YOLOv5Face YOLO5Face人脸检测论文及代码简析
YOLO5face人脸检测模型论文和代码简析
- YOLO5Face模型分析
-
- 论文及源码下载
- 论文创新点
- 实验结果
- 下载代码跑起来
- 调整数据集
- 训练完成之后检验结果
- 一点点代码简析
-
- 文件结构
- data
- models
-
- common.py
- utils
- 一些问题
- 参考文章
YOLO5Face论文发出以后,对YOLO5Face论文进行分析的文章较少,就想写一篇对YOLO5Face进行分析的文章,主要也是非常喜欢YOLO系列,博主也是刚刚入门人脸检测,写的就是一篇小白文,也第一次写文章,有不正确的地方希望大神们多多指正。
YOLO5Face模型分析
论文及源码下载
论文地址:https://arxiv.org/abs/2105.12931论文我们中国人写的,读起来还是挺顺的。
源码地址:https://github.com/deepcam-cn/yolov5-face
WiderFace地址:WIdeFace
Yolo5Face是深圳神目科技&LinkSprite Technologies(美国)在Yolov5模型基础上进行更新得到的人脸检测模型,在WiderFace上取得了SOTA。
论文创新点
正如论文名字的后半部分Why Reinventing a Face Detector?论文将人脸检测视为一般的目标检测任务,所以作者以现在比较热门的YOLOv5模型为基础,辅助以人脸特性,得到一个新的人脸检测器。
论文创新点:
-
在YOLOv5网络中添加五个人脸关键点回归,回归的损失函数用的是Wing loss。(类比MTCNN、RetinaFace)
MTCNN中使用L2损失作为5个人脸关键点的回归损失,但是L2对小的误差并不敏感,为了克服这个问题,Wing-Loss出现了。
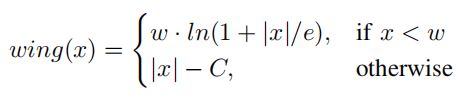
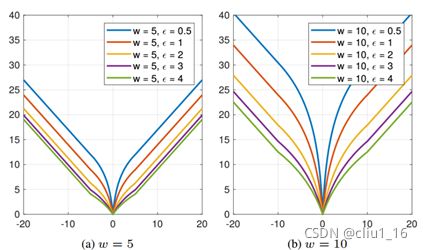
可以看到Wing-loss是一个分段的复合损失函数,在训练初期误差较大时用L1损失,在训练后期误差相对小,用一个具有偏移量的对数函数。wing-loss的优点我也不能很好的论述清楚,感兴趣的可以去看这篇博客。https://blog.csdn.net/john_bh/article/details/106302026
作者将五个人脸关键点回归损失加入到总的损失函数中去后,作者将这部分损失函数称为LossL并给这部分损失加上权重,加上YOLOv5本身的损失函数LossO,总的损失函数为Loss(s)。
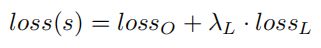
作者在配置文件里面写的:landmark: 0.005 # landmark loss gain,那应该这个权重就是0.005,具体的代码我还没有看到,看到以后如果不对再改。 -
用Stem模块替代网络中原有的Focus模块,提高了网络的泛化能力,降低了计算复杂度,同时性能也没有下降。
Focus模块出来的时候,就有人说Focus模块比较鸡肋。可能是作者想改掉这部分又不想大改v5的整体模型,所以设计出一个相对更好的模块。
Stem模块的图示中虽然都是用的CBS,但是看代码可以看出来第2个和第4个CBS是1x1卷积,第1个和第3个CBS是3x3,stride=2的卷积。配合yaml文件可以看到stem以后图像大小由604x640变成了160x160。
class StemBlock(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=None, g=1, act=True):
super(StemBlock, self).__init__()
self.stem_1 = Conv(c1, c2, k, s, p, g, act) # 已经下采样一次了
self.stem_2a = Conv(c2, c2 // 2, 1, 1, 0)
self.stem_2b = Conv(c2 // 2, c2, 3, 2, 1)
self.stem_2p = nn.MaxPool2d(kernel_size=2,stride=2,ceil_mode=True)
self.stem_3 = Conv(c2 * 2, c2, 1, 1, 0)
def forward(self, x):
stem_1_out = self.stem_1(x)
stem_2a_out = self.stem_2a(stem_1_out)
stem_2b_out = self.stem_2b(stem_2a_out)
stem_2p_out = self.stem_2p(stem_1_out)
out = self.stem_3(torch.cat((stem_2b_out,stem_2p_out),1))
return out

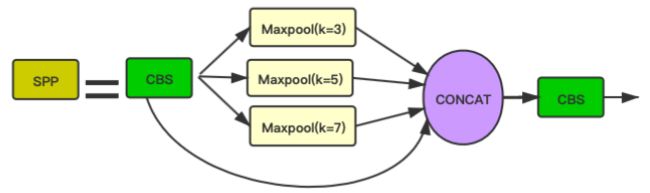
- 对SPP模块进行更新,使用更小的kernel,使yolov5更适用于人脸检测并提高了检测精度。YOLOv5用的SPPkernel(5,9,13),YOLO5Face用的kernel(3,5,7)。
- 添加一个stride = 64的P6输出块,P6可以提高对大人脸的检测性能。(之前的人脸检测模型大多关注提高小人脸的检测性能,这里作者关注了大人脸的检测效果,提高大人脸的检测性能来提升模型整体的检测性能)。P6的特征图大小为10x10。
- 发现一些目标检测的数据增广方法并不适合用在人脸检测中,包括上下翻转和Mosaic数据增广。删除上下翻转可以提高模型性能。对小人脸进行Mosaic数据增广反而会降低模型性能,但是对中尺度和大尺度人脸进行Mosaic可以提高性能。随机裁剪有助于提高性能。
这里主要还是COCO数据集和WiderFace数据集尺度有差异,WiderFace数据集小尺度数据相对较多。 - 基于ShuffleNetv2设计了两个轻量级模型,backbone和CSP网络不同,模型非常小,可以在嵌入式设备和移动设备达到SOTA。
依托YOLOv5可以调整网络宽度和深度的特点,作者可以方便的设计不同深度和宽度的网络模型,还用ShuffleNetv2设计了轻量级模型,也就是说从复杂到简单,从服务器到嵌入式或者移动设备,都有可以选择的模型。
实验结果
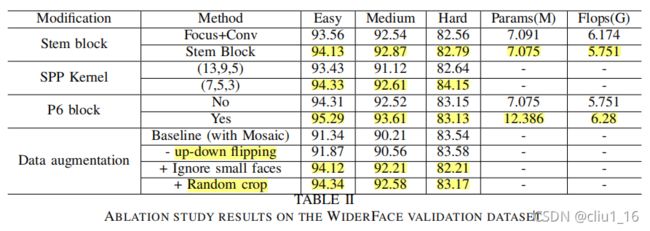
可以看到作者用的各种模块基本上都能提升map,忽略小人脸进行Mosaic数据增广Easy和Medium的map提升,但是hard的map下降了一些,模型整体的map提升。
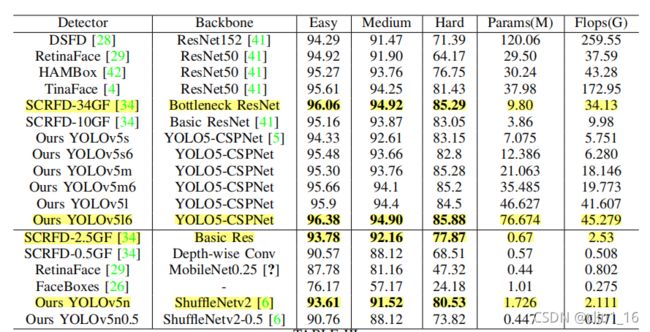
对比实验主要还是和SCRFD进行对比,可以看到SCRFD的模型整体性能也很好,并且参数和计算量相对比YOLOv5l6小一些,但是YOLOv5l6的map稍微更高一些。
实验最后的一些图显示YOLO5Face的召回率相比还有一些提升空间,但是评估中没有TTA方法。(我觉得可以看看看图里面比YOLO5Face召回率高的论文,分析一下为什么别的论文里面召回率更高一些,大神分析出来了请告诉我好吗)。
下载代码跑起来
下载代码的地址就是上面的github地址,如果没有配环境就慢慢配环境,不过我觉得更好的方法是把yolov5的代码下载下来,主要里面有个requirements.txt,在pycharm里面直接就能自动下载了,太爽了,没有什么就下载什么,很快就能把环境配好,然后打开yolo5face的代码,用v5自动配好的环境,如果有不匹配的再改。
调整数据集
现在我用的数据集目录结构:widerface和widerfaceyolo都用到了。
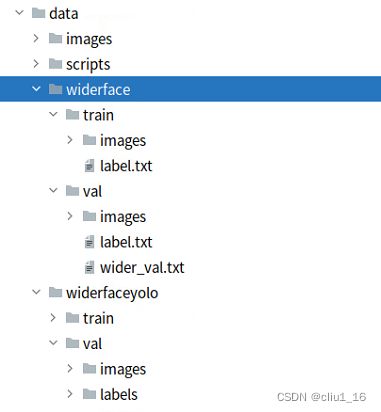
调整数据集其实需要分两步,我是把两步的数据集都放到项目里面了:
- 将官网训练集标签替换成带人脸关键点的标签,并将验证所需要的wider_val.txt放到路径下面,将数据集放在项目下命名为widerface,用于验证模型检测精度。
- 将数据集调整成YOLO5face所需要的的目录格式,命名为widerfaceyolo,用于训练。
这两步生成的数据集我都上传到腾讯微云了,如果不想看具体怎么操作的,可以直接点击链接获取已经调整好的数据集,下载下来放到自己的文件夹就行了。
- WiderFace官网下载数据集链接已经放到最上面了。下载的地方是这样的:
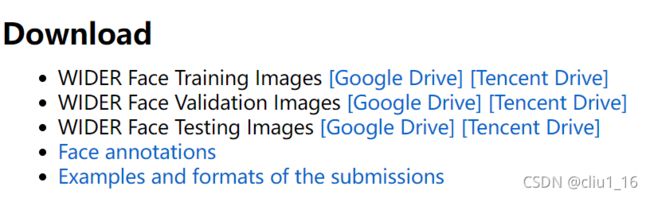 官网的数据集分三部分,Training和Validation是带标签的,test没有标签,可以暂时不下载。
官网的数据集分三部分,Training和Validation是带标签的,test没有标签,可以暂时不下载。 - 下载人脸关键点的标签:因为官网的训练集中人脸是不带关键点,yolo5face需要用到人脸关键点,需要下载带人脸关键点的注释。官网上给的下载地址是goole drive的地址。更换标签就完成了初步转换,要把这个初步转换的数据集放到项目里面去,然后在网上找到wider_val.txt也放到下面。因为后面要做检测精度的验证,目录结构和我上面的图里面的结构保持一致。
- 调整目录结构:
运行两个.py文件,就是官网上说的train2yolo.py和val2yolo.py。看名字也能看明白,这两个代码就是把数据集转成YOLO训练用的格式。
先改train2yolo.py
看名字应该看的懂的,save_path是转换之后的图片存到哪里,我是直接存到data下面了,注意文件夹一定要事先建好,不然会出错!第二行就是label.txt的位置,要根据label.txt找图片的位置,这就是为什么要调整好图片和labels.txt。
再改val2yolo.py, root改到widerface层

修改img和txt的输出路径,具体将图片和标签放不放在一起,看自己写的代码。

调整完成的widerfaceyolo目录结构:

和上面的总体结构一起看就能明白。 - 修改widerface.yaml文件,改为自己的数据集路径,记得把下载voc的代码注释掉,然后改成类似的格式就可以了。
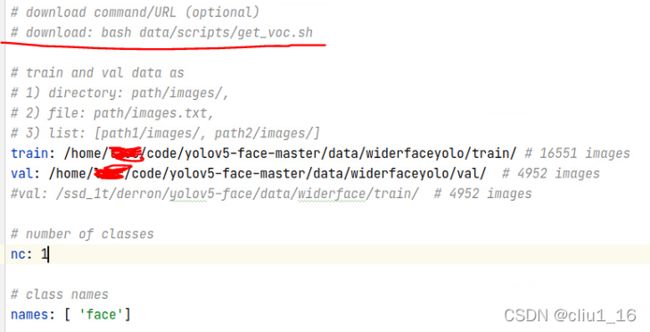
训练完成之后检验结果
runs文件夹下面有对应的训练输出结果,可以看到召回率,检测精度,map。
- 验证检测准确度
修改test_widerface.py文件,写入自己的训练好的权重路径
修改验证集图片路径,指出wider_val.txt的路径,我这里就是用的widerface的路径,不是widerfaceyolo的路径,相应的改成自己的路径即可。

这些步骤完成以后,运行test_widerface.py文件,运行完成以后,进入到widerface_evaluate文件夹下,点击widerface_txt可以看到生成的txt文件夹,和里面的txt文件,运行evalution.py即可得到检测准确度,跑不起来就先把对应的包先装好。 - 未完待续
一点点代码简析
文件结构
- data
- models
- runs
- torch2tensorrt # 没看懂,也没用过,懂的教教我
- utils
- weights # 下载预训练权重的脚本
- widerface_evaluate # 验证检测精度的文件夹
- detect_face.py # 只能检测一张图片
- hubconf.py #PyTorch Hub相关代码,没啥大用
- LICENSE # 版权文件
- README.md # README markdown文件
- result.jpg # 检测人脸的输出结果
- test.py # 不是用的这个
- test_widerface.py # 用的是这个
- train.py # 模型训练脚本
data
- images,一些检测用得到的图片。
- scripts,下载其他数据集的一些脚本文件,基本没用。
- widerface,初步转换数据集,用来生成widerfaceyolo数据集和验证训练模型的检测精度。
- widerfaceyolo,训练用的数据集。
- argoverse_hd.yaml/coco.yaml/coco.yaml/voc.yaml,下载自动驾驶/COCO/VOC训练数据集,配置一下类别数,没啥用。
- hyp.finetune.yaml,yolov5根据voc数据集设置的超参
- hyp.finetune.yaml,真正用到的超参文件!
- retinaface2yolo.yaml,没用过,不太懂
- train2yolo.py,生成训练用的train数据集
- val2yolo.py,生成训练用的val数据集
- widerface.yaml,训练用到的配置文件!
models
- common.py 模型组件的相关代码
- experimental.py 实验性质的代码,作者的一些想法,没有加到模型里去
- export.py 导出网络模型的结构,会很长很长
- yolo.py Detect以及Model构建代码,写出网络模型的整体构建过程
- …yaml 大大小小的模型配置文件,突出一个灵活。
common.py
- def autopad:为same卷积或same池化自动零填充,具体填充多少就是用这个函数计算的,保证卷积和池化后的特征图大小不变。
- def channel_shuffle:通道打乱,ShuffleV2Block的前置模块。
- def DWConv:深度可分离卷积,没用到。
- class Conv:Conv2d+BN+SiLU,也可以不进行BN操作。
- class StemBlock:替代Focus的模块,注意每个卷积核的大小和输出尺度。
- class Bottleneck:两次卷积+一次残差连接
- class BottleneckCSP:有多少个n就会有多少个Bottleneck,外层用的激活函数是Leaky_ReLU(0.1)。
一个分支做一次CBS(1x1),再做n次Bottleneck,再进行一次Conv2d(1x1);
另一个分支做一次Conv2d(1x1);
两个分支concat+BN+leakyRelu+CBS(1x1)。 - class C3:论文里面的C3的图是错误的,图里面的浅绿色方块是做一次Conv2d,实际上C3没有进行Conv2d,而是全部用的CBS,也可能是我没看到更深层的代码。
一个分支做CBS,做n次Bottleneck;
另一个分支做CBS;
两个分支concat以后做一次CBS。 - class ShuffleV2Block:轻量化网络结构模块ShuffleV2Block,我没有对这个部分深入理解,后续用到再更新。
- class SPP:SPP模块。
- class Focus:Focus模块。
- class Contract:收缩模块:调整张量的大小,将宽高收缩到通道中。
- class Expand:扩张模块,将特征图像素变大,例如:x(1,64,80,80) to x(1,16,160,160)。
- class Concat:自定义concat模块,dimension就是维度值,说明沿着哪一个维度进行拼接。
- class NMS :非极大值抑制模块。
- class autoShape:自动调整shape值:因为输入图像可能来自不同的地方和格式,例如filename,URI,numpy等,autoShape模块就是将这些数据进行预处理和调整。
- class Detections:看名字是做检测,但是好像没用到这个模块。
- class Classify:二级分类模块,人脸检测没用到。
utils
- aws/goolge_app_engine/wandb_logging/google_utils.py 谷歌云和自动驾驶相关的东西,没啥用
- activation.py 激活函数代码
- autoanchor.py 自动计算先验框代码
- datasets.py yolov5用来生成训练用数据的代码,yolo5face没用这个
- face_datasets.py dataset和dataloader定义代码,只能读图片
- general.py 设置一些通用的代码,如日志文件,随机数,获取最后一个权重文件等等
- loss.py 损失函数相关代码
- metrics.py 模型验证度量,计算ap,p,r等
- plotting utils.py 画图工具
- torch_utils pytorch工具,初始化随机数种子,git描述等
一些问题
- 有问题可以先去github官网源码那里看看,想在CSDN找答案实在是太难了。
- 官网的yolo5-face.pt预训练权重加入到模型中进行训练是会报错的,用yolov5官方的5.0的权重作为预训练权重就可以了。
- 验证检测精度的wider_val.txt文件链接:wider_val.txt
最后

参考文章
https://zhuanlan.zhihu.com/p/375966269
https://blog.csdn.net/john_bh/article/details/106302026