BF串的朴素算法和KMP算法
目录
-
- 一、BF串的朴素算法
- 二、KMP算法
-
- 1. 引入
- 2. KMP算法的核心思想
- 3. KMP算法的next数组求解思想
- 4. KMP算法代码实现
- 三、KMP算法优化
一、BF串的朴素算法

子串在主串里面的搜索过程叫做模式匹配。
BF算法就是暴力搜索算法,效率低。BF算法的思想:
定义变量i=0和j=0来分别遍历主串和子串,对应位置进行比较,

- 如果对应位置相等的话,
i++;j++


- 如果对应位置不相等,
i=i-j+1;j=0;
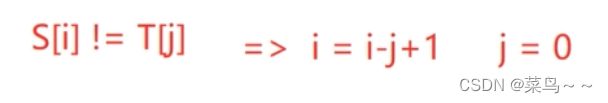

然后继续进行比较是否相等,比较的前提是i和j必须小于他们的长度

如果是子串的j==T.length跳出循环,则表示找到子串在主串中的起始位置并返回


如果i==S.length表示主串里根本没有主串。
代码实现:
#include如果主串的长度为n,子串的长度为m,时间复杂度O(n*m),空间复杂度O(1)。

分析算法缺陷:

主串里的B和子串里的A根本不用比较,因为C和D适配之前,前面肯定都是匹配的,一模一样的,那我们其实可以分析子串的规律,可以发现A和B两个字符不相等,那么现在AB和主串里的对应位置的字符相等,那么那时候拿子串的A和主串的B比较肯定不相等。所以下面这一步是没有用的判断,结果肯定失败。

我们需要考虑这么一个问题:BF算法中对于子串的形状没有做任何分析,导致匹配过程中做了很多无效的匹配操作(明知结果不可能匹配成功的操作),导致算法效率降低。我们现在需要做的就是,让匹配过程中,主串的i不用回退,提高算法的效率,这就是KMP算法的思想。
二、KMP算法
1. 引入
子串字符都互不相同(下图画×的是不可能成立的比较)

在第2步发现f和x不匹配了,于是i回退到1,j回退到0。通过分析我们知道,主串和模式串的abcde都匹配,且abcde又各不相同,拿着模式串的a去和主串的b、c、d、e去比较就没有意义
但是第7步用模式串的a和主串的f比较就是有意义的,因为我们知道模式串的x不等于主串的f,模式串的x也不等于模式串的a,故和x不相同的两个字符是有可能相同的,所以需要拿着模式串的a和主串的f比较
所以应该跳过中间无效的比较,确保我们所有的比较都是有效的,模式串是已知的,主串是未知的,我们只比较未知的字符( 模式串的字符和主串中未遍历的字符比较),不拿两个已知字符比较(模式串的字符和主串中已经遍历过的字符比较)
我们知道主串的i是不用回退的,那模式串的j每次就都是回退到0吗?这个不一定,回退到哪里,和模式串的结构有关
子串中有重复的字符(下图画×的是不可能成立的比较,画√的是肯定成立的比较,都无需作比较,绿色框里的是需要比较)

为什么子串的j回退到2,前面说j回退到哪里,和模式串的结构有关,能直接跳到步骤7,核心原因就是模式串中abcab有公共前后缀ab,即在后缀和主串匹配完成的前提下,前缀也就直接和主串相应的部分匹配了,在BF算法基础下直接跳到前缀的下一个字符再比较即可。

2. KMP算法的核心思想
字符失配后,主串的i不做回退操作,只回退子串的j,由于在任意一个字符匹配时,都有可能失配,所以KMP算法的关键是给子串计算出一个next数组,里面存储的是当前字符失配时j要回退到的位置,同理也就是存储的当前字符前面子串的公共前后缀长度。
3. KMP算法的next数组求解思想
定义的next数组是给子串定义的,子串的每一个字符对应的next数组里面存储了这个字符前面串的最长公共前后缀。
定义j和k

当j=0时,k=-1;next[j]=-1,-1在这里是一个很巧妙的处理。比如下面这个匹配

这里首字母比较都不相同,这就不可能i不动只回退j。j回退到next[0]值是-1,就说明它连首字母都匹配失败了,此时我们i++;j++,这里面j++后就变成0了,把-1看做一个标志,推动i也向后++

当j=1时,k=0;next[1]=0。因为要求一个字符串的公共前后缀,前面最起码得有两个字符,才能求前后有没有公共的字符或字符串。当j=1的时候前面只有一个字符没有公共前后缀,所以next[1]=0。
字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串; 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
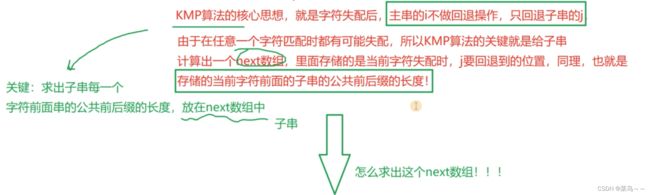
继续比较,当子串满足P0...Pk-1=Pj-k...Pj-1,前后缀对应的字符相当,那么next[j]=k,k表示公共前后缀长度。


我们已经知道了next[j]的公式,现在核心就是要知道next[j+1]是多少?会算这个那么next数组计算问题就都解决了。
![]()
- 当
Pk==Pj时,next[j+1]=k+1

- 当
Pk!=Pj时,k=next[k],只做k的回退操作就行

前面是相同的,但是末尾的这个字符不同,所以公共的前后缀并没有这么长,所以就意味着要在前面P0…Pk-1范围内再找一找看有没有和第j个字符相等的。所以k值需要回退,找看有没有和Pj相等的。
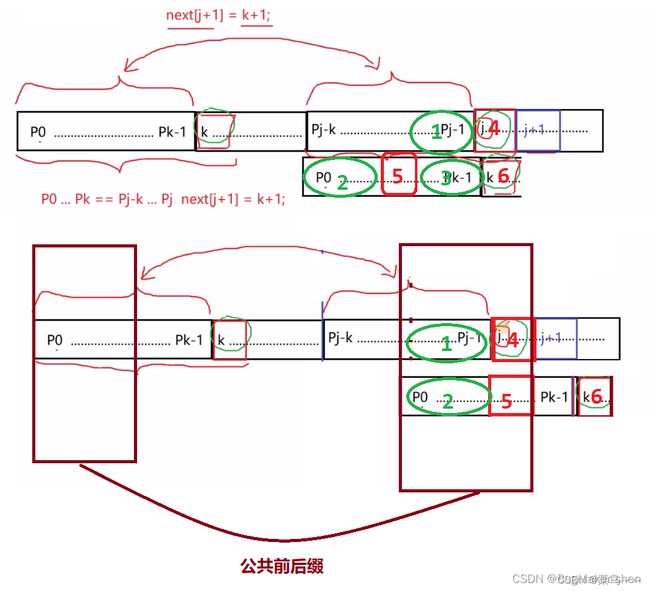
我们现在是4!=6,那我们需要在前面找一个字符5,使得54,并且还要确保12,由于我们知道13,所以只要保证23即可,next数组中字符6对应的位置存储的就是公共前后缀2和3的长度
也就是说如果没有回溯到首字符,回溯的地方5,必然能保证2==3,剩下只需要比较字符4是否等于字符5了。若相等,则找到公共前后缀的长度;若不等,则继续往前回溯,直到首字符
所以,当P k ≠ P j 时,一直做k=next[k],直到回溯的字符与当前字符相等,或到达首字符
4. KMP算法代码实现
KMP的核心是不回退i值,只回退j值。
#include三、KMP算法优化
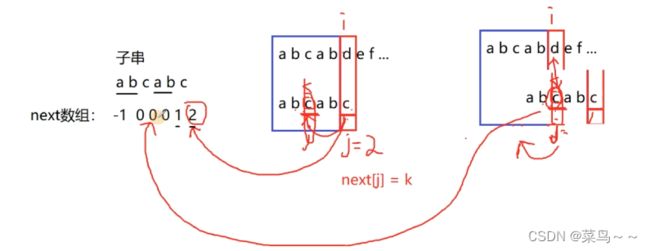
按照我们常规的求next数组的方法,d和c失配,应该回溯到下标为2的位置,可我们发现fmt[2]==fmt[5],所以fmt[2]肯定也匹配失败,所以next[5]不能放2,应该直接放上next[2]。这种情况(当前比较的字符失配了和回退到next[j]=k位置的字符相等),回退后肯定也不会和主串相等的,没有必要比较,j的值需要继续向前回退。
#include时间复杂度:O(n+m),空间复杂度O(n)。