end
end
d
nd=nonzeros(d); %去掉d中的零元素,非零元素按列排列
nd=union(nd,nd) %去掉重复的非零元素
for i=1:m-1
nd_min=min(nd);
[row,col]=find(d==nd_min);tm=union(row,col); %row和col归为一类
tm=reshape(tm,1,length(tm)); %把数组tm变成行向量
fprintf('第%d次合成,平台高度为%d时的分类结果为:%s\n',...
i,nd_min,int2str(tm));
nd(find(nd==nd_min))=[]; %删除已经归类的元素
if length(nd)==0
break
end
end
得到聚类结果

得到结果后画聚类图,原图找不到了,这里举个例子

五、四分位模型
根据自己情况可以将大于上四分位数的城市视为应该建立生态保护区的城市或中位数平均值等。
x=[301
262
214
196
196
151
138
107
96
85
]
ss50=prctile(x,50)
disp(['中位数:',num2str(ss50)])
ss25=prctile(x,25)
disp(['下四分位数:',num2str(ss25)])
ss75=prctile(x,75)
disp(['上四分位数:',num2str(ss75)])
RS=ss75-ss25
disp(['四分位极差:',num2str(RS)])
得到结果如下图
