使用卷积神经网络(普通CNN和改进型LeNet)以及数据增强和迁移学习技巧识别猫和狗,并制作成分类器软件(基于Keras)
数据集:https://www.microsoft.com/en-us/download/confirmation.aspx?id=54765
猫和狗的图片各自有12500张。
第一步
整理数据集,查看各类别图片的分辨率,发现猫和狗图片的分辨率都毫无规律,且不少于10种。
import os
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
dogs_dir = os.listdir(r'D:\kaggle\data\Dog')
cats_dir = os.listdir(r'D:\kaggle\data\Cat')
dog_shapes = []
cat_shapes = []
os.chdir(r'D:\kaggle\data\Dog')
for each in dogs_dir:
img = np.array(Image.open(each))
if img.shape not in dog_shapes:
dog_shapes.append(img.shape)
print('已知狗的图片分辨率有%d种'%(len(dog_shapes)))
if len(dog_shapes) == 10:
print('分辨率不少于10种')
break
print('\n')
os.chdir(r'D:\kaggle\data\Cat')
for each in cats_dir:
img = np.array(Image.open(each))
if img.shape not in cat_shapes:
cat_shapes.append(img.shape)
print('已知猫的图片分辨率有%d种'%(len(cat_shapes)))
if len(cat_shapes) == 10:
print('分辨率不少于10种')
break
第二步
数据预处理(裁剪,筛选,洗牌),然后保存成.npy文件,有些图片只有一个通道,所以没有选入数据集(大概60张左右,影响不大)。
import numpy as np
import os
from PIL import Image
from matplotlib import pyplot as plt
from sklearn.utils import shuffle
import warnings
warnings.filterwarnings("error", category=UserWarning)#捕获警告
dogs_dir = os.listdir(r'D:\kaggle\data\Dog')
cats_dir = os.listdir(r'D:\kaggle\data\Cat')
#训练集 11961:111935 测试集 498:500 狗:猫
#猫的标签[1,0] 狗的标签[0,1]
train_batches = []
train_labels = []
test_batches = []
test_labels = []
os.chdir(r'D:\kaggle\data\Dog')
for idx,each in enumerate(dogs_dir):
try:
img = Image.open(each)
img = np.array(img.resize((224,224),Image.ANTIALIAS))
except:
plt.imshow(img)
plt.show()
if img.shape !=(224,224,3):
continue
if idx >= 12000:
test_batches.append(img)
test_labels.append(np.array([0,1]))
if (idx+1) %100 == 0:
print('狗图片的测试集已完成:{:.2f}%'.format((len(test_batches)/500)*100))
else:
train_batches.append(img)
train_labels.append(np.array([0,1]))
if (idx+1) %100 == 0:
print('狗图片的训练集已完成:{:.2f}%'.format((len(train_batches)/12000)*100))
print('\n')
os.chdir(r'D:\kaggle\data\Cat')
for idx,each in enumerate(cats_dir):
try:
img = Image.open(each)
img = np.array(img.resize((224,224),Image.ANTIALIAS))
except:
plt.imshow(img)
plt.show()
if img.shape !=(224,224,3):
continue
if idx >= 12000:
test_batches.append(img)
test_labels.append(np.array([1,0]))
if (idx+1) %100 == 0:
print('猫图片的测试集已完成:{:.2f}%'.format(((len(test_batches)-500)/500)*100))
else:
train_batches.append(img)
train_labels.append(np.array([1,0]))
if (idx+1) %100 == 0:
print('猫图片的训练集已完成:{:.2f}%'.format(((len(train_batches)-12000)/12000)*100))
#打乱数据
train = shuffle(train_batches,train_labels)
test = shuffle(test_batches,test_labels)
#把dataset以npy格式保存
os.chdir(r'D:\kaggle')
np.save('train_batches.npy',train[0])
np.save('train_labels.npy',train[1])
np.save('test_batches.npy',test[0])
np.save('test_labels.npy',test[1])
第三步
建模(训练模型,评估模型,保存模型)
由于内存不够,只能取部分数据集进行训练,但训练集和测试集准确率还是能达到百分之七十以上。
网络模型包括三层(卷积+池化),在输出层展开并利用Dense层改变输出维度,笔者曾尝试过使用rate=0.3的Dropout层(位于Dense层前)抑制过拟合,结果效果并不理想,虽然测试集与训练集精度差值减小,可是代价是两者的精度都降低了大概5个百分点,于是我改成使用权重正则化(L2正则化)约束权重的更新,效果虽然未达到期盼(精度还是没上80),但效果比Dropout要好。
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten ,Dense
from keras.models import Model
import keras
#Loss = 0.6403 Train accuracy = 0.7803 Test accuracy = 0.7224
def get_data():
train_batches = np.load(r'D:\kaggle\train_batches.npy',allow_pickle=True)
train_labels = np.load(r'D:\kaggle\train_labels.npy',allow_pickle=True)
test_batches = np.load(r'D:\kaggle\test_batches.npy',allow_pickle=True)
test_labels = np.load(r'D:\kaggle\test_labels.npy',allow_pickle=True)
return (train_batches,train_labels),(test_batches,test_labels)
#载入数据集
(train_x_batch,train_y_batch),(test_x_batch,test_y_batch)=get_data()
#内存不够,取部分图片训练
train_x_batch = train_x_batch[0:4000]
train_y_batch = train_y_batch[0:4000]
#归一化
train_x_batch = train_x_batch.astype('float32') / 255.0
test_x_batch = test_x_batch.astype('float32') / 255.0
#建模
input_imgs = Input(shape=train_x_batch[0].shape)
tower_1 = Conv2D(32, (3, 3), padding='same', activation='relu',kernel_regularizer=keras.regularizers.l2(0.01))(input_imgs)
tower_1 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_1)
tower_2 = Conv2D(32, (3, 3), padding='same', activation='relu',kernel_regularizer=keras.regularizers.l2(0.01))(tower_1)
tower_2 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_2)
tower_3 = Conv2D(64, (3, 3), padding='same', activation='relu',kernel_regularizer=keras.regularizers.l2(0.01))(tower_2)
tower_3 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_3)
flat_imgs = Flatten()(tower_3)
output = Dense(2, activation='softmax')(flat_imgs)
model = Model(inputs = input_imgs,outputs = output)
#编译模型
model.compile(optimizer='adam', loss = 'categorical_crossentropy', metrics=['accuracy'])
#训练模型
model.fit(train_x_batch,train_y_batch,epochs=10,batch_size=96,verbose=1)
#保存模型
model.save_weights("weights")
with open("model.json", "w") as f:
f.write(model.to_json())
#评估模型
preds = model.evaluate(test_x_batch,test_y_batch)
print('Loss = ' + str(preds[0]))
print('Test Accuracy = ' + str(preds[1]))
input()
为了进一步提高精度,尝试使用经典的改进型LeNet网络,该网络架构为:
Input->第一层卷积层(size=55,Cout=32)->第一层最大值池化层->第二层卷积层(size=55,Cout=64)->第二层最大值池化层->Flatten->Dense层(神经元数目=1024)->Dropout层(保留比例=0.5)->Dense层(改变输出维度)->Output.
此外,为了抑制过拟合,将数据量从4000增加至5000,同时将epochs从10降低为8.
按照架构一步步建模,接着训练,便可得到结果,代码和结果如下:
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten ,Dense ,Dropout
from keras.models import Model
import keras
#Loss = 1.1238 Train accuracy = 0.9428 Test accuracy = 0.6303
def get_data():
train_batches = np.load(r'D:\kaggle\train_batches.npy',allow_pickle=True)
train_labels = np.load(r'D:\kaggle\train_labels.npy',allow_pickle=True)
test_batches = np.load(r'D:\kaggle\test_batches.npy',allow_pickle=True)
test_labels = np.load(r'D:\kaggle\test_labels.npy',allow_pickle=True)
return (train_batches,train_labels),(test_batches,test_labels)
#载入数据集
(train_x_batch,train_y_batch),(test_x_batch,test_y_batch)=get_data()
#内存不够,取部分图片训练
train_x_batch = train_x_batch[0:5000]
train_y_batch = train_y_batch[0:5000]
#归一化
train_x_batch = train_x_batch.astype('float32') / 255.0
test_x_batch = test_x_batch.astype('float32') / 255.0
#建模(改进型LeNet)
input_imgs = Input(shape=train_x_batch[0].shape)
tower_1 = Conv2D(32, (5, 5), padding='same', activation='relu')(input_imgs)
tower_1 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_1)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_1)
tower_2 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_2)
flat_imgs = Flatten()(tower_2)
fc = Dense(1024, activation='relu')(flat_imgs)
drop = Dropout(rate=0.5)(fc)
output = Dense(2, activation='softmax')(drop)
model = Model(inputs = input_imgs,outputs = output)
#编译模型
model.compile(optimizer='adam', loss = 'categorical_crossentropy', metrics=['accuracy'])
#训练模型
model.fit(train_x_batch,train_y_batch,epochs=8,batch_size=96,verbose=1)
#保存模型
model.save_weights("weights")
with open("model.json", "w") as f:
f.write(model.to_json())
#评估模型
preds = model.evaluate(test_x_batch,test_y_batch)
print('Loss = ' + str(preds[0]))
print('Test Accuracy = ' + str(preds[1]))
input()
由结果可知,训练集精度的确得到有效提升,然而出现了严重的过拟合问题。
对付过拟合问题,除了正则化技术和BatchNnormalization外,还有一个强有力的武器——数据增强。我们使用keras.preprocessing.imageImageDataGenerator来实现数据增强,其拥有以下重要参数:
rotation_range :在指定角度范围内,对图片作随机角度的选择。
width_shift_range:在指定长度范围内,对图片的宽度作随机长度的变换。
height_shift_range:在指定长度范围内,对图片的高度作随机长度的变换。
rescale:可以实现归一化(1/255)
shear_range:可以实现剪切变换,参见剪切变换
zoom_range:在指定范围内实现放大和缩小
horizontal_flip:水平翻转
注意,要将数据整理成以下形式("/"表示一个目录):
/train
/dog
dog0.jpg
dog1.jpg
...
/cat
cat0.jpg
cat1.jpg
...
/val
/dog
dog1500.jpg
...
/cat
cat1500.jpg
...
此外,将损失函数调整为binary_crossentropy并调整输出层,将输出维度调整为1。由于使用了数据增强,可以上调dropout的保留比例,并且增加网络的深度,使得模型学习到更丰富的特征。
另外由于输出维度的改变,使得分类器的调用函数需要重写。如下:
def classify(self,img_dir):
model = load_model()
img_dir = self.img_dir
categories = ['猫','狗']
img = (Image.open(img_dir)).resize((224,224),Image.ANTIALIAS)
img = ((np.array(img)).reshape(1,224,224,3))/255
pred = model.predict((np.array(img)).reshape(1,224,224,3))
if pred.size > 1:
name = categories[np.argmax(pred)]
confidence = str(pred[0][np.argmax(pred[0])])
else:
if pred[0][0] < 0.5:
name = '猫'
confidence = str(1-pred[0][0])
else:
name = '狗'
confidence = str(pred[0][0])
self.textBrowser.setText('预测结果为:'+name+'\n置信度为:'+confidence)
模型的代码和结果如下所示:
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten ,Dense ,Dropout
from keras.models import Model
from keras.preprocessing.image import ImageDataGenerator
import keras
#Loss = 0.4673 Train accuracy = 0.8012 Test accuracy = 0.8124
#采用增强的数据进行训练
train_datagen = ImageDataGenerator(rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
rescale = 1/255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest')
train = train_datagen.flow_from_directory(r'D:\kaggle\data\for_enhanced_data\train',
target_size=(224,224),
batch_size=96,
class_mode='binary')
#创造验证集
test_datagen = ImageDataGenerator(rescale=1/255)
validation_generator = test_datagen.flow_from_directory(r'D:\kaggle\data\for_enhanced_data\val',
target_size=(224, 224),
batch_size=50,
class_mode='binary'
#建模(改进型LeNet)
input_imgs = Input(shape=(224,224,3).shape)
tower_1 = Conv2D(32, (3, 3), padding='same', activation='relu')(input_imgs)
tower_1 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_1)
tower_2 = Conv2D(32, (3, 3), padding='same', activation='relu')(tower_1)
tower_2 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_2)
tower_3 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_2)
tower_3 = MaxPooling2D((2, 2), strides=(2, 2), padding='same')(tower_3)
flat_imgs = Flatten()(tower_3)
fc = Dense(512, activation='relu')(flat_imgs)
drop = Dropout(rate=0.8)(fc)
output = Dense(1, activation='sigmoid')(drop)
model = Model(inputs = input_imgs,outputs = output)
#编译模型
model.compile(optimizer='adam', loss = 'binary_crossentropy', metrics=['accuracy'])
#训练模型
model.fit_generator(train,
samples_per_epoch = 3000,
nb_epoch = 60,
validation_data = validation_generator,
nb_val_samples=800)
#保存模型
model.save_weights("weights")
with open("model.json", "w") as f:
f.write(model.to_json())
input()
可见精度达到了百分之八十左右,效果还是挺不错的。
可是我们还想进一步提高精度,于是想到增加网络的深度和宽度,用深度学习的思路去建模,可是问题来了,具有相当深度和宽度的网络,需要的算力可不是一般人能承担的。好在别人已经帮我们训练好了模型(在别的任务上,比如ImageNet),我们可以使用迁移学习的技巧,既能节省运算资源,也能使模型获得良好的性能。
迁移学习分为两步,首先要冻结基础模型所有的层,只训练新层;然后冻结基础模型的部分层,训练剩余的层和新层。
良好的微调能使模型从别的任务学到的特征重用到自己的任务里(比如纹理、颜色等细节),从而使得模型具有良好的泛化能力。
代码和结果如下图所示:
我是手动下载InceptionV3的模型数据再导入的,模型数据下载资源不好找,可以从GITHUB下载或者私信我。
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten ,Dense ,Dropout ,GlobalAveragePooling2D
from keras.models import Model,load_model
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.inception_v3 import InceptionV3,preprocess_input
from keras.optimizers import Adagrad
import keras
#Loss = 0.0495 Train accuracy = 0.9835 Test accuracy = 0.976
#采用增强的数据进行训练
train_datagen = ImageDataGenerator(rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
rescale = 1/255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest')
train = train_datagen.flow_from_directory(r'D:\kaggle\data\for_enhanced_data\train',
target_size=(299,299),
batch_size=96,
class_mode='binary')
#创造验证集
test_datagen = ImageDataGenerator(rescale=1/255)
validation_generator = test_datagen.flow_from_directory(r'D:\kaggle\data\for_enhanced_data\val',
target_size=(299, 299),
batch_size=50,
class_mode='binary')
#建模(迁移学习InceptionV3)
base_model = InceptionV3(weights=None,include_top=False)
base_model.load_weights(r'D:\kaggle\inceptionV3\inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5')
# 增加新的输出层
global_pooling = GlobalAveragePooling2D()(base_model.output) # GlobalAveragePooling2D 将 MxNxC 的张量转换成 1xC 张量,C是通道数
fc = Dense(512,activation='relu')(global_pooling)
drop = Dropout(rate=0.8)(fc)
output = Dense(1,activation='sigmoid')(drop)
model = Model(inputs=base_model.input,outputs=output
#编译模型(两步,第一步只训练新层,基础模型冻结;第二步训练基础模型的部分层以及新层,其余层冻结。
def setup_to_transfer_learning(model,base_model):#base_model
for layer in base_model.layers:
layer.trainable = False
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
def setup_to_fine_tuning(model,base_model):
FROZEN_LAYER = 16
for layer in base_model.layers[:FROZEN_LAYER]:
layer.trainable = False
for layer in base_model.layers[FROZEN_LAYER:]:
layer.trainable = True
model.compile(optimizer=Adagrad(lr=0.0001),loss='binary_crossentropy',metrics=['accuracy'])
#训练和评估模型
setup_to_transfer_learning(model,base_model)
model.fit_generator(train,
samples_per_epoch = 3000,
nb_epoch = 3,
validation_data = validation_generator,
nb_val_samples=800)
setup_to_fine_tuning(model,base_model)
model.fit_generator(train,
samples_per_epoch = 3000,
nb_epoch = 3,
validation_data = validation_generator,
nb_val_samples=800)
#保存模型
model.save_weights("weights")
with open("model.json", "w") as f:
f.write(model.to_json())
input()
可见结果是相当好的。基本上人能分辨出来的,模型都能分辨出来。
第四步
使用PyQt5为分类器设置用户界面
安装:
1.pip install PyQt5
2.pip install pyqt5-tools
建议下载国内镜像,速度更快,如果安装过程中出现ReadTimeoutError,只需要重新进行安装就可以了。
安装完后,在cmd中输入pyuic5,如果出现Error: one input ui-file must be specified,则说明安装成功。否则,你可能需要去配置环境变量,打开控制面板-系统和安全-系统-高级系统设置-环境变量,然后在path里输入相应的路径即可。
找到安装的地址(一般在Python的Scripts目录下),打开可执行文件pyqt5designer.exe,便可进入GUI的设置界面
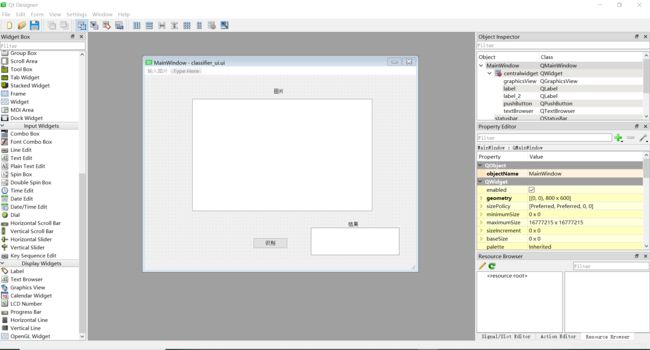 左边可以选择你想要的工具,将其按住并拖入到主窗口便可自动生成,非常方便,这里注意一个问题:Textedit是编辑文本,Textbrowser是用来显示文本的,这里我们使用Textbrowser,如果需要编辑文本,也可以自行添加。窗口设计完后,将其保存在和模型的同一个目录下,然后在用cmd进入该目录,输入命令
左边可以选择你想要的工具,将其按住并拖入到主窗口便可自动生成,非常方便,这里注意一个问题:Textedit是编辑文本,Textbrowser是用来显示文本的,这里我们使用Textbrowser,如果需要编辑文本,也可以自行添加。窗口设计完后,将其保存在和模型的同一个目录下,然后在用cmd进入该目录,输入命令pyuic5 -o classifier.py classifier_ui.ui便可生成一个.py文件。建立文件main.py,进入文件,导入相应的库(其中classifier_ui是我们之前生成的文件)
import sys
from classifier_ui import *
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QApplication, QMainWindow
并添加主函数
if __name__ == '__main__':
app = QApplication(sys.argv)
MainWindow = QMainWindow()
ui = Ui_MainWindow()
ui.setupUi(MainWindow)
MainWindow.show()
sys.exit(app.exec_())
运行该文件,如果不出意外,你可以看见自己设计的GUI界面。
首先,我们需要利用QFileDialog.getOpenFileName获取图片。这需要在之前生成的classify_ui.py文件中加入一个load_img函数,具体实现方法为
def openImg(self):
file_name, _ = QFileDialog.getOpenFileName(None, '选择图片', 'D:\\', 'Image files(*.jpg *.gif *.png)')
print(file_name)
接着我们可以利用graphicsView.setPixmap(QPixmap(file_name))来将获取的图片显示在Label上。
然后我们可以使用ui.pushButton.clicked.connect(func,args)来绑定事件。
那么这里func就应该实现模型对输入图片的识别。
同时,我们可以使用ui.textBrowser.setText(),将识别的结果显示在TextBrowser内。
完整代码如下:
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtWidgets import QApplication, QMainWindow,QAction,QFileDialog
from PyQt5.Qt import *
from keras.models import model_from_json
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import os
def load_model():
#载入模型
model = model_from_json(open('model.json').read())
model.load_weights('weights')
return model
class Ui_MainWindow(object):
def __init__(self):
self.img_dir = None
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(800, 600)
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.pushButton = QtWidgets.QPushButton(self.centralwidget)
self.pushButton.setGeometry(QtCore.QRect(320, 480, 101, 31))
self.pushButton.setObjectName("pushButton")
self.pushButton.clicked.connect(self.classify)
self.textBrowser = QtWidgets.QTextBrowser(self.centralwidget)
self.textBrowser.setGeometry(QtCore.QRect(490, 450, 261, 81))
self.textBrowser.setObjectName("textBrowser")
self.label = QtWidgets.QLabel(self.centralwidget)
self.label.setGeometry(QtCore.QRect(600, 430, 72, 20))
self.label.setObjectName("label")
self.graphicsView = QtWidgets.QLabel(self.centralwidget)
self.graphicsView.setGeometry(QtCore.QRect(140, 70, 531, 331))
self.graphicsView.setObjectName("graphicsView")
self.label_2 = QtWidgets.QLabel(self.centralwidget)
self.label_2.setGeometry(QtCore.QRect(380, 40, 72, 15))
self.label_2.setObjectName("label_2")
MainWindow.setCentralWidget(self.centralwidget)
self.statusbar = QtWidgets.QStatusBar(MainWindow)
self.statusbar.setObjectName("statusbar")
MainWindow.setStatusBar(self.statusbar)
self.menuBar = QtWidgets.QMenuBar(MainWindow)
self.menuBar.setGeometry(QtCore.QRect(0, 0, 800, 26))
self.menuBar.setObjectName("menuBar")
self.menu = QtWidgets.QMenu(self.menuBar)
self.menu.setObjectName("menu")
MainWindow.setMenuBar(self.menuBar)
self.localfile_action = QAction(MainWindow)
self.localfile_action.setCheckable(False)
self.localfile_action.setObjectName('localFileAction')
self.localfile_action.triggered.connect(self.openImg)
self.localfile_action.setText('输入图片')
self.menuBar.addAction(self.localfile_action)
self.retranslateUi(MainWindow)
QtCore.QMetaObject.connectSlotsByName(MainWindow)
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))
self.pushButton.setText(_translate("MainWindow", "识别"))
self.label.setText(_translate("MainWindow", "结果"))
self.label_2.setText(_translate("MainWindow", "图片"))
def openImg(self):
file_name, _ = QFileDialog.getOpenFileName(None, '选择图片', 'D:\\', 'Image files(*.jpg *.gif *.png)')
self.graphicsView.setPixmap(QPixmap(file_name))
self.img_dir = file_name
def classify(self,img_dir):
model = load_model()
img_dir = self.img_dir
categories = ['猫','狗']
img = (Image.open(img_dir)).resize((224,224),Image.ANTIALIAS)
img = ((np.array(img)).reshape(1,224,224,3))/255
pred = model.predict(img)
if pred.size > 1:
name = categories[np.argmax(pred)]
confidence = str(pred[0][np.argmax(pred[0])])
else:
if pred[0][0] < 0.5:
name = '猫'
confidence = str(1-pred[0][0])
else:
name = '狗'
confidence = str(pred[0][0])
self.textBrowser.setText('预测结果为:'+name+'\n置信度为:'+confidence)
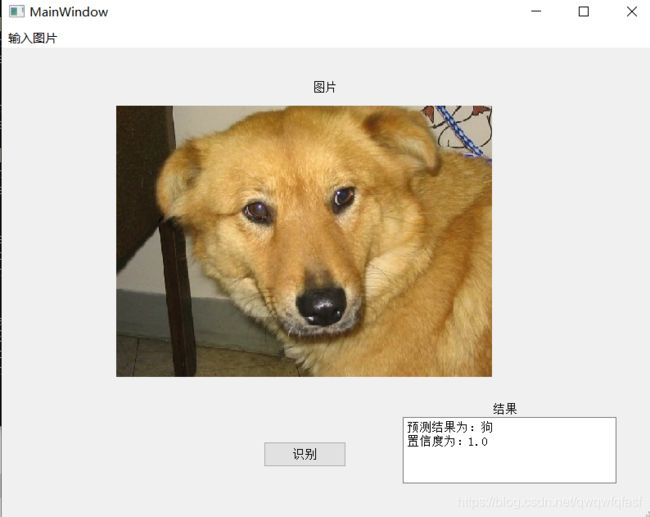
最终结果如图所示