Semi-Supervised Image Dehazing(半监督图像去雾)2020
概要:
本文提出了一种有效的半监督学习算法,用于单幅图像去雾。所提出的算法应用了一个包含监督学习分支和无监督学习分支的深度卷积神经网络 (CNN)。在监督分支中,深度神经网络受到监督损失函数的约束,这些损失函数是均方损失、感知损失和对抗损失。
在无监督分支中,本文通过暗通道的稀疏性和梯度先验利用干净图像的特性来约束网络。我们以端到端的方式在合成数据和真实世界图像上训练提议的网络。我们的分析表明,所提出的半监督学习算法不仅限于合成训练数据集,还可以很好地推广到真实世界的图像。
具体过程:
具体来说,设计了一个由监督分支和无监督分支组成的深度网络,两者在训练过程中共享权重。监督分支在合成模糊图像上进行训练,而无监督分支在真实模糊图像上进行训练。在监督分支中,我们应用标记损失(例如均方损失、感知损失和对抗性损失)来训练具有估计结果和地面实况之间差异的网络。为了避免监督分支过度拟合训练数据集,本文通过暗通道 (DC) 和图像梯度(例如总变化 (TV))利用清晰图像的属性来约束无监督分支。整个网络以端到端的方式在合成数据和真实世界图像上进行训练。使用半监督学习方法,我们的网络在最先进的去雾方法中表现出色。
主要贡献:
- 我们提出了一种半监督算法来学习合成图像和真实世界模糊图像之间的关系。所提出的网络由一个监督分支和一个无监督分支组成
- 我们利用传统的图像先验作为未标记的损失,用真实的训练数据训练无监督分支。
- 我们进行了广泛的实验,并证明所提出的半监督去雾方法在合成数据集和真实模糊图像上都优于最先进的去雾方法。
网络结构
我们建议使用传统的暗通道和总变化损失函数来训练无监督分支。
在这项工作中,我们使用半监督学习方法解决了这个问题。具体来说,我们使用标记数据集![]() 和未标记数据集
和未标记数据集![]() 训练深度 CNN 进行图像去雾,其中
训练深度 CNN 进行图像去雾,其中![]() 和
和![]() 表示标记和未标记训练图像的数量,分别。此外,
表示标记和未标记训练图像的数量,分别。此外,![]() 和
和![]() 表示第 i 个模糊图像和对应的真实干净图像。我们训练一个网络从模糊输入 I 中学习无雾图像 J:
表示第 i 个模糊图像和对应的真实干净图像。我们训练一个网络从模糊输入 I 中学习无雾图像 J:
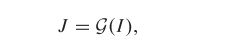
其中 ![]() 表示由监督分支
表示由监督分支![]() 和无监督分支
和无监督分支 ![]() 组成的提议网络。两个分支在训练期间共享相同的权重。
组成的提议网络。两个分支在训练期间共享相同的权重。
编码器包含三个尺度,每个尺度由三个堆叠的残差块组成。类似于 Nah 等人的工作。我们在残差块中不使用任何归一化层。我们使用 Stride-Conv 层将特征图从之前的尺度下采样 1/2。
解码器包含三个尺度,每个尺度也由三个残差块堆叠。我们使用 Transposed-Conv 层对特征进行 2 倍的上采样。每个卷积层后面都有一个非线性 ReLU 层,Conv24 除外。我们通过求和操作跳过连接特征图。此外,我们使用残差学习来学习模糊图像和干净图像之间的区别。
对于对抗性学习,我们通过传统分类器构建鉴别器,由卷积、非线性 ReLU 和实例归一化层的分支堆叠。
损失训练
我们使用有监督和无监督损失来训练相应的分支。
(1)监督损失:我们使用均方损失来确保预测图像 J 接近真实值 ![]()
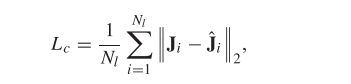
其中![]() 表示小批量中标记数据的数量。此外,J 和
表示小批量中标记数据的数量。此外,J 和 ![]() 分别表示预测图像 J 和对应的真实图像
分别表示预测图像 J 和对应的真实图像 ![]() 的向量形式。为了生成照片般逼真的图像,我们还使用基于预训练 VGG-19 网络的感知损失:
的向量形式。为了生成照片般逼真的图像,我们还使用基于预训练 VGG-19 网络的感知损失:
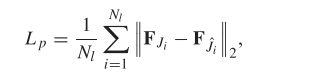
![]()
![]() 表示特征的向量形式,表示预测与真实图片的差值,特征图来自在 ImageNet上预训练的 VGG-19 网络的 conv3-3 层。
表示特征的向量形式,表示预测与真实图片的差值,特征图来自在 ImageNet上预训练的 VGG-19 网络的 conv3-3 层。
为了生成清晰且视觉上令人愉悦的图像,我们遵循 GAN 模型并构建鉴别器 Dis 来区分图像是由生成器 G(即 J)生成还是来自标记数据的真实数据(即 J^ )。对抗性损失可以表示为:
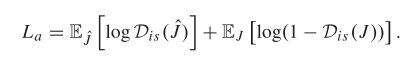
(2)无监督损失:我们使用总变化和暗通道损失来加强无监督分支,以生成与干净图像具有相同统计属性的图像。总变化损失,即无监督分支对预测图像的L 1正则化梯度先验,用于保留结构和细节:
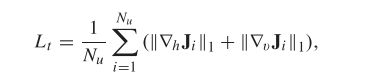
其中,![]() 和
和![]() 分别表示水平微分运算矩阵和垂直微分运算矩阵。
分别表示水平微分运算矩阵和垂直微分运算矩阵。
干净图像的暗通道已被证明比有雾图像的暗通道更稀疏。它可以表示为
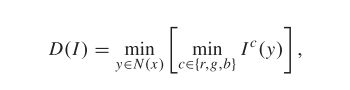
其中 x 和 y 是像素坐标,![]() 表示第 c 个颜色通道,N(x) 是以 x 为中心的图像块。受此启发,我们应用 L1-正则化 来约束预测图像的暗通道的稀疏性:
表示第 c 个颜色通道,N(x) 是以 x 为中心的图像块。受此启发,我们应用 L1-正则化 来约束预测图像的暗通道的稀疏性:
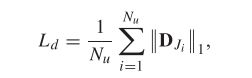
其中,![]() 表示预测图像
表示预测图像![]() 的暗通道的向量形式。
的暗通道的向量形式。
我们应用 5 × 5 的矩阵来表示单通道图像。在前向阶段,图像的暗通道计算为:
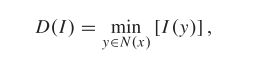
其中图像块 N(y)的大小设置为3×3。如图3(a)所示,每个patch的暗像素用不同的颜色标记。我们反复填充图像以处理边界问题。在后向阶段,图像的暗像素通过求和收集相应像素的传播梯度。
(3)) 整体损失函数:我们结合监督损失、无监督损失和对抗损失来训练提议的网络:
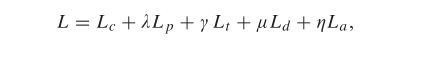
其中λ、γ、μ和η是每个损失函数的正权重。
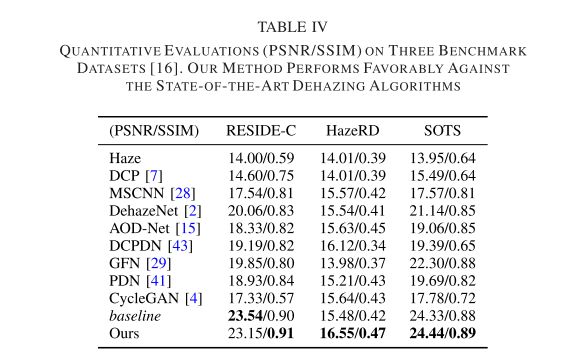
实验结果:
RESIDE-C 数据集包含 100 个室内和 100 个室外的合成模糊图像,随机选自ITS 和 OTS 数据库。我们注意到所选图像不会出现在我们的训练数据中。然后,我们在 HazeRD和 SOTS数据集上评估我们的方法。